
- 1让人工智能机器人学会自我情绪管理
- 2Linux使用openssl工具生成私钥(private.pem)和公钥(public.pem)_openssl 根据私钥创建公钥文件public_key.pem
- 3springboot项目集成Spring cloud alibaba nacos入门_springboot如何集成到springcloudalibaba
- 4Linux下载命令之 wget 实用参数详解_wget.download 参数
- 5SQL server 安全基线 安全加固操作_建立sql server数据库安全访问基线
- 6华为OD机试 - 两个字符串间的最短路径问题(Java & JS & Python & C & C++)_给定两个字符串,分别为字符串a与字符串b。例如a字符串为abcabba,b字符串为cbabac
- 7第九章:AI大模型的产业应用与前景9.3 AI大模型的社会影响9.3.2 人工智能与生活...
- 8低代码开发与物联网应用:重塑未来技术生态
- 9android自定义弹出对话框,使用FlyDialog实现自定义Android弹窗对话框
- 10Python实现简单的智能助手_python 智能语音助手
重磅︱文本挖掘深度学习之word2vec的R语言实现_r语言word2vec
赞
踩
笔者寄语:2013年末,Google发布的 word2vec工具引起了一帮人的热捧,大家几乎都认为它是深度学习在自然语言领域的一项了不起的应用,各种欢呼“深度学习在自然语言领域开始发力 了”。
基于word2vec现在还出现了doc2vec,word2vec相比传统,考虑单词上下文的语义;但是doc2vec不仅考虑了单词上下文的语义,还考虑了单词在段落中的顺序。
如果想要了解word2vec的实现原理,应该读一读官网后面的三篇参考文献。显然,最主要的应该是这篇: Distributed Representations of Words and Phrases and their Compositionality
这篇文章的基础是 Natural Language Processing (almost) from Scratch 其中第四部分提到了把deep learning用在NLP上。
强力推荐:一个在线测试的网站,貌似是一位清华教授做的:http://cikuapi.com/index.php[2]
笔者又写了一篇相关内容,推荐:
重磅︱R+NLP:text2vec包简介(GloVe词向量、LDA主题模型、各类距离计算等)
———————————————————————————————————————————————
一、word2vec词向量由来
在word2vec产生前,还有一些语言模型,在自然语言处理 NLP模型中,到达word2vec历经了一些步骤。但是对于NLP模型中,起到确定性作用的是词向量(Distributed Representation/word Embedding)的提出,在这之前有一些基础性的模型如统计语言模型、神经网络概率语言模型。
几个基于统计的传统语言模型与word2vec这种直接预测的方法的比较(图片摘自Stanford CS244)【5】:

1、统计语言模型
