
- 1Android源码笔记--Service的启动流程(2)_permissions_review_required
- 2ssssssssss17
- 3记录一次kafka connectos之erdemcer启动报错_workersourcetask{id=mid_1941_invitation_relationsh
- 4百度地图Android API实现点聚合功能以及设置最小聚合数和最大显示数_百度地图合并展示数字怎么弄
- 5idea的 Cannot resolve method ‘setAttribute(java.lang.String, java.lang.String)的解决问题_cannot resolve method 'setsignature(string)
- 6windows下配置gcc/g++/gdb + emacs编译环境只需两三步
- 7Android开发Jetpack从入门到精通教程_jiepack 教程
- 8利用C#查看特定服务是否安装
- 9DSPE-PEG-MAL,474922-22-0,DSPE-PEG-Maleimide_dspe-peg-mal结构式
- 10Python3.6实现12306火车票自动抢票(附源码)_12306抢票脚本
YOLOv7移植经验分享_yolov7移植bm1680
赞
踩
目录
一、背景
YOLOv7在 5 FPS 到 160 FPS 范围内的速度和准确度都超过了所有已知的目标检测器,并且在 GPU V100 上 30 FPS 或更高的所有已知实时目标检测器中,具有最高的准确度 56.8% AP。
YOLOv7-E6(56 FPS V100,55.9% AP)比基于Transformer的检测器 SWIN-L Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)的速度和准确度分别高出 509% 和 2%,并且比基于卷积的检测器 ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度提高 551%,准确率提高 0.7%,以及 YOLOv7 的表现还优于:YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、 DETR、Deformable DETR、DINO-5scale-R50、ViT-Adapter-B和许多其他速度和准确度的目标检测算法。此外,YOLOv7基于 MS COCO 数据集上从零开始训练 ,未使用任何其他数据集或预训练的权重。
为了更好的服务客户,这里基于该算法进行提前适配,方便后续客户使用时进行参考、指导。
官方仓库:https://github.com/WongKinYiu/yolov7
模型地址:https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7x.pt
二、环境
2.1 服务器环境
SDK复现需要借助一定的开发环境,这里基于公有服务器,通过ssh方式使用,步骤如下:
- 申请服务器账号
- 借助ssh工具,登录到服务器,MobaXterm、SecureCRT等软件
