
- 1硬件工程师成长之路(3)——PCB设计_硬件pcb学习教程
- 2学习Vue前所一定要知道的事?怎么学?推荐教程?_学习vue之前要学习什么
- 3MySQL主从延迟问题排查_查询从库耗时吗
- 4Java测试类的编写与使用_java测试类怎么写
- 5HTML简易的用户名密码登录页面_艾孜尔江撰_简单账号密码登陆页面html代码
- 6HBase数据一致性和容错_hbase支持哪种类型的数据一致性?
- 7python open函数文本操作详解_python open wt
- 8阿里云代理仓库地址
- 9出现INSTALL_FAILED_UPDATE_INCOMPATIBLE错误原因_the application could not be installed: install_fa
- 10【精华】AIGC之大语言模型及实践应用_aigc大语言模型模型文件
人脸编辑神器!浙大&腾讯提出FaceX:统一面部表征建立通用人脸编辑模型
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫码加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文搞科研,强烈推荐!

在CVer微信公众号后台回复:论文,即可下载论文pdf和代码链接!快学起来!
项目主页:https://diffusion-facex.github.io
论文链接:https://arxiv.org/abs/2401.00551

1. 引言
研究问题:
随着泛娱乐领域的火热发展,以人为中心的AIGC技术也越发引人注目。本文研究多种主流面部编辑任务,包括low-level tasks如facial inpainting [1]和domain stylization [2],high-level tasks如region-aware face / head / attribute swapping [3,4,5,6,7],以及motion-aware pose / gaze / expression control [8,9,10]。上述任务在泛娱乐、社交媒体和安全等多个领域都有广泛的应用价值与前景。面部编辑的主要挑战是在修改不同属性的同时保持身份和未受影响的属性一致。
研究动机:
为了获得高质量的编辑人脸图像,当前方法大多在StyleGAN [11]的latent space寻找解耦方向实现不同属性的编辑。得益于扩散模型强大的生成能力,最近的人脸编辑工作逐渐采用改进的StableDiffusion(SD)模型来提高各种人脸编辑任务中生成的面部质量。然而,在Zero-shot setting下解耦并控制面部属性效果仍不理想。此外,不同的方法会精心设计task-specific模块以提高模型效果,不具有普适性而限制了它们的通用性。相比之下,通用模型(即一个模型完成多个任务)具有更高的实用价值,在自然语言处理[12,13]和图像分割[14]等领域均有相关研究工作。受限于面部任务的多样性,通用人脸编辑模型的研究存在较大挑战。
如何统一多种人脸编辑任务:
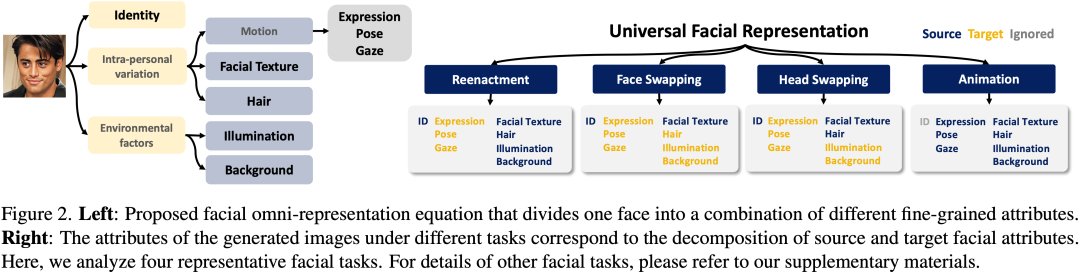