统计语言模型的一般形式直观、准确,n元模型中假设在不改变词语在上下文中的顺序前提下,距离相近的词语关系越近,距离较远的关联度越远,当距离足够远时,词语之间则没有关联度。
但该模型没有完全利用语料的信息:
(1) 没有考虑距离更远的词语与当前词的关系,即超出范围n的词被忽略了,而这两者很可能有关系的。
例如,“华盛顿是美国的首都”是当前语句,隔了大于n个词的地方又出现了“北京是中国的首都”,在n元模型中“华盛顿”和“北京”是没有关系的,然而这两个句子却隐含了语法及语义关系,即”华盛顿“和“北京”都是名词,并且分别是美国和中国的首都。
(2) 忽略了词语之间的相似性,即上述模型无法考虑词语的语法关系。
例如,语料中的“鱼在水中游”应该能够帮助我们产生“马在草原上跑”这样的句子,因为两个句子中“鱼”和“马”、“水”和“草原”、“游”和“跑”、“中”和“上”具有相同的语法特性。
而在神经网络概率语言模型中,这两种信息将充分利用到。
2、神经网络概率语言模型
神经网络概率语言模型是一种新兴的自然语言处理算法,该模型通过学习训练语料获取词向量和概率密度函数,词向量是多维实数向量,向量中包含了自然语言中的语义和语法关系,词向量之间余弦距离的大小代表了词语之间关系的远近,词向量的加减运算则是计算机在"遣词造句"。
如今在架构方面有比NNLM更简单的CBOW模型、Skip-gram模型;其次在训练方面,出现了Hierarchical Softmax算法、负采样算法(Negative Sampling),以及为了减小频繁词对结果准确性和训练速度的影响而引入的欠采样(Subsumpling)技术。
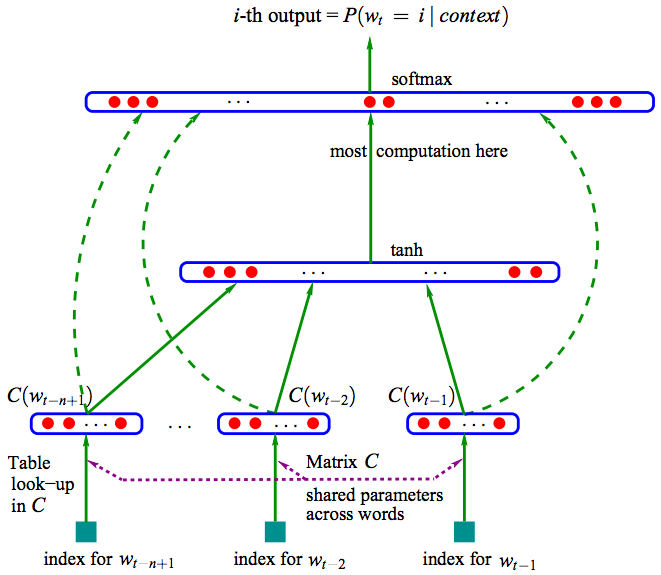
上图是基于三层神经网络的自然语言估计模型NNLM(Neural Network Language Model)。NNLM可以计算某一个上下文的下一个词为wi的概率,即(wi=i|context),词向量是其训练的副产物。NNLM根据语料库C生成对应的词汇表V。
———————————————————————————————————————————————
二、word2vec——词向量特征提取模型
先解释一下词向量:将词用“词向量”的方式表示可谓是将 Deep Learning 算法引入 NLP 领域的一个核心技术。自然语言理解问题转化为机器学习问题的第一步都是通过一种方法把这些符号数学化。
词向量具有良好的语义特性,是表示词语特征的常用方式。词向量的每一维的值代表一个具有一定的语义和语法上解释的特征。故可以将词向量的每一维称为一个词语特征。词向量用Distributed Representation表示,一种低维实数向量。
例如,NLP中最直观、最常用的词表示方法是One-hot Representation。每个词用一个很长的向量表示,向量的维度表示词表大小,绝大多数是0,只有一个维度是1,代表当前词。“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …] 即从0开始话筒记为3。
但这种One-hot Representation采用稀疏矩阵的方式表示词,在解决某些任务时会造成维数灾难,而使用低维的词向量就很好的解决了该问题。同时从实践上看,高维的特征如果要套用Deep Learning,其复杂度几乎是难以接受的,因此低维的词向量在这里也饱受追捧。
Distributed Representation低维实数向量,如:[0.792, ?0.177, ?0.107, 0.109, ?0.542, …]。它让相似或相关的词在距离上更加接近。
总之,Distributed Representation是一个稠密、低维的实数限量,它的每一维表示词语的一个潜在特征,该特征捕获了有用的句法和语义特征。其特点是将词语的不同句法和语义特征分布到它的每一个维度上去表示。
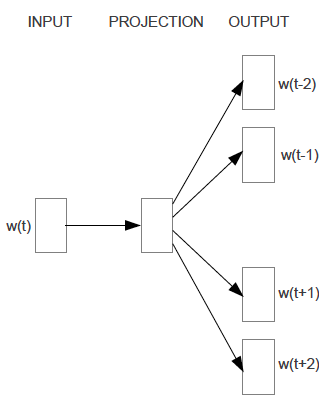
再来看看结合deep learning的词向量是如何获取的。谈到word2vec的词向量,就得提到两个模型——DBOW以及skip-gram模型。两个模型都是根据上下文词,来推断当前词发生的概率。可以实现两个基本目标:这句话是否是自然语句;获得词向量。两个模型的大致结构如下图所示:
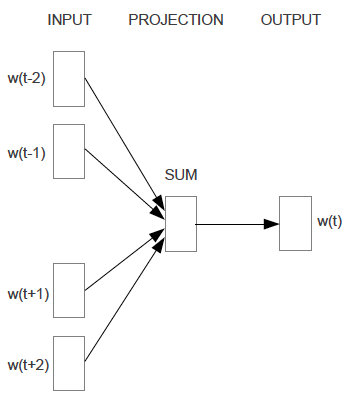
1、 CBOW加层次的网络结构((Continuous Bag-Of-Words Model,连续词袋模型))
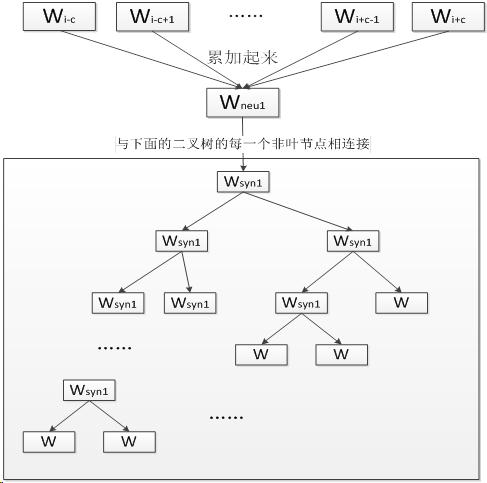
其中第一层,也就是最上面的那一层可以称为输入层。输入的是若干个词的词向量,中间在神经网络概率语言模型中从隐含层到输出层的计算时主要影响训练效率的地方,CBOW和Skip-gram模型考虑去掉隐含层。实践证明新训练的词向量的精确度可能不如NNLM模型(具有隐含层),但可以通过增加训练语料的方法来完善。第三层是方框里面的那个二叉树,叫霍夫曼树,W代表一个词,Wsyn1是非叶节点是一类词堆,还要继续往下分。
这个网络结构的功能是为了完成一个的事情——判断一句话是否是自然语言。怎么判断呢?使用的是概率,就是计算一下这句话的“一列词的组合”的概率的 连乘(联合概率)是多少,如果比较低,那么就可以认为不是一句自然语言,如果概率高,就是一句正常的话。
计算的公式是下面的公式:
p(s)=p(w1,w2,⋯wT)=∏i=1Tp(wi|Contexti)
其中的Context表示的是该词的上下文,也就是这个词的前面和后面各若干个词,这个“若干”(后面简称c)一般是随机的,也就是一般会从1到5之间的一个随机数。举个例子就是:“大家 喜欢 吃 好吃 的 苹果”这句话总共6个词,假设对“吃”这个词来说c随机抽到2,则“吃”这个词的context是“大家”、“喜欢”、“好吃”和“的”,总共四个词,这四个词的顺序可以乱,这是word2vec的一个特点。假设就是计算“吃”这个词的在“大家”、“喜欢”、“好吃”和“的”这四个词作为上下文的条件 概率,则
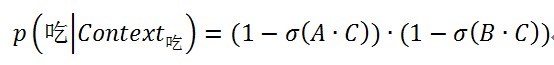
其中 σ(x)=1/(1+e−x) ,是sigmoid公式。
这个神经网络最重要的是输出层的那个霍夫曼树的叶子节点上的那些向量,那些向量被称为词向量,词向量就是另外一篇博文里面介绍的,是个好东西。运用上面那个“吃”的例子。
笔者自问自答(以下都是笔者自己的观点,如有疑问千万不要找我,哈哈...):
为啥要用霍夫曼树来储存词?
答:可以知道霍夫曼树可以储存着语料库所有的词,每一个节点就是一个词(W)或者众多词在一起的向量节点(Wsyn1)。但是用这棵树来存储词的方式的确很特别,原因是因为求解词条件概率时候应用到了神经网络的能量模型:
P(吃︱Context)=p(A|C)=e−E(A,C)∑Vv=1e−E(wv,C)
其中C是这个词的上下文的词向量的和(向量的和),V表示语料库里面的的词元(词组的概念)的个数;整个语料库有W个词。
这个公式的意思就是在上下文C出现的情况下,中间这个词是A的概率,为了计算这个概率,肯定得把语料库里面所有的 词的能量都算一次,然后再根据词A的能量,那个比值就是出现A的概率。
这个概率其实并不好统计,为了算一个词的的概率,得算上这种上下文的情况下所有词的能量,然后还计算指数值再加和。所以把语料库的所有词分成两类,分别称为G类和H类,每类一半,其中词A属于G类,那么下面的式子就可以成立了
p(A│C)=p(A|G,C)p(G|C) =e−E(A,C)∑W∈Ge−E(W,C)×11+e−E(H−G,C)
还是存在E能量难算,又把语料库切割下去。这个过程就像是建立分支树的过程。
有了这个霍夫曼树,怎么得出词向量?
答:假如“吃”这个字在最右边的W,那边他要经过的步骤是:Wsyn1(1)→Wsyn1(2.2)→W。每分开一次节点,就有一次节点选择,这个选择就是一个Logistic函数,可能Wsyn1(1)→Wsyn1(2.2)左右的概率分别是[0.6,0.4],Wsyn1(2.2)→W的概率是[0.3,0.7],那么W“吃”就可以表示为[0.4,0.7]。
其中提到的logistic regression模型,是因为
P(吃︱Context)=∏k=1Kp(dk|qk,C)=∏k=1K((σ(qk⋅C))1−dk⋅(1−σ(qk⋅C))dk)
这个公式是把p(A│C)=p(A|G,C)p(G|C) 中的语料库切割无数次之后得到的最终函数形式。那么求解函数,就得到了以下的似然函数,最后通过数学等式得到了如图所示的公式。
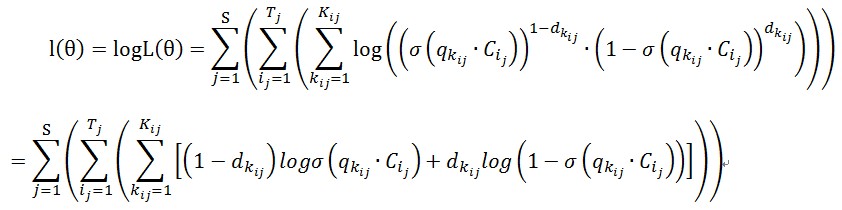
dk表示树枝的左右向,dk=1向左分,dk=0向右分。
word2vec就是这么考虑的,把在霍夫曼树向左的情况,也就是dk=0的情况认为是正类,概率就可以算出来是σ(qijk⋅Contextij),而负向的(dk=1)就是1-σ(qijk⋅Contextij)。
每个叶子节点都产生一个样本,这个样本的label(也就是属于正类或者负类标 志)可以用霍夫曼编码来产生,前面说过了,向左的霍夫曼编码dk=0,所以很自然地可以用1-dk表示每个样本label。霍夫曼编码也变成了一个词向量之前很重要的东西。
2、Skip-gram模型(Skip-Gram(Continuous Skip-GramModel))

词Wi与huffman树直接连接,没有隐藏层的。使用方法依然与cbow加层次的相似。在判断“大家 喜欢 吃 好吃 的 苹果”这句话是否自然语言的时候,是这么来的,同样比如计算到了“吃”这个词,同样随机抽到的c=2,对吃这个词需要计算的东西比较多,总共要计算的概率 是p(大家|吃),p(喜欢|吃),p(好吃|吃)和p(的|吃)总共四个。
P(吃︱Context)=p(大家|吃)×p(喜欢|吃)×p(好吃|吃)×p(的|吃) 其中p(大家│吃)=(1-σ(A?D))?σ(B?D)?σ(C?D)...(还有三个)
把一整句话的所有词的概率都计算出来后进行连乘,得到的就是这句话是自然语言的概率。这个概率如果大于某个阈值,就认为是正常的话;否则就认为不是自然语言,要排除掉【3】。
有一个比较简易的解读见【4】Skip-gram表示“跳过某些符号”。例如句子“中国足球踢得真是太烂了”有4个3元词组,分别是“中国足球踢得”、“足球踢得真是”、“踢得真是太烂”、“真是太烂了”,句子的本意都是“中国足球太烂”,可是上面4个3元组并不能反映出这个信息。
此时,使用Skip-gram模型允许某些词被跳过,因此可组成“中国足球太烂”这个3元词组。如果允许跳过2个词,即2-Skip-gram,那么上句话组成的3元词组为:

由上表可知:一方面Skip-gram反映了句子的真实意思,在新组成的这18个3元词组中,有8个词组能够正确反映例句中的真实意思;另一方面,扩大了语料,3元词组由原来的4个扩展到了18个。
语料的扩展能够提高训练的准确度,获得的词向量更能反映真实的文本含义。
完成了两大目标:考虑距离更远的词语与当前词的关系;生成充分的语料库,并且有正确的词意词元。
———————————————————————————————————————————————
三、一些应用案例word2vec
1、广告推荐:布置在ANSJ上进行新闻关键词提取,抽调googlecode.com包,得到了计算每个词与最接近词之间的距离(distance)、还可以执行聚类【利用word2vec对关键词进行聚类】。
2、网络语料库包的训练实践:从网络的一些有名的语料包进行训练、在cygwin(因为word2vec需要linux环境,所有首先在windows下安装linux环境模拟器),抽调googlecode.com,并详细解释了函数系数。【Windows下使用Word2vec继续词向量训练】
3、兴趣挖掘的必要性。利用word2vec给广告主推荐用户,只是简单分析没有实操,但是提到了论文《互联网广告综述之点击率系统》中的一些方法。【深度学习 word2vec 笔记】
———————————————————————————————————————————————
四、R语言中tmcn.word2vec
R语言中word2vec包,目前看到有一个叫tmcn.word2vec。该包真是一个草率、任性的包, 作者Jian Li,写于2014年9月21日。而且貌似后期也没有维护,不过作者貌似同时也在网上发布了word2vec自编译的函数。笔者猜测作者同时发布了两个版本用R实现word2vec的方式。
两种实现途径分别为:tmcn.word2vec包、自编译函数。
1、word2vec包的介绍
作者上传的word2vec包即为简单,只有两个函数,第一个函数是word2vec,第二个函数计算单词之间cos距离。两个函数基本没什么附加的参数可以调节。
包的下载地址可见链接:https://r-forge.r-project.org/R/?group_id=1571
或者通过install的方式,但是笔者未能通过下面的方式直接下载到。
install.packages("tmcn.word2vec", repos="http://R-Forge.R-project.org")包中有三个demo案例,笔者在这贴出来:
(1)第一个demo
第一个是英文的word2vec方法的列举。
require(tmcn.word2vec)
# English characters
TrainingFile1 <- system.file("examples", "rfaq.txt", package = "tmcn.word2vec")
ModelFile1 <- file.path(tempdir(), "output", "model1.bin")
res1 <- word2vec(TrainingFile1, ModelFile1)
dist1 <- distance(res1$model_file, "object")
nrow(dist1)distance代表在word2vec所得到的词向量中,“object”词与其他单词之间的距离(一般采用CosDist距离)。该函数给出了与object最近的20个词语。
(2)第二个demo
中文内容的,是金庸的小说为输入预料。
> TrainingFile2 <- system.file("examples", "xsfh_GBK.txt", package = "tmcn.word2vec")
> ModelFile2 <- file.path(tempdir(), "output", "model2.bin")
>
> res2 <- word2vec(TrainingFile2, ModelFile2)
Starting training using file ./R-3.2.2/library/tmcn.word2vec/examples/xsfh_GBK.txt
Vocab size: 1145
Words in train file: 27824
Alpha: 0.000000 Progress: 790.77% Words/thread/sec: 22.69k The model was generated in 'C:/Users/long/AppData/Local/Temp/Rtmpm460Qd/output'!
