
- 1史上最全Nextcloud部署方式,含snap与手动部署两种(已亲测使用)
- 2Docker端口映射_docker port映射
- 3vue2项目打包好之后index.html为空白_vue2项目打包dist后index为空
- 4分布式系统的一致性算法_分布式一致性算法
- 5WPF在ListView绑定数据后如何清空Items的问题_wpf listview清空数据
- 6【iOS开发】Xcode修改中文配置_xcode怎么设置中文版
- 7vue+element-ui给全局请求设置一个loading样式_vue多个请求只显示一个loading效果
- 8CleanMyMac X破解版2024注册机_cleanmymac classic
- 9【密码协议篇】虚拟专用网技术原理与应用(商密)_ike协议实际应用
- 10鸿蒙HarmonyOS开发,颜色资源配置文件添加及使用和自定义圆角背景,把自己踩的坑记下来!!!!_鸿蒙text设置圆角背景
NLP重要概念_nlp cls
赞
踩
记录NLP的一些重要概念,不断更新。
- 1
self-attention

有一种新的layer,叫self-attention,它的输入和输出和RNN是一模一样的,输入一个sequence,输出一个sequence,它的每一个输出b1-b4都看过了整个的输入sequence,每一个输出b1-b4可以并行化计算。





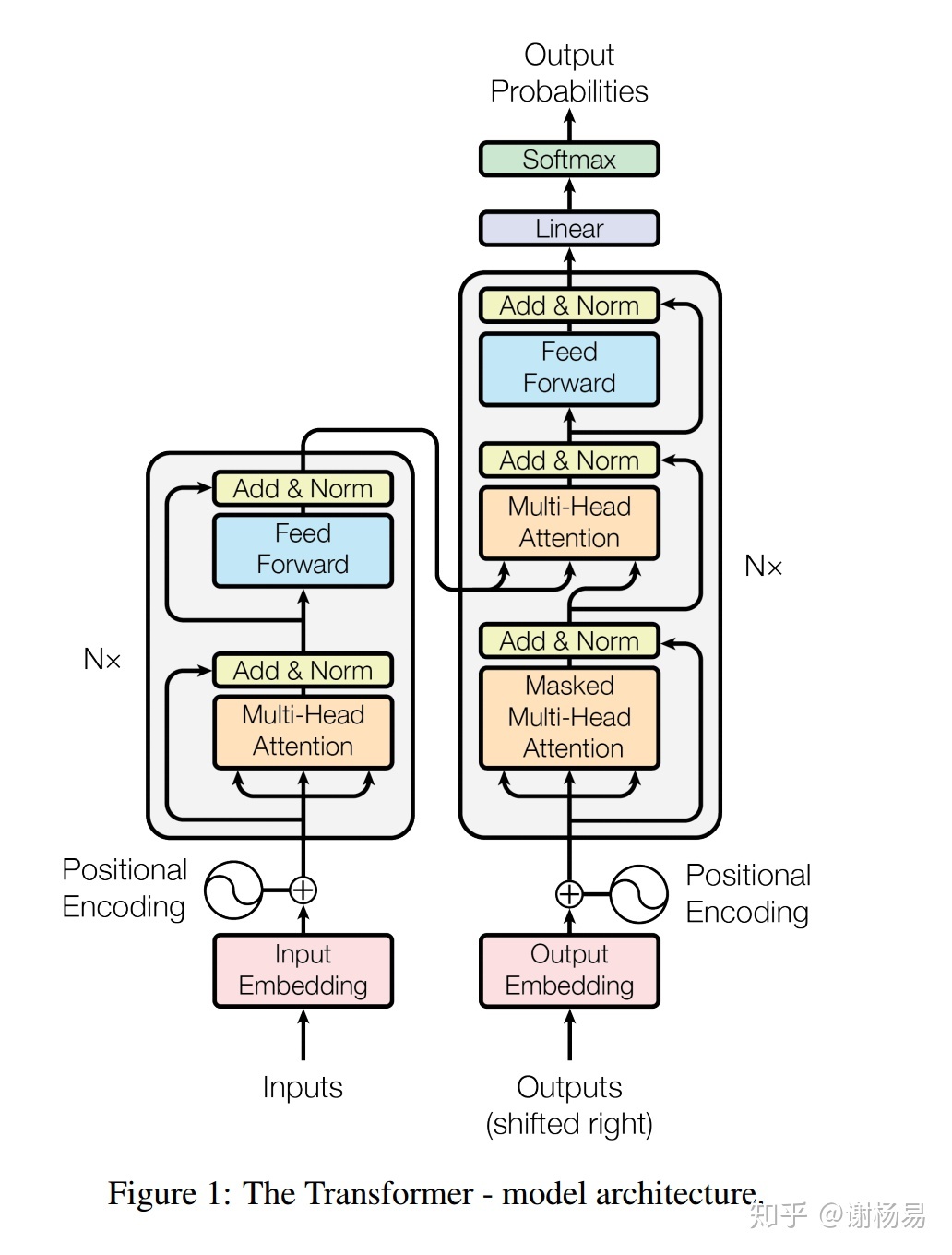
Transformer
Transformer主体框架是一个encoder-decoder结构,摒弃了RNN的序列结构,完全采用attention和全连接。
-
encoder:
-
输入层embedding。输入层对inputs文本做token embedding,并对每个字做position encoding,然后叠加在一起,作为最终的输入。
-
编码层encoding。编码层是多层结构相同的layer堆叠而成。每个layer又包括两部分,multi-head self-attention和feed-forward全连接,并在每部分加入了残差连接和归一化。
encoder layer分为两个子模块
- self attention, 并对输入attention前的和经过attention输出的,做残差连接。残差连接先经过layer-norm归一化,然后进行dropout,最后再做add。后面我们详细分析
- feed-forward全连接,也有残差连接的存在,方式和self attention相同。
MultiHeadedAttention采用多头self-attention。它先将隐向量切分为h个头,然后每个头内部进行self-attention计算,最后再concat再一起。
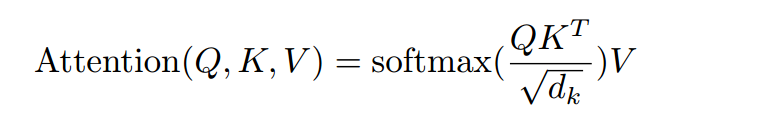
-
-
decoder
decoder结构和encoder大体相同,也是堆叠了N层相同结构的layer(默认6层)。不同的是,decoder的每个子层包括三层。
- masked multi-head self-attention。这一部分和encoder基本相同,区别在于decoder为了保证模型不能看见要预测字的后面位置的字,加入了mask,从而避免未来信息的穿越问题。mask为一个上三角矩阵,上三角全为1,下三角和对角线全为0
- multi-head soft-attention。soft-attention和self-attention结构基本相同,甚至实现函数都是同一个。唯一的区别在于,self-attention的q k v矩阵来自同一个,所以叫self-attention。而soft-attention的q来自decoder,k和v来自encoder。表征的是encoder的整体输出对于decoder的贡献。
- feed-forward。这一块基本相同。
decoder的输出作为最终输出层的输入,经过两步
- linear线性连接,也即是w * x + b
- softmax归一化,向量长度等于vocabulary的长度,得到vocabulary中每个字的概率。利用beam-search等方法,即可得到生成结果。
Bert
BERT自18年10月问世以来,就引起了NLP业界的广泛关注。毫不夸张的说,BERT基本上是近几年来NLP业界意义最大的一个创新,其意义主要包括
- 大幅提高了GLUE任务SOTA performance(+7.7%),使得NLP真正可以应用到各生产环境中,大大推进了NLP在工业界的落地
- 预训练模型从大量人类优质语料中学习知识,并经过了充分的训练,从而使得下游具体任务可以很轻松的完成fine-tune。大大降低了下游任务所需的样本数据和计算算力,使得NLP更加平民化,推动了在工业界的落地。
- pretrain fine-tune两阶段已基本成为NLP业界新的范式,引领了一大波pretrain预训练模型的落地。
- Transformer架构更加深入人心,attention机制基本取代了RNN。有了Transformer后,模型层面创新对NLP任务推动作用比较有限,可以将精力更多的放在数据和任务层面上了。
BERT全称为“Bidirectional Encoder Representations from Transformers”。它是一个基于Transformer结构的双向编码器。其结构可以简单理解为Transformer的encoder部分。如下图所示

最左边即为BERT,它是真正意义上的双向语言模型。双向对于语义表征的作用不言而喻,能够更加完整的利用上下文学习到语句信息。

**Bert的语言输入表示包含了3个组成部分: **
词嵌入张量: word embeddings
语句分块张量: segmentation embeddings
位置编码张量: position embeddings
最终的embedding向量是将上述的3个向量直接做加和的结果。
embedding层
- 从三个embedding表中,通过id查找到对应向量。三个embedding表为word_embeddings,position_embeddings,token_type_embeddings。均是在train阶段训练得到。
- 三个embedding向量直接相加,得到总embedding。注意此处没有加权,因为权值可以被包含在各自embedding中
- 对总embedding进行归一化和dropout
encode层
encoder由多个结构相同的子层BertLayer组成,遍历所有的子层,执行每层的self-attention和feed-forward计算,并保存每层的hidden_state和attention分布
pooler层
pooler层对CLS位置向量,进行全连接和tanh激活,从而得到输出向量。CLS位置向量一般用来代表整个sequence。
ERNIE
基于BERT,更加优秀