作者认为不同人脸任务本质上均可表示为条件受限下的图像生成任务,不同任务之间的差异表现为条件的差异,因此只要将控制条件统一即可完成不同人脸编辑任务的统一。受启发于probabilistic LDA[15,16],作者的解决方案是引入了一个统一面部表征公式,宏观地将面部分解为三个因素的组合:
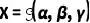 (1)
(1)
其中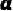 代表身份(Identity),
代表身份(Identity),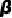 代表人脸相关变量(Intra-personal Variation),
代表人脸相关变量(Intra-personal Variation),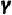 代表环境变量(Environmental Factors),
代表环境变量(Environmental Factors), 代表强大的生成模型。进一步,
代表强大的生成模型。进一步,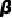 可以分解为运动(Motion),面部纹理(Facial Texture)和头发(Hair),
可以分解为运动(Motion),面部纹理(Facial Texture)和头发(Hair),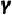 对应于照明(Illumination)和背景(Background)。如下图所示,该方式实现了清晰的公式级任务分解,易于操作并能快速适应各种面部编辑任务,使多功能和高效的解决方案成为可能。
对应于照明(Illumination)和背景(Background)。如下图所示,该方式实现了清晰的公式级任务分解,易于操作并能快速适应各种面部编辑任务,使多功能和高效的解决方案成为可能。
2. 方法
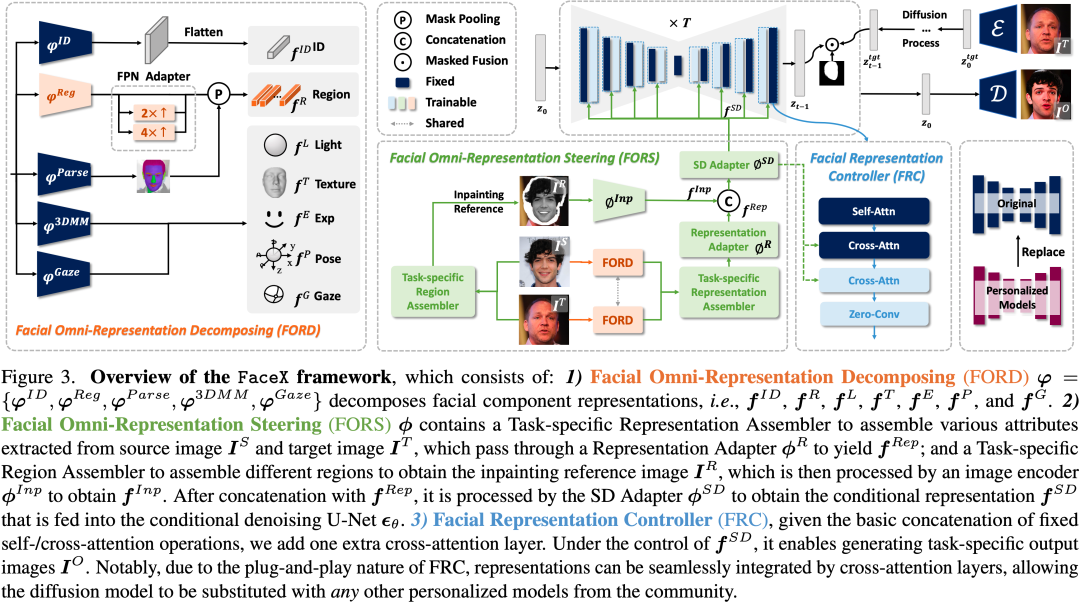
作者首次提出了通用的人脸编辑模型FaceX,其使用统一的模型同时处理多种面部编辑任务,在zero-shot setting下生成高质量人脸图像的同时保持了各种属性的分解和编辑能力。具体地,FaceX包含两个重要的设计以实现通用人脸任务能力:
1)Facial Omni-Representation Decomposing (FORD,下图橙色部分):
作者基于统一面部表征公式(1)使用不同的预训练模型提取不同的面部成分,包括:
Identity Feature:人脸识别特征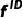 [17]用来保持生成图像身份的一致性。
[17]用来保持生成图像身份的一致性。
Region Feature:使用预训练CLIP ViT[18,19]作为面部特征编码器以与SD文本空间对齐,同时设计了FPN Adapter恢复空间分辨率,配合face parsing模型BiSeNet[20]得到的人脸区域(眉毛、眼睛、鼻子、嘴唇、耳朵和皮肤)后通过mask feature pooling得到区域特征表示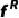 。
