
- 1make a vcard/vcal Ndef message on Android_text/x-vcard
- 21.《一个物联网系统的实现》之使用微信小程序给ESP32C3配网_物联网小程序 教程
- 3vnc viewer 远程桌面,vnc viewer 远程桌面使用教程
- 4细粒度识别 DCL 论文及代码学习笔记_细粒度目标识别
- 5鸿蒙系统开发教程提纲_鸿蒙开发课程大纲
- 6关于 Qt报错“No rule to make target xxxx 长路径”一种非常规问题定位(原因:shadow全路径+深度模块依赖相对路径超过系统预定义256字节) 的解决方法_qt没有规则可制作目标
- 7安卓项目报错了Connect timed out_android connect timed out
- 8意图识别bert_bert隐式意图判断
- 9linux暑期实践1-字符界面与常用命令_尝试在字符界面用ls命令查询新建文件夹
- 10用灰度发布功能实现A/B测试_a/b测试 灰度落地方案
NLP之预训练语言模型GPT
赞
踩

来源:信息网络工程研究中心
本文约4000字,建议阅读8分钟
本文将围绕 ScienceAdvances 的一篇论文,介绍如何利用机器学习,对燃煤电厂的胺排放量进行预测。
目录
引言
适配下游任务
GPT代码
例子
调用huggingface的模型
微调用在其他任务上
引言
在自然语言处理领域中,预训练模型通常指代的是预训练语言模型。广义上的预训练语言模型可以泛指提前经过大规模数据训练的语言模型,包括早期的以Word2vec、GloVe为代表的静态词向量模型,以及基于上下文建模的CoVe、ELMo等动态词向量模型。
在2018年,以GPT和BERT为代表的基于深层Transformer的表示模型出现后,预训练语言模型这个词才真正被大家广泛熟知。因此,目前在自然语言处理领域中提到的预训练语言模型大多指此类模型。预训练语言模型的出现使得自然语言处理进入新的时代,也被认为是近些年来自然语言处理领域中的里程碑事件。
OpenAI 公司在2018年提出了一种生成式预训练(Generative Pre-Training,GPT)模型用来提升自然语言理解任务的效果,正式将自然语言处理带入“预训练”时代。“预训练”时代意味着利用更大规模的文本数据以及更深层的神经网络模型学习更丰富的文本语义表示。同时,GPT的出现打破了自然语言处理各个任务之间的壁垒,使得搭建一个面向特定任务的自然语言处理模型不再需要了解非常多的任务背景,只需要根据任务的输入输出形式应用这些预训练语言模型,就能够达到一个不错的效果。因此,GPT提出了“生成式预训练+判别式任务精调”的自然语言处理新范式,使得自然语言处理模型的搭建变得不再复杂。
所以以往大家的工作模式是:
1.各个公司会自己去github下载代码,
2.然后公司出钱捞数据,打标,
3.工程师用自己公司的打标数据去训练来完成业务的需求
但是随着huggingface的成立,现在大家的工作模式是:
1.算法工程师打开huggingface网页,搜业务相关的预训练模型(这些模型都是大厂基于大量的数据训练好的模型),下载
2.算法工程师自己收集或者标记少量的数据;
3.微调下载的模型
公认的很好地讲解GPT的是jalammar的gpt2;http://jalammar.github.io/illustrated-gpt2/。
GPT
GPT的论文内容及结构还是挺简单的。

如GPT-1: Improving Language Understanding by Generative Pre-Training关于论文的翻译,如下截图(懒得打字)。


其实缩写就是:
| GPT的阶段 | 描述 |
|---|---|
| 预训练阶段 | 以语言建模作为训练目标,将Transformer的Decoder部分用于无监督预训练任务, |
| 微调阶段 | 将训练好的Decoder参数固定,接上一层线性层,通过有监督训练任务微调线性层的参数,从而进行预测 |
适配下游任务
不同任务之间的输入形式各不相同,应如何根据不同任务适配GPT的输入形式成为一个问题。典型的任务在GPT中的输入输出形式,其中包括:单句文本分类、文本蕴含、相似度计算和选择型阅读理解:
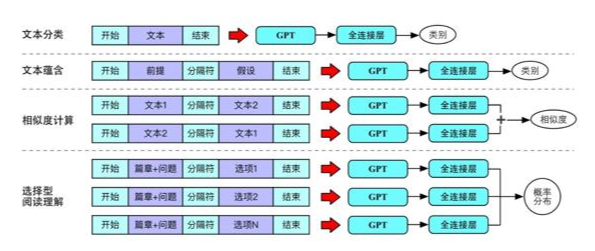
GPT代码
我们参考莫凡的代码来分析,这里莫凡用的是encoder,而论文说用decoder,看GPT模型介绍并且使用pytorch实现一个小型GPT中文闲聊系统的实现名称叫decoder,其实也是transformer的encoder部分。
原因就是:用着Decoder的 Future Mask (Look Ahead Mask),但结构上又更像Encoder。
首先基于transformer编写encoder,假设下述代码在transformer.py中
- import tensorflow as tf
- from tensorflow import keras
- import numpy as np
- import utils # this refers to utils.py in my [repo](https://github.com/MorvanZhou/NLP-Tutorials/)
- import time
- import pickle
- import os
-
-
- MODEL_DIM = 32
- MAX_LEN = 12
- N_LAYER = 3
- N_HEAD = 4
- DROP_RATE = 0.1
- self.wv = keras.layers.Dense(n_head * self.head_dim) # [n, step, h*h_dim]
-
-
- # 输出为
- self.o_dense = keras.layers.Dense(model_dim)
- self.o_drop = keras.layers.Dropout(rate=drop_rate)
- self.attention = None
-
-
- def call(self, q, k, v, mask, training):
- # 先基于给定的q,k,v计算https://www.cnblogs.com/shouhuxianjian/p/16165451.html#3-multiheadedattention 图中下面的linear部分
- _q = self.wq(q) # [n, q_step, h*h_dim]
- _k, _v = self.wk(k), self.wv(v) # [n, step, h*h_dim]