> dist2 <- distance(res2$model_file, intToUtf8(c(33495, 20154, 20964)))
Word: ���˷� Position in vocabulary: 316
> dist2
Word CosDist
1 可是 0.3918099
2 呼 0.2853436
3 踏 0.2702354
4 多 0.2539852
5 眼光 0.2498445
6 较 0.2495218
7 盒 0.2491589
8 群雄 0.2380990
9 后面 0.2367072
10 几 0.2354743
11 一只 0.2346973
12 一齐 0.2282183
13 夺 0.2276031
14 他 0.2262077
15 </s> 0.2241129
16 一招 0.2232552
17 双刀 0.2226523
18 救 0.2194796
19 学 0.2124971
20 即 0.2113202
代码解读:输入的语料库是分好词的,intToUtf8(c(33495, 20154, 20964))是一个词——“苗人凤”。经过运算得出了与其最近的词,看前20个词貌似没有啥特别有用的信息。
(3)第三个demo代码
# Chinese characters in UTF-8 encoding, for *nix
TrainingFile3 <- system.file("examples", "xsfh_UTF8.txt", package = "tmcn.word2vec")
ModelFile3 <- file.path(tempdir(), "output", "model3.bin")
res3 <- word2vec(TrainingFile3, ModelFile3)
dist3 <- distance(res3$model_file, intToUtf8(c(33495, 20154, 20964)))
dist32、word2vec自编译函数
自编译函数需要自己布置一些环境,但是也只有两个函数,word2vec和distance函数。但是能够设置参数。自编译代码改写自google。应该这个自编译函数需要有这么几个步骤:
(1)仔细阅读.c.call extensions.pdf文件。其中详细写出了如何在电脑中搭建一个适用于R语言的二进制数据库;
(2)windows系统下,需要下载Rtools.exe文件,并改变环境变量的路径,同时重启计算机;
(3)看train_word2vec.R,其中有R中如何调用word2vec的API。
具体的可以从 http://download.csdn.net/download/sinat_26917383/9513075 下载得到完整的自编译函数、说明以及上述提到的PDF文档。
笔者在这简单叙述一下word2vec函数中的一些参数:
word2vec <- function (train_file, output_file,
binary=1, # output format, 1-binary, 0-txt
cbow=0, # skip-gram (0) or continuous bag of words (1)
num_threads = 1, # num of workers
num_features = 300, # word vector dimensionality
window = 10, # context / window size
min_count = 40, # minimum word count
sample = 1e-3, # downsampling of frequent words
classes = 0
)