。
Motion Descriptor:使用D3DFR[21]提取expression和pose特征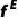 、
、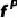 ,此外解耦的light和texture特征
,此外解耦的light和texture特征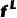 和
和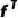 进一步提升面部生成质量,MPIIGaze [22]提取gaze特征
进一步提升面部生成质量,MPIIGaze [22]提取gaze特征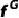 。
。
2)Facial Omni-Representation Steering(FORS,下图绿色部分):
解耦后的人脸表示可以根据特定人脸任务灵活重组,包括:
Task-specific Representation Assembler在特征级别操作。
Task-specific Region Assembler在图像级别重组不同面部区域。
SD Adapter将重组后的特征映射到SD空间。
通过这种方式,提出的FaceX可以实现单一模型在多任务下的多样化和混合编辑能力,比如眼镜,胡须,外形,发型,图像修复,以及多种属性的组合。此外,直观的图像级区域重组操作也增强了编辑的交互性和应用价值。
3)Facial Representation Controller(FRC,下图蓝色部分):
对于条件生成模型,核心挑战是如何有效并高效地利用丰富的面部表征条件来指导目标图像的生成过程。作者提出了基于self-attention、cross-attention和zero-convolution串接的FRC模块进行特征的高效注入。
3. 实验
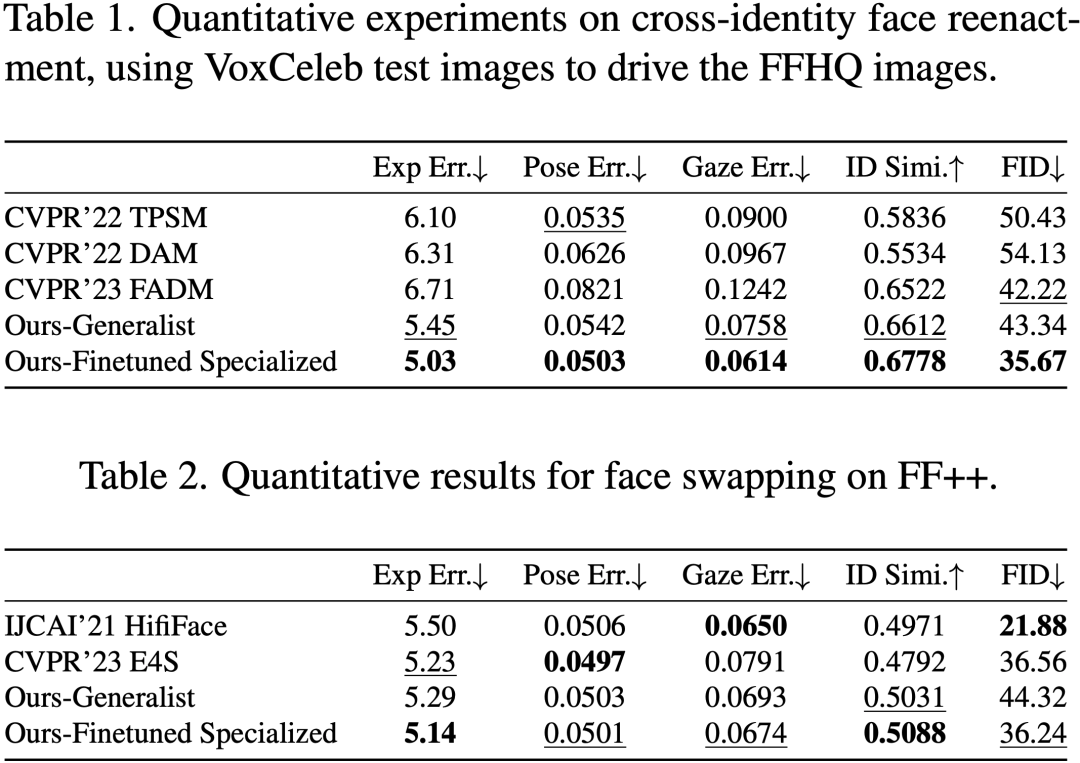
作者在8个主流人脸任务上做了大量定性/定量实验分析,证明了FaceX不仅能够使单一模型具有通用人脸编辑能力,同时具有最先进或极具竞争力的结果。部分实验结果如下,更多的实验结果见项目主页(https://diffusion-facex.github.io)和论文。




4. 结论
作者提出了一种新颖的通才FaceX,通过构建连贯的面部表征来完成多种人脸编辑任务。具体来说,文章提出了一种新颖的FORD以便轻松操控各种面部细节,并设计了FORS来重组统一的面部表示,然后通过设计的FRC有效地引导SD的可控人脸生成过程。在多种人脸任务上的大量实验证明了所提方法的统一性、高效性和有效性。
参考文献
[1] Zhang, Wendong, et al. "Context-aware image inpainting with learned semantic priors." IJCAI. 2021.
[2] Gal, Rinon, et al. "StyleGAN-NADA: CLIP-guided domain adaptation of image generators." ACM TOG. 2022.
[3] Liu, Zhian, et al. "Fine-Grained Face Swapping via Regional GAN Inversion." CVPR. 2023.
[4] Luo, Yuchen, et al. "Styleface: Towards identity-disentangled face generation on megapixels." ECCV. 2022.
[5] Nirkin, Yuval, Yosi Keller, and Tal Hassner. "FSGANv2: Improved subject agnostic face swapping and reenactment." TPAMI. 2022.
[6] Shu, Changyong, et al. "Few-shot head swapping in the wild." CVPR. 2022.
[7] Wang, Yuhan, et al. "Hififace: 3d shape and semantic prior guided high fidelity face swapping." IJCAI. 2021.
[8] Xu, Chao, et al. "High-fidelity Generalized Emotional Talking Face Generation with Multi-modal Emotion Space Learning." CVPR. 2023.
[9] Zhang, Jiangning, et al. "Freenet: Multi-identity face reenactment." CVPR. 2020.
[10] Zhu, Feida, et al. "HifiHead: One-Shot High Fidelity Neural Head Synthesis with 3D Control." IJCAI. 2022.
[11] Karras, Tero, et al. "Analyzing and improving the image quality of stylegan." CVPR. 2020.
[12] Brown, Tom, et al. "Language models are few-shot learners." NeurIPS. 2020.
[13] Ouyang, Long, et al. "Training language models to follow instructions with human feedback." NeurIPS. 2022.
[14] Wang, Xinlong, et al. "Images speak in images: A generalist painter for in-context visual learning." CVPR. 2023.
[15] Ioffe, Sergey. "Probabilistic linear discriminant analysis." ECCV. 2006.
[16] Prince, Simon, et al. "Probabilistic models for inference about identity." TPAMI. 2011.
[17] Deng, Jiankang, et al. "Arcface: Additive angular margin loss for deep face recognition." CVPR. 2019.
[18] Radford, Alec, et al. "Learning transferable visual models from natural language supervision." ICML. 2021.
[19] Dosovitskiy, Alexey, et al. "An image is worth 16x16 words: Transformers for image recognition at scale." ICLR. 2021.
[20] Yu, Changqian, et al. "Bisenet: Bilateral segmentation network for real-time semantic segmentation." ECCV. 2018.
[21] Deng, Yu, et al. "Accurate 3d face reconstruction with weakly-supervised learning: From single image to image set." CVPRW. 2019.
[22] Zhang, Xucong, et al. "Mpiigaze: Real-world dataset and deep appearance-based gaze estimation." TPAMI. 2017.
在CVer微信公众号后台回复:论文,即可下载论文pdf和代码链接!快学起来!
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集- 人脸技术交流群成立
- 扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-人脸技术 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如人脸技术+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
- ▲扫码或加微信号: CVer444,进交流群
- CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
-
- ▲扫码加入星球学习
▲点击上方卡片,关注CVer公众号