-
-
- # 将q k v进行切分为了后面算多头
- _q = self.split_heads(_q) # [n, h, q_step, h_dim]
- _k, _v = self.split_heads(_k), self.split_heads(_v) # [n, h, step, h_dim]
-
-
- # 将多头concat起来
- context = self.scaled_dot_product_attention(_q, _k, _v, mask) # [n, q_step, h*dv]
-
-
- # https://www.cnblogs.com/shouhuxianjian/p/16165451.html#3-multiheadedattention 图中上面的linear
- o = self.o_dense(context) # [n, step, dim]
- o = self.o_drop(o, training=training)
- return o
-
-
-
-
- def split_heads(self, x):
- x = tf.reshape(x, (x.shape[0], x.shape[1], self.n_head, self.head_dim)) # [n, step, h, h_dim]
- return tf.transpose(x, perm=[0, 2, 1, 3]) # [n, h, step, h_dim]
-
-
- def scaled_dot_product_attention(self, q, k, v, mask=None):
- dk = tf.cast(k.shape[-1], dtype=tf.float32)
- score = tf.matmul(q, k, transpose_b=True) / (tf.math.sqrt(dk) + 1e-8) # [n, h_dim, q_step, step]
- if mask is not None:
- score += mask * -1e9
- self.attention = tf.nn.softmax(score, axis=-1) # [n, h, q_step, step]
- context = tf.matmul(self.attention, v) # [n, h, q_step, step] @ [n, h, step, dv] = [n, h, q_step, dv]
- context = tf.transpose(context, perm=[0, 2, 1, 3]) # [n, q_step, h, dv]
- context = tf.reshape(context, (context.shape[0], context.shape[1], -1)) # [n, q_step, h*dv]
- return context
-
-
- #建立逐位置的前向网络
- class PositionWiseFFN(keras.layers.Layer):
- def __init__(self, model_dim):
- super().__init__()
- dff = model_dim * 4
- self.l = keras.layers.Dense(dff, activation=keras.activations.relu)
- self.o = keras.layers.Dense(model_dim)
-
-
- def call(self, x):
- o = self.l(x)
- o = self.o(o)
- return o # [n, step, dim]
-
-
- # 建立encoder层,以方便后面进行重复
- class EncodeLayer(keras.layers.Layer):
- def __init__(self, n_head, model_dim, drop_rate):
- super().__init__()
- self.ln = [keras.layers.LayerNormalization(axis=-1) for _ in range(2)] # only norm z-dim
- self.mh = MultiHead(n_head, model_dim, drop_rate)
- self.ffn = PositionWiseFFN(model_dim)
- self.drop = keras.layers.Dropout(drop_rate)
-
-
- def call(self, xz, training, mask):
-
-
- attn = self.mh.call(xz, xz, xz, mask, training) # [n, step, dim]
- o1 = self.ln[0](attn + xz)
- ffn = self.drop(self.ffn.call(o1), training)
- o = self.ln[1](ffn + o1) # [n, step, dim]
- return o
-
-
- #将encoderlayer进行重复,获取整个编码器
- class Encoder(keras.layers.Layer):
- def __init__(self, n_head, model_dim, drop_rate, n_layer):
- super().__init__()
-
-
- # 重复n_layer层
- self.ls = [EncodeLayer(n_head, model_dim, drop_rate) for _ in range(n_layer)]
-
-
- def call(self, xz, training, mask):
- for l in self.ls:
- xz = l.call(xz, training, mask)
- return xz # [n, step, dim]

然后基于上述Encoder编写gpt
- import tensorflow as tf
- from tensorflow import keras
- import utils # this refers to utils.py in my [repo](https://github.com/MorvanZhou/NLP-Tutorials/)
- import time
- from transformer import Encoder
- import pickle
- import os
-
-
-
-
- class GPT(keras.Model):
- def __init__(self, model_dim, max_len, n_layer, n_head, n_vocab, lr, max_seg=3, drop_rate=0.1, padding_idx=0):
- super().__init__()
- self.padding_idx = padding_idx
- self.n_vocab = n_vocab
- self.max_len = max_len
-
-
- # I think task emb is not necessary for pretraining,
- # because the aim of all tasks is to train a universal sentence embedding
- # the body encoder is the same across all tasks,
- # and different output layer defines different task just like transfer learning.
- # finetuning replaces output layer and leaves the body encoder unchanged.
-
-
- # self.task_emb = keras.layers.Embedding(
- # input_dim=n_task, output_dim=model_dim, # [n_task, dim]
- # embeddings_initializer=tf.initializers.RandomNormal(0., 0.01),
- # )
-
-
- self.word_emb = keras.layers.Embedding(
- input_dim=n_vocab, output_dim=model_dim, # [n_vocab, dim]
- embeddings_initializer=tf.initializers.RandomNormal(0., 0.01),
- )
- self.segment_emb = keras.layers.Embedding(
- input_dim=max_seg, output_dim=model_dim, # [max_seg, dim]
- embeddings_initializer=tf.initializers.RandomNormal(0., 0.01),
- )
- self.position_emb = self.add_weight(
- name="pos", shape=[1, max_len, model_dim], dtype=tf.float32, # [1, step, dim]
- initializer=keras.initializers.RandomNormal(0., 0.01))
-
-
- self.encoder = Encoder(n_head, model_dim, drop_rate, n_layer)
- self.task_mlm = keras.layers.Dense(n_vocab)
- self.task_nsp = keras.layers.Dense(2)
-
-
- self.cross_entropy = keras.losses.SparseCategoricalCrossentropy(from_logits=True, reduction="none")
- self.opt = keras.optimizers.Adam(lr)
-
-
- def call(self, seqs, segs, training=False):
- embed = self.input_emb(seqs, segs) # [n, step, dim]
-
-
- # 需要增加mask
- z = self.encoder(embed, training=training, mask=self.mask(seqs)) # [n, step, dim]
- mlm_logits = self.task_mlm(z) # [n, step, n_vocab]
- nsp_logits = self.task_nsp(tf.reshape(z, [z.shape[0], -1])) # [n, n_cls]
- return mlm_logits, nsp_logits
-
-
-
-
- def step(self, seqs, segs, seqs_, nsp_labels):
- with tf.GradientTape() as tape:
- mlm_logits, nsp_logits = self.call(seqs, segs, training=True)
- pad_mask = tf.math.not_equal(seqs_, self.padding_idx)
- pred_loss = tf.reduce_mean(tf.boolean_mask(self.cross_entropy(seqs_, mlm_logits), pad_mask))
- nsp_loss = tf.reduce_mean(self.cross_entropy(nsp_labels, nsp_logits))
- loss = pred_loss + 0.2 * nsp_loss
- grads = tape.gradient(loss, self.trainable_variables)
- self.opt.apply_gradients(zip(grads, self.trainable_variables))
- return loss, mlm_logits
-
-
-
-
- def input_emb(self, seqs, segs):
- return self.word_emb(seqs) + self.segment_emb(segs) + self.position_emb # [n, step, dim]
-
- def mask(self, seqs):
- """
- abcd--
- a011111
- b001111
- c000111
- d000011
- -000011
- -000011
- force head not to see afterward. eg.