- 下载必要的成果物:SDK最新包+docker镜像,可以采用wget命令:
| # docker镜像 |
下载好的成果物如下:
2.2 SDK环境
通过上述操作,我们已经下载了必备的成果物,这里先解压SDK整包,解压后,可以通过校验MD5码,防止文件被篡改,带来一些不必要的麻烦,命令如下:
| (base) xxx@bitmain-SYS-4028GR-TR2:~$unzip bmnnsdk2_bm1684_v2.7.0_20220531patched.zip |
继续解压缩SDK真正成果物,如下:
| (base) xxx@bitmain-SYS-4028GR-TR2:~/bmnnsdk2_bm1684_v2.7.0_20220531patched$tar -zxvf bmnnsdk2-bm1684_v2.7.0.tar.gz |
至此,SDK包的环境已经处理完毕。
2.3 docker环境
经过上述操作,我们已经进入到服务器环境,并且下载好了相关成果物。为了方便复现SDK,这里直接基于官方docker镜像,不再采用自搭docker。
docker采用ubuntu-docker-py37,首先需要解压该docker压缩包,解压缩后,可以通过校验MD5码,防止文件被篡改,带来一些不必要的麻烦,命令如下:
| (base) xxx@bitmain-SYS-4028GR-TR2:~$unzip bmnnsdk2-bm1684-ubuntu-docker-py37.zip |
之后通过加载docker镜像,将镜像仓库加载到服务器环境,命令如下:
| #装载镜像 |
参考官方说明,SDK包中有docker运行的脚本docker_run_bmnnsdk.sh,这里为了方便识别,对脚本做了一些修改:重命名container名称等,如下(可以根据自己需要增删):
| if [ -c "/dev/bm-sophon0" ]; then |
下面创建container,采用官方脚本,容器创建后,会默认进入,命令如下:
| (base) xxx@bitmain-SYS-4028GR-TR2:~/bmnnsdk2_bm1684_v2.7.0_20220531patched/bmnnsdk2-bm1684_v2.7.0$./docker_run_bmnnsdk.sh |
注:上述方式运行的container,在退出后,container会自动退出,为了方便反复使用,可以通过如下命令进入:
| (base) xxx@bitmain-SYS-4028GR-TR2:~/bmnnsdk2_bm1684_v2.7.0_20220531patched/bmnnsdk2-bm1684_v2.7.0$docker start ubuntu16.0-py37-wnb |
至此,基本环境就搭建完毕了。
三、移植开发
常规算法移植,基本上都需要以下几个阶段:
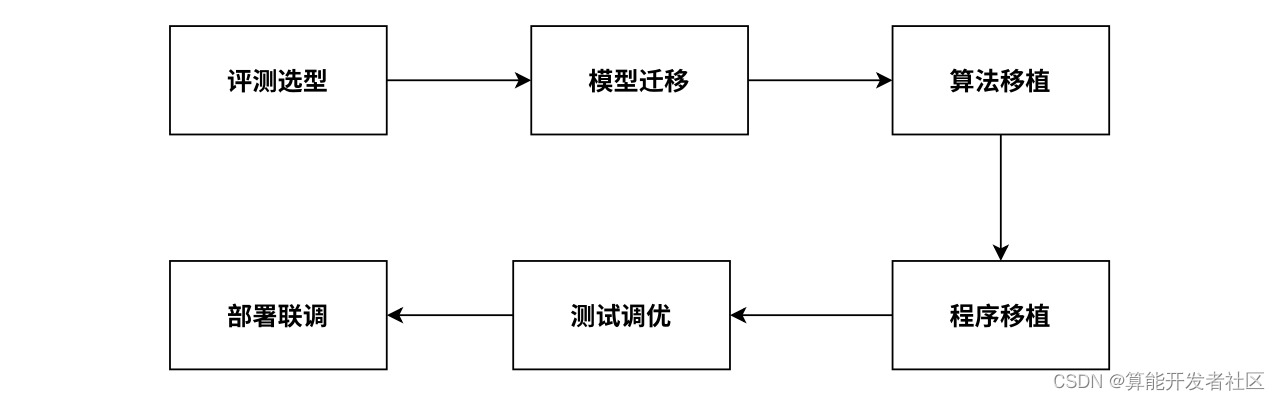
具体各阶段需要做的事情如下:
- 评测选型:根据应用场景,确定使用的产品形态,敲定模型;
- 模型迁移:将原始深度学习框架下训练生成的模型转换为具体硬件平台支持的模型,涉及量化、自定义算子等;
