
- 1Ubuntu20.04LTS系统CUDA已经安装但nvcc -V显示command not found_nvcc -v 提示未找到命令
- 2电脑中没有vmnet8_vmnet8不见了
- 3鸿蒙系统导航栏,HarmonyOS三方件开发指南(18)-Flexbox流式布局组件
- 4Python中装饰器的写法大全_python装饰器写法
- 5winform html资源文件,Winform中显示HTML(富文本编辑器)
- 6本地同城生活推广投流实战课:通识篇实操篇技巧篇
- 7SSH_Unable to negotiate with ... port ..: nomatching host host key type found. Their offer:ssh-rsa_unable to negotiate with port
- 8传统方法分割三维点云——几何分割_o3d.geometry.trianglemesh.create_cylinder设置
- 9鸿蒙HarmonyOS实战-Stage模型(UIAbility组件)_鸿蒙stage模型
- 10为何大量网站不能抓取?爬虫突破封禁的6种常见方法
浅析分布式系统之体系结构 共识及其相关算法与协议 一致性的实现_pasox协议
赞
踩

共识的本质
共识是人们数千年来广泛使用的用来收敛系统整体状态,对抗熵增的一类工具的总称。共识Consensus )这个词在拉丁语种意味着一致 "agreement, accord",其源自“consentire”本意为“感觉在一起”( "feel together")。广义上讲,共识一般指普遍接受的意见本身(agreement),在社会学以及物理学、计算机科学等学科当中也可以指一个达成一致的过程。从社会学意义来说,在不同层次规模的由多个独立自主的个体组成的民主的组织或社群中,其独立个体对于某个问题的看法可能各不相同的从而造成了不同的提案,为了能将各种不同的提案结果进行收敛,使独立个体对于提案的看法达成一致从而得到代表这个组织的决定,其必然需要某种过程工具使产生代表这个组织的决定成为可能,并且这个能为所有人都接受的目的或需求的决定的提案是由这个过程的参与者来制定的。

而对于现实物理世界来说,由于我们的宇宙是一个熵增的宇宙,熵增定律是宇宙的基本定律之一。(它的物理定义如下:熵增过程是一个自发的由有序向无序发展的过程(Bortz, 1986; Roth, 1993))。作为现实世界的一部分,现实物理世界存在并真实运行的任意物理系统也必然是一个熵增系统。系统的各个实体的状态,必然有概率会由于各种原因随机转换到不符合业务定义的状态,这些不符合业务定义的状态便是错误与失败(即系统熵增)。当组成分布式系统的实体的数量足够多(当代分布式系统的复杂性是显而易见的),这个系统的运行时间足够的长,且缺乏对抗熵增的机制,则这个物理的出现问题的实例必然增多,系统的运行过程必然是一个熵增过程。为了对抗熵增,物理系统不得不采用冗余的策略以提升系统的整体可靠性,这便造成系统的对外的整体的单一状态往往是由多个离散副本实例的状态依据某种规则产生的。所以,为了保持系统的长期稳定可靠,必须使用相应的策略和算法协调分布式系统的各个实体,保证即使有部分实体处于错误或无序状态,系统整体的各个部分的离散副本实例状态仍能收束到某些收敛的符合系统需求与业务规则所需要的状态值之中,从而维持系统整体状态以及执行的正确性,而这些整体状态值便是系统各个离散副本实例需要达成的共识(无论是否有故障)。同时需要主要注意的是,为了实现强一致性,系统需要达成的共识往往不仅仅单个孤立状态,还需要对于这些状态之间的顺序与关系也达成共识。
和任何物理系统一样,在计算机科学的范畴内,故障的同样的不可避免,分布式系统同样需要保证整体其整体对外的运行状态或结果与某种业务需求或功能所定义的状态或结果相一致,不产生矛盾,即系统需要维持足够的一致性。分布式系统由大量的不同粒度的独立离散实例(线程、容器、服务器、集群)组成,然而系统在具体运行时,一般都以一个整体的面貌对外展现,这便需要这些实例在分布式系统的不同层次,多个维度通过某种协调机制达成系统需要的一致性(也就是收敛系统的离散实例的不同状态或结果),从而使这个分布式系统在各个层次对外都能够表现整体的,正确的状态中间信息或结果,并能以此为基础使所需功能的可以整体向前推进执行,并最终正确实现所需的需求。而共识过程正是广泛采用的,实现分布式系统在部分实例有故障的情况下保证系统仍能一致、正确的实现业务需求或功能的一种系统基本的协调机制与工具。在本文上下文中共识是共识过程(consensus process)的简称,一般指在一个有限集合范围内的达成一般意义的意见一致(general agreement)(例如,“以协商一致方式作出决定”和“已达成共识”)的过程。
分布式系统中共识的定义
共识中的涉及的基本角色
基于前述对于共识本质的说明,可以将参与这个过程的每个参与者会被分配以下两个角色中的一个或两者兼而有之:
提案者:有一个特定值并希望其被最终采用的参与者。提案者之间可以相互通信。
接受者、学习者:接受、学习并持久化已经被决定值的参与者,有的过程将接受者中学习部分作为一个单独的学习者角色。
共识的基本属性定义
安全属性(safety property)/活力属性(liveness property)与容错(Fault tolerance)
共识和任何其他程序过程或协调算法一样,其也要符合安全属性(safety property)与 活力属性(liveness property)两个基本原则。与此同时,由于故障、错误与失败也是任何实际分布式系统的本质属性,所以需要将安全属性与 活力属性与容错属性相结合进行综合考虑。通过综合这些原则,可以认为若要得到即使有故障发生,系统的各个实例最终仍旧的能就最终决定达成不可撤销的一致认识的共识协议,需要符合如下四个基本属性:
终止(Termination):每一个正常执行的实例,其最终无论如何都会做出决定(活力属性)
一致(Agreement):每一个正常执行的实例的最终决定必须相同 (安全属性)
完整(Integrity): 每一个正常执行的实例执行决定一次 (安全属性)
有效性(Validity):这个被决定而达成一致的值必须是某一个参与者的所提议的值,若每一个参与者都从相同的所提议的提案开始提交(即只有一个提案),则他们最后的决定也必然是这个提案(如果没有这个限制,则共识决定的值可以是所提议之外的任意值或某一个固定值:例如总是否定无论系统的初始状态是什么。当这种情况发生,这个共识过程所得到结果不会满足系统保证正确性的需要也就没有意义。)(安全属性)
为了实现上述四个基本属性,基于安全属性(safety property)与 活力属性(liveness property)两个基本原则还需要如下限制条件进行保证:
1)安全属性(safety property)限制条件,为保证共识过程对应的算法的一致性,完整性与有效性:
非平凡(Non-triviality):最终决定的值必须是某一个参与者的所提议的值。
安全(safety ):一旦一个值被决定,则没有后续的值会被决定。一次共识过程中决定环节只能执行一次。
安全学习(Safe learning):若一个参与者学习了一个值,则其必须学习的是这个已经被协议决定的值。
2)活力属性(liveness property)限制条件,保证系统能够终止(Termination)即算法过程必然可以最终执行完毕而无须担心系统的状态(例如被死锁或活锁等情况所阻碍):
执行:在一组特定的保持活力属性条件行下,如果有一个参与方给出一个值作为提案,则必然有一个值会被最终决定。
最终学得:接受者可以相互通信,在一组特定的保持活力属性条件行下,如果有一个值被决定,则这个值必然会给参与者学习得到。
虽然安全属性不依赖于活力属性,然而特定的保持活力属性是保证共识过程必然可以执行的基本条件,例如:系统实体之间的通信与执行不能是全部异步(fully asynchronous),至少是部分同步。
同时需要指出的是,对于共识的最终决定的结果可以不仅仅是一个完全确定的值,还可以是一类近似一致的范围值(例如:物理时间同步无法完全杜绝各个物理节点之间的物理时钟的偏差,多个声纳探测的结果总有一个精度差距)。同时,安全与安全学习限制条件以及执行条件未规定必须使用多数胜利的规则选择最终决策值,而且决定的方式与参与者接受的下限(若决定结果是一个近似一致范围的情况下)由与需求相关的有效性规则定义。由此可知对于如何决定选用那一个提案值是没有规则限制的,只需要有一个符合需求的规则即可。分布式系统的共识过程可以依据不同的需求与使用场景基于任意规则选择任意的提案值,而无需考虑是哪一个参与者提出的这个值,提出这个值的顺序以及有多少参与者提出相同的值。
共识的基本过程
共识基本概念
轮次(epoch):由于各种各样的原因(例如:实例故障,网络问题等等),分布式系统在执行共识过程当中,接收者实例往往不可能对于提案只进行一次决定过程就得到最终决定,而是需要进行多次执行。因此,若选择的某一种共识过程乃是基于每次已经执行完毕的决定过程的系统状态记录信息来收敛出最终决定值,从而保证活力属性以及提高过程的执行效率,这便要求系统能够给每一次决定过程(无论是否成功得到最终决定)的系统状态记录都分配唯一的标识(即轮次),而且由于共识过程是基于历次执行的结果进行收敛,所以需要确定各次执行的唯一先后顺序。因此,当整个共识过程完毕后,每一次执行过程唯一的标识组成的集合必须是一个全序集合E(这意味着轮次集合E可以使用完整操作符 以及 =定义),从而使系统在发生(例如:存在并发,消息传递延迟等)各类情况时仍旧能够得到各个执行的统一先后顺序。
提案(Proposal):一个提案是一个轮次与提案值的组合。
界限数字(quorum):在一个分布式系统,当需要执行一个事务中的一个操作,而这个操作被允许执行的条件由各个实例节点投票表决来决定, 则这个投票表决的通过所需的通过票的最小数量则为界限数字(quorum)。
共识基本过程本质上指在一个轮次(epoch)当中多个提案者向一个系统提交多个提案,而系统最终选择其中一个提案做为代表整个的最终决策结果的过程,由此可以将此基本过程分为多个提案者提交提案的过程和接受者接受并确定最终提案过程两个最基本环节。实现共识最基本过程的系统可以由n个实例组成,这些实例的全部或一部分的角色可为接收者、提案者或两者兼而有之。由于是最基本的共识过程,这里假设共识过程接收者(包括两者兼而有之的情况)数量为1(类似单机的情况,或者说学习者和接收者是同一个实例)。在共识基本过程当中,系统于时间维度需要实现将某个接受者提交了一个特定的具体值后的某一时刻作为提交点。在这个提交点之后,某一个由提交者提交的特定值便被最终确定为最后接受的系统状态且在后面过程中不能修改。下面将基于最简单、基本的单接受者共识(Single acceptor algorithm)来对共识的基本过程进行说明。具体过程如下:
1. 对于提案者来说,任意一个提交者可以提交一个候选值 A 并发送消息propose(A)给接收者。然后等待从接受者发送的响应信息,并进行学习。
- candidate A (可配置, 持久化) //提案者可以设置并持久化候选提案值A
- step1: send propose(A) to acceptor // 提案者发送提案候选值A的消息
- step2: case accept(A) received from acceptor //从接受者处收到已经决定的值的消息
- step3: return A //接受者学得了已经被接受者决定了的最终值V=A并返回给实例共识调用方
2.对于接受者来说,这里接收者采用的先来先接受的规则作为提案的提交并决定最终结果的决定规则,即接受者会选择接受到的第一个提案作为最终决定值 并持久化。当这个步骤结束,接受者会发送消息accept(A)给发送这个这个提案的提案者。对于其后收到的其他提案者的提案,接收者由于已经做出决定故而不会再次决定并接受其他提案,并且接收者还会发送同样的已经带有已经被决定的值A的反馈信息accept(A)给他们,从而供这些提案者进行学习。
- acc V: accepted value (持久化) //决定最终接受值并持久化这个值
- step1: while true do //循环接受消息的操作,直到收到消息
- case propose(A) received from proposer //从提案者接收到了候选提案值A的消息
- if V = null then //如果当前决定值为空,则表明这是第一到来的候选提案值
- step2:acc A //依据决定规则:先来先接受,决定候选提案值A为决定值,并持久化下来。
- step3:send accept(A) to proposer //发送已经决定的值为A的消息accept(A) 到各个提案者。
由于接受者基于收到的propose(A)信息进行的决定,所以若信息没有造假,则决定的值必然来自于某一个提案者,故而符合非平凡的要求。若能保证所有accept(A)消息都是来自于接受者,且所有接受者的消息基于唯一接受者的已经持久化的值A, 则每一个提案者学习的值必然是相同的,故而符合安全以及安全学习的要求。若系统符合活力属性,则系统至少有任意一个提交者与一个接受者能够正常运行,且所有的信息在各个实例之间可以最终送达并最终执行(对于传输时间和执行时间长短没有限制)。如此系统可以保证至少在足够的一段时间内这个值可以被提交并被决定,则可以说明这个过程是符合执行与最终学习等执行相关条件的。
这个共识过程只包含了最基本的步骤,此外除了对应接收者数量进行了限制,其对于系统这个接收者的结构以及传输方式都没有做出定义。 选择提案的决定是基于接收者接收到的消息全序采取先来先得的规则做出,当接收者接收到并发操作时的规则则没有进行定义。这个基本过程是一个高度抽象的过程,缺乏实际的工程意义,只对于共识的基本步骤进行了说明,没有任何对于工程实现方面的定义。例如:由于只有单个接受者,所以其具有单点故障以及效率低下的问题:若接受者因为故障而无法运行,则整个共识过程无法进行下去,必须等待它的恢复,因此执行效率十分有限。
系统结构、通信类型与达成共识
共识的基本过程只对于共识的基本步骤进行了定义,对于系统结构的假设也是最简单的单个接收者实例,对于其他具体实现部分并没有给出定义。 前文也描述过,在具体的工程实现层面上述理想化系统没有实用意义的。而实际分布式系统的架构、通信方式、系统故障类型等等维度都会对达成共识的方式与过程有深刻的影响,故而是否所有类型的分布式都能得到合适的共识过程成为了一个需要解答的问题。随着对于各类系统研究的逐渐深入,人们发现并不是所有类型的系统都一定能够通过得到共识并可执行。例如:在基于共享寄存器的同步系统中,不同种类结构原子寄存器可以提供的共识数字决定了多个线程下可以提供的达成无等待共识的能力。而在基于纯异步消息通信的分布式系统中,1985年,Michael Fischer、Nancy Lynch、Mike Paterson三位共同发布了著名论文:Impossibility of Distributed Consensus with One Faulty Process(简称FLP)从而为开发者明确了何种类型的分布式系统从理论上便无法得到一个可达成共识的协调方式(算法),从而免去日后了大量无谓的工作。
基于共享存储同步通信系统与共识
若一个共识需要决定的提案的集合是一个只有两个值的集合(例如:{0,1}或{true,false}),则可以认为这个共识是二进制(Binary)共识。若需要决定的提案的集合的值的数量是大于二任意数量,则可以认为是多值(Multivalued )共识。二进制共识是多值共识的基础,多值共识在某些分布式系统下可以归结到二进制共识。对于基于共享存储的同步系统中无等待共识问题,可以简化为一个输入只有1或0的二阶系统的二阶共识问题。由于任何共识过程都要符合一致性和有效性,所以在并发下,被多个线程同时并发操作的共识共享对象需要线性(符合一致性)的转换为一个由各个线程顺序执行的共识对象,并且提供最终决定值的线程需要先完成其决定(decide)方法来确定具体的值(符合有效性)。故而,基于共享存储的同步系统中的二阶共识问题必然也存在一个关键阶段状态S,即当系统处于这个状态时,如果其有线程继续调用共识共享对象的方法都会将系统状态从二阶状态向一阶状态转化(所有线程二阶状态向一阶状态转化的最终结果(即执行决定(decide)方法的结果)都应该相同以符合共识的一致(Agreement))。
不同种类以及结构的共享对象能够解决的无等待共识的线程数量的限制是不同的。例如:若系统仅使用共享原子读写寄存器,其无法得到超过一个线程的共识过程(所谓的共识数为1)(对于其他共识数字可以参考 多线程下自旋锁设计基本思想 中同步原语部分)。如图1所示,假设线程A和线程B并发基于原子寄存器进行操作,其转换为线性的线程操作顺序的不同可以分为3两个场景:
场景一,线程B先开始,B的操作会使二阶状态向着最终决定值为1的一阶状态S1变化, 而后线程B的操作单独继续执行直到共识过程完成,因而在共享原子寄存器上得到最终输出为1。
场景二,线程A先开始,其会读取这个一个原子寄存器,则由于A的操作,使二阶状态向着最终决定值为0的一阶状态S2变化(图中黄色部分为线程A在线程本地栈中操作,本地操作的结果使共享寄存最终结果为0), 而后线程B的操作单独继续执行(蓝色部分)直到共识过程完成,并在共享原子寄存器上得到最终输出为0。
这里,由于对于线程B来说,当其开始蓝色部分的执行时,由于其只能从共享原子读写寄存器中的得到数据,由于是单个原子读写寄存器,其只能得到当前值,而无法得到之前的变化历史(图中从红色S二阶状态为出发点,有左右两个场景,走不同的线程路径,但是对于线程B来说,其无法分辨当前状态是从哪一个路径的得来的)信息,故而其只能根据当前的值得到最终共识结果,进而其得出最终决定值必然会随着读写顺序变化而变化(而共识要求两个线程的任意顺序都能够达成一致),从而造成系统无法得到共识。

图1
除了上面提到的场景,线程A和线程B也存在现在写入不同的或相同的寄存器的场景,其结果和上面的场景时一致的。
基于本地存储消息传递分布式系统与共识
不同故障类型、通信类型的基于消息传递本地存储分布式系统与共识
在不同的通信方式以及进程类型组成的分布式系统下,系统允许发生的故障不同,则允许容忍失败实例数量为t的共识需系统实例的最小数量是不同的(采用鸽巢原理)。(在浅析分布式系统之体系结构 技术基本目标----一致性(单对象、单操作)也有相应的描述与说明)
| 不同故障类型下基于消息通信的容忍故障数量为t的可以得到共识的本地存储分布式系统所需的最小实例数量 | |||||
| 故障类型 | 通信以及进程类型 | ||||
| 同步 | 异步 | 半同步通信以及同步进程 | 半同步通信以及进程 | 半同步进程以及同步通信 | |
| Fail Stop 失败停止故障 | t | 不存在 | 2t+1 | 2t+1 | t |
| omission Failure 遗漏性故障 | t | 不存在 | 2t+1 | 2t+1 | [2t,2t+1] |
| Authentification detectable byzantine failures 可检测认证拜占庭 | t | 不存在 | 3t+1 | 3t+1 | 2t+1 |
| 拜占庭故障 | 3t+1 | 不存在 | 3t+1 | 3t+1 | 3t+1 |
表1
由表1可以发现在容忍拜占庭故障的分布式系统中如何达成共识的条件的讨论最早可以追溯到 Leslie Lamport 等人 1982 年 发表的论文《The Byzantine Generals Problem》。在可以容忍拜占庭故障的系统中,可以发现当只有三个实例的时候,即使采用同步通信方式,只要有一个副本实例作恶,无论其是主副本还是一般副本,系统中的各个副本实例无论如何都无法基于少数服从多数原则得到共识。之后围绕着容忍拜占庭故障,出现了大量研究,代表性成果包括《Optimal Asynchronous Byzantine Agreement》(1992 年)、《Fully Polynomial Byzantine Agreement for n>3t Processors in t+1 Rounds》(1998 年)等。
在实际的工程实践当中,在最普遍、最可行的场景是在半同步以及同步进程组成分布式系统中基于相应共识过程实现系统的一致性。所以,本文接下来的篇幅主要对于基于半同步消息传递的多副本本地存储模式分布式系统达成共识的方式进行介绍。
基于异步消息传递本地存储分布式系统与共识-----FLP理论(Impossibility of Distributed Consensus with One Faulty Process(简称FLP))
FLP定义回答了在不存在超时上限的异步消息传递下的分布式系统中是否可以存在的问题。FLP的定义:在一个基于可靠消息传递的完全异步的分布式系统当中,只要有一个实例(例如:进程)发生崩溃且这个崩溃不为系统的其他部分所知,则无法得到一个决定性协议来使系统达到共识,即使只是在最简单的1比特集合{b,0,1}(b为实例因没用达到决定状态而输出的初始状态值,0或1为最终决定的决定值)范围内,也无法就其中一个值达成共识。
这个定义对应的分布式系统具有以下相关属性及其定义:
1. 完全异步:完全异步的分布式系统各个实体都是独立运行没有任何同步(包含时钟同步),且对于各个实体运算时间与消息传输的时间没有任意限制(不存在超时)。
2.消息通信:分布式系统使用间接通信,实体之间有着空间与时间上的解耦(发送者和接收者相互不知道对方的存在,接收者不必发送者发送消息的同一时刻存在并接受消息。),相互之间的消息(p,m)通过 一个不做任何决定的消息缓存(例如:各类消息中间件)进转发,转发分为发送与接受两部分组成,发送----将消息(p,m)放入消息缓存,接受-----若从消息缓存得到消息并将消息从缓存删除,则可以认为消息发送成功,否则则返回null值且缓存内消息没有改变。除此以外,只要进程没有崩溃,消息接受虽会被无限延迟,所有消息能被正确传输且传输,语义为恰好一次(没有重复发送)。
3.故障检测:分布式系统中的任意实例(进程)都无法分辨其他实例的当前状态----即实例已经崩溃,或执行的完成速度十分缓慢乃至停滞等。同时,系统的故障类型仅限于无法探知的崩溃型故障(Crash Failure ),本文后面将使用故障代指崩溃型故障,即实例停止,在停止之前正常运行,进程停止运行的原因可能是因为收到了不正确的信息或硬件原因或环境原因(例如:停电)造成。其他类型的故障,例如比其弱的遗漏性故障(omission Failure )直到拜占庭故障等故障,以及比其强的可探知的 失败停止故障(Fail Stop)都被排除在外。

图2
4.可接受运行(admissible run):系统的当前状态变化由消息通信事件e=(p,m)驱动,即事件表示某个实例给另外某个实例发送消息,且消息已经成功送达。由于实例的运行过程本身具有确定性,即当接受消息的实例因为接受了这个消息而执行了某个运算,进而导致这个实例的状态必然会从一个确定状态变化为另一个确定状态,其完全必然是基于这个事件而作出了决定。若因为事件e的信息使系统基于系统当前的状态S产生了新的系统状态,则可以认为这个事件e作用(applied)于系统的状态S。消息的成功接受,实例的状态成功变化以及发送一个消息去其他实例的过程共同组成了一个执行步骤,这个步骤会将系统的状态从前一个实例状态集合得到一个新的实例状态集合。可以从一个系统状态S开始调度有限或无限多个事件(F=(e1, e2, …, ek),F也称为调度(schedule),其中相互关联的事件的组成有限或无限的序列步骤 组成了一次运行(run)(run=(S,F))。
如果这个序列F是有限序列则其运行必将结束,从可以基于系统的前一个S状态得到一个新的状态F(S)也就是所谓的可达(reachable)。 从某些初始状态可达的状态被称为可访问(accessible)的状态,这里假设后面提到的所有状态都是可访问的。另外,由于实例即使没有接受任何消息也是可以执行其他步骤,其等同于事件e=(p,null) 作用(applied)于系统的状态S。 当这个系统中某些实例进入一个决定态(即一旦决定则后续不会改变),则说明这个这个系统的状态含有了决定值。一个实例如果在一次运行(run)中,其每一步总是正常执行(无论步骤数是否有限)则认为没有故障,反之则认为这个实例发生了故障。如果这个分布式系统的某次运行时至多有一个实例出现故障并且所有非故障实例都最终接收到了向这些实例发送的消息,则这个运行是可以为系统所接受的(admissible)也就是可接受运行(admissible run)。此外,只有这个运行当中某些实例遵循共识特性最终做出了决定,才可以认为这个实例提供了决定,如果这个运行当中没有实例达到某最终决定状态,即没有实例最终做出决定,则这个可接受运行不是一个决定性运行。

图3
5.系统状态(FLP论文原文称为Configuration):若将一个具有上述属性的分布式系统看作一个状态机,系统当前状态S由各个实例的当前状态、消息缓存内的当前内容组成。初始状态(initial configuration state)由各个实例的初始状态、消息缓存为空的初始状态组成。各个实例的初始状态可以不同(系统实例初始状态处于任意状态)是系统开始执行共识过程进行的基础,在共识执行的过程中系统状态会基于各个执行步骤不停的变换,直到系统的所有实例达成一致。
状态S可以决定的提案的范围是最简单的1比特集合{0,1}(0或1为最终决定的决定值)。若系统的实例达到决定态(Decision state)只能有一次机会,一旦决定则无法更改。如果有些实例 已经处于 决定态即实例输出值为v,则系统整体状态决定值(Decision value)为v。另外需要指出为了保证足够泛化,FLP对于系统基于何种规则来整体决定值v没有任何定义。
1)若系统当前状态S的某些实例已经决定为{0,1}其中一个决定值或从其出发可达的状态的决定值的集合的数量为1(即只包含决定值{1}的实例或只包含决定值为{0}的实例)则此状态是一阶(univalent)状态,或从这个状态出发的可访问的所有状态必然都是一阶状态(由于一阶状态S中部分实例已经决定最后的决定值且无法更改,从这个状态S出发的所有一阶状态的决定值必然与出发状态S决定值一致,否则这个状态S的决定值范围可以为{0,1}中任何一个而成为二阶状态值,这与一阶状态定义冲突)。

图4
2)若系统当前状态S本身实例都没用达到决定态,或从其出发可达的状态的决定值的集合的数量为2(即同时包含决定值{0,1}内所有值的实例)则可以认为初始状态不确定,这个状态是二阶(bivalent)状态,且若从这个状态S开始的可访问的某些状态是一阶状态,则这些一阶状态的某些是决定结果值是0(0-valent)而其他决定结果值是1(1-valent)。
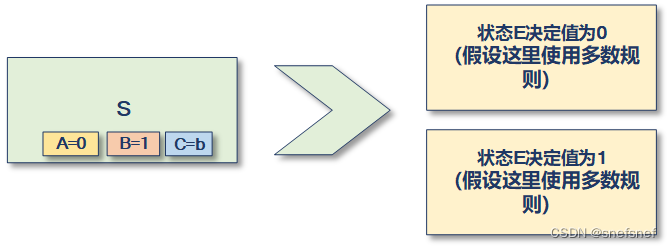
图5
6. 交换性(commutativity):假设将一个具有上述属性分布式系统中实例集合由为若干个没有交集的子集(例如:一个集群由5台实例A、B、C、D、E,其中A、B组合为一个子集V,C、D、E组合为另外一个子集W)组成。基于这样的分布式系统可得如下引理:这个分布式系统的当前是某实例状态集合S,若执行两个不同的事件序列步骤F1,F2,则会分别进入两个不同的新状态S1,S2。若这个分布式系统中的子集分别执行了步骤F1和F2,从状态S出发先执行F1可得状态S1,然后基于状态S1执行F2可得状态S3。同样的若调整测序,若其中S先执行F2可得S2,然后基于S2执行F1可得相同的状态S3。
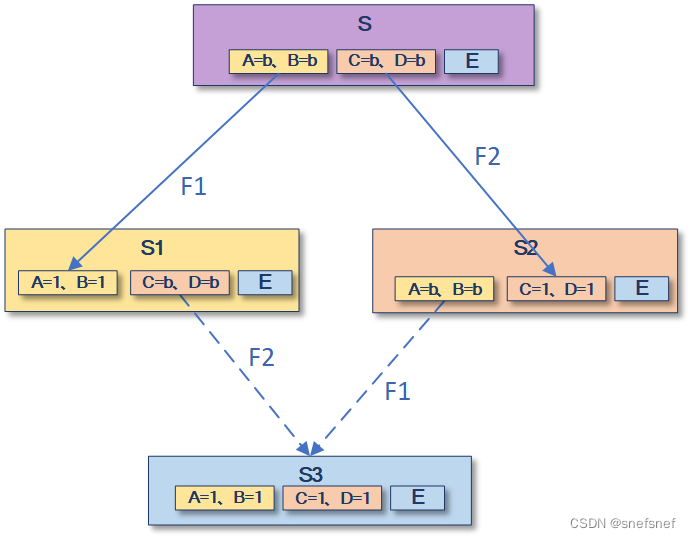
图6
具有上述性质的一个分布式系统得到一个完全正确的共识过程需要满足以下条件:
1)若系统中某些实例的到达决定态(即已经完成最终决定),则系统的状态必然包含决定值,以此为基础系统若要实现部分正确的共识需满足以下两个条件:
- 系统所有可访问的状态集合不能含有多于一个的决定值(最终决定值只能有一个,安全属性:完整、一致性)。
- 对于每一个决定值(决定值都来自于一个最简单的1比特集合{0,1}(即各个实例的最终决定值都来自于这个集合)),某些可访问的系统状态包含决定值(安全属性:有效性)。
2)若尽管有一个实例发生了故障,分布式系统采用的共识协议只要能够保证部分正确的并且这个系统中的每一个可接受运行(admissible run)都是一个决定性运行,仍旧可以认为这个共识协议是完全正确的。(活力属性:终止)
对于FLP的定义来说,若能证明符合部分正确的共识且具有上述性质的分布式系统无法保证第二点,即系统的实例集合在运行的过程中必有永久无法得到决定值的实例的运行存在,则说明这个分布式系统从理论上就不可能得到一个完全正确的共识协议,因为无论何种共识在这个系统当中都会出现永远无法做出决定情况。基于以上思路,可以将FLP的证明分为两个步骤:
步骤1:证明引理1:参与共识的系统必然具有某不确定性的初始状态。
步骤2:基于步骤1的引理,可以构建出一个可接受运行(admissible run),且运行中的任何步骤都不会使系统做出特定的决定。
步骤1的证明
假设实现共识的分布式系统具有预先决定执行能力使系统所有实例的所有可能的初始状态(即初始实例状态集合)都是一阶(univalent)(即确定)状态,即都是决定了的状态,则基于部分正确共识所具有的有效性属性,系统在每次执行共识后的状态必然只能由这个各个实例的初始状态的值的集合所决定。若随着系统运行各个实例的状态而发生变化且系统多次使用这个共识,则会使共识决定结果随着初始状态的变化而发生变化,各次共识决定值会有的为{0},有的为{1}。 通过将共识执行时各个不同的初始化状态集合的所有可能组合进行排列,可以组成一个环(发生重复组合即为环的开始与结束)。在这个环中,若将只有一个实例状态不同的系统的两个状态称为相邻(adjacent)状态,可以发现无论何种排序方式,则必定存在系统的两个一阶实例状态集合S0和S1相邻,并且基于S0执行共识的决定结果为“1”,而基于S1执行共识决定结果为“0”。这意味着系统存在两次使用共识得到决定结果会由于两个状态集合中只有一个实例状态不同而不同。由于系统允许一个实例发生故障或某种原因长时间没有响应,则在系统状态S0中,这个实例必然是唯一状态不同的实例。由于此实例将无法发送与接受任何消息,故而它的状态初始状态也就不能为其他系统所得知,从而对其他实例来说其处于二阶状态,在这种缺失一个实例状态的情况下系统基于当前状态仍旧要保证有一个运行(run)要得出决定“0”。问题是,若同样的事情也发生在了系统状态S1之中,即发生故障的实例是同一个唯一状态不同的实例,然而这时系统却要在相同的系统状态下的情况保证有一个运行(run)要得出决定“1”。由于状态集合S0和状态集合S1只有一个实例状态不同,且对其他实例来说现在这个实例因为没有任何消息而从这两个状态集合中被排除,故而两者剩余的实例组成的状态集合(系统状态)必然是相同的。而以这两个系统状态为出发点执行步骤和逻辑都是一致的运行却可能得到不同的结果,这与一开始的假设系统在每次执行共识后的状态必然只能由这个各个实例的初始状态的值的集合所决定是相违背的。这个悖论说明,如果有一个实例发生故障,系统的共识的执行的得到相同的结果变有可能会有“0”或“1”(不确定性)的情况的出现,即使系统执行共识的初始系统状态为确定的一阶系统初始状态。同时,由于故障所造成的悖论,也揭示了系统初始状态(初始实例状态集合)为双阶(bivalent)状态的存在可能性(两个实例状态一致却可以得到不同的共识结果,说明决定数为二,其为二阶状态), 以及基于异步消息分布式系统的本质特征:系统执行共识得到最终结果并不是完全基于系统初始状态而是依赖于故障的类型以及异步消息传输的可靠性等其他因素。
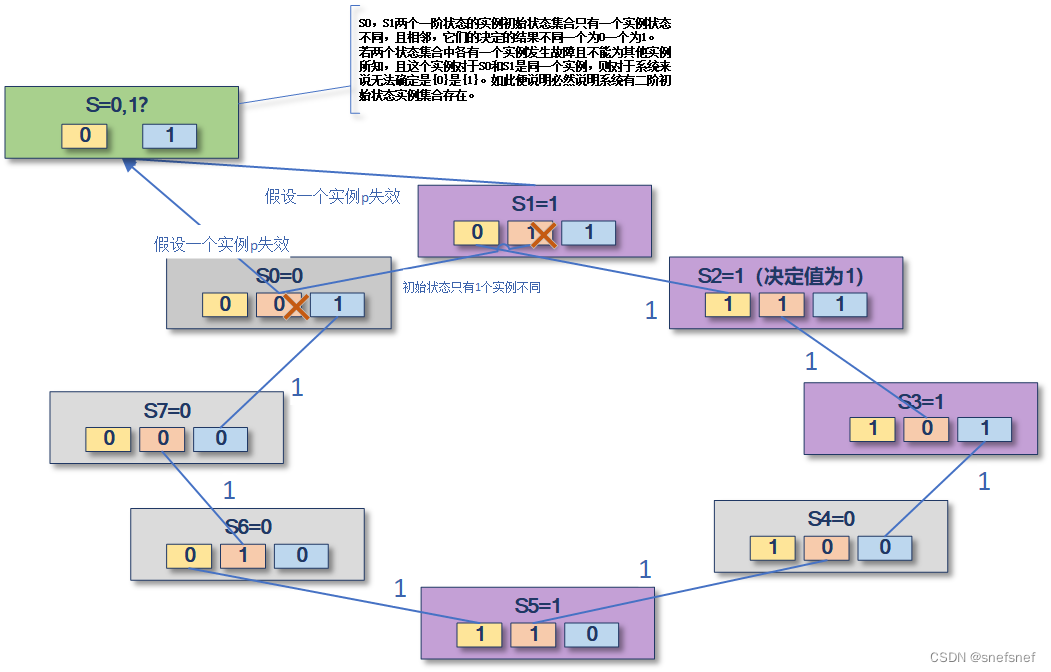
图7 基于三个实例组成的分布式的示例
步骤2的证明
步骤二证明过程和前面的证明方法一样使用反证法来证明,若状态集合D不包含双阶状态集合(即不存在不确定的状态集合),会引出一个悖论。基于步骤一证明了的系统初始状态为双阶(bivalent)(不确定)状态的存在,在步骤二则是在这个结论的基础上证明引理二:无论系统使用何种共识,其基于不确定的二阶系统状态作为执行的起始点,且有一个消息可作用于这个状态集合,那么从这个二阶状态集合开始,由任意顺序的消息作用(applied)于这个集合并由此产生的可达的状态集合的集合中仍可能会包含有至少一个二阶状态集合(即从系统会因为一个消息的丢失或延迟的足够长而造成 一个二阶系统状态(同于不确定状态)转到的下一状态仍旧是一个二阶系统状态进而有可能使系统进入一个无限循环从而使这个系统永远无法做出最终决定从而得到共识)。这里的任意顺序的消息可以理解,因任意数量消息任意延迟造成的消息传递的任意的顺序变化,而使一个系统的最终状态仍旧为双阶(bivalent)(不确定)状态成为可能。
步骤二证明需要涉及如下定义:
集合S:系统的初始状态为实例双阶状态(不确定)集合。
事件e:事件e=(pm)为可作用于集合S的某些事件
状态集合M:从状态集合S出发,其为所有不因系统接受到了事件e(例如:可能是其他消息e1或其他步骤)而达到的系统状态集合(E1,E2......Ek)。
状态集合D:从状态集合M出发,其为所有因消息事件e作用的,可达的状态集合( F1,F2....Fk)。
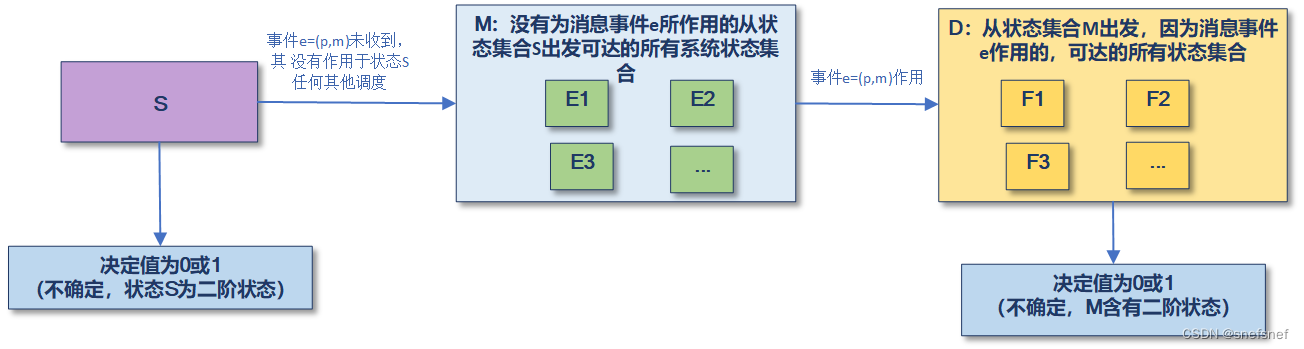
图8
具体证明过程如下:
由于是基于异步分布式系统,故而事件e到达系统的时间也是任意的。假设这个分布式系统初始状态为双阶(bivalent)(不确定)状态S,而集合D只能包含一阶状态集合。
首先来看对于系统实例变化,由于系统要达成共识,假设事件e的到来将促使系统的各个实例必然由二阶状态向一阶状态转化(达成共识的关键)
1)当事件e到达系统的实例时,系统状态初始S已经变化,系统状态初始S可能已经因为其他事件或执行其他方法转变为任一状态Ek(k为其他事件或步骤的执行数k={0....n}),将这些Ek状态并归类到状态集合M。
若Ek为一阶状态(例如:图9中的E1),(若这个系统状态Ek的得到决定结果为“0”,系统状态Ek=0。反之,系统状态Ek=1)。假设此时系统的状态是Ek且决定值是0,事件e必然会作用于状态Ek,并基于此消息产生了新的决定值为0属于状态集合D系统一阶状态Fk(依据一阶状态的定义Fk的决定值必然为0,因为Ek0的部分实例已经决定为0),Ek决定值是1的过程也是一致的,只不过其产生的是决定值为1的属于状态集合D系统一阶状态Fk。
若Ek仍旧为二阶状态(例如:图9中的Ei),则在集合M中必然会找到两个互为邻居的状态Ei和Ei+1,Ei+1的结果是由Ei执行单个步骤(假设接收到另外一个事件e1=(p1,m1),Ei+1=e1(Ei))得到 。事件e可以在系统处于状态Ei或Ei+1时作用于系统,并得到各自对应的一阶状态Fi以及Fi+1。由于状态Ei或Ei+1为二阶状态,故而状态Fi的结果可以为0而Fi+1的结果可以为1。依据前面的定义状态Fi和Fi+1都属于集合D。
2)当事件e直接作用于系统状态初始S,由于S也是二阶状态,则可以直接得到属于集合D的一阶状态Fk(例如:图中最右侧的F1),并且可以通过Fk再次通过其他步骤得到一阶状态Ek。
从上面的状态变化可以发现,从二阶状态S出发,状态集合D必然会同时包含决定值为1与决定值为0的一阶状态。
接下来通过观察事件e和事件e1,来检查上述的系统实例状态变化以及集合D只包含一阶状态假设是否成立。
1)当系统为二阶状态Ei(icommutativity)(图9的中红色实例部分),可以知道所有实例各自接受到各个事件没有变化,只是走不同的事件传播路径会使实例收到事件的时间点不同而已,所以系统实例最终状态应该为Fi+1且结果为1。故而依据交换律,则由Fi0决定值为0的状态开始,应该可以通过接受事件e1生成决定值为1的状态Fi+1。但是,这与一阶状态的基本定义(即一阶状态S出发的所有一阶状态的决定值必然与出发状态S决定值一致)产生了矛盾,说明D必须包含二阶状态(例如:图9中的Fi),否则一阶状态的基本定义不成立。
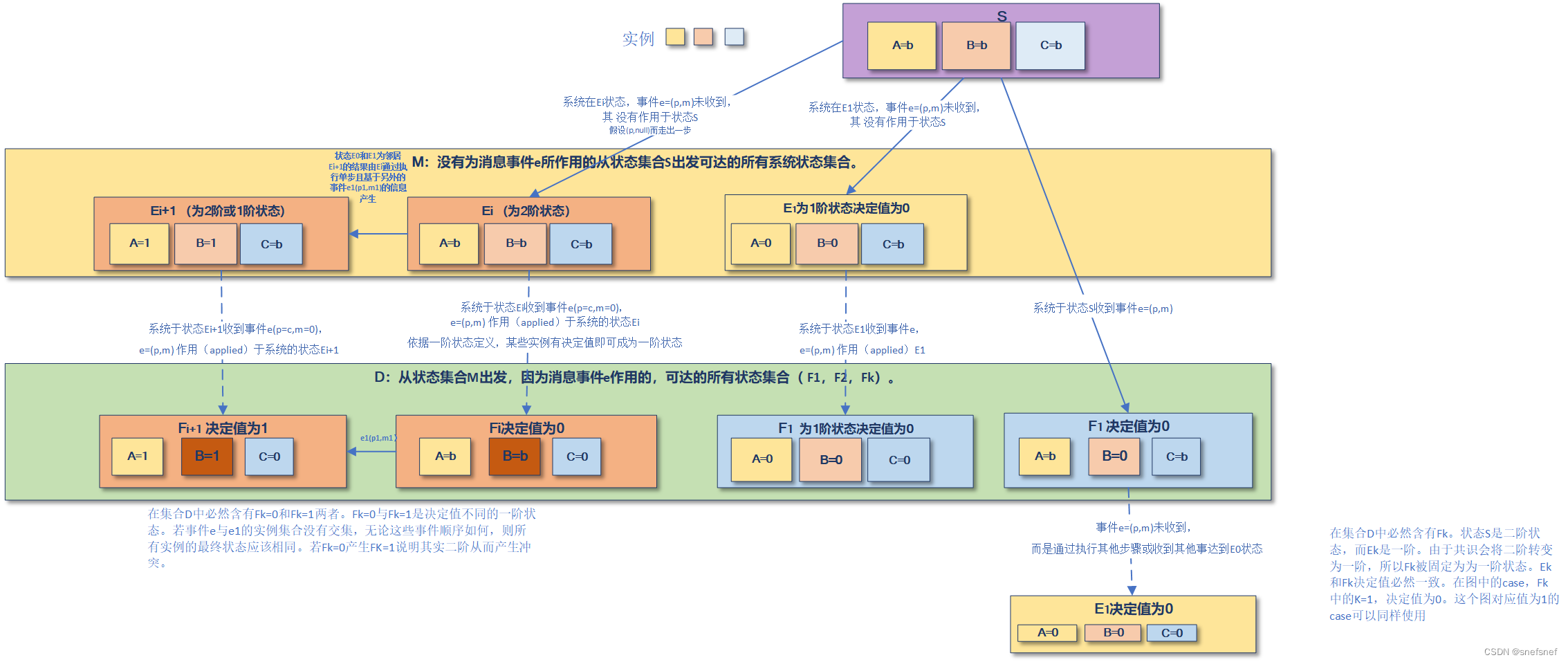
图9
2)当系统为二阶状态Ei(icommutativity)不再适用。若从状态Ei 出发而此时作为交集的实例因故障而没有发送任何消息,且系统基于这个状态的后续的一个运行(run)是决定性运行F,则会产生一个一阶系统状态Ai=F(Ei),Ai应该属于集合D。同样由于实例的故障的存在,此时系统又开始符合交换性了。由于Ei是二阶状态状态所以从状态Ei出发必然可以通过交换性得到两个最终决定结果不同的系统状态Gi。由此基于交换律可以发现状态Ai必然是一个二阶状态,否则状态Ai无法既可以通过e(e1(A)) = Gi,Gi=1 ,又可以通过e(A)得到决定值为0的Gi。由于状态Ai又不可能即是一阶的又是二阶的,则说明D必须包含二阶状态Ai,否则会造成悖论使交换性不成立(即决定性运行F不可能存在)。
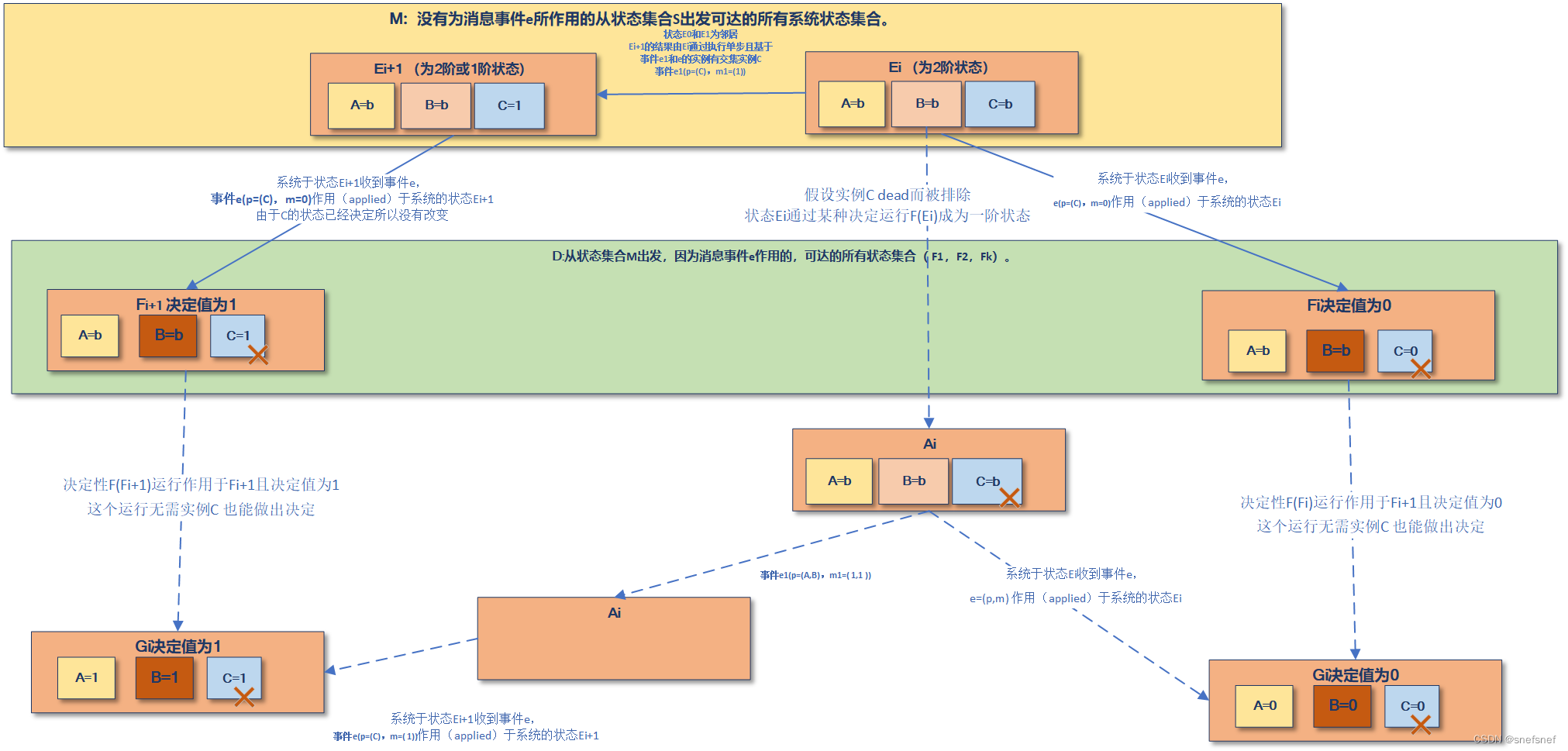
图10
上述证明说明了无论e=(p,m)事件和事件e1=(p1,m1)中实例是否有交集,若有故障出现,集合D必然包含二阶状态。
下面来说明在一个共识过程中, 集合D中包含二阶状态情景是否可能每次都发生直到永远。若这个分布式系统的初始状态为二阶状态(不确定状态,引理1已证明)S,并保证其之后的运行到达的状态都是可访问(accessible)的,系统实例接受的顺序和事件被发送的顺序一致,采取先发先到原则。
假设这个分布式由多个实例组成,实例p是这个系统中的第一个会收到事件的实例(例如:这些实例排成队列,而这个实例排在第一) 。分布式系统的的共识过程从二阶状态S开始,每一次共识过程为一个轮次。若事件 e = (p, m)(m可以是任意值包括null)是这次共识过程轮次中第一个到达这个分布式系统中实例p的事件 ,由于状态S是二阶的,所以通过引理二(图10、图11的右侧部分),可以得到二阶状态Ai。同样基于引理二,通过状态S可以得到另外一个二阶状态Ei+1,而事件e可以是最后作用于它的事件(图10、图11的左侧部分),同样可以得到二阶状态Ai。若这个顺序永远继续下去,则这个共识过程便会永远无法达到最终的一致,从而完成证明。
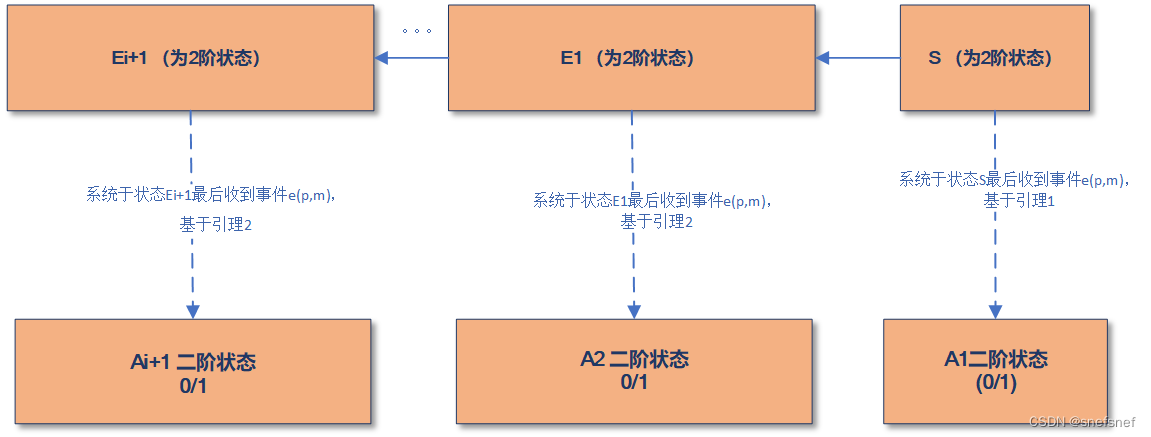
图11
需要注意的是FLP只是证明了在何种类型的系统中无法得到一个共识,这并不意味着所有的分布式系统都无法得到共识过程。FLP定理让人们了解到对于完全异步分布式系统来说,若想设计同时确保共识的安全属性、活力属性以及系统保持故障忍耐性且符合确定性算法(即具有给予相同的输入总是给出相同输出结果且系统总是经历相同的状态顺序的性质的算法)原则的共识算法是不可能的,安全属性和活力属性故障忍耐性三者无法同时得到。而在采用其他通信类型的分布式系统下,设计出同时具有这三者的符合确定性算法的共识有可能的。

图12
这也意味着在异步分布式系统中,为了得到合适的共识过程,可以通过部分舍弃安全属性和活力属性与故障忍耐性三者中的一个或放松对于完全异步通信的限制(例如:设置通信超时机制,使完全异步分布式转为半同步分布式系统的方式),或基于概率1(Probability 1)算法(通过一个符合需求的概率来确定系统的下一轮共识执行是否会强制得到决定值)来确定决定值从而保证系统的决定值的收敛(不是如同一般分布式系统,其都是基于决定性算法)的方模式或分布式系统故障实例可以被探知等模式来设计分布式系统的架构以绕过FLP的限制,而基于这些模式设计的架构中最常见的莫过于基于多副本本地存储模式分布式系统了。
基于半同步消息传递的本地存储模式分布式系统达成共识的方式
广义上来说互联网虽然是一个纯异步的消息通信系统,然而由于可以通过前述方式对于局部网络进行改造,得到适合某些共识过程良好执行的系统环境,从而绕过FLP的限制。人们提出了各类受限环境下的分布式系统共识过程用于生产实践,下面就最常见的是半同步消息传递的多副本本地存储模式分布式下的单值共识与多值共识进行介绍。
多副本本地存储模式分布式系统
由于系统故障的不可避免,本文开篇涉及的冗余方式便是应对应对故障并实现高可用的基本设计思想之一,而且其天然契合本地存储模式。基于同步或半同步通信模式的多副本本地存储模式系统设计是也成为了能够容忍故障并支持相应一致性需求的最基本最常用的分布式设计模式之一。其中对于以数据为中心的多副本本地存储实例分布式系统(例如:分布式数据库系统或分布式锁等系统来说)来说, 可以将其看作某类有限状态机。基于各个副本间不同的信息复制机制设计,可以将多副本模式分为俩个大类:主动复制副本(Active replication)与被动复制副本(Passive replication)。
主动复制副本:也称为状态机副本复制(state machine replication),即每一个副本运行一个独立的确定性状态机,所有的副本以相通的顺序运行相通的操作。客户端的操作可以发送到任何一个副本。主要的过程如下:
1) 客户端各自提交到操作请求消息到系统中的所有的各个副本实例 (图中的op1 以及op2 in Fig. 2a).
2) 各个副本实例的起始状态都相同,且都通过相同的顺序接受到了操作请求。
3) 各个副本实例都会将相应响应返回给各个客户端。客户端由于会收到多份相同的响应,因此只会读取最先收到的响应。
如果要保证系统的较强的一致性例如:线性一致性,则各个实例会按照相同的顺序收到操作请求,并按照相同顺序执行这些操作请求消息。(对于不同的一致性的介绍,具体可以参见浅析分布式系统之体系结构 技术基本目标----一致性(单对象、单操作))
被动复制副本:也称为主备份(primary backup),即只有一个备份实例运行确定性状态机,其他备份实例仅拷贝主备份实例的状态。主备份实例通过运行操作计算出一系列的新的状态,并依据状态的产生顺序发送并复制这些状态到各个备份实例。客户端的操作需要发送到主备份。
1) 所有客户端只会将操作请求消息发送到主副本实例(即leader)
2) 主副本实例负责操作顺序并计算出相应结果,转变自身状态到新的状态,并返回响应回客户端。
3) 主副本实例按照状态产生变化的顺序将自身的新的状态传播到 各个副本实例。
4) 主副本实例只有这个响应对应的系统级别的副本状态变化被成功决定后才能(各个副本达成共识) 返回响应回客户端。