- a is a embedding for a---
- b is a embedding for ab--
- c is a embedding for abc-
- later, b embedding will + b another embedding from previous residual input to predict c
- """
- mask = 1 - tf.linalg.band_part(tf.ones((self.max_len, self.max_len)), -1, 0)
- pad = tf.math.equal(seqs, self.padding_idx)
- mask = tf.where(pad[:, tf.newaxis, tf.newaxis, :], 1, mask[tf.newaxis, tf.newaxis, :, :])
- return mask # (step, step)
-
-
- @property
- def attentions(self):
- attentions = {
- "encoder": [l.mh.attention.numpy() for l in self.encoder.ls],
- }
- return attentions
-
-
-
-
- def train(model, data, step=10000, name="gpt"):
- t0 = time.time()
- for t in range(step):
- seqs, segs, xlen, nsp_labels = data.sample(16)
- loss, pred = model.step(seqs[:, :-1], segs[:, :-1], seqs[:, 1:], nsp_labels)
- if t % 100 == 0:
- pred = pred[0].numpy().argmax(axis=1)
- t1 = time.time()
- print(
- "\n\nstep: ", t,
- "| time: %.2f" % (t1 - t0),
- "| loss: %.3f" % loss.numpy(),
- "\n| tgt: ", " ".join([data.i2v[i] for i in seqs[0, 1:][:xlen[0].sum()+1]]),
- "\n| prd: ", " ".join([data.i2v[i] for i in pred[:xlen[0].sum()+1]]),
- )
- t0 = t1
- os.makedirs("./visual/models/%s" % name, exist_ok=True)
- model.save_weights("./visual/models/%s/model.ckpt" % name)
-
-
-
-
-
-
-
-
- def export_attention(model, data, name="gpt"):
- model.load_weights("./visual/models/%s/model.ckpt" % name)
-
-
- # save attention matrix for visualization
- seqs, segs, xlen, nsp_labels = data.sample(32)
- model.call(seqs[:, :-1], segs[:, :-1], False)
- data = {"src": [[data.i2v[i] for i in seqs[j]] for j in range(len(seqs))], "attentions": model.attentions}
- path = "./visual/tmp/%s_attention_matrix.pkl" % name
- os.makedirs(os.path.dirname(path), exist_ok=True)
- with open(path, "wb") as f:
- pickle.dump(data, f)
-
-
-
-
- if __name__ == "__main__":
- utils.set_soft_gpu(True)
- MODEL_DIM = 256
- N_LAYER = 4
- LEARNING_RATE = 1e-4
-
-
-
- d = utils.MRPCData("./MRPC", 2000)
- print("num word: ", d.num_word)
- m = GPT(
- model_dim=MODEL_DIM, max_len=d.max_len - 1, n_layer=N_LAYER, n_head=4, n_vocab=d.num_word,
- lr=LEARNING_RATE, max_seg=d.num_seg, drop_rate=0.2, padding_idx=d.pad_id)
- train(m, d, step=5000, name="gpt")
- eport_attention(m, d, name="gpt")
例子
调用huggingface的模型
如果只是使用openai的gpt,那就相当简单了,直接调用huggingface的模型就好:
- from transformers import pipeline, set_seed
- generator = pipeline('text-generation', model='openai-gpt')
- set_seed(42)
- generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
微调用在其他任务上
参考文献:
《自然语言处理:基于预训练模型的方法》
莫凡GPT 单向语言模型
GPT-1: Improving Language Understanding by Generative Pre-Training
GPT-2没什么神奇的,PyTorch 就可以复现代码
GPT模型介绍并且使用pytorch实现一个小型GPT中文闲聊系统
编辑:王菁
校对:林亦霖