- 算法移植:将模型的前后处理部分进行加速接口替换,一般硬件平台都会针对一些常见的图片处理接口进行加速,比如:图片缩放、色彩空间转换等。
- 程序移植:移植任务管理、资源调度等算法引擎代码及逻辑处理、结果展示、数据推送等业务代码,根据具体业务相关。
- 测试调优:网络性能与精度测试、压力测试,基于网络编译、量化工具、多卡多芯、任务流水线等方面的深度优化。
- 部署联调:将算法服务打包(如Docker)部署到BM168X硬件产品上,并在实际场景中与业务平台或集成平台进行功能联调;必要时在生产环境中调整参数配置并收集数据进一步优化模型。
本次移植已确定具体算法,并且不涉及复杂的业务逻辑,只需要关注【模型迁移】、【算法移植】、【测试调优】,下面会结合具体移植实操,进行展开讲解。
3.1 模型迁移
3.1.1 fp32bmodel生成
3.1.1.1 模型准备
由于官方原生模型默认采用Eager mode(用于构建原型、训练和实验),无法与python解耦,也就是需要依赖YOLOv7源码,无法直接进行模型转换,因此,需要先通过trace进行转换。这里基于官方项目进行:
- 拉取官方代码仓库,安装相关依赖
- 下载原生模型,当前官方仅提供了第一个版本v0.1
- 原生转换为torchscript模型,可以直接采用官方提供的export.py,命令如下:
| (yolov7) root@bitmain-SYS-4028GR-TR2:yolov7# python m models/export.py --weights yolov7.pt |
3.1.1.2 模型转换
下面基于yolov7.torchscript.pt进行模型迁移,采用官方原生的docker环境,通过bmnetp工具实现模型转换,主要转换代码如下:
| python3 -m bmnetp \ |
执行完成后,会在指定目录生成yolov7_float32_1b.bmodel,该工具相关说明可以通过python3 -m bmnetp --help查看,也可以参考官方说明。
3.1.1.3 精度回归
精度回归(这里主要验证转换前后一致性,其他用法详见工具说明)需要依赖BM1684芯片(PICE或者SOC模式均可),并且在【模型转换】时配置了--cmp=true,模型转换完成后,在指定路径下不仅会生成bmodel,还会生成input_ref_data.dat和output_ref_data.dat。
工具采用官方提供的bmrt_test,该工具用法比较简单,执行时会取input_ref_data.dat数据,在BM1684上进行推理,然后比较推理结果和output_ref_data.dat差异,浮点数据差异小于1e-2(可配)即通过:
| bmrt_test --context_dir=模型转换指定路径 |
这里采用yolov7转换后的模型做演示,如下所示,当出现cmp success +++(未报错)意味着精度回归通过:
| root@bitmain-SYS-4028GR-TR2:YOLOv7_object/model# bmrt_test --context_dir=./output/YOLOv7/ |
至此,fp32bmodel模型迁移完成