# The parameters:
# binary - output format of the model;
#
# cbow - which algorithm to use for training or skip-gram bag of words (cbow).
# Skip-gram is slower but produces a better result on the rare words;
#
# num_threads - Processor number of threads involved in the construction of the model;
#
# num_features - the dimension of words (or a vector for each word), it is recommended from tens to hundreds;
#
# window - as many words from the context of the training algorithm should be taken into account;
#
# min_count - limits the size of a boost word dictionary.
# Words that are not found in the text more than the specified number are ignored.
# Recommended value - from ten to one hundred;
#
# sample - the lower limit of the frequency of occurrence of words in the text,
# it is recommended from .00001 to .01. 以下关于参数的解释是来源于linux环境模拟器,cygwin中操作,用Java来调用的,发现R中这个包也跟这个函数参数,大同小异,而且解释很清楚,所以非常感谢作者的细心翻译[1]。
参数解释:
-train_file 训练数据
-output_file 结果输入文件,即每个词的向量
-cbow 是否使用cbow模型,0表示使用skip-gram模型,1表示使用cbow模型,默认情况下是skip-gram模型,cbow模型快一些,skip-gram模型效果好一些
-num_features 表示输出的词向量维数
-window 为训练的窗口大小,8表示每个词考虑前8个词与后8个词(实际代码中还有一个随机选窗口的过程,窗口大小<=5)
-sample 表示 采样的阈值,如果一个词在训练样本中出现的频率越大,那么就越会被采样
-binary 表示输出的结果文件是否采用二进制存储,0表示不使用(即普通的文本存储,可以打开查看),1表示使用,即vectors.bin的存储类型
-------------------------------------
除了上面所讲的参数,还有:
-alpha 表示 学习速率
-min-count 表示设置最低频率,默认为5,如果一个词语在文档中出现的次数小于该阈值,那么该词就会被舍弃
-classes 表示词聚类簇的个数,从相关源码中可以得出该聚类是采用k-means
模型训练完成之后,得到了.bin这个词向量文件,文件的存储类型由binary参数觉得,如果为0,便可以直接用编辑器打开,进行查看.其中word2vec中提供了distance求词的cosine相似度,并排序。也可以在训练时,设置-classes参数来指定聚类的簇个数,使用kmeans进行聚类。
disttance函数。
由于word2vec计算的是余弦值,距离范围为0-1之间,值越大代表这两个词关联度越高,所以越排在上面的词与输入的词越紧密[2]。
distance(file_name, word,size)
一个在线测试的网站,貌似是一位清华教授做的:http://cikuapi.com/index.php[2]
3、关于两者体会
(1)word2vec的自编译函数在使用时也需要加载tmcn.word2vec包,笔者在使用过程中直接调用word2vec函数的话,会出现一下的error情况:
Error in .C("CWrapper_word2vec", train_file = as.character(train_file), :
C symbol name "CWrapper_word2vec" not in load table(2)tmcn.word2vec与word2vec自编译是可以互补的。在require(tmcn.word2vec)之后,可以直接调用word2vec函数,而且自编译函数可以调节参数,而且有一个非常bug的功能,可以自行聚类,这个非常厉害,并且可以通过cbow=0的参数选择使用CBOW模型还是skip-gram模型,并且通过binary=0参数可以调整输出的是txt文件,而且tmcn.word2vec包中输出只有.bin文件,难以读取。
(3)tmcn.word2vec与word2vec自编译中两个word2vec生成不一样的语料库,同时执行distance函数之后也计算不一样的词距离。(接下来的结论,是由笔者自己推测)语料库不同的原因:因为CBOW模型与Skip-gram模型在抽取近邻词的时候也会采用随机抽样的方法,所以会产生不一样的结果;distance函数不同的原因,因为语料库的不同,笔者在设定了(set.seed)随机数之后,得到了相同的distance结果。
(4)笔者推断最佳的使用tmcn.word2vec步骤是:加载包(require(tmcn.word2vec))、执行自编译函数(word2vec/distance)、设定随机数(set.seed)(很关键,会影响输出结果)、用自编译函数来执行分析任务(选择模型、是否聚类、是否输出txt文件、词维度、词数量等)。
———————————————————————————————————————————————
四、text2vec包
该包写于2016年3月21日,全名是Fast Text Mining Framework for Vectorization and Word Embeddings,矢量化词向量文本挖掘模型。
关于这个包,有待研究。
参考博客:
3、深度学习 word2vec 笔记
4、word2vec词向量训练及中文文本相似度计算
5、word2vec——高效word特征求取
6、《Word2vec的工作原理及应用探究 · 周练 · 西安电子科技大学2014年》
7、《Word2vec对中文词进行聚类的研究 · 郑文超,徐鹏 · 北京邮电大学2013年》
8、《Word2vec的核心架构及其应用 · 熊富林,邓怡豪,唐晓晟 · 北邮2015年》
————————————————————————————————————————
延伸一:详解word2vec生成过程
在word2vec工具中,主要的工作包括:
- 预处理。即变量的声明,全局变量的定义等;
- 构建词库。即包含文本的处理,以及是否需要有指定词库等;
- 初始化网络结构。即包含CBOW模型和Skip-Gram模型的参数初始化,Huffman编码的生成等;
- 多线程模型训练。即利用Hierarchical Softmax或者Negative Sampling方法对网络中的参数进行求解;
- 最终结果的处理。即是否保存和以何种形式保存。

