
- 1基于spacy的实体抽取工具_zh_core_web_sm
- 2【AI】大模型API调研及推荐_大模型api 费用大概多少
- 3Linux线程(二)—— 多线程(同步与互斥、线程安全)_linux之线程同步二
- 4CSA发布| 科技创新和云计算趋势中的网络安全因素
- 5本地化部署AI语言模型RWKV指南,ChatGPT顿时感觉不香了。_rwkv-runner
- 6kali linux菜单中各工具功能_kali各个工具作用
- 7车道线检测综述(难点/数据集/主要方案/后处理)
- 8docekr 部署vue项目到nginx服务器,反向代理tomcat服务器_nginx反向代理docekr部署的wordpress,访问域名以后wordpress样式丢失
- 9Visio哪个版本好用?有哪些版本
- 10语义分割论文-DeepLab系列_deeplabv语义分割论文
t-SNE:可视化效果最好的降维算法_t-sne优缺点
赞
踩
PCA-主成分分析是降维领域最主要的算法。它最初是由皮尔逊(Pearson)在1901年开发的,许多人对此做了即兴创作。即使PCA是一种广泛使用的技术,但它的主要缺点是无法维护数据集的局部结构。为了解决这个问题,t-SNE出现了。
1、什么是t-SNE?
t-SNE的主要用途是可视化和探索高维数据。 它由Laurens van der Maatens和Geoffrey Hinton在JMLR第九卷(2008年)中开发并出版。 t-SNE的主要目标是将多维数据集转换为低维数据集。 相对于其他的降维算法,对于数据可视化而言t-SNE的效果最好。 如果我们将t-SNE应用于n维数据,它将智能地将n维数据映射到3d甚至2d数据,并且原始数据的相对相似性非常好。与PCA一样,t-SNE不是线性降维技术,它遵循非线性,这是它可以捕获高维数据的复杂流形结构的主要原因。
2、t-SNE工作原理
首先,它将通过选择一个随机数据点并计算与其他数据点(|x—x|)的欧几里得距离来创建概率分布。 从所选数据点附近的数据点将获得更多的相似度值,而距离与所选数据点较远的数据点将获得较少的相似度值。 使用相似度值,它将为每个数据点创建相似度矩阵(S1)。
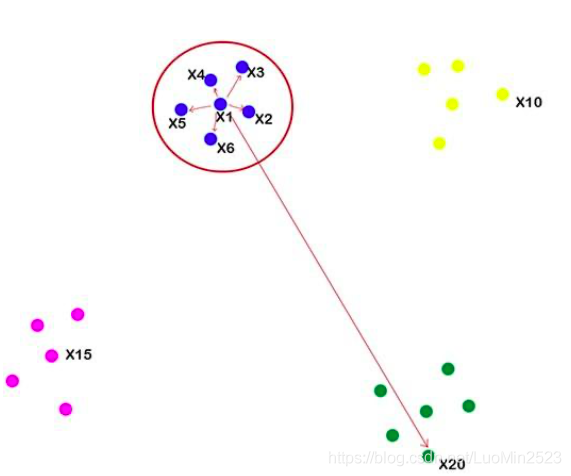
通过以上的计算,t-SNE将所有数据点随机排列在所需的较低维度上。

t-SNE将再次对高维数据点和随机排列的低维数据点进行所有相同的计算。 但是在这一步中,它根据t分布分配概率。 这就是名称t-SNE的原因。t-SNE中使用t分布的目的是减少拥挤问题(后面与PCA对比可见)。
但是请记住,对于高维数据,该算法根据正态分布分配概率。
对于较低维的数据点,还将创建一个相似度矩阵(S2)。然后该算法将S1与S2进行比较,并通过处理一些复杂的数学运算来使S1与S2之间有所不同。包括使用两个分布之间的Kullback Leibler散度(KL散度)作为损失函数运行梯度下降算法。使用KL散度通过将两个分布之间相对于数据点位置的值最小化,帮助t-SNE保留数据的局部结构。
在统计学中,Kullback-Leibler散度是对一个概率分布与另一个概率分布如何不同的度量。梯度下降算法是各种机器学习算法中用于最小化损失函数的一种优化算法。
最后,该算法能够得到与原始高维数据相对相似度较好的低维数据点。
我们可以使用sklearn.manifold.TSNE()实现t-SNE算法
PS:一个形象展示t-SNE优化技巧的网站How to Use t-SNE Effectively.
3、t-SNE优缺点
t-SNE可降样本点间的相似度关系转化为概率:在原空间(高维空间)中转化为基于高斯分布的概率;在嵌入空间(二维空间)中转化为基于t分布的概率。这使得t-SNE不仅可以关注局部(SNE只关注相邻点之间的相似度映射而忽略了全局之间的相似度映射,使得可视化后的边界不明显),还关注全局,使可视化效果更好(簇内不会过于集中,簇间边界明显)。
目标函数:原空间与嵌入空间样本分布之间的KL散度。
优化算法:梯度下降。
注意问题:KL散度作目标函数是非凸的,故可能需要多次初始化以防止陷入局部次优解。
t-SNE的缺点:
- 计算量大,耗时间是PCA的百倍,内存占用大。
- 专用于可视化,即嵌入空间只能是2维或3维。
- 需要尝试不同的初始化点,以防止局部次优解的影响。
4、简单的实现
t-SNE算法可视化sklearn库中的手写字体数据集
- import numpy as np
- import sklearn
- from sklearn.manifold import TSNE
- from sklearn.datasets import load_digits
-
- # Random state.
- RS = 20150101
-
- import matplotlib.pyplot as plt
- import matplotlib.patheffects as PathEffects
- import matplotlib
-
- # We import seaborn to make nice plots.
- import seaborn as sns
- sns.set_style('darkgrid')
- sns.set_palette('muted')
- sns.set_context("notebook", font_scale=1.5,
- rc={"lines.linewidth": 2.5})
- digits = load_digits()
- # We first reorder the data points according to the handwritten numbers.
- X = np.vstack([digits.data[digits.target==i]
- for i in range(10)])
- y = np.hstack([digits.target[digits.target==i]
- for i in range(10)])
- digits_proj = TSNE(random_state=RS).fit_transform(X)
-
- def scatter(x, colors):
- # We choose a color palette with seaborn.
- palette = np.array(sns.color_palette("hls", 10))
-
- # We create a scatter plot.
- f = plt.figure(figsize=(8, 8))
- ax = plt.subplot(aspect='equal')
- sc = ax.scatter(x[:,0], x[:,1], lw=0, s=40,
- c=palette[colors.astype(np.int)])
- plt.xlim(-25, 25)
- plt.ylim(-25, 25)
- ax.axis('off')
- ax.axis('tight')
-
- # We add the labels for each digit.
- txts = []
- for i in range(10):
- # Position of each label.
- xtext, ytext = np.median(x[colors == i, :], axis=0)
- txt = ax.text(xtext, ytext, str(i), fontsize=24)
- txt.set_path_effects([
- PathEffects.Stroke(linewidth=5, foreground="w"),
- PathEffects.Normal()])
- txts.append(txt)
-
- return f, ax, sc, txts
-
- scatter(digits_proj, y)
- plt.savefig('digits_tsne-generated.png', dpi=120)
- plt.show()

可视化结果如下图所示。

更多数据集可以参考网站:http://www.face-rec.org/databases
TSNE的学习网址:
https://scikit-learn.org/stable/modules/generated/sklearn.manifold.TSNE.html
参考资料:
https://baijiahao.baidu.com/s?id=1685017041330123531&wfr=spider&for=pc