注:最准确的做法是使用官方验证集进行精度指标统计,这里不展开介绍,待后续放到YOLOv5量化调优 介绍
3.1.2 int8 bmodel
模型量化就是将训练好的深度神经网络的权值,激活值等从高精度转化成低精度的操作过程,例如将32位浮点数转化成8位整型数int8,同时我们期望转换后的模型准确率与转化前相近。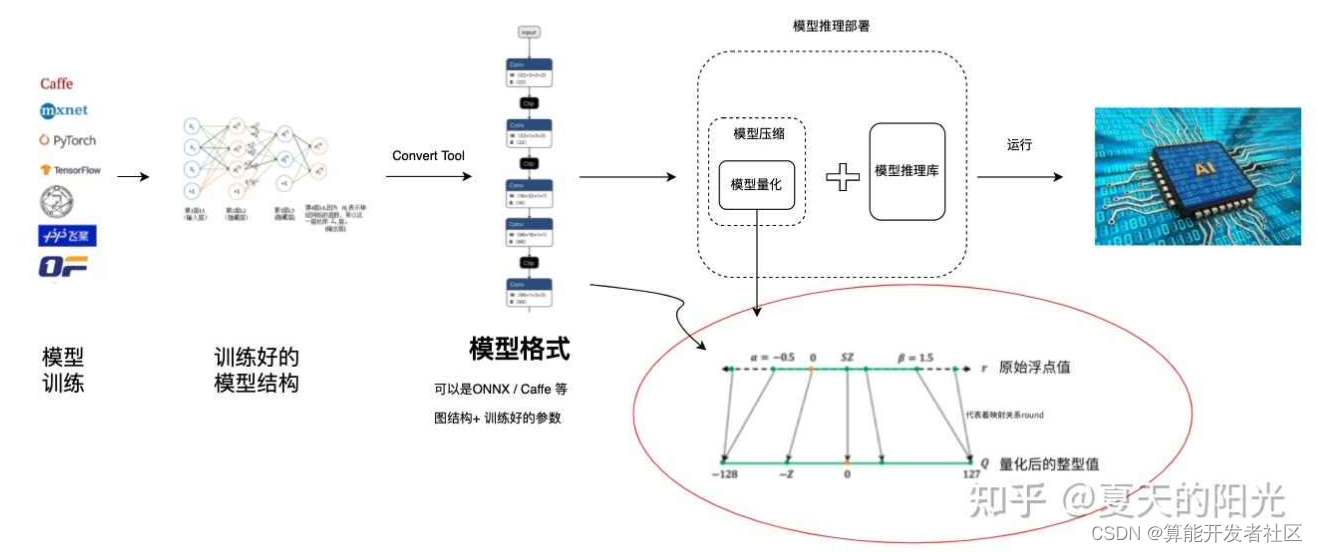
针对模型量化,算能目前支持int8量化,提供一整套Qantization-Tools用于支持模型量化。模型量化相较于fp32模型转换会复杂一些,流程图如下所示:
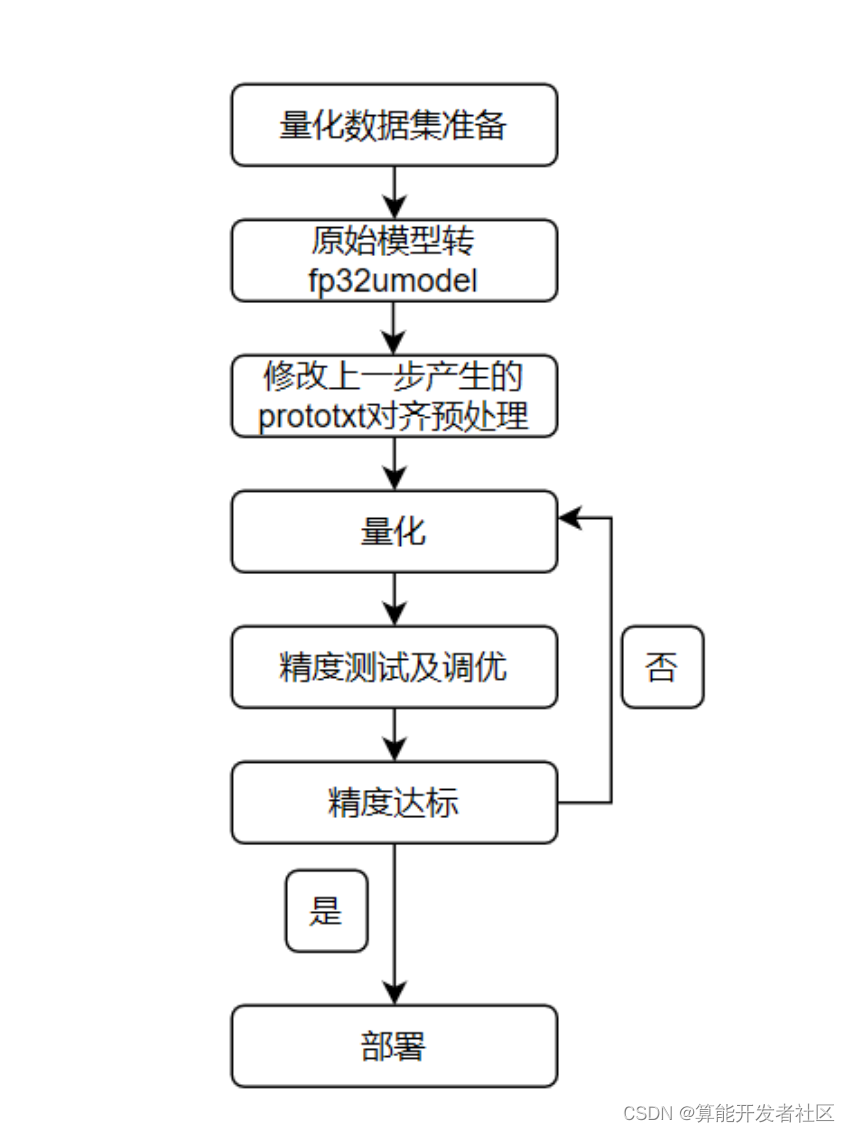
量化流程
3.1.2.1 量化数据集准备
Quantization-tools作为Post-Training量化工具,对已经训练好的float32网络进行量化。此过程需要一定数量的真实数据用float32网络进行推理,推理过程中会统计每层的输入输出数据范围作为量化参考,关于数据集:
- 如果使用一键量化接口,对于常见的CV类推理任务,设置量化图片的路径和前处理会在一键量化的过程中生成lmdb,分步量化的时候可以直接使用;
- 如果简单的前处理设置不能满足需求或者对于非CV类的网络输入可能是各种shape,可以自己制作lmdb。
这里采用自己制作lmdb数据集的方式,基于coco128数据进行处理,参考官方前处理(需要保持一致),主要是等比例加框处理、归一化,将数据集处理成lmdb格式的文件,命令执行如下:
| root@bitmain-SYS-4028GR-TR2:YOLOv7_object/data# python3 convert_imageset.py --imageset_rootfolder ./coco128/images/train2017/ --imageset_lmdbfolder ./ --image_size 640 --bgr2rgb True --gray False |
为了方便查看前处理图片是否正确,防止后期出问题排查成本,可以将加框处理后图片存出后,对比查看,如下可以看出前处理正确:

左图原图,右图预处理后
3.1.2.2 fp32umodel生成
下面需要将基于不同框架的网络转换为float32 Umodel之后进行量化,此过程中可以指定【3.1.2.1】中准备好的数据作为推理输入。 此步骤使用到的工具为ufw.tools.*_to_umodel,部分转换脚本代码如下:
| python3 -m ufw.tools.pt_to_umodel \ |
转换完成后,会在指定目录下生成对应成果物,如下:
| root@bitmain-SYS-4028GR-TR2:YOLOv7_object/model# ./gen_fp32umodel.sh |
3.1.2.3 int8umodel生成
通过一定次数的推理统计和计算量化参数,将float32 Umodel转化为int8 Umodel。此步骤使用到的工具为calibration_use_pb二进制工具或者其python形式接口。该步骤是算法最关键,也是最耗时的一步,后面会专门讲解如何调优,这里就不过多展开阐述。
基于上述前面制作生成的lmdb数据集、fp32umode、prototxt等成果物,进行int8umodel转换,主要包含两部分:
- 对输入浮点网络进行图优化,这一步在【3.1.2.2】中已包含,也可以在此处做
- 对浮点网络进行量化,得到int8的网络及权重文件
这里我们只进行int8的量化,不进行图优化,迭代200次,部分代码如下,工具相关参数可以通过calibration_use_pb --help查看:
| calibration_use_pb quantize \ |
相关执行过程,详见如下部分操作记录:
| root@bitmain-SYS-4028GR-TR2:YOLOv7_object/model# ./gen_int8umodel.sh |
3.1.2.4 int8bmodel生成
量化完成后部署,与float32网络部署类似。使用bmnetu工具将int8 Umodel转换成最终能部署到BM1684相关设备上能运行的int8bmodel。
编译生成int8bmodel的部分代码如下,编译成功后,会在指定目录生成对应成果物:
| bmnetu \ |
相关执行过程,详见如下部分操作记录:
| root@bitmain-SYS-4028GR-TR2:YOLOv7_object/model# ./gen_int8bmodel.sh |
3.1.2.5 精度回归
此步骤可能与量化网络一起进行多轮,通过验证量化后网络是否满足精度或者速度要求,对量化参数进行调节,然后再次量化,达到预期目标。 此步骤使用到的工具为ufw test_fp32/ufw test_int8以及可视化工具,或者多数情况下需要用户自己开发精度测试程序验证精度,这里限于篇幅不做展开,后续会在YOLOv5量化调优 中详述。
3.2 算法迁移
算法迁移部分主要的工作是使用BM1684提供的软件接口,实现原来有caffe/pytorch等框架实现的前后处理、推理等代码,也即是适应具体平台提供的软件接口替换原有不再能够使用/性能效率低下的接口,以此达到迁移前的效果。
这里参考官方源码,实现了CPP/Python版本的算法,并且在Python版本中,分别基于opencv、bmcv实现了两个版本:
| . |
下面,基于Python bmcv版本,做简单介绍,让大家对此有个简单认知,如下是前处理中的部分代码:
| padded_img_bgr = self.bmcv.vpp_resize_padding( |
该前处理主要实现了以下几个操作:
- letterbox:该步骤采用bmcv.vpp_resize_padding接口,替换掉原opencv中resize、copyMakeBorder
- BGR->RGB:该步骤采用bmcv.vpp_resize接口,替换掉原opencv中cvtColor
以点带面,其余涉及到的环节,比如:加载模型、模型推理等,如果不支持(一般都不支持),均需要进行相关接口替换。
四、部署
该步一般需要结合特定业务进行算法封装、部署、测试等,如下是采用量化后模型推理后的可视化结果:
左图官方,右图量化
基于coco2017val测试集,mAP@0.5相较于官方仅下降3.9个百分点:


