
- 1neo4j 知识图谱_用Python构建一个知识图谱
- 2基于单片机的光电传感转速测量系统的设计
- 3Visual Studio Code -> VSCode 开发环境搭建 ---- C 代码调试(code runner 插件)_vscode c代码调试
- 4python读取csv文件并转为list
- 5vue+Element-Plus+springboot整合mybatis-plus后台管理系统的学习笔记_基于spring boot + mybatis plus + vue & element的支持各种图
- 6WPF Tabcontrol SelectionChanged的错误触发问题_selectionchanged触发条件
- 7pyhon用超级鹰平台识别图片验证码登录超级鹰_简述如何使用超级鹰识别点选验证码
- 8记一次微信小程序直播对接_微信小程序直播api
- 9android电池(四):电池 电量计(MAX17040)驱动分析篇_电池电量计曲线
- 104. mtklog分析_mtklog 生成properties
ChatGPT是如何训练得到的?通俗讲解_chatgpt训练
赞
踩
首先声明喔,我是没有任何人工智能基础的小白,不会涉及算法和底层原理。
我依照我自己的简易理解,总结出了ChatGPT是怎么训练得到的,非计算机专业的同学也应该能看懂。看完后训练自己的min-ChatGPT应该没问题
希望大牛如果看到这篇文章后,就当图一乐。
ChatGPT名词解释(这里看看就行)
ChatGPT=GPT+人类反馈强化学习
GPT是Generative Pre-trained Transformer(生成预训练变换模型)
- Generative:生成的意思,因为这是个能生成文本的模型。
- Pre-trained:预训练的意思,这里代表无监督学习,是没有明确目的的训练方式,你无法提前知道结果是什么,生成文本比较发散。
- Transformer:变换的意思,代表是模型训练是网络架构,网络里面的各个参数不断变换嘛。
