
- 1北京大学创新推出ManipLLM黑科技 | 大幅提升机器人操作的鲁棒性与智能性
- 2conv-tasnet网络结构+mobilenet网络结构+VQ-VAE-2模型_convtasnet
- 3python进行中文文本聚类实例(TFIDF计算、词袋构建)_中文文本聚类分析实例
- 4设置vscodium采用微软官方扩展源_vscodium 官方源
- 5攻略 | 如何拿下奖金534万的全国人工智能大赛?_ai+视觉特征编码
- 6Stable Diffusion:详细版安装教程!_stable diffusion 云盘安装需要多大
- 7最新类ChatPDF及AutoGPT开源18大功能平台——闻达手把手超详细环境部署与安装——如何在低显存单显卡上面安装私有ChatGPT GPT-4大语言模型LLM调用平台_闻达框架
- 8Python深度学习026:基于Pytorch的典型循环神经网络模型RNN、LSTM、GRU的公式及简洁案例实现(官方)_python gru库
- 9朱晔的互联网架构实践心得S1E3:相辅相成的存储五件套
- 10Python:高级聊天机器人_chatterbot要哪个版本的python
HanLP汉语言处理包 下载和配置_hanlp data-for-1.3.2 下载
赞
踩
HanLP汉语言处理包的主要作用是对分词后的文本进行停用词的去除和标注
下面将用两种方式介绍HanLP的配置方式
方式一:maven 仓库
步骤:1直接在pom.xm中加入HanLP的坐标即可使用基本功能((由字构词、依存句法分析外的全部功能)。
- <dependency>
- <groupId>com.hankcs</groupId>
- <artifactId>hanlp</artifactId>
- <version>portable-1.7.8</version>
- </dependency>
若用户需要自定义配置通过在resources文件下创建hanlp.properties文件即可

方式二、下载jar、data、hanlp.properties
HanLP将数据与程序分离,给予用户自定义的自由。
1、下载:data.zip
下载后解压到任意目录,接下来通过配置文件告诉HanLP数据包的位置。
HanLP中的数据分为词典和模型,其中词典是词法分析必需的,模型是句法分析必需的。
- data
- │
- ├─dictionary
- └─model
用户可以自行增删替换,如果不需要句法分析等功能的话,随时可以删除model文件夹。
- 模型跟词典没有绝对的区别,隐马模型被做成人人都可以编辑的词典形式,不代表它不是模型。
- GitHub代码库中已经包含了data.zip中的词典,直接编译运行自动缓存即可;模型则需要额外下载。
2、下载jar和配置文件:hanlp-release.zip
配置文件的作用是告诉HanLP数据包的位置,只需修改第一行
root=D:/JavaProjects/HanLP/
为data的父目录即可,比如data目录是/Users/hankcs/Documents/data,那么root=/Users/hankcs/Documents/ 。
最后将hanlp.properties放入classpath即可,对于多数项目,都可以放到src或resources目录下,编译时IDE会自动将其复制到classpath中。除了配置文件外,还可以使用环境变量HANLP_ROOT来设置root。安卓项目请参考demo。
如果放置不当,HanLP会提示当前环境下的合适路径,并且尝试从项目根目录读取数据集。
附:本地jar包加入maven仓库并添加词库
起因:用maven方式不管配不配置hanlp.properties进行标准切词发现有些词语都切不出来,如“毛呢”会被分开,如下图

因项目使用的是maven方式来统一管理jar包,故采用本地jar包加入maven仓库并添加词库的方式来做。
1、按照方式二下载data以及jar包和配置文件
- hanlp-1.7.8-sources.jar: 这个包可以不要
2、将下载的jar包导入maven仓库
install:install-file -Dfile=<Jar包的地址>
-DgroupId=<Jar包的GroupId>
-DartifactId=<Jar包的引用名称>
-Dversion=<Jar包的版本>
-Dpackaging=<Jar的打包方式>
install:install-file -Dfile=D:\hanlp-1.7.8.jar -DgroupId=com.hankcs -DartifactId=hanlp -Dversion=hanlp-1.7.8 -Dpackaging=jar
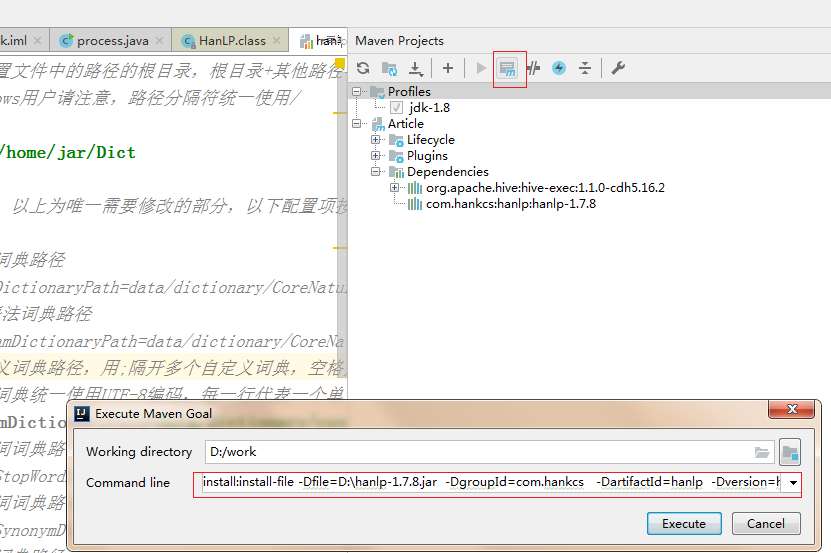
成功后会在本地maven仓库看到加入的jar包
3、pom.xml中添加依赖
- <!--自定义本地jar包使用python词典-->
- <dependency>
- <groupId>com.hankcs</groupId>
- <artifactId>hanlp</artifactId>
- <