图13
依据此类系统的使用需求与场景的不同,系统对于数据或系统状态的完整性、正确性要求也会各不相同,这也导致了系统所需的一致性各不相同。若这类系统对于随着时间的流逝而不断变动的数据或系统状态的完整性、正确性有较高的需求,这便意味着多副本模式系统需要能够实现在具有非拜占庭故障的情况下,任意时刻维持线性一致性,即系统能够在数据维度和时间顺序维度符合线性一致性的要求。
基于半同步消息传递的非拜占庭多副本本地存储分布式系统单值基本共识过程----朴素Paxos
由于处理分布式系统中拜占庭类型故障的实现复杂性,且工程实践中大量的分布式系统并不运行在公共网络之上,而是处于私有网络或者说私链的范围之内,系统的实例都处于强监管的状态, 因此可以假设多副本本地存储分布式的故障仅限于副本实例的崩溃,不会有作恶副本实例出现。朴素Paxos是这类系统中处理故障的最经典的方式之一。朴素Paxos又称为经典Paxos,由Lamport于1998年提出,其为基于执行有序轮次,序号的最大值以及界限数字(quorum)对于系统的操作、数据等维度进行收敛,从而得到最终决定值一类算法的代表性算法。其可以容忍少于界限数字(quorum)的接收者节点实例发生故障。Paxos算法的最为基本过程与形式为可以从一个部分(partial)同步的分布式中提供得到单个最终决定值的朴素Paxos算法。在最好的情况下,使用朴素的Paxos算法可以在两轮过程运行完毕后,使大多数接受者实例能够达成唯一的一致的决定值。
朴素Paxos所需Quorum
Quorum的本意为会议的(最低)法定人数。在计算机系统中,是一种分布式系统中常用的,用来保证数据冗余和最终一致性的投票算法。在朴素Paxos中,为了保证系统的接受者集合只能最终批准一个决定值,基于鸽巢原理,其采用的Quorum为超过全部接受者实例数量的一半(假设接受者实例数量为n,则界限数字应该等于n/2 + 1),这样可以保证若出现两个超过界限数字的接受者集合出现(即若系统由于故障等原因单次投票并不能得到最终决定值而必须多次投票),则必定至少有一个接受者实例为公共实例,从而可以发现最终批准的决定值超过1个,违反了最终批准一个决定值的限制。
朴素Paxos的主要流程简述
朴素的Paxos算法中得到最终决定值的过程和现实中人们达成共识认识的流程有一定的相似之处,整体过程分为3个阶段:
第一阶段(提案准备)
第一步:一个提案者S1决定提交一个提案并让分布式系统的各个实例基于这个提案的信息达成共识(共识过程得到最终决定值必须只属于 proposers 提出的提案范围之内,以符合上面提到过的属于安全属性的非平凡(Non-triviality))。同时,它需要做如下的准备:
1)由于这是进行一次决定过程的开始,提案者需要得到一个唯一的轮次标识e。
2)基于唯一的轮次标识,提案者生成消息 prepare(e),并发生到接受者集合。
- //提案者部分执行逻辑
- //所需变量声明
- n //接收者实例数量 (configured, persistent) //初始化基本变量
- e=null //当前轮次唯一标识
- //执行逻辑
- send prepare(e) to acceptors //生成消息 prepare(e),发生到接受者集合
第二步:当接受者集合中的各个接受者收到消息 prepare(e)后,各个接受者基于自身的当前状态信息进行以及消息prepare(e)并基于如下规则进行相应的逻辑执行。
1)若接受者基于自身的当前状态信息中未包含任何轮次标识,则轮次标识e为这个实例第一次收到的消息,则将之持久话,作为实例新的状态信息,同时生成消息promise(e,null,null)并返回给提案者。
2)若接受者已经接受过提案,则会做如下操作:由于自身的当前持久化状态信息(字段epro)中已经包含当前prepare之前最后发送的promise对应的轮次唯一标识(假设值为b),接受者会进行比较,若当前消息中轮次标识e的值大于或等于已经持久化的轮次标识epro的值b,则可以认为轮次标识e在这个接收者最后接受的轮次(存储在字段eacc)之后发生(基于全序),由于所有接受者需要以最新的提案作为决定依据(有限全序集合最大值必然唯一,从而使各个接受者做出决定所基于的轮次唯一标识可以收敛),所以其会将轮次标识的值e 进行持久话(更新字段epro),并将轮次标识值e,轮次标识值eacc及其对应的决定值vacc组成消息promise(e,eacc,vacc)并返回给提案者S1。
- //接收者执行逻辑
- //所需变量声明
- epro//持久化当前prepare之前最后发送的promise对应的轮次唯一标识
- eacc//持久化最后接受的轮次唯一标识
- vacc//持久化最后接受的决定值
- ================
- while true do
- switch do
- case prepare(e) received from proposer //接受消息prepare(e)
- if epro = nil || e ≥ epro //第二步规则1或规则2
- epro=e //持久化轮次标识的值e
- send promise(e,eacc,vacc) to proposer //将轮次标识值e,之前持久化的轮次标识值eacc及其对应的决定值vacc组成消息promise(e,eacc,vacc)
第三步:由于提案者实例S1已经收到了promise消息,接下来其需要选择出这次提案所需的值。其将遵循如下规则:
1)若在第一阶段收到的promise中没有包含任何已经接受的提案值,则说明提案者可以选择任何值作为提案值(例如:系统刚开始进行第一次共识)。
2)若在第一阶段收到的promise中只包含一个已经接受的提案值,则说明提案者需要选择这个值作为提案值。(符合前面描述过的安全属性中有效性)
3)若在第一阶段收到的promise中包含超过一个已经接受的提案值,则说明不同的接受者做了不同的决定值,提案者需要选择轮次最大值对应的被接受的提案决定值作为其提案值(这保证了轮次是单调递增的,进而保证了安全属性以及向某些提案决定值收敛)。
一旦提案者S1实例收到消息promise(e,null,null)或消息promise(e,b,v) 的数量大于或等于Quorum数量的要求(例如(n/2+1)),且提案者实例S1选定了提案所需的值,其会将选择的提案所需的值与轮次值e组成提案propose(e,v),并发送给各个接受者,则认为可以开始进行裁决,则进入第二阶段。否则,一旦到了这个提案者实例的等待消息的时间超过超时的上限,则这个提案者将认为当前轮次,无法开启裁决并得到最终决定值需要重试,其会基于一个更大唯一的轮次标识f的开始一个新的轮次,重新开始第一阶段。
- //提案者部分执行逻辑
- //所需变量声明
- Qp //接受到的接受者发出的promise的数量
- Qa //接受了决定值的接受者的数量
- emax //在第一阶段中已经被接受者的接受提案对应的最大的轮次唯一标识
- Set(promise)//集合
- Set (accept) //集合
- v=null //当前提案决定值
- //提案者执行逻辑
- while Qp < n/2 + 1 do //是否到达到符合Quorum数量要求
- switch do
- case promise(e,eacc,vacc) received from acceptor a //从某个接受者a实例中得到对应
- Qp=Qp+1
- Set(promise).add(promise(e,eacc,vacc)) //接受promise并放置于集合
- if eacc != null && (emax =null|| eacc>emax )//寻找(eacc,vacc)当前已经被接受的最大的轮次唯一标识对应的决定值
- emax=eacc, //更新已经接受最大轮次唯一标识为当前提案的轮次唯一标识对应的最后接受的轮次唯一标识
- v=vacc //选择轮次最大值对应的被接受的提案决定值作为其提案值,
- case timeout //未收到达到符合Quorum数量要求,且接受超时
- goto 第一阶段第一行代码 //本轮的执行认为失败
- //执行逻辑选择最新的已经被接受过的值
- if v = null //若没有收到过任何提案
- v=r //提案者指定任意值r,基于具体业务逻辑
- //将提案所需的值与轮次值e组成提案propose(e,v)
- //进入第二阶段
- send propose(e,v) to acceptors

第二阶段(开始裁决)
第一步:每一个接受者收到了提案propose(e,v),其需要依据以下规则来接受提案中的决定值从而使提案者得以判断系统已经得出最后的决定值。
约束1:若接受者从没有接受到任何提案则其必须接受第一次收到的提案。这是因为由于要符合安全属性(即使所有得接收者都有接受值处于确定状态,从而使系统得以进行基于Quorum数量得终决定值裁决),所以若其从没有接受到任何提案则其必须接受第一次收到的提案。这个是约束并不完备(例如:接受者实例数量为偶数,而一半接受的提案具有值v,而另一半接受的提案具有值u,无法达到Quorum数量的要求,或者接受者、提交者因为故障恢复造成提案丢失等情况)。为处理上述情况并符合安全性,所以需要加强这个约束1,从得到了接受者的约束2。
约束2:一个含有决定值 v 的提案被决定(即接受这个决定值的接受者实例达到了Quorum数量的要求),那么之后的接受者实例可以接受的提案必须具有决定值 v(暗示相同决定值的提案可以多次被接收者接受,只需要保证轮次标识变大,这同样也是为了保证将来所有提案符合安全属性。前面已经阐述过轮次是单调递增的全序集合,所以之后的提案的轮次必然大于前面的轮次)。这个约束针对如下场景:分布式系统由于自身限制(例如:故障、通信中断等等)造成某些 提案者和从未接受过提案的接受者无法工作,而当一个 决定值v 已经被决定后,若此时一个提案者和一个从未接受过提案的接受者从故障中恢复,且前者提出一个具有新的决定值w的提案,依据约束1则这个从未接受过提案的接受者必须接受这个提案值。这与约束2产生了冲突。由于接受者是被动的接受提案,所以需要对提案者的行为进行约束,即一个 决定值v 已经被决定后,任何一个提案者的提案包含的决定值必须具有决定值v。由于仅通过提案者很难找到实际的手段直接实现约束2,例如:故障中恢复的提案者并不知道当前的系统状态也就无从得知是否有决定值v需要包含在其当前的提案中。因此需要接受者通过轮次唯一标识作为辅助信息,并结合提案者提供的提案的决定值来进一步加强这个约束使之具有可行性,从而得到了约束3。
约束3: 基于约束2得场景,由于决定值 v 的提案已经被选定,而此时标识为f的,显然存在一个 接受者的多数派 ,这些接收者都接受(accept)了v,且对应得唯一标识为f。此时,一个提案者如果其发出了一个轮次唯一标识值为e 的提案且e大于标识f,则需要保证这个提案者的提案值也是v 。为了实现这一点那么对于这个系统得接受者来说,要么它们中所有实例都没有接受过(accept)轮次唯一标识值小于e 的任何提案,或者它们已经接受(accept)的所有轮次唯一标识小于 e的提案中轮次唯一标识最大的那个提案具有的决定值就是 v(即若有轮次唯一标识f小于轮次e且轮次唯一标识f对应的决定值为w,则v必然等于w)。(可以通过数学归纳法证明,这同样也是为了保证将来所有提案符合安全属性)。正式基于约束3,并结合提交者第一阶段第二步规则1或规则2,使任何提交者提出一个提案前,首先要和足以形成多数派的acceptors进行通信,获得他们进行的最近一次接受(accept)的提案(prepare过程),之后根据回收的信息决定这次提案的value,从而满足约束2。
当接受者这基于以上规则得到最后的决定值后,则将决定值对应的轮次唯一标识组装成消息accept(e)返回给提案者。
- while true do
- switch do
- case propose(e,v) received from proposer
- if epro = null || e ≥ epro then //持久化最后发送的promise对应的轮次唯一标识储存在epro,各个接受者实例要么都没有接受过(accept)轮次唯一标识值小于e的任何提案则直接持久化,要么当当前轮次的唯一标识大于或等于前面的轮次的标识,则覆盖前面接受的值(说明自己的状态当前是少数派))
- epro =e, vacc=v, eacc=e
- send accept(e) to proposer
第三步:当提案者接受到各个接受者发送的消息accept(e)后,依据收到的轮次唯一标识都为e的消息accept(e)进行判定,若其数量大于或等于Quorum数量,则说明轮次唯一标识都为e对应的决定值v已经成为最终决定值。
- Qa //接受了决定值的接受者的数量
- while Qa < n/2 + 1 do
- switch do
- case accept(e) received from acceptor a
- Set (accept).add(accept(e))
- Qa= Qa+1
- case timeout
- goto 第一阶段第一行代码 //本轮的执行认为失败
- return v //v的值来自第二阶段第一步line6
朴素Paxos第一与第二阶段主要角色及其行为与消息的描述列表:
| 发出方 | 接受方 | 消息 | 消息描述 | |
| 阶段一 | 提案者 | 接收者 | prepare(e) | e //轮次唯一标识 |
| 接收者 | 提案者 | promise(e,eacc,vacc) | e //轮次唯一标识 eacc//持久化最后接受的轮次唯一标识 vacc//持久化最后接受的决定值 | |
| 阶段二 | 提案者 | 接收者 | propose(e,v) | e //轮次唯一标识 v //当前提案决定值 |
| 接收者 | 提案者 | accept(e) | e //轮次唯一标识 |
第三阶段(学习决定)
若将接受者和学习者这两者的角色分开,可以加入学习决定阶段,在这个阶段学习者实例和提案者实例类似都是仅仅学习最终决定值,其是纯被动的。提案者或接受者都可以对学习者发送消息告知最终的决定值。
朴素Pasox具体执行的实例
下面以一个由2个提案者(S1,S2)以及5个接受者(A1-A5)组成的Paxos分布式系统为例,对应Paxos的执行过程中的各类场景进行简要说明。
其中轮次唯一标识结构为A.B,其由两部分组成。A为提案者实例对应的编号,其为逐渐递增的自然数,B为单调递增的轮次的全序。
1)标准执行实例:
图12为一个两个提案者顺序执行朴素Paxos的最佳执行的例子,提案者S1先执行,并得到了最终决定值(1.1,10)。然后,S2再次第执行,由于达到Quorum数量的接受者都已经接受了最终决定值10。两个提案者都完成了完整的两个阶段(为了简化说明,默认第三阶段学习阶段均会完成)。

图14
2)提案者S1实例故障无法完成完整的第一阶段。
若提案者实例S1出现故障或网络出现问题无法完成第一阶段并停止运行,则如图13所示,当实例S2开始依据相同的流程启动共识过程的新一个轮次,则各个接收者实例基于第一阶段第二步的规则2将新轮次唯一标识进行更新(1.1->2.2)。

图15
3)提案者S1实例完成完整的第一阶段后与系统出现网络问题,其发送的propose消息只能传递到部分接受者从而无法到达Quorum数量的要求。
如图16所示,实例S2开始依据相同的流程启动共识过程的新一个轮次,则各个接收者实例基于第一阶段第二步的规则2将新轮次唯一标识进行更新(1.1->2.2),同时由于S2实例得到了来自于接收者A1的promise(2.2,1.1,10),则依据第二阶段第一步规则2,其中选择10作为决定值,并组成propose(2.2,10)消息发送给接收者A1。
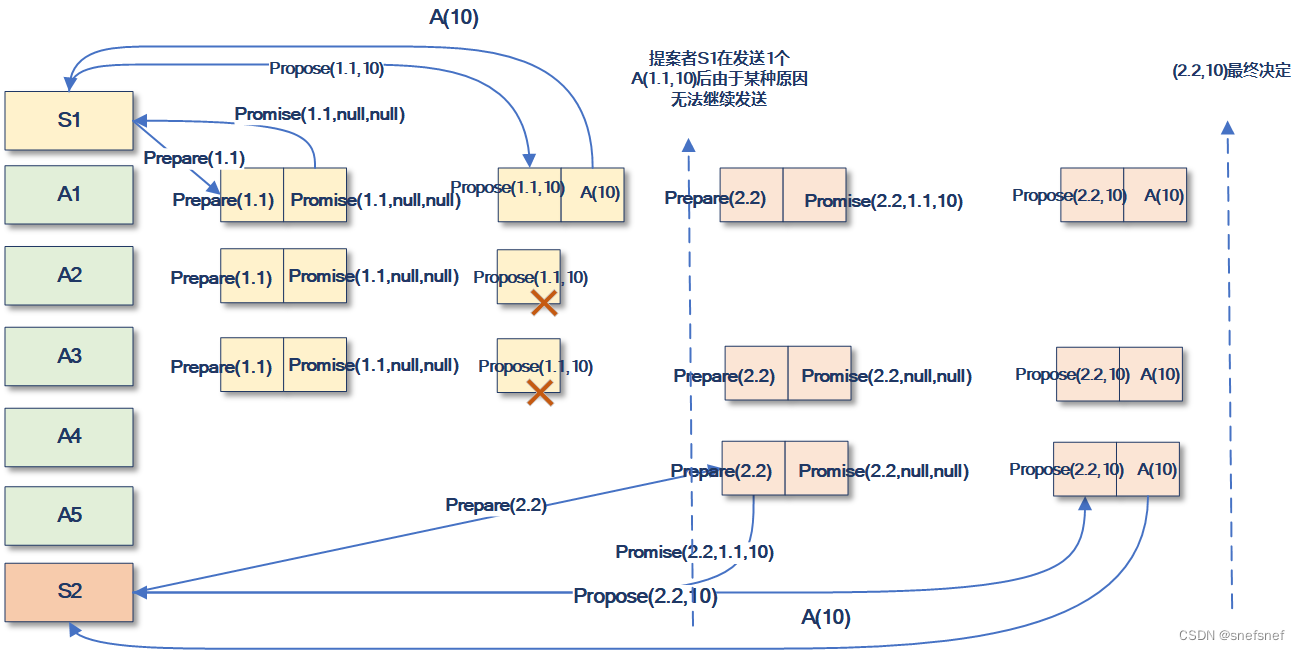
图16
4)提案者S1实例完成完整的第一阶段过程中系统出现网络问题,接受者A3因为网络短暂卡顿而没有及时将promise回发到S1实例,从而使S1实例因没有到达Quorum数量的要求而等待了一段时间。
由图17可以看到,此时,S2启动了其共识决定轮次并完成了第一阶段,且其发送的接受者实例A3,A4,A5都没有接受过propose消息,此时A3实例基于了第一阶段第二部规则2而接受了轮次2.2后,其收到了因为网络阻塞而姗姗来迟的消息Propose(1.1,10)。此时,其只能依据第二阶段第二步约束3(接受者所有实例都需要保证没有接受(accept)轮次唯一标识值小于e 的任何提案)
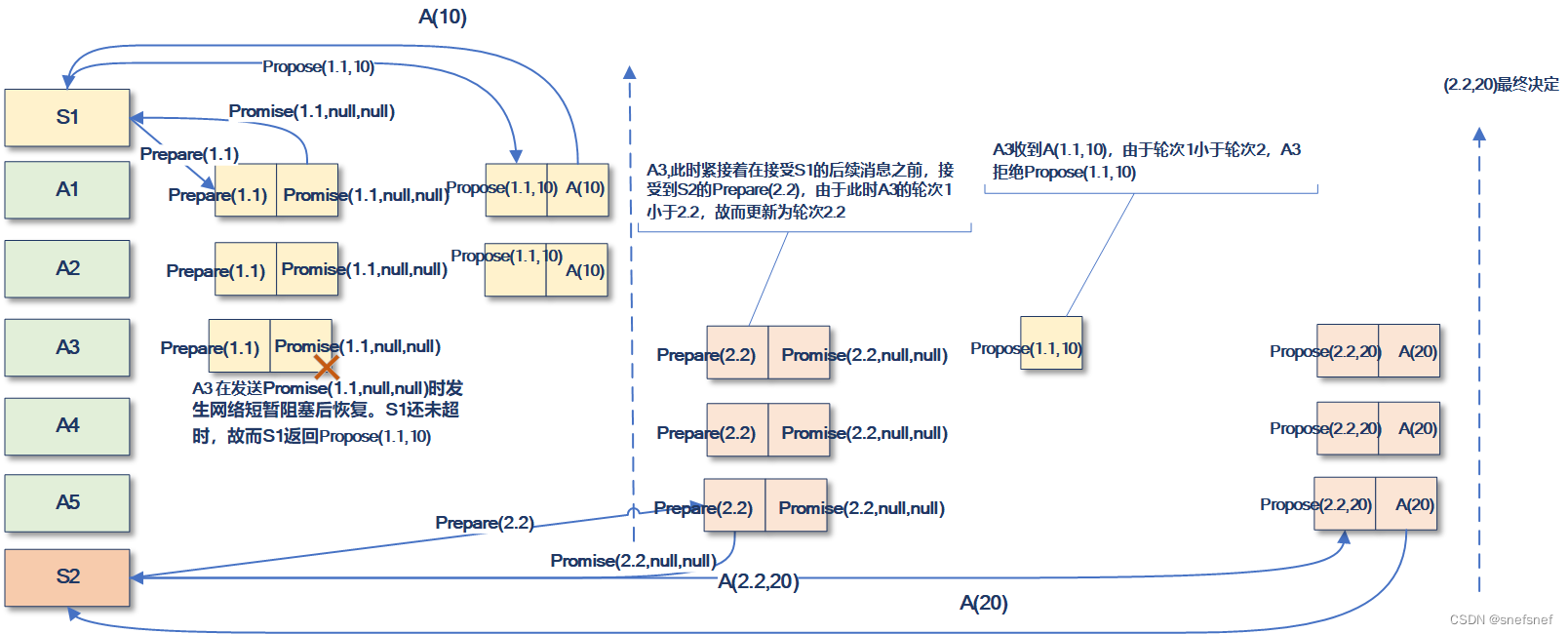
图17
5)图18的场景与图17类似,主要区别在于S2实例发送的接受者实例A2接受过propose消息,所以S2实例只能选择10作为提案的最终决定值。
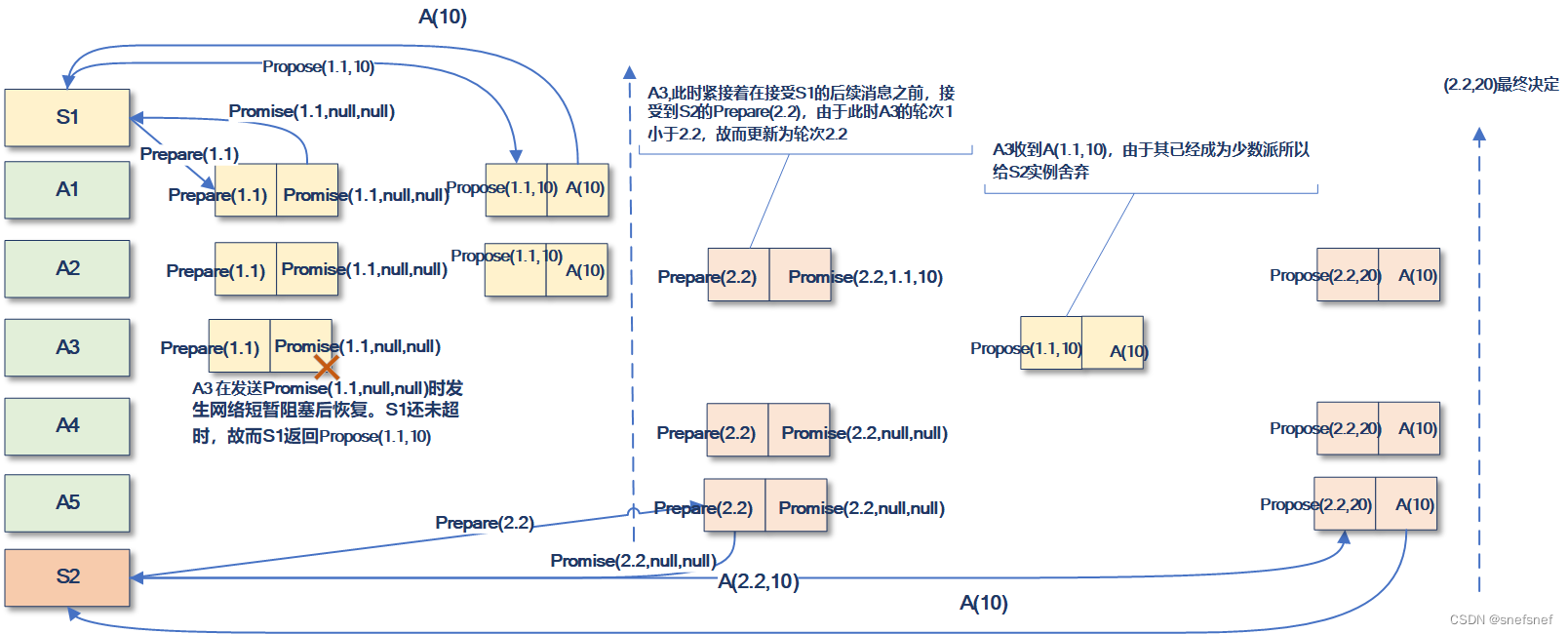
图18
6)实例S1与实例S2由于各种原因,在各自的第一个轮次1.1 与2.2中均没有达到Quorum数量的要求,从而得到最终决定值,在S2实例的后续轮次2.3中达到了Quorum数量的要求,其中接受者A2依据第二阶段第一步规则3,选择轮次2.2对应的决定值20作为接受的决定值。
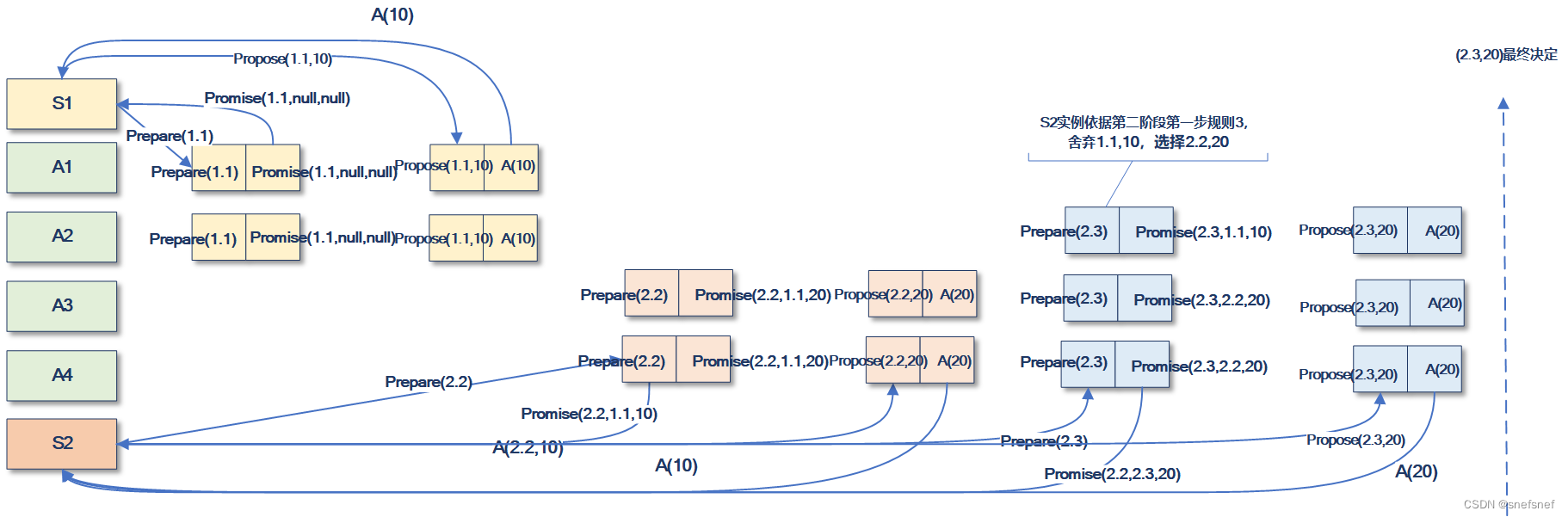
图19
朴素Paxos的限制
朴素Paxos与任何其他程序过程或协调算法一样,其也要符合安全属性(safety property)与 活力属性(liveness property)两个基本原则。从上面的过程与规则可以看到,朴素的Paxos的安全属性没有依赖任何活力属性相关的条件,即其可以在完全异步的系统中保证安全性,所以对于诸如消息延迟的上限或实例执行时间的限制等约束没有要求。朴素Paxos的限制主要在于保证活力属性。若分布式系统需要保证朴素paxos总是能够顺利执行(即在一个从0开始的完整物理时间段内,系统的各个部分都能够顺序执行朴素paxos),这便需要系统保证活力属性,而这与FLP定理息息相关。
因此,执行朴素的Paxos需要符合如下活力属性规则要求:
1)至少符合Quorum数量的接受者实例必须能够正常运行计算并能够正常的与提案者之间进行信息收发且每个实例的执行与收发过程所需时间极限值 f 符合其所需共识的方式的极限。
2)系统需要保证恰好有一个(Exactly one)提案者能够正常运行,且其时钟与系统的整体物理时钟相比较其时钟漂移提前量不能够超过上限g(通过时间保证顺序,且也是保证超时规则能够成立的基础)。
3)在提案者和符合Quorum数量的接受者之间传递消息所需时间在一个知己上限的时间限制 h 之内。
例如:当系统中的一个提案者的等待promise消息的超时上限可以至少定为f+2h+g。当时间超过这个限度,则提案者认为当前轮次执行失败而启动新的轮次。
若有分布式系统虽然其消息传递方式为异步,然而其符合上述要求,则可以发现其事实上符合同步系统的要求。故而有时也称为这类系统为半同步系统。这是由于系统保证需要接收者实例达到Quromun的数量及以上并且这些实例都可以和提案者进行通信并得到最终决议以完成朴素Paxos协议的两个阶段。同时,系统也需要保证恰好有一个(Exactly one)提案者能够正常运行以维持系统的确定性。而有限执行时间,消息延迟以及时钟漂移等约束则保证了接收者有机会在提案者启动新一轮提案之前对于当前的进行回应。若一个系统满足上述活力属性要求,则系统可以保证提案者可以最终停止并返回一个最终决定值v,(这也可以认为最终决定值v必然确定了)。
下面是一个不符合活力属性规则1的例子,当持续出现因某个接受者出现故障而使系统的中的正常运行的接收者始终未达到Quorum数量的要求时,在朴素Paxos会有如下所示的活锁问题。
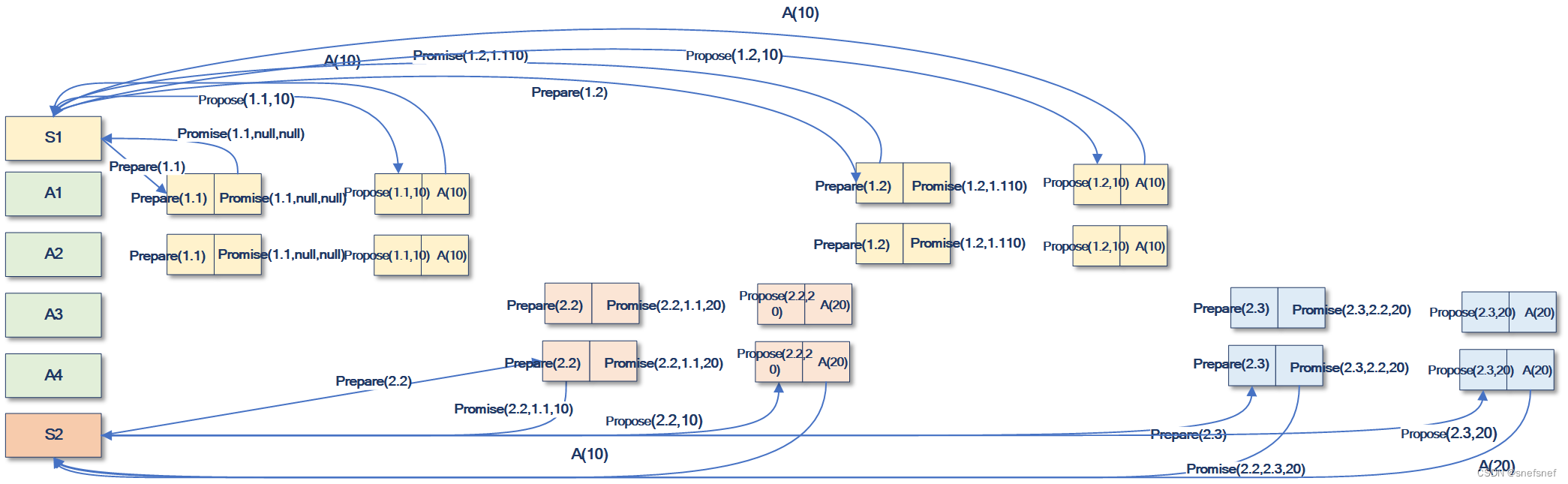
图20
下面是一个不符合活力属性规则2的例子,当系统有两个提案者时,执行朴素Paxos的系统有小概率持续出现 ,因第一阶段这两个提案者各自发出的prepare消息几乎同时到达接收者,而造成各个接受者上的轮次唯一标识相互覆盖(所谓的提交者对决情况),从而使系统处于活锁状态,进而使后续的第二阶段过程一直无法继续执行的情况。
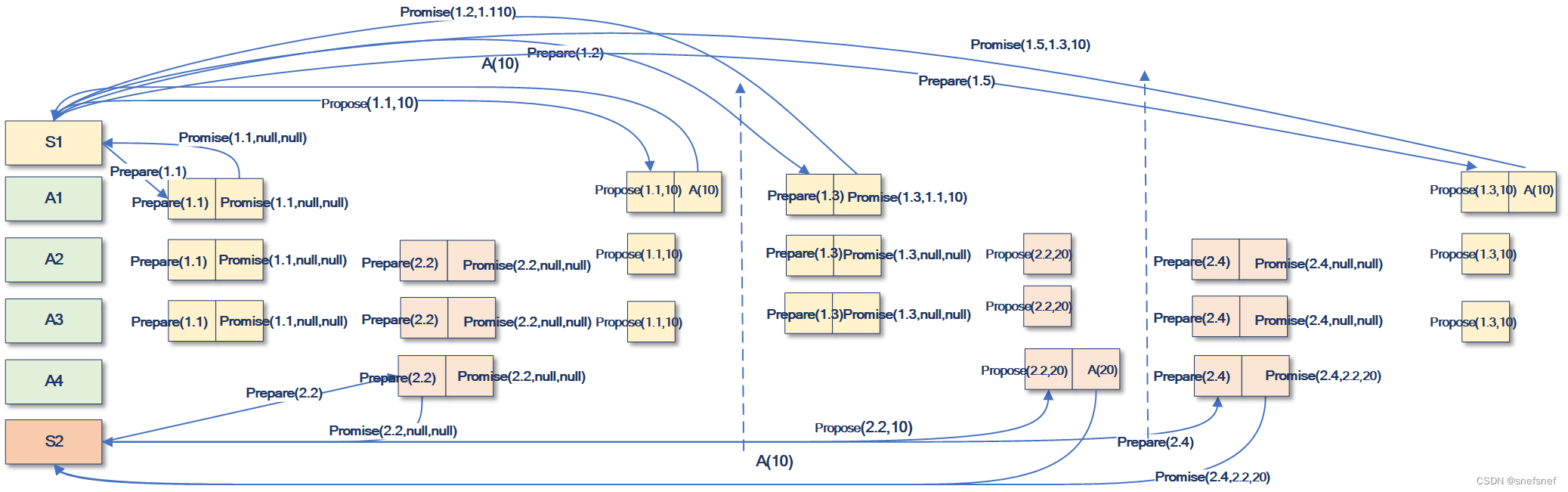
图21
虽然,有上述问题,但是实际生产环境中一直发生的概率非常小,因此如果在n个实例的异步式分布式系统中能够一直保证至少有n/2+1个接受者以及一个提案者实例在正常运行,且这下实例之间通信延迟可以控制在上限f+2h+g之内,则在这个分布式系统中基于朴素Paxos的共识执行会非常良好。
朴素Paxos的改进
朴素的Paxos对于系统如何达成共识的问题给出了一个抽象且泛化的基本方案,并没有考虑具体的系统环境与使用情景。因此,下面给出一些相对泛化的改进建议:
1)出于提高共识过程执行效率等目的,可以对于朴素的Paxos算法进行优化,譬如:系统可以当前轮次标识小于前面的轮次的标识时,在前述的过程中加入由接受者向提案者发出的no-promise(e) 以及no-accept(e)的NACK(Negative ACK)消息,提案者可以选择直接开始新的提案轮次从而加快速度,其也可以忽略这个消息直到得到达到Quorum数量的消息再做判断。系统可以维持一个给出相同的Promise的接受者集合,当提案者在第一阶段接受到了达到Quorum数量的相同的接受者的Promise,则可以越过第二阶段,直接得到最终决定结果。
2) 加入学习阶段,当任意一个接受者得到了决定值,则其可以直接通知各个提案者最终决定值已经确定,其可以进行学习,从而使系统的这次共识过程提早进入终结。同时,为了防范前面描述过的提交者对决从而造成活锁的情况,可以对于朴素Paxos中对等的提案者进行区分,这一般通过保证在一段时间内所有提案者都明确确实只有一个特殊提案者来执行朴素的Paxos的方式来实现,然而由于这个特殊提案者也会出现故障,所以由于无法解决的FLP问题,这种方式仍旧无法在完全异步的分布式系统使用。不过同样可以使系统处于前面描述过的半同步的方式来来保证系统执行Paxos的活力属性。
3) 朴素的Paxos中的提案者无需预先知道提案值,其可以在阶段二再提出提案值。故而,当确认了一个特殊提案者,则可以使这个提案者在完成阶段一之后再习得提案值,若此时没有其他提案者也执行同一个过程获得更大的轮次唯一标识(保证不会有对决的情况),则这个提案者可以在一次而不是两次消息往返中决定这个值(由于不会发生对决,这个特殊提案者可以在习得提案值后直接开始Paxos二阶段),同时在后续的其他共识过程中,若这个实例仍可以正常运行,则其可以保持这种方式,从而减少消息往返通信的次数,这种方式通常和一个特殊提案者方案,以及MultiPaxos一起使用。
朴素的Paxos与多副本本地存储模式系统
由于使用多副本模式的分布式系统的广泛使用,其需要某种方式来实现业务需求所要求一致性。 然而,朴素的Paxos对于系统如何达成共识的问题给出了一个抽象且泛化的基本方案,并没有考虑具体的系统环境与使用情景,其需要其他具体实践相关的定义来补充支持。同时,朴素的Paxos并没有对于leader提案者(特殊提案者)进行定义,所以不能直接用于被动复制副本系统(Passive replication)的实践当中。
朴素Paxos与状态(数据)维度一致性
对于多副本模式的分布式系统来说,在数据维度朴素Paxos一次只能决定一个最终决定值,即一次只能保证系统在一个提案值上的一致性。在谷歌的论文中将系统中从单个值提交到系统的Paxos执行部分,到一次朴素Paxos执行完毕且系统的各个实例最终确定了一个达成共识的提案值的完整过程做为一个实例(instance)。由于基于朴素Paxos的单个数据达成共识的过程必须是独立的,不能受到预先定义的参与这个过程以外其他元素的干扰,否则将直接影响达成一致的可能性(例如:朴素Paxos各个阶段的规则判定的正确性),因此每个实例必须是完全独立,互不干涉,且一旦最终决定值给选择后便意味着共识达成无法改变(可以将这个提交过程看作线性一致性的一个原子写操作)。参与单个实例的Acceptor以及Proposer的作用域只能在本实例之内。
另外,需要说明的是单个Paxos实例仅负责决定某个值的最终决定,并保证这个决定值对于所有实例来说是无法改变的。至于系统使用这个值是变更已经有值的共享变量还是赋值给空的共享变量,与Paxos过程本身无关。若将分布式系统看作状态机(图20),并将通过朴素Paxos单个实例得到最终决定值作为系统的状态值,则可以通过朴素Paxos收敛分布式系统各个节点实例的状态,从而保持系统整体状态的一致性。这类场景在分布式数据库、分布式缓存等数据为中心的分布式系统中十分常见。
朴素Paxos与时间顺序维度的一致性
对于一个基于消息通信的具有实际业务运行价值的多副本分布式系统来说,通过单次执行朴素Paxos来保证单个数据在各个副本达成副本并不足够,其还需要保证一个共享变量的被多个客户端进行多次数据提交时系统仍能保证这个变量变更的准确性、完整性。这需要系统在时间与顺序维度也能保证共享变量变化的正确性与完整性,即系统要能够保证一致性(指线性一致性)。基于所需达到的一致性在时间与顺序维度方面的定义,有序的重复执行朴素的Paxos共识过程,是实现这类要求的可行的方法之一。
对于每一次的朴素Paxos共识执行过程来说,由于其一旦决定了某个值则这个值将无法改变,所以针对同一个共享变量的数据每一次提交过程所需的朴素的Paxos共识过程实例,与对于多个新的共享变量的数据提交的朴素的Paxos共识过程实例一致都是独立的过程实例,相互之间无关。系统必然会有多个不同的共享变量,且对于同一共享变量也会有多次数据提交。对于分布式系统来说,这些变量的值的提交(写入)的过程必然相互交织,基于系统所能实现的一致性的不同,进而组合成为具有不同的性质的过程有序集合。同理,这也必然会使多个朴素的Paxos实例也相互交织,并组合成为一个有序的朴素的Paxos实例集合。基于这个Paxos实例集合可以得到一个与系统中所有副本实例都达成一致的共享变量的值的变化顺序纪录。当这个共享变量变化顺序纪录所记录的顺序符合系统所需达成一致性所要求的共享变量变化记录的顺序 ,则可以认为这个系统符合相应的一致性。例如:当系统需要实现线性一致性,则意味者其所有写操作记录组成的先后顺序记录必然是一个符合操作实际发生顺序(基于物理时间)的全序,系统所有实例必然对于系统的所有写操作的顺序达成共识。同理,其所有的Paxos的实例也必然组成一个具有相同顺序的全序序列,系统所有实例必然对于系统的所有朴素Paxos实例的顺序也需达成共识,(出现重叠情况,Paxos实例已经通过Quorum进行仲裁),而且所有朴素Paxos实例的记录顺序与系统的操作顺序在时间顺序维度要保持一致。
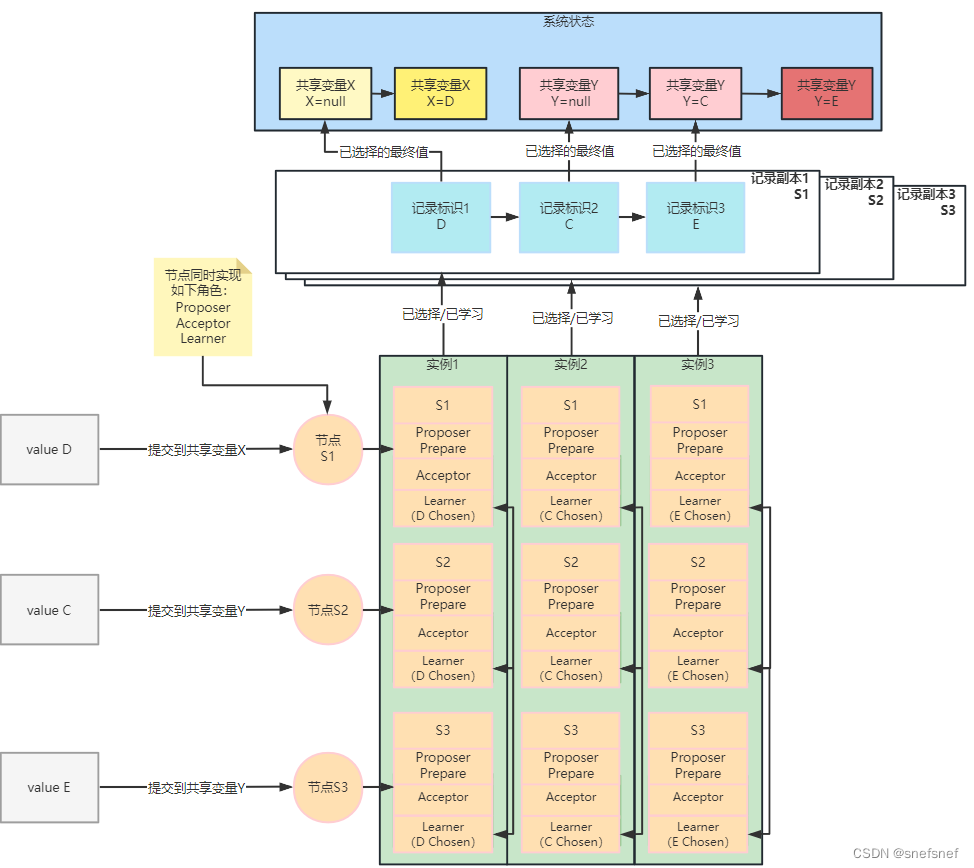
图22 节点实例S1,S2,S3,将D,C,E三个数据提交到系统,并由此形成了3个朴素Paxos实例,这三个实例组成了一个全序集合,共识过程产生的最终决定值的记录标识组成的最终统一顺序为:1,2,3。基于这个顺序以及朴素Paxos单个实例得到最终决定值,系统可以保证其代表系统整体状态的共享变量的值以及变化顺序始终保持一致,从而使系统的整体状态始终保持一致。这里共享变量X由初始状态null转换到当前状态值D。共享变量Y由初始状态null转换到中间状态C,最后转换到当前状态D。
基于半同步消息传递的非拜占庭多副本本地存储分布式系统多值基本共识过程----Multi-Paxos
通过对于朴素Paxos与状态(数据)以及时间顺序维度一致性的关系的分析可以看出,通过某些方式有序的重复执行朴素的Paxos可以保证系统所需的一致性,但是其缺乏实际工程的可行性。若对于有序的重复执行朴素的Paxos共识过程的以工程化实现角度进行适当的优化与扩展,从而得到一个可以在实际系统中使用的共识过程即Multi-Paxos(也是由Lamport提出),并能够支持主动复制副本(Active replication)与被动复制副本(Passive replication) 。其是使分布式系统的整体数据或状态在某些实例有故障的情况(非拜占庭故障)下从数据维度和时间顺序维度仍能符合线性一致性的重要工程基础技术之一。
Multi--Paxos涉及的基本概念
实例(instance):一次朴素Paxos的执行作为一个实例单位。
领导者(leader): 若在一段时间内,只有唯一的提案者,则这个提案者称为领导者(leader)。
维护实例之间的顺序(线性一致性的基础)
由于将一次朴素Paxos的执行作为一个实例单位,所以实例的顺序决定了最终决定的共享变量纪录的变化顺序。为了维护共享变量变化纪录的顺序,可以对于系统各个副本实例所属的Paxos的实例给予唯一编号(即轮次编号),编号从0开始,只增不减。由此副本实例上的多个Paxos实例都是一个递增编号的有序系列,而基于朴素的paxos可以保证属于一个编号的实例的系统副本的最终选择的值必然都是一致的。同时需要注意的是,Multi-Paxos对于提案的编号(proposal id 或Epoch Number)序列是否应该连续没有做出定义,其只要求这个编号序列是一个全序以保证安全性。同时,Multi-Paxos对于存储数据的条目是否被有序复制保存也是没有要求的。
故障的容忍与恢复处理
由于分布式系统需要在有系统实例出现故障的情况下,仍能保持对于所有朴素Paxos实例在数据与时间顺序都达成共识。因此,需要将前面提到的每一个Paxos实例及其对应的记录标识组成全序序列进行持久化, 形成由于实例记录标识组成的全序记录。从而使系统中发生的故障的副本实例在恢复之后,可以学习全序记录的顺序与内容,并使自身状态严格按照全序记录进行变化,从而最终消除与系统全局状态的差异。
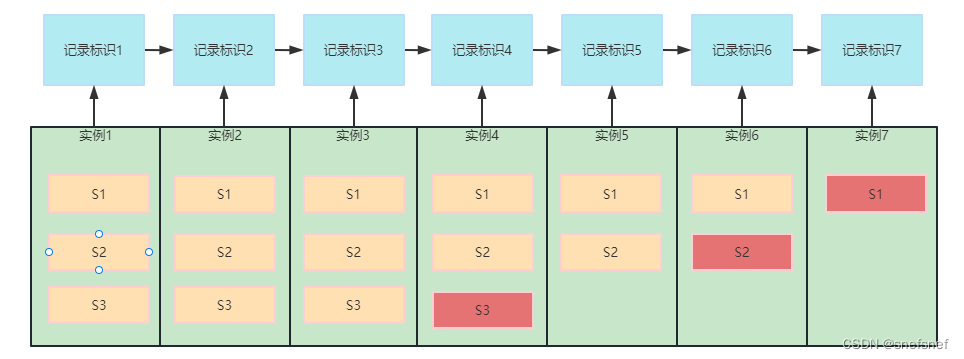
图23 展示了分布式系统执行各个共识实例时的系统状态快照。副本实例S3在执行Paxos实例4的时候由于故障而停止,副本实例S2和S1继续执行实例4与实例5并已经确定了对于相应的最终决定值(已经达到Quorum的数量)。副本实例S2仍在执行Paxos实例6,由于副本实例S1已经完成对于实例6的最终决定值的accept,并接受到了最终决定值已经确认的消息,而S2实例还未得到这个消息。副本实例S1当前执行的是Paxos实例7。
对于副本实例学习全序记录的顺序与内容可以在朴素Paxos的第三阶段(学习决定)阶段进行。即副本实例,同时也会执行学习者(Learner)的行为。基于朴素Paxos的过程,除非出现通信超时等被判定为失败的情况,否则只有符合了第二步的约束条件并得出最终决定值,则才能认为当前Paxos实例结束,并增大记录标识。因此,若这个故障恢复后的副本实例的当前最大的记录标识小于其他正常运行的副本实例的全序序列持久化的记录中的记录标识(可以通过对于其他副本同步通信收集判断,这里假设采取各个副本实例上面都有保存全序序列持久化的记录,当然也可以使用数据库或缓存等状态机集中存储,不过这会降低系统整体可靠性),则这个副本实例可以直接向其他正常运行的副本实例请求学习全序序列持久化的记录 ,从而产生自己的相同的全序序列持久化的记录。同时,通过略过当中的朴素Paxos的前面两个阶段的执行,可以大幅提高整体执行效率。
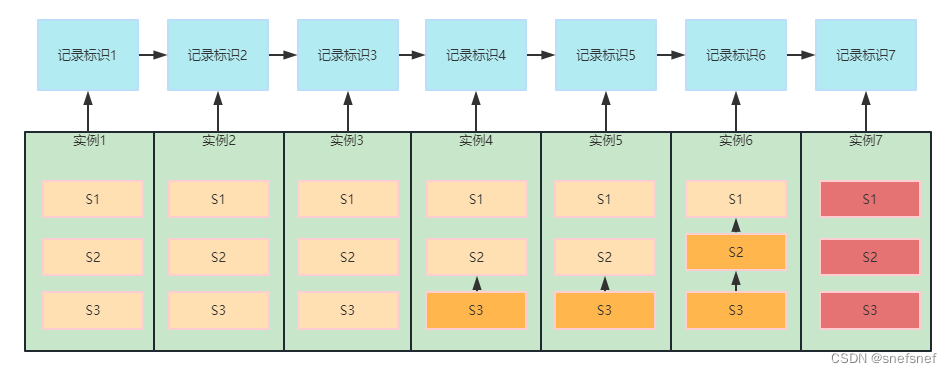
图24 副本实例S3从副本实例S2习得了所需的全序序列持久化的记录,而S2则从S1处得到了所需的全序序列持久化记录信息。从而使3个副本实例从实例7开始,同时执行实例7。
保证活力属性并减少系统信息交互
Multi-Paoxs由朴素的的paxos实例组成,由于朴素的的paxos支持主动复制副本(Active replication)模式,所以Multi-Paoxs也一样可以支持主动复制副本(Active replication)模式,但是这也会付出相应的性能代价。这是因为虽然各个朴素Paxos实例相互隔离,然而在同一个实例当中,所个副本实例可以同时各自提交提案,从而造成前面描述过的各个接受者上的轮次唯一标识相互覆盖,(提交者对决),进而迫使各个提交者需要不停的变大唯一记录标识使共识过程继续下去(参考图19),在小概率的情况下甚至会出现活锁情况。所以,可以将分布式系统中可以作为Proposer的副本实例的总数降低到一个(即所有Paxos实例都采用同一个提案者的提案), (主动复制副本模式转变为被动复制副本模式),是防止副本实例同时提交的情况发生的一个十分有效的方式。由于只有一个提案者,所以可以保证所有朴素Paxos实例得到相同的Prepare信息,所有的Promise对应的唯一记录标识必然相同,因此在这个提案者发生故障之前的一段时间内最大限度避免了提交者对决的情况的发生,由此也就避免了因为对决造成的提交者需要不停的变大唯一记录标识的情况。这里将这唯一的提案者称为领导者(leader)。同时,这个方式可以跳过prepare阶段以节省时间,同时由于极大的减少由大量的prepare阶段所引起的消息通讯,从而节约网络资源,提高系统效率。
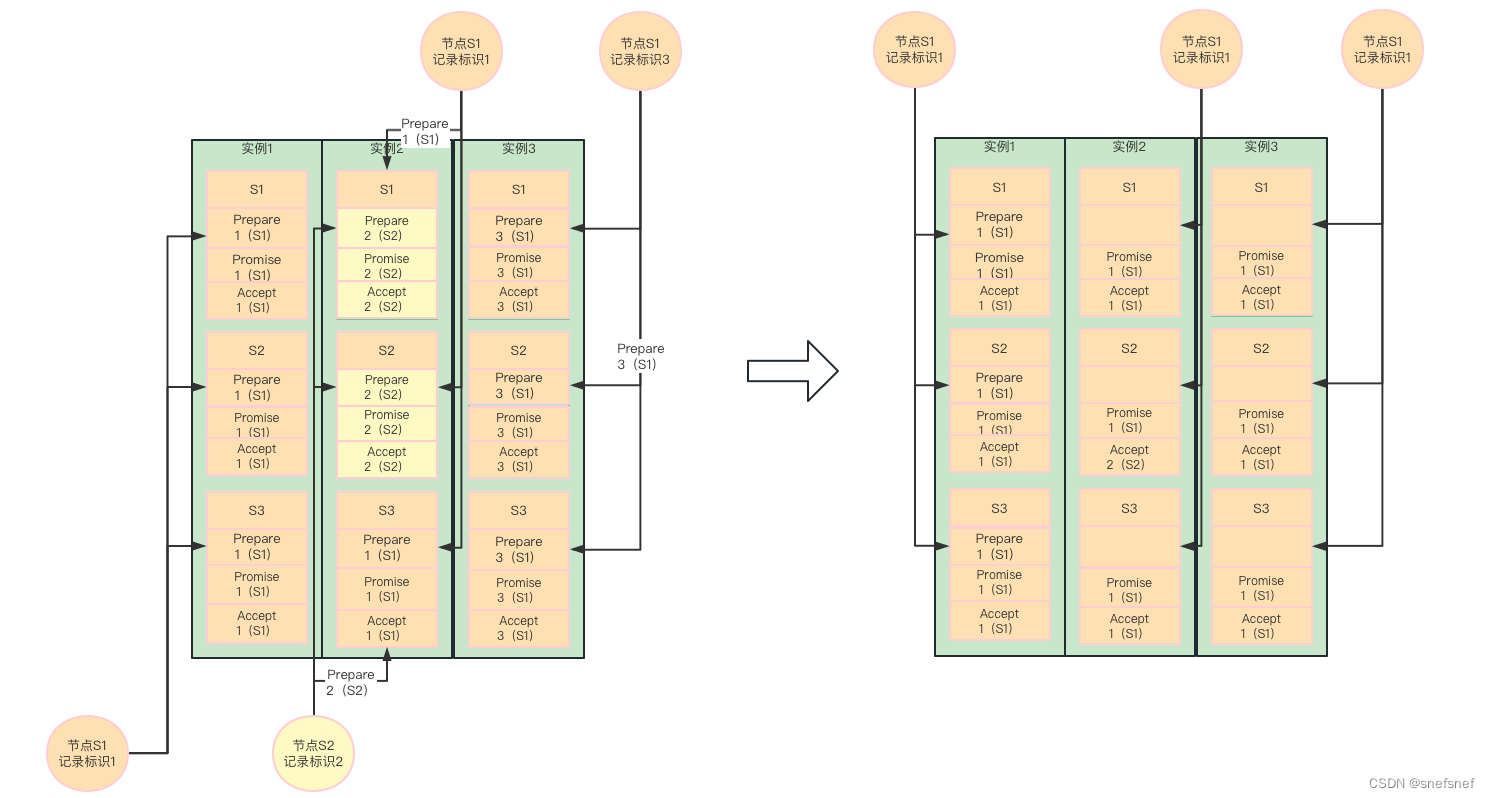
图25 当系统总共只有一个提案者,在没有其他节点提交的干扰下,每次Prepare的编号(谷歌论文中成为Epoch numbers)都是一样的。由此,S1的Promised消息变成全局消息。
当这个提案者出现了故障并停止工作,系统有两种应对方式:
1)通过某种机制再次快速选择一个唯一的提交者(可以由使用者自行实现),从而维持只有一个提交者的状态。在Lamport的论文中建议通过分布式副本实例的“名字”来确定一个固定的顺序,当当前的proposer出现问题则下一个副本实例成为proposer。这个策略主要的问题是灵活性不佳,可能依据名称得到的proposer的稳定性不佳(例如:编号为1的副本总是不稳定,十分容易crash),从而系统常常处于没有proposer的状态,进而影响整个系统的稳定性。另一个方式,是以及以往的运行记录选择最稳定的实例作为领导者(leader)。然而,这需要系统的所有副本实例都要知晓最稳定的实例是哪一个。
2)允许出现多个提案者进行提案提交,而这将使竞争的情况复现,也意味着Multi-Paxos退化到朴素Paxos。
通过并行运行提升吞吐量
由于Multi-Paxos的单次执行(一次执行包含多个Pasox实例(instance))是一个单线程的顺序执行的过程,即Paxos实例(instance)必须一个一个顺序执行,以保证单个变量的一致性(例如 线性一致性)。可以将这个单次执行看作一个单独的状态机实例。由此为了提高系统的整体吞吐量以及CPU的利用率,在现实的基于Paxos的共识系统中(例如Google)往往会采用并行执行多个Multi-Paxos状态机实例,以同时保证多个共享变量的一致性。最终,系统需要将这些记录最终会组合为一个全序符合整体一致性(线性一致性)的记录。需要注意得是,Multi-Paxos并没有对于序号顺序(prefix order)进行定义 ,所以其不能保证系列得顺序是连续得,其仅能保证序列是一个全序(记录当中会有空位)。
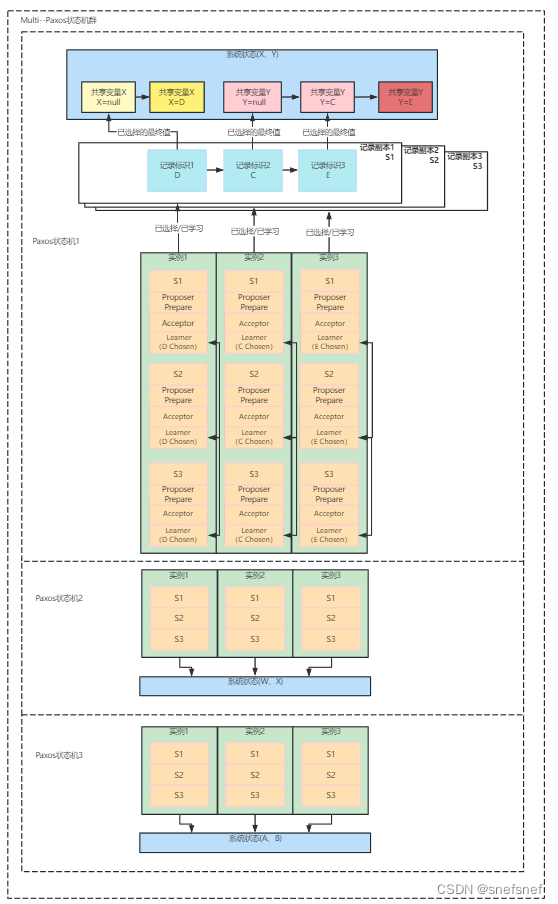
图26 多个multi-Paoxis组成的群组,从而可以对于多个没有关联共享实例并发执行共识并保证系统的线性一致性,提高系统吞吐量。
Multi-Paxos与朴素Paxos与的定义类似都是较为泛化抽象的,但与朴素Paxos相比,对于多副本系统的使用进行了扩展,显得更为具体一些。虽然其仍旧缺少基于具体场景的具体实现方式的及其细节的定义,尤其是对于关键的各个提案之间的序列的正确性只给出一个相应的要求,而没有给出具体的解决方式。这造成了对于Multi-Paxos的具体实现,不同的公司与团队会各有不同(参见Google与腾讯的实现),例如:对于leader的选择方式、生成提案序列的方式、全序的维护方式、是否需要保证序号得连续、日志副本的数据完整以及序列的维护等等。
基于半同步消息传递的非拜占庭多副本分布式系统多值共识过程示例 ---ViewStamped 复制
ViewStamped本质是针对基于异步网络通信、非拜占庭故障(crash-recovery) 模型的多副本系统设计并保证系统内各个副本的复制状态信息符合线性一致性的复制协议(replication protocol)。它是Oki 以及Liskov女士在研究分布式系统2阶段提交时提出的一种实现共识的方式。ViewStamped能达到线性一致性的正确性、完整性,其最初版本发表于1988年(比Paxos发表时间更早),所以与Paxos并无直接关系。ViewStamped适用于采用被动复制副本本地存储为架构的分布式系统,并能提供连续得全序序列记录。
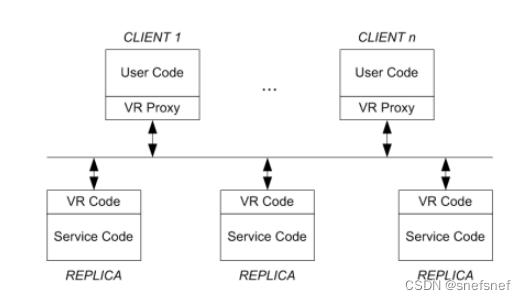
图27 最简单ViewStamped副本实例组成的系统架构图。
ViewStamped涉及的基本概念
视图(View):视图(View)指客户端于某一个时刻的对于系统进行观察得到的静态状态,也是一次执行实例。
视图编号(View-number):视图的唯一编号从0开始。当主副本出现变动,则进行单调递增。
界限数字(quorum):ViewStamped与Paxos一致,也使用界限数字(quorum)q来保证系统可用性与所存储信息的可靠性。若数量q为系统可以容忍的出现崩溃(crash)故障的副本实例的数量的最小数量。
系统整体副本实例数量应为2q+1。这意味着,使用ViewStamped的副本系统,其每个步骤都必须由 至少q + 1 个副本处理完毕(q + 1 个副本可以通过设计指定)。从而使系统可以能够在不等待其余q个副本参与的情况下执行请求,并基于鸽巢原理保证即使系统有q个副本实例出现故障,系统仍旧保证有一个正常的副本实例保存了正确的状态信息而不会产生遗漏。
主副本(primary replica):VR 使用主副本来排序客户端请求;这其他副本是仅接受主选择的顺序的备份。
操作数(op-number):副本实例最近收到的请求编号(单调递增),初始化值为0。
提交数(commit-number):最后提交成功的请求编号(单调递增)。
配置(configuration):系统中所有副本实例的ip与唯一id号的列表。
日志(log):造成整体状态变化的有序(全序)记录。
客户端表(client-table):追踪客户端request和reponse。每一个客户端具有唯一的标识。
请求编号(request-number):每一个请求的唯一的编号。客户端生产并保存于副本实例的客户端表。
反馈编号(response-number):每一个请求完成后的唯一的编号。保存于客户端表。
副本实例状态(status):副本实例当前状态。
客户端编号(clidentId):客户端唯一编号

图28
ViewStamped的主要流程简述
一般场景下基本流程:
当主副本实例正常时,一个用户request的处理流程如下:
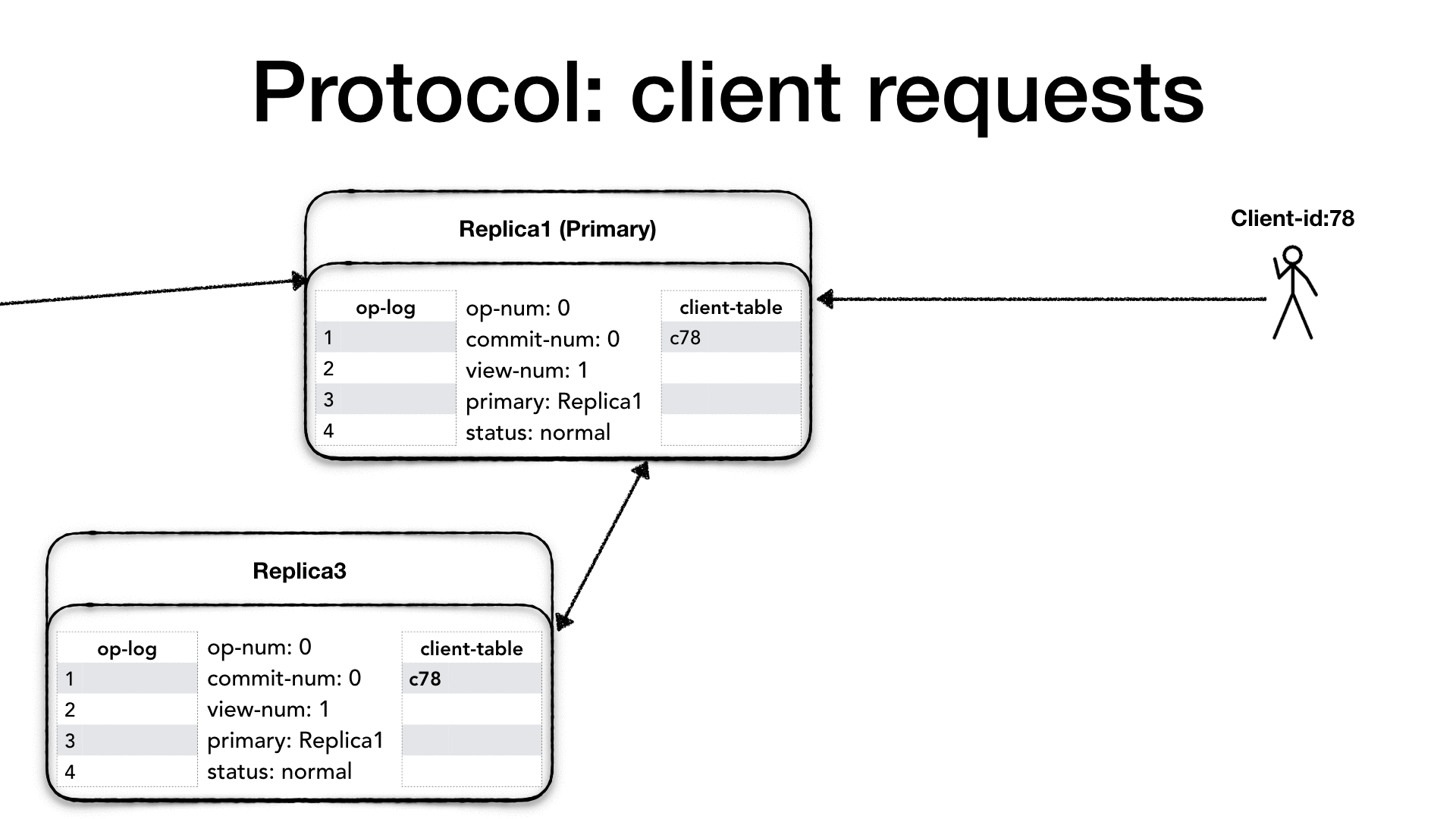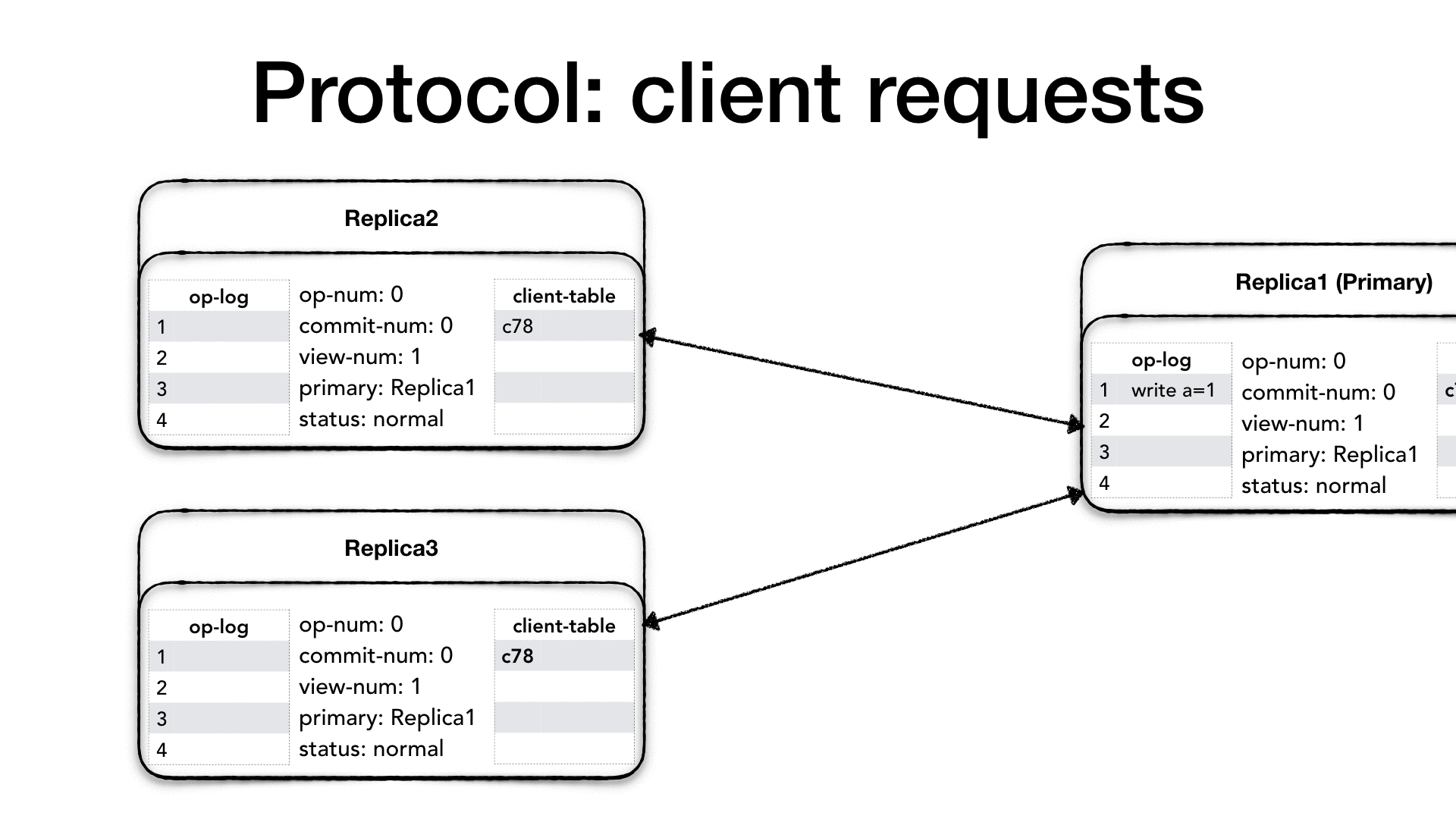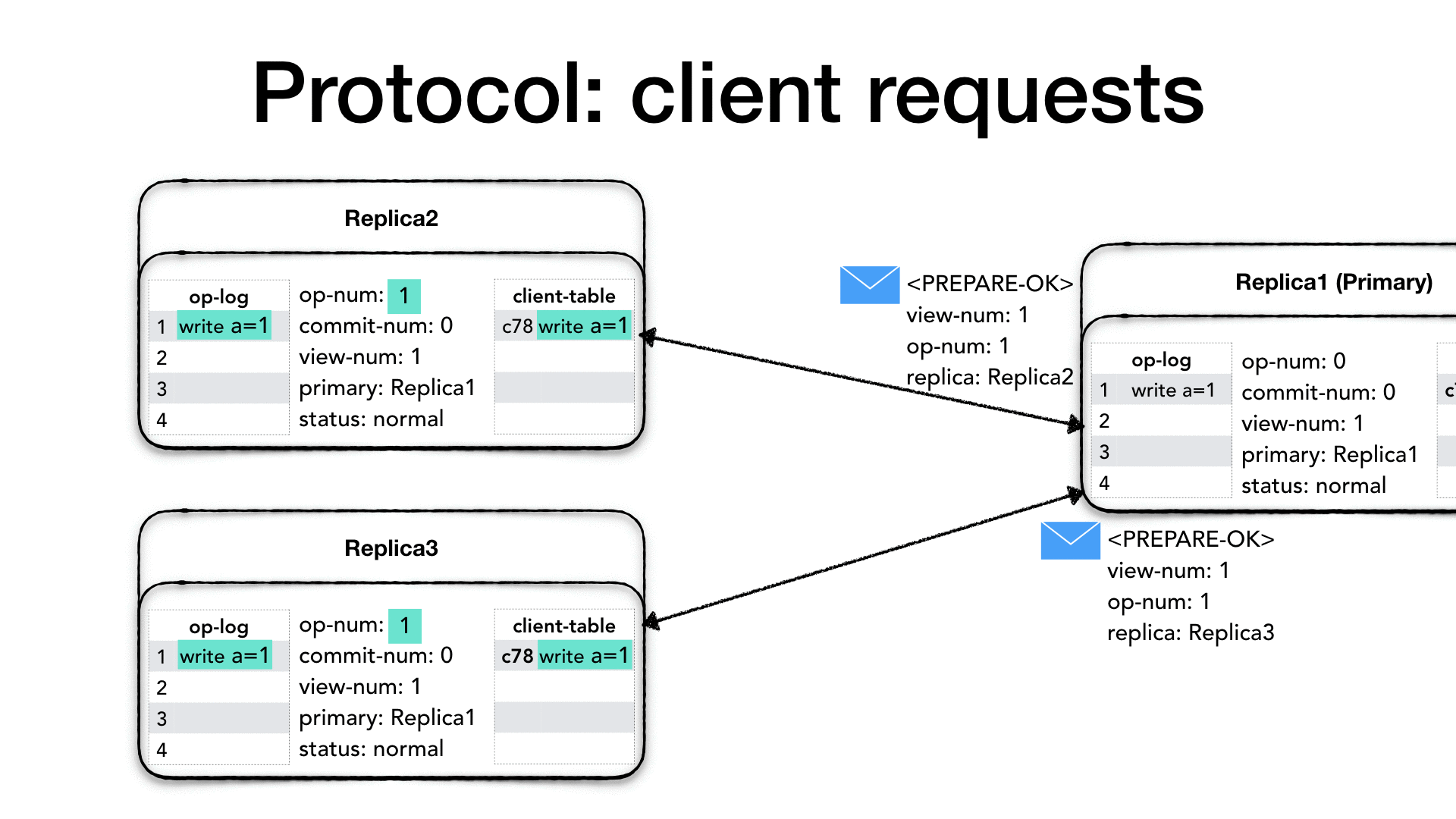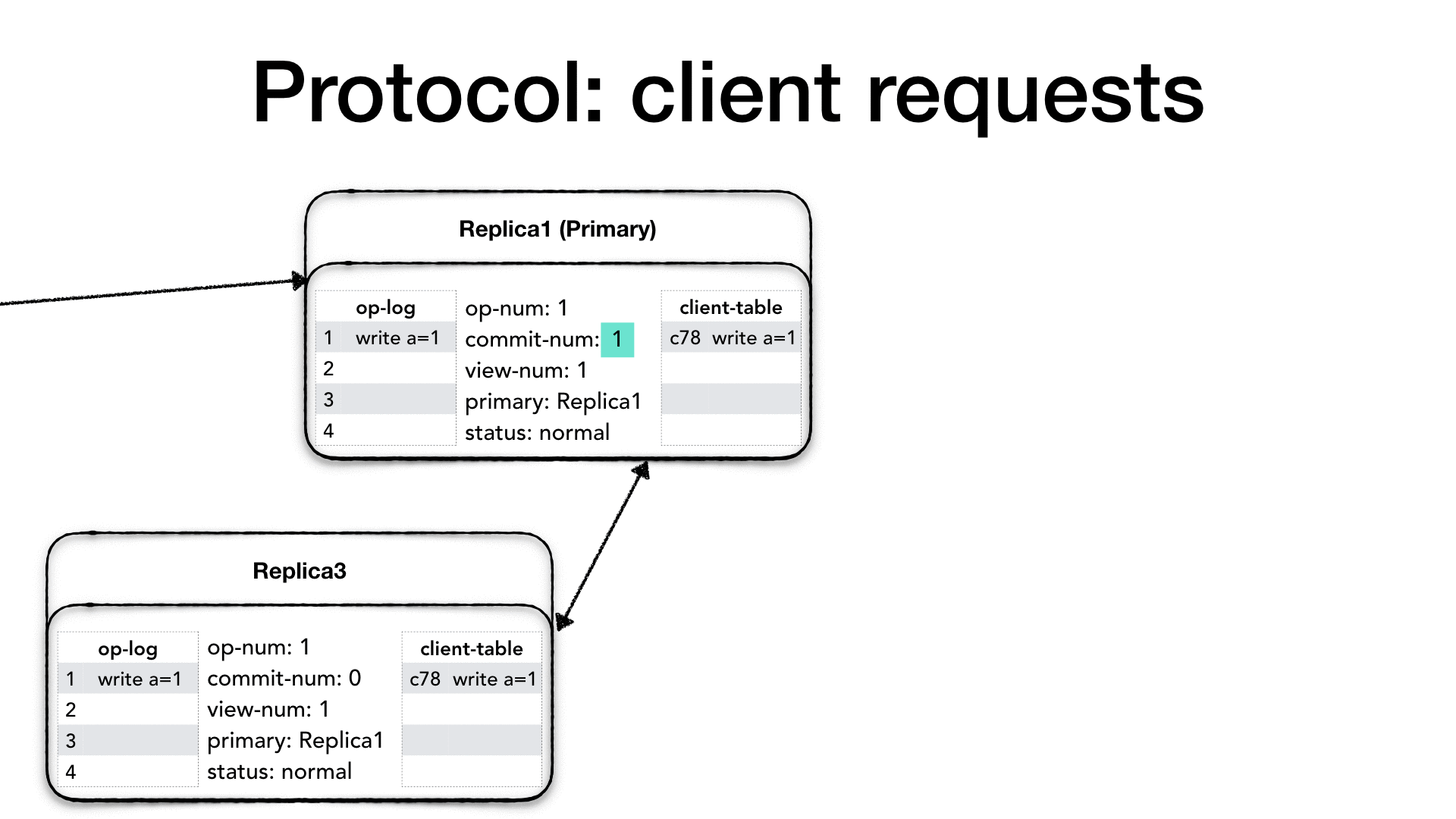
第一步:客户端发送Request给主副本实例,Request需包含客户端编号(clidentId)、request-number(由客户端生成);
第二步:主副本实例收到请求后做如下步骤
1)利用client-table保证幂等性,如果是最近的一个已经执行过的请求则会返回响应以加强系统可靠性;
2)主副本递增本地操作数(op-number),将请求追加到log末尾,并更新client-table,发送Prepare请求给所有的副本(Prepare请求包含当前view-number(当前成员组的编号)、客户端发送消息内容本身、op-number(当前请求对应的操作编号)、提交数(commit-number))
第三步:副本实例收到请求后做如下步骤
3)副本实例收到Prepare请求后进行如下步骤,首先需要保证收到各个Prepare请求组成序列的是一个全序(假设系统需要保证线性一致性),为此其便需要副本实例首先对于Prepare请求中的op-number与本地的log的记录进行比较, 若没有找到所有比这个Prepare请求op-number小的记录则
拒绝Prepare请求,并等待(或发起state transfer请求来主动获得)否则将请求追加到日志末尾,并加大操作数(op-number),并回复主副本实例PrepareOK(PrepareOK包含当前view-number(当前成员组的编号)、op-number(当前请求对应的操作编号)、
副本实例唯一编号)。
第四步:主副本实例收到f(f为界限数字(quorum))个 PrepareOK 做如下步骤:
主副本实例收到从不同副本实例发出的消息后,就认为当前的 operation 及所有之前的op都是已经提交完毕(commmitted),当其认为其完成了之前所有的操作后(通过向上调用(up-call)服务代码来执行 所有小于当前的
操作数(op-number)),则开始当前operation的执行,并递增本地的commit-number,然后将result(包含view-number(当前成员组的编号),客户端编号(clidentId),向上调用(up-call)进行执行并得到结果)作为Reply消息应答客户端;并同时更新client-table。
第五步:主副本知会各个副本系统的系统当前的操作的提交情况
在通常的情况下,主副本通过下一个Prepare请求(必须等待上一轮f个客户端的反馈结果保证共识达成)来知会各个副本系统的系统当前的操作的提交情况。 因此每一个Prepare消息中都必须具有commit-number。当没有客户端请求时,primary也会周期性发送 Commit 消息给副本p节点,以便commit-number(此场景下commit-number=op-number)能够尽快通知到副本;当备份实例收到一个提交信息, 其必须等待对应的请求被收入到它的日志中并完成所有之前的执行之后其才能如同主副本一样向上调用(up-call)进行执行,然后递增本地的commit-number,更新本地的client-table,只是无需给客户端回复。当客户端没有收到对请求的及时响应,则对于所有的副本进行重复发送。(这往往意味着主副本出了crash fail,会出现view的变更)副本实例会忽略这些请求。
在第三步备份实例必须按一个相同的操作的全序来处理Prepare收到的消息,理论上backup上可以放开这个限制,允许乱序处理Prepare请求。但是这会使view change切主流程变得复杂,因为每一任新主副本需要对前面的顺序做重新确认。

图29 ref:https://blog.brunobonacci.com/images/vr-paper/client1.gif
ViewStamped的故障场景下基本流程:
主副本实例出现故障维持系统安全属性与活力属性:
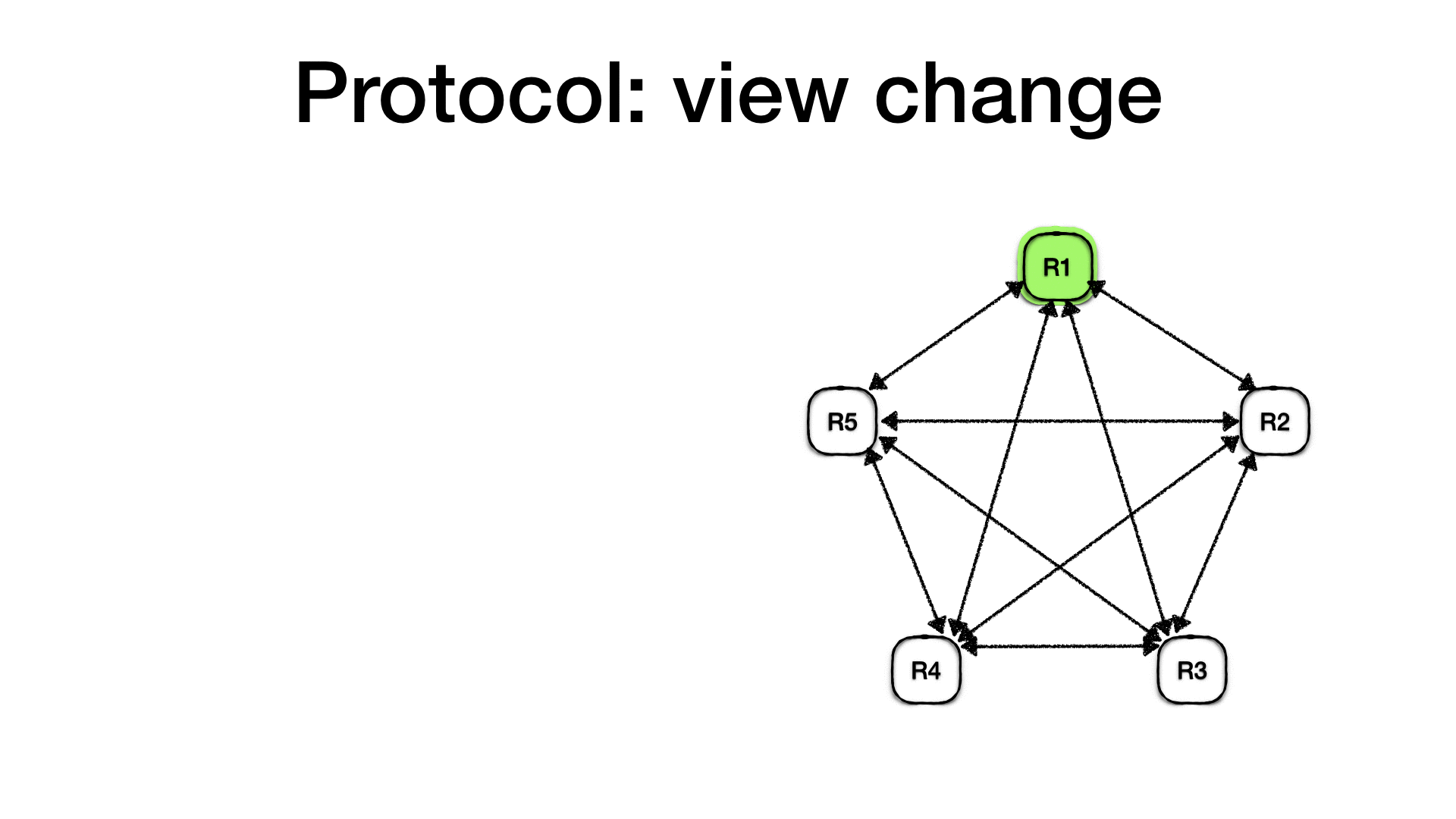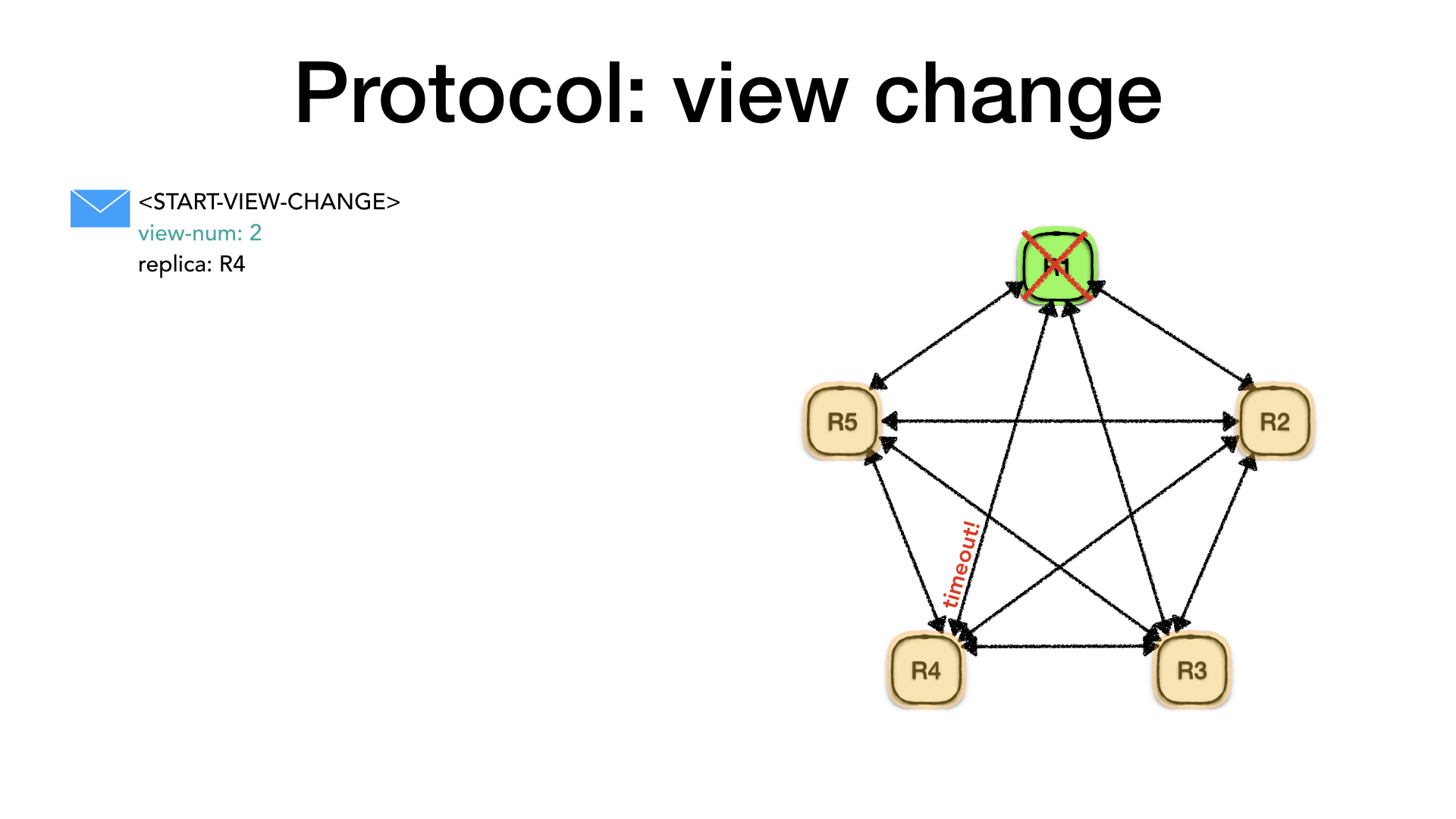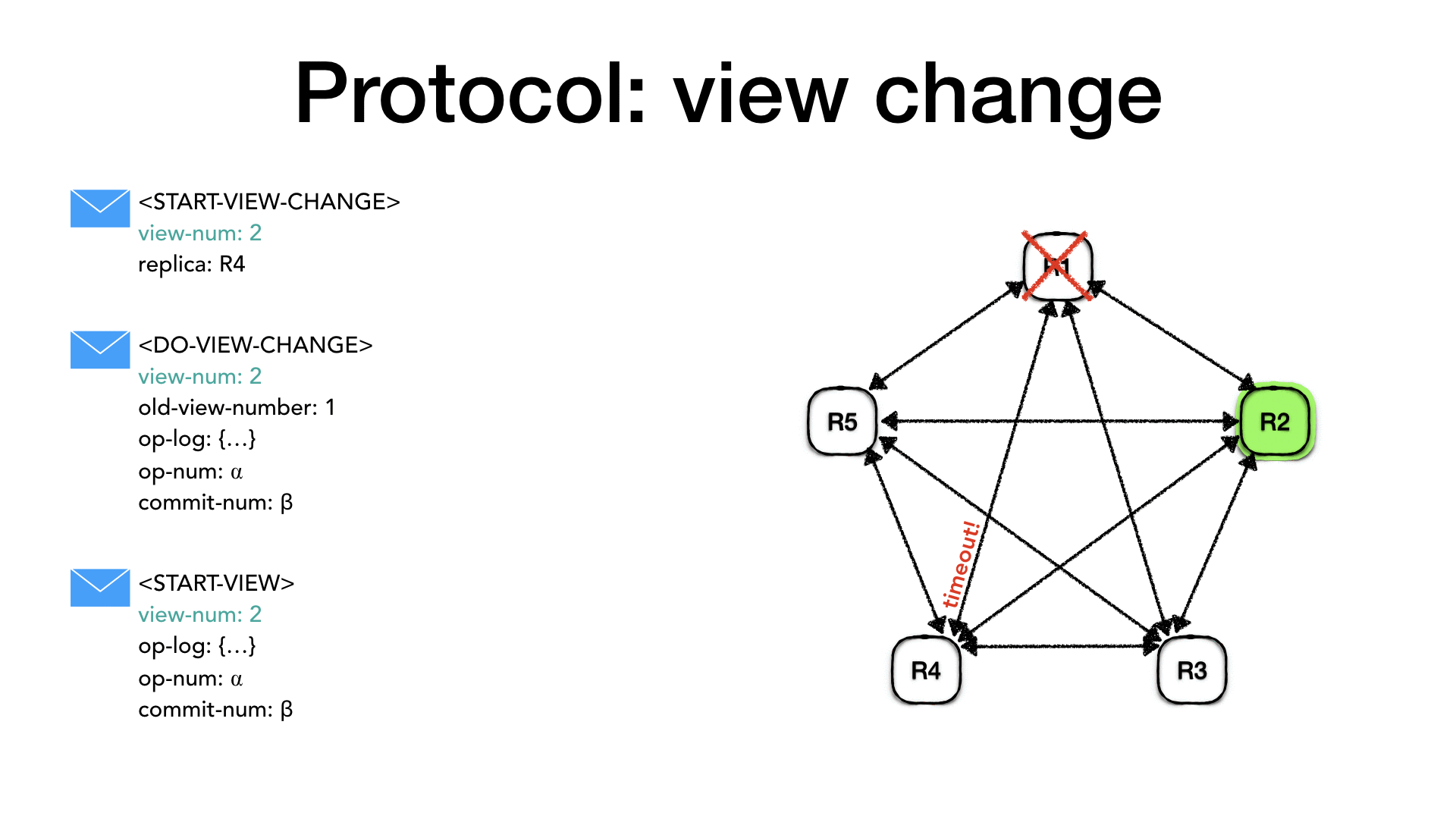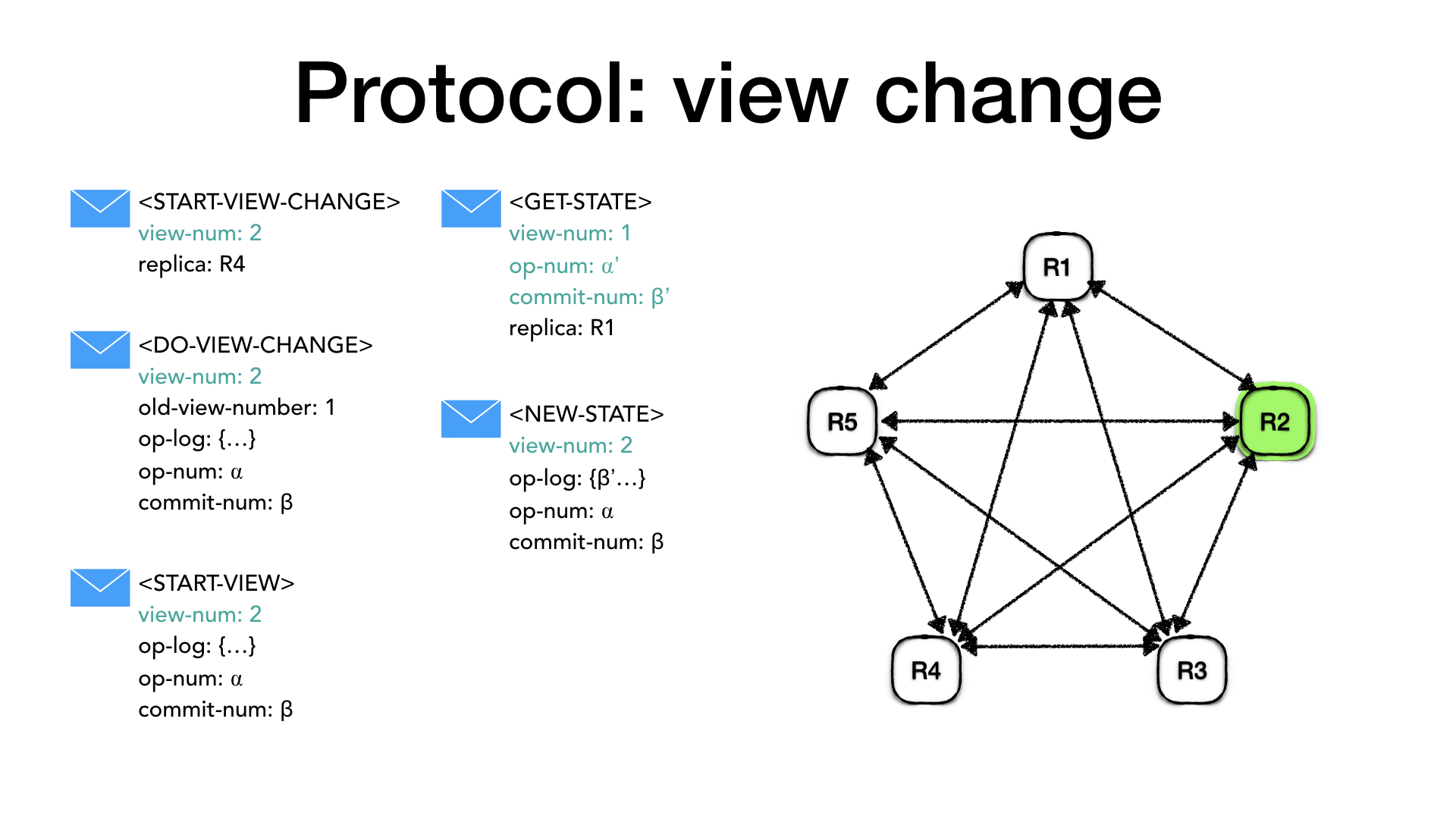
每个副本实例都会监控主副本实例(通过类似心跳的机制,主副本实例在没有收到客户端请求时会周期性给副本实例发送Commit消息以代替Prepare消息给各个副本实例。)若副本实例在阈值期限内没有收到此消息(即超时),则可认为主副本实例发送crach fail类异常,系统开始 view change流程来保证整体高可用。
1)任意一个副本都会发起view change,发送startViewChange消息到其他副本,并提升其视图编号(View-number),同时会将副本状态(status)从normal转变为viewchange。
2)当副本收到其他f个(f为quorum数据)副本发过来的startViewChange消息并得到view-number后,其会发出一个DOVIEWCHANGE到在新的view中的主副本实例。
3)当新的主副本实例收到了f+1(包含其自身)的DOVIEWCHANGE消息时,将自己的view-number设置为消息中最后的副本状态为normal的最大的view-number,并将此消息的内容作为新日志;如果多个消息具有相同的view-number,它会选择其中某一个消息。它将其 op 编号设置到新日志中最顶层条目之中,将 commit-number 设置为其在 DOVIEWCHANGE 消息中收到的最大commit-number 编号,将其自身状态更改为正常,然后发送STARTVIEW消息通知其他副本,视图已完成改变。
4)此时新的主副本实例开始客户的请求。同时,主副本实例开始按照已经存在的全序顺序开始执行任何其没有执行过的已经提交的操作,并更新客户端表(client-table)以及回复客户端。
5) 当其他副本收到STARTVIEW消息时, 其用消息中的日志替换当前的日志, 将 op-number 设置为在日志中最新条目的 op-number 并将的视图编号设置为消息中的视图编号,将其状态更改为正常,
并更新其客户表中的信息。如果日志中有未提交的操作,则向主节点发送 PREPAREOK 消息, 然后其如同主副本一样开始按照已经存在的全序顺序开始执行任何其没有执行过的已经提交的操作,并提高 commit-number,并更新其客户表中的信息。
图30 ref:https://blog.brunobonacci.com/images/vr-paper/view-change.gif
主副本的选择
ViewStamped Replication对于如何得到下一个主副本实例没有具体的定义在具体实现中可以采用完全不同的方法。它使用副本节点基于固定属性的确定性函数,例如如果副本实例的唯一标识符或 IP 地址是固定的,则可以用来确定主副本节点。实现团队可以 使用某些确定性算法例如:排序函数,并基于副本实例的固定 IP 列表来得到确定的副本实例排序方法。 由此,ViewStamped Replication 可以简单地使用排序后的 IP 列表来确定谁是下一个主副本实例,并且使用简单的round-robin方式来确定当前一个节点不可用时,其他副本实例如何依次成为新的主副本实例。
故障副本恢复流程:
1)当故障副本恢复正常后,其会宣布状态恢复并向其他的副本实例发送一个带有特殊随机数x的消息RECOVERY。
2)任意其他状态为正常(normal.)的副本实例才会响应RECOVERY消息发送RECOVERYRESPONSE消息,并将特殊随机数x加入RECOVERYRESPONSE消息之中。RECOVERYRESPONSE消息还包含view-number,op-number,commit-number,日志记录等多个关键信息。
3)当故障副本得到多于quorum数量的副本所回复的RECOVERYRESPONSE消息后,包含一个来自于 从这些消息习得的最新视图的主实例的消息,同时所有这些消息都需具有特殊随机数x。然后,此副本会依据主副本提供的消息更新自身信息,并将状态变成正常状态(normal)。
ViewStamped的工程实践优化
1)ViewStamped不要求持久保存内部各个副本状态才能正常工作,在工程实践中可以将各个副本实例的状态存储在持久存储中以便当副本实例崩溃后加快恢复速度。
2)在执行客户端请求之前,主副本实例必须等待Quorum数量的副本实例对每个 请求做出响应。在大型集群中,随着副本实例数量的增加,而增加了主副本实例必须等待响应的其余副本实例的数量,并且增加了遇到某些副本实例变慢以及必须等待更长时间的概率。在这种情况下,可以将整体划分为活动(Active)副本和见证(Witness)副本。 活动副本占

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。


{kind=link}
{kind=link}