人类反馈强化学习是什么呢?
可以这样理解,模型的训练结果很大程度依赖人类的反馈,人类对其生成的结果进行打分。对打分的结果重新输入的模型中,来对模型进行调整。得分高相当于告诉它:”多生成这样的结果!“。得分低的相当于告诉它:”不要生成这样的结果!“。
ChatGPT是怎么训练得到的?
首先看一下ChatGPT发展时段:
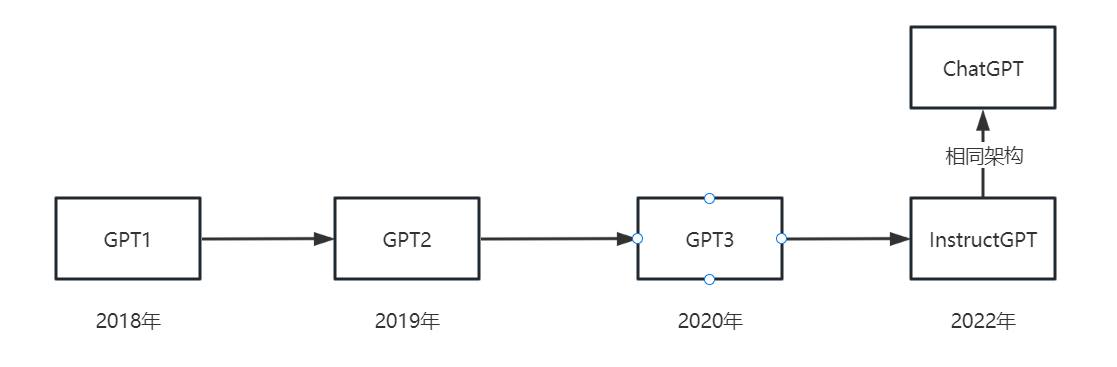
从GPT1到GPT3这个过程,GPT的三个模型几乎都是相同架构,只是有非常非常少量的改动。但一代比一代更大,,也更烧钱.。所以我对GPT系列的特点就是: 钞能力, 大就完事了。 其影响力和花费的成本是成正比的。
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
|---|---|---|---|
| GPT-1 | 2018年6月 | 1.17亿 | 约5GB |
| GPT-2 | 2019年2月 | 15亿 | 40G |
| GPT-3 | 2020年5月 | 1750亿 | 45TB |
从InstructGPT到ChatGPT没有很大的改动,ChatGPT采用的是InstructGPT的架构,本质上是一样的,只不过采用的训练的数据更多和人类聊天相关,所以变成了"ChatGPT"。
所以,最主要是看InstructGPT怎么通过GPT3来的。
InstructGTP训练流程
我参考了OpenAI发表关于InstructGPT论文:https://arxiv.org/pdf/2203.02155.pdf,分为如下的三步。
理论上讲,只要看懂了训练步骤的这三部分,就可以训练得到我们自己的 ChatGPT
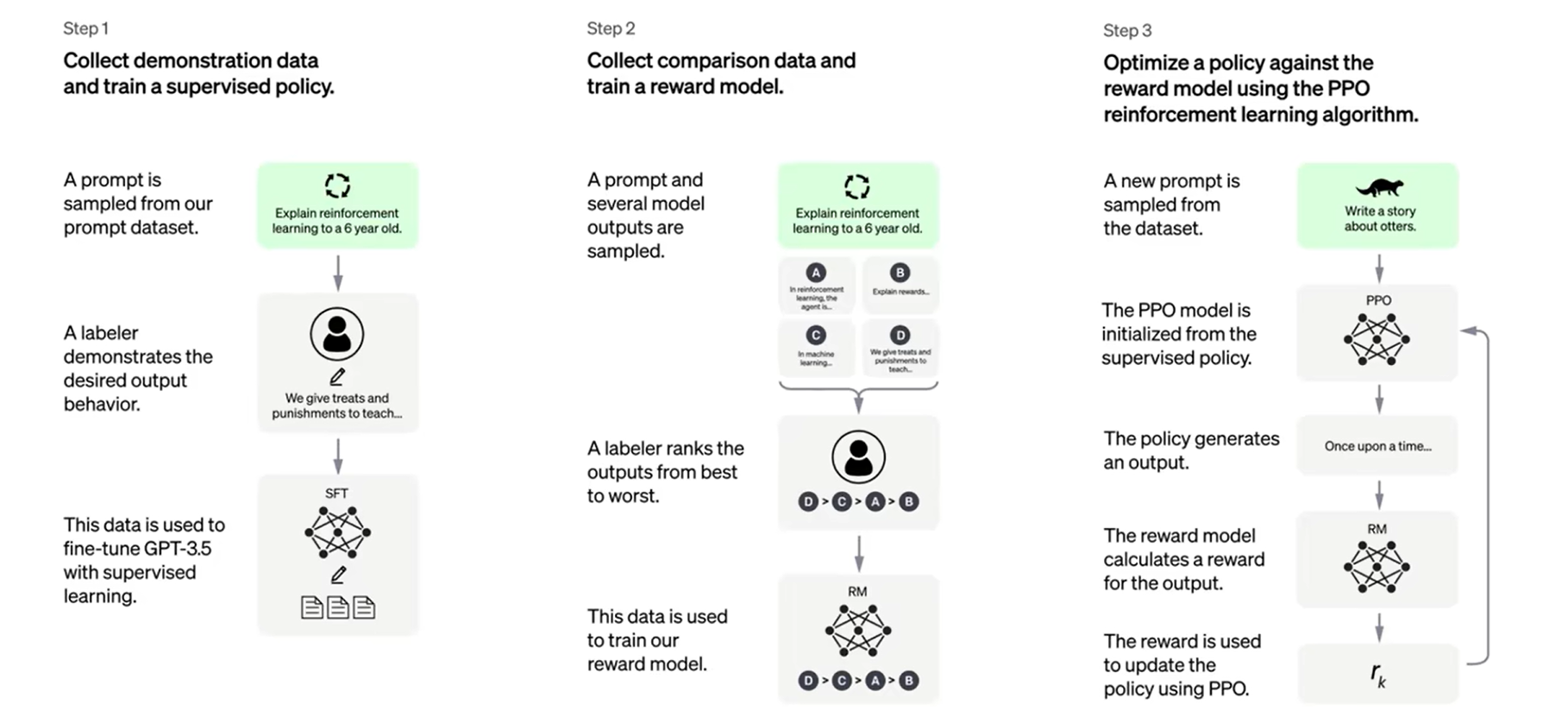
通俗化后如下…,下面我会详细解释每一步。
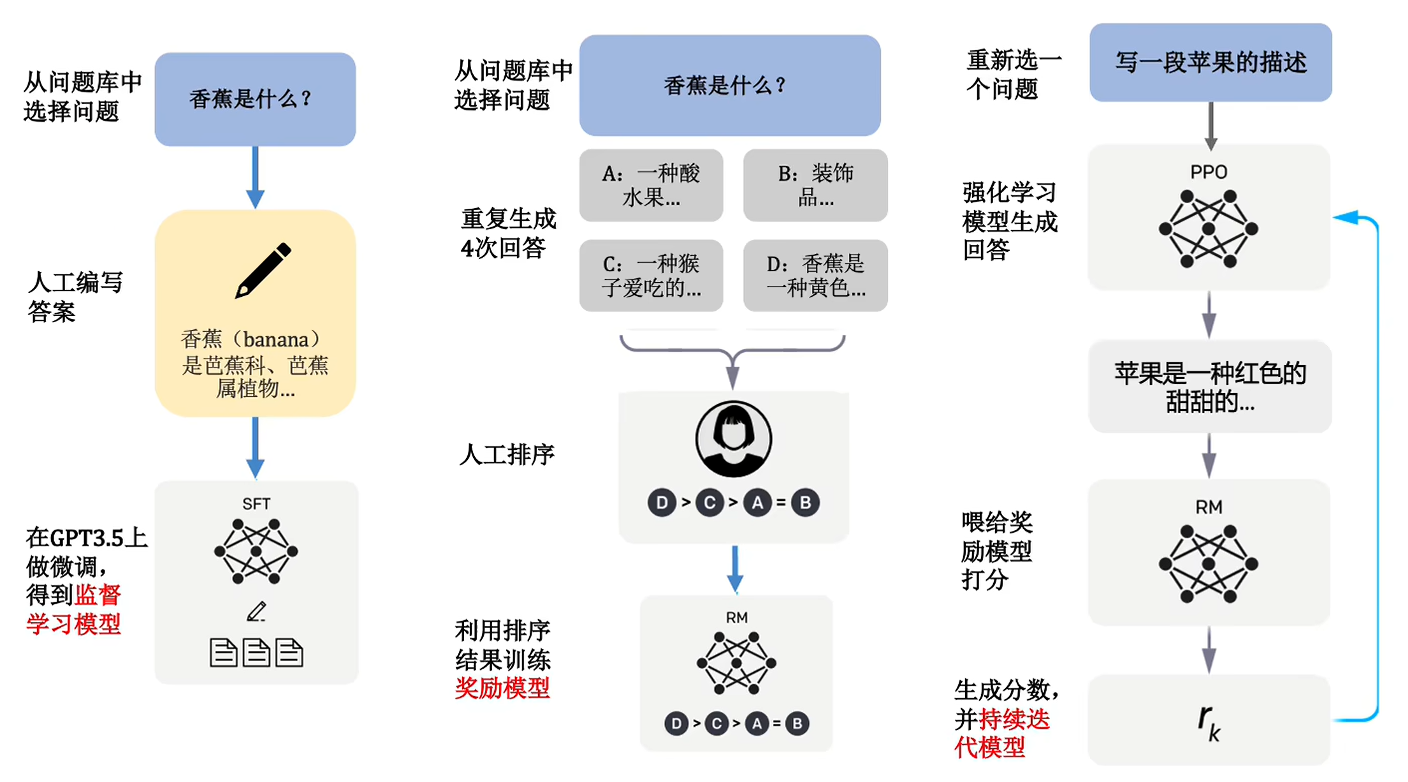
Step1 以监督学习的方式对GPT3进行微调,得到监督学习模型

首先收集人们在对话中更感兴趣的问题,形成一个问题库,然后不断从数据库中提取一个问题(称为prompt),给到现实生活中的人,让它来做出回答。原论文图片里面的例子是给6岁的儿童解释强化学习,让人工回答完后将问题和回答一起放入到GPT-3.5中进行监督学习,来得到一个生成模型。
每次往模型中输入一个文本,它就是按照训练的数据,给我们输出一个文本。
补充:问题库的来源:
GPT3面世后,OpenAI提供了api,可集成到自己的项目中,用户使用的时候直接采用 prompt的方法做0样本或小样本的预测
下面的代码就是调用OpenAI提供的api,使用的同时,OpenAI会收集prompt数据,研究人员从这些问题(prompt)中采样一部分,人工对这些问题(prompt)做回答,得到的结果称为demonstration即有标签数据,再用这些demonstration继续微调GPT3
import openai
openai.api_key="**********************"
response = openai.Completion.create(
model="text-davinci-003",
prompt=prompt,
temperature=0,
max_tokens=100,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.0,
)
message = response.choices[0].text
print(message)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
毫无疑问,第一步通过大量监督学习的方式其实是比较困难的,它消耗很多的资源。很难找到足够多的人来回答问题很多不同领域的问题,并且有些回答不好评价它的好坏。因此有了接下来的两步。
Step2 训练出一个奖赏模型

奖赏模型的训练方式,针对同一个问题,让第一步得到监督学习模型给出四个答案。让现实中的人对这四个回答进行排序,对这个排序来进行训练奖赏模型。
虽然我造不出冰箱,但我可以评价一个冰箱的好坏。意思是说,我没有办法像监督学习这样的方式,告诉你冰箱是怎么造的,但是我是冰箱实际上的使用者,我是可以评估冰箱是好还是坏的。就像我没有办法向6岁儿童解释深度学习,但是我可以对生成回答判断是好是坏,就能很轻易的对它们进行排序。
很显然,排序的成本是比直接回答的成本更低的。
补充:为什么需要奖赏模型?
我们需要不断对生成的结果进行排序,来得到人们最满意的回答。人能够对生成的结果进行满意度排序,那我们也希望有模型来对结果排序。
Step3 训练得到基于PPO算法的强化学习模型

PPO算法不用管,只用知道这是人工智能领域一个很厉害的强化学习的算法就行了。深入不讨论。
首先我们还是从数据集里面取出一条问题(prompt),然后放入到强化学习模型里面,得到了一条输出文本。我们对输出的文本进行打分,把打分的结果反馈到强化学习模型中。
这个强化学习模型是基于第一步得到的监督模型得到的,打分的话,是用到第二部得到的奖励模型。
总结
InstructGPT比GPT3有哪些方面的改进?
- InstructGPT使用的训练数据,是人们更加经常使用到的,比如:日常的对话,常见的数学、物理知识等等。因此我们使用ChatGPT才能更像对话。
- 引入了强化学习
ChatGPT这次能破圈引起全球讨论,原因是采用了对话形式,让每个普通人都能感受到人工智能技术的强大
最后说一下我对ChatGPT的理解
-
ChatGPT的出现并不是说OpenAI有多厉害,他们用的技术并不都是原创的技术,甚至很多模型都是行业内开源的,但是他们巧妙地把这些模型融合到了一起。更为关键的是,ChatGPT将模型参数扩大到了1750亿,模型框架没有改变,但是参数有了十倍、百倍的增长,最终量变引发了质变
-
ChatGPT更准确的定位是个人助手
它在办公场景里很好用,比如写大纲、写报告、写文章,还有做题,甚至写代码,就算是编程的初学者也能在其帮助下写出高质量的代码。现在,ChatGPT已经具备了一定的逻辑推理能力,未来,在客服、营销、医疗等诸多场景下,只要是重复性的人脑劳动都有可能被ChatGPT取代
参考:

