
- 1jenkins自动化部署_jenkins打包,发布,部署
- 2opencv图像美化_opencv 图像美化
- 3计算机基础知识和实践技能300分,2019年河北省普通高职单招考试十类和对口电子电工类、计算机类联考考试内容...
- 4VideoCrafter - 文本生成视频
- 5openMP编程详解(囊括所有基本指令)
- 6函授大专计算机考证_函授大专计算机专业可以考什么证
- 7一分钟教你把Notion变为中文版_notion怎么变成中文版
- 8axios详解以及完整封装方法_axios封装
- 9esxi6.7安装MacOS 10.15_esxi6.7安装mac os 卡住
- 10Android HAL层添加HIDL实例实现串口通信_android 新增hidl接口
AIBigKaldi(五)| Kaldi的单音子模型训练(上)(源码解析)_kaldi 模型训练
赞
踩
本文来自公众号“AI大道理”。
这里既有AI,又有生活大道理,无数渺小的思考填满了一生。
提取了MFCC特征,并进行倒谱均值方差归一化,数据检查无误后就可以进行模型训练了。
首先进行的是单音素模型训练,然后进行三音子模型训练。
单音子模型为后期训练提供对齐基础。
以kaldi中的yesno为例。
1 单音子模型训练
3 train_mono.sh
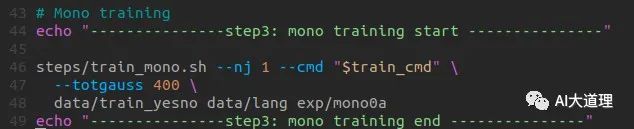
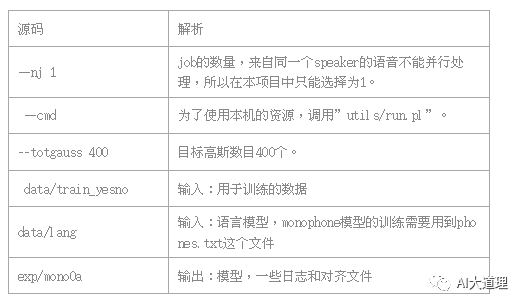
源码解析:
Usage: steps/train_mono.sh [options] <data-dir> <lang-dir> <exp-dir>
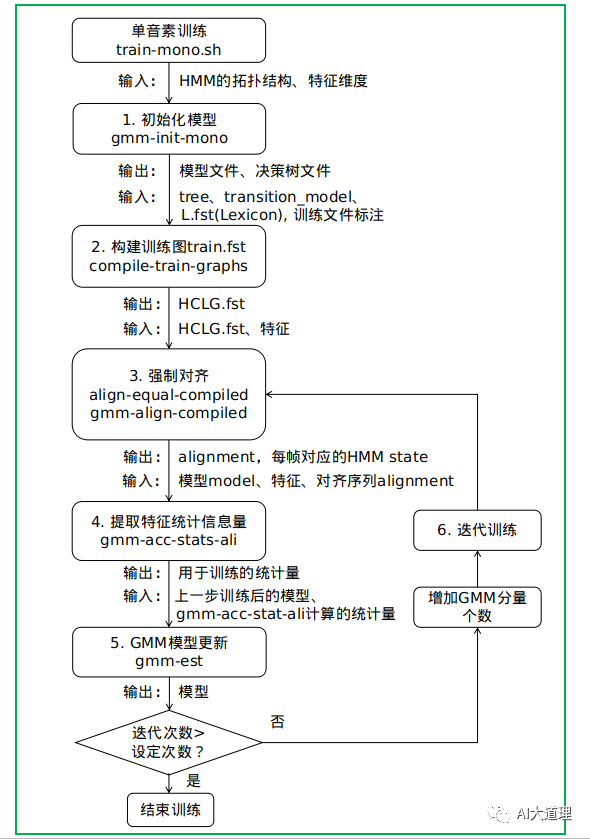
过程之道:
初始化模型->生成训练图HCLG.fst->对标签进行初始化对齐->统计估计模型所需的统计量->估计参数得到新模型->迭代训练->最后的模型final.mdl。
在迭代训练中:
使用gmm-align-compiled对齐特征数据,得到新的对齐状态序列;
调用gmm-acc-stats-ali计算更新模型参数所用到的统计量;
调用gmm-est更新模型参数,并且在每一轮中增加GMM的分量个数。
2 初始化模型
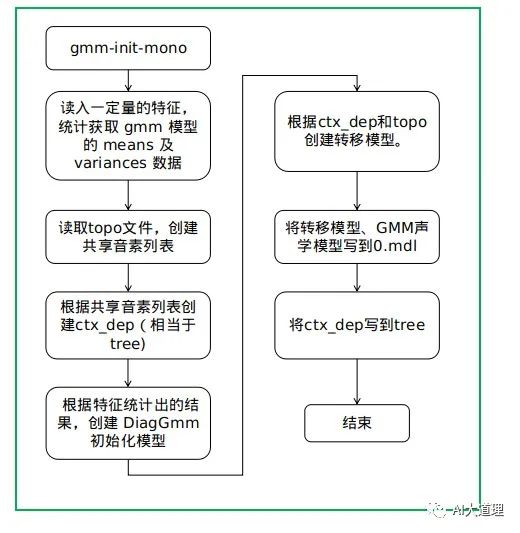
3.1 gmm-init-mono.cc
功能:
初始化模型是最基础的模型。
这是不需要任何训练数据就可以得到的模型。
(无中生有)
输入:HMM的拓扑结构,特征维度
输出:模型、决策树

源码解析:
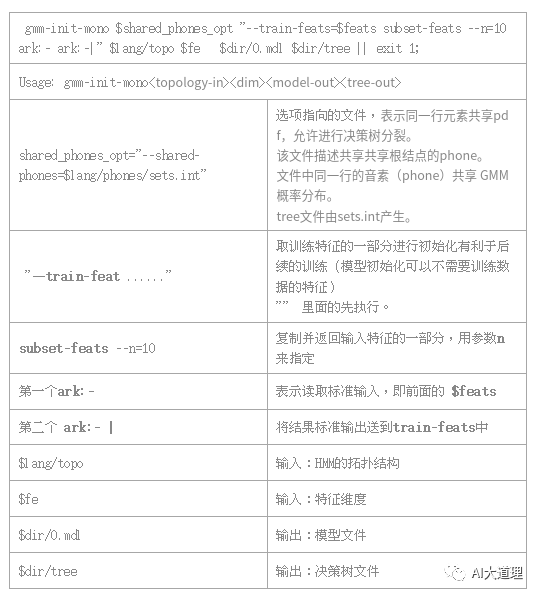
过程之道:
-
初始化全局特征的均值和方差glob_inv_var,glob_mean均为1,大小等于特征维度。如果有输入特征,另外再计算更新。
-
读入拓扑结构HmmTopology,建立里面所有phone到该phone的Pdf class数目的映射。
-
构建决策树,只需要根据set.int文件递归的构造树。
-
gmm-init-mono构建GMM。每个pdf初始化只有一个gmm,也就是单高斯,均值方差来自之前的glob_inv_var,glob_mean, weight为1,均值方差也都为1,计算常数部分gconsts 即高斯分布x为0时的概率。
-
将所有gmm模型导入声学模型am_gmm中。最后输出transition和声学模型的文件model,决策树tree。
初始化模型结果:
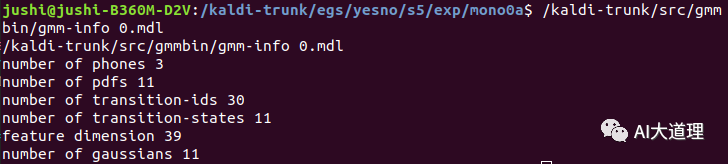
这已经是一个完整的声学模型了,可以用它来进行语音识别,只是识别率不高。
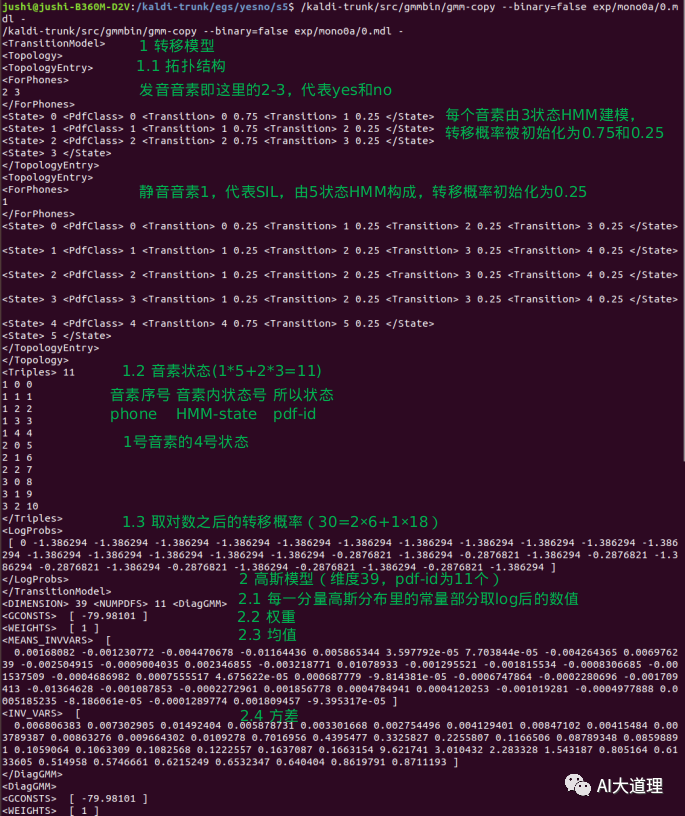
0.mdl的内容如下:
/kaldi-trunk/src/gmmbin/gmm-copy --binary=false exp/mono0a/0.mdl -
0.mdl包含TransitionModel转移模型和多个DiagGMM高斯模型。
其中:
拓扑结构:
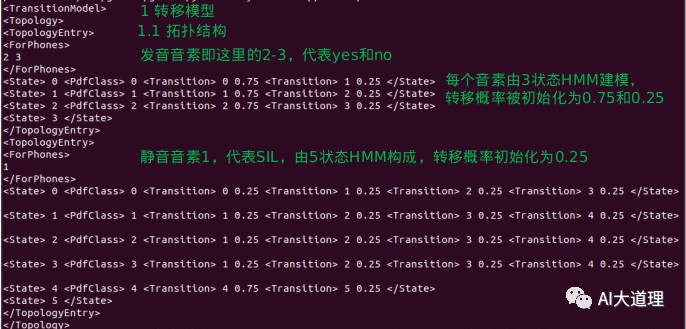
三状态HMM(非静音)
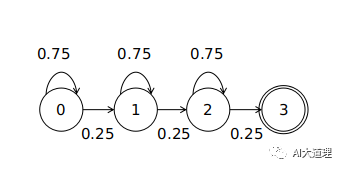
可见共6个转移弧。
五状态HMM(静音)
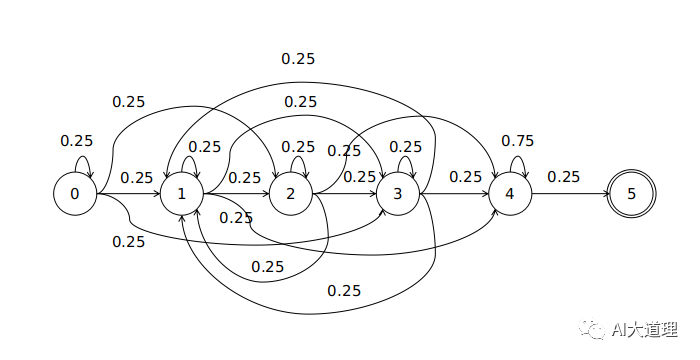
可见共4*4+2=18个转移弧。
音素 hmm状态:

1号是静音因素有5个HMM状态,用01234表示,其他因素只有3个状态,用012表示 。
pdf-id就是0-10,每个状态对应一个GMM分布。
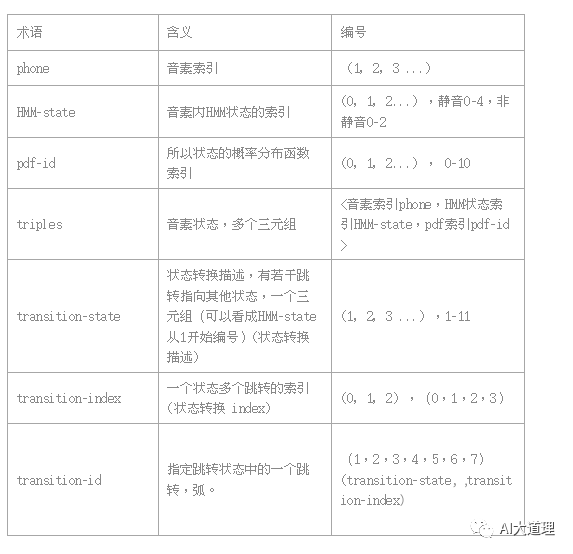

取对数之后的转移概率:
转移弧个数31=2*6+1*18+1
其中第一个0是因为transition-id是从1开始,在所有转移弧前补充一个0。

高斯模型:
维度39维(没有能量),pdf-id个数为11个,参数包含means_invvars均值和inv_vars方差、权重、每一分量高斯分布里的常量部分取log后的数值。
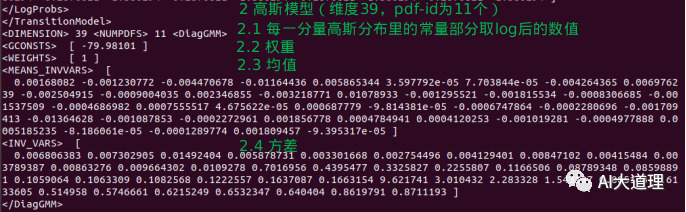
得到了初始化的模型0.mdl, 2个音素,11个状态。
每个状态对应一个只包含一个高斯分量的GMM。
可以直接用这个模型进行语音识别,但效果会很差。
后续的参数迭代中要更新每个状态的HMM转移概率和GMM的均值向量以及协方差矩阵,同时进行单高斯分量到混合高斯分量的分裂。
tree
查看tree内容:
/kaldi-trunk/src/bin/copy-tree --binary=false tree -
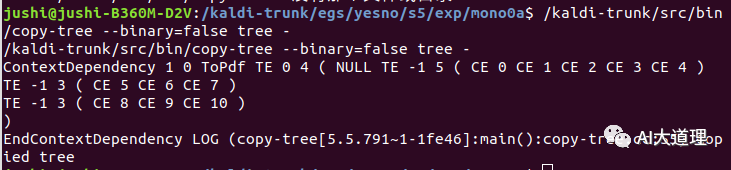
文件之后的内容,是递归保存了一棵决策树。
构造决策树的过程:
CE(Constant EventMap):叶子节点,直接保存该节点存放的transition ID;
SE(Split EventMap):非叶子节点,保存左右子节点yes,no等等;
TE(Table EventMap):非叶子节点,保存节点数以及各个子节点的指针。
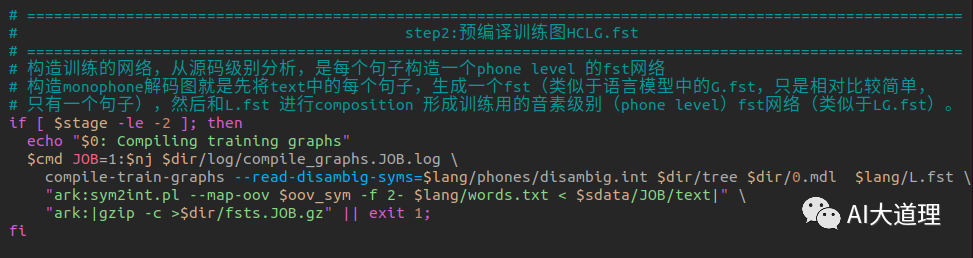
3 预编译训练图
3.2 compile-train-graphs.cc
功能:
训练用每句话转换成一个FST结构,输入是音素,输出是整个句子。
输入:tree , transition_model ,L.fst(Lexicon),训练文件标注。
输出:为图 HCLG.fst
标注文本:
为什么需要训练图?
kaldi训练模型并不是采用理论中的Baum-Welch算法的软对齐,实践中是使用Vitrerbi算法进行硬对齐。
(可见理论和实践的差异。)
为了获得每一帧对应的状态号作为训练的标签,需要构建一个直线形的状态图。
在这个图上利用Viterbi算法求得最优路径,同时得到帧与状态的对齐。
源码解析:
构造结果:
状态图是一个直线型的图,包含了标注文本的状态序列,同时每个状态有指向自身的跳转即self-loop。
在monooa目录下运行:
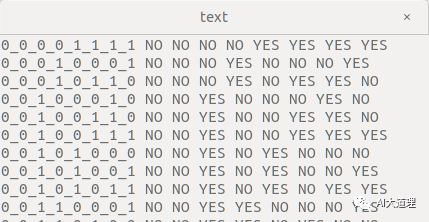
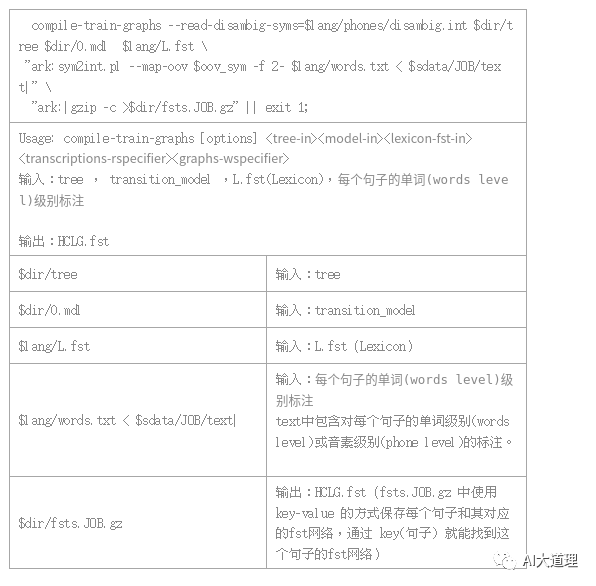
/kaldi-trunk/src/bin/compile-train-graphs --read-disambig-syms=../../data/lang/phones/disambig.int tree 0.mdl ../../data/lang/L.fst 'ark:../../utils/sym2int.pl --map-oov 1 -f 2- ../../data/lang/words.txt < ../../data/train_yesno/split1/1/text|' ark,t:HCLG.fst.txt
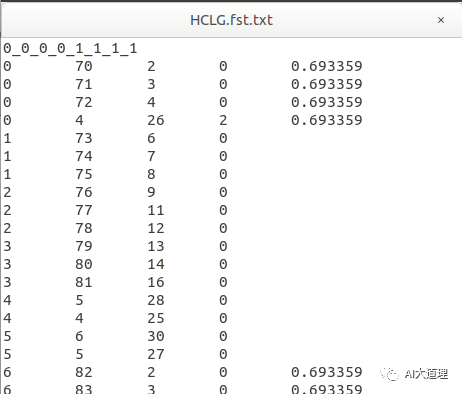
去掉0_0_0_0_1_1_1_1和其他语音,保存。
转化为fst图:
fstcompile HCLG.fst.txt HCLG.fst
可视化:
fstdraw --isymbols=phones.txt HCLG.fst | dot -Tps > HCLG111.ps

放大:
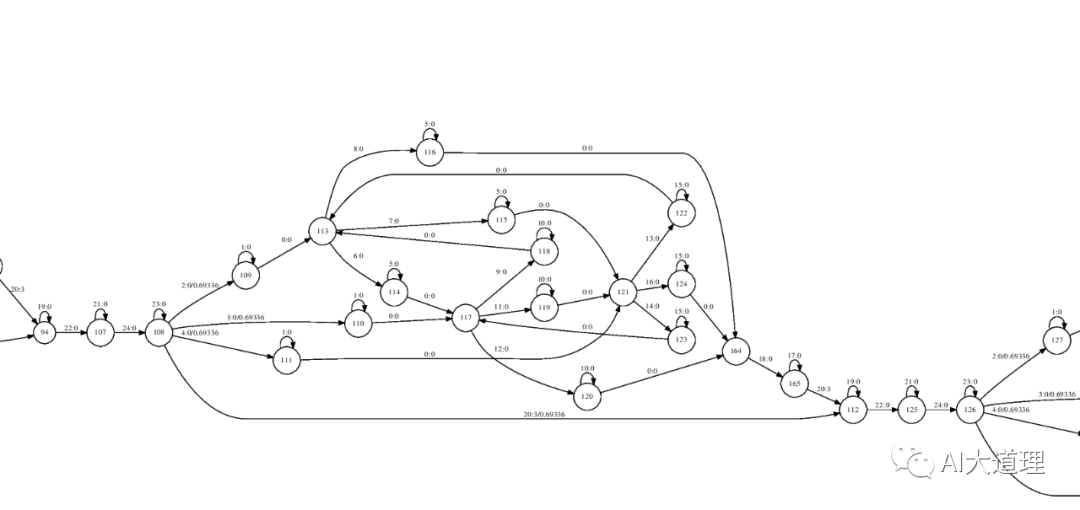
整体来看这个状态图是一个直线型的图,包含了标注文本的状态序列,同时每个状态有指向自身的跳转即self-loop。
圆圈表示的就是状态,里面的数字是状态的id。
弧上面,冒号前面的数字是transition-id,冒号后面的数字是输出的音素;斜杠后面的数字是权重。
只包含标注文本的状态序列。
(构造训练图是基于抄本构建的,比后面的构造解码图要简单些,所采用的代码也不一样。)
4 模型训练
构造好训练图接下来就可以进行训练了。
所谓训练就是在训练图上进行解码,获得最优路径的同时得到对齐序列,根据对齐序列进行统计信息量。
转移概率可以进行数数获得,GMM参数随着对齐的帧数变化而更新,同时GMM分量从一开始的单高斯split出更多的高斯。
如此不断迭代训练获得单音子模型。

下期预告
AIBigKaldi(六)| Kaldi的单音子模型训练(下)
往期精选
AI大语音(十四)——区分性训练
AI大语音(十三)——DNN-HMM
AI大语音(十二)——WFST解码器(下)
AI大语音(十一)——WFST解码器(上)
AI大语音(十)——N-gram语言模型
AI大语音(九)——基于GMM-HMM的连续语音识别系统
AI大语音(八)——GMM-HMM声学模型
AI大语音(七)——基于GMM的0-9语音识别系统
AI大语音(六)——混合高斯模型(GMM)
AI大语音(五)——隐马尔科夫模型(HMM)
AI大语音(四)——MFCC特征提取
AI大语音(三)——傅里叶变换家族
AI大语音(二)——语音预处理
AI大语音(一)——语音识别基础
——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

—————————————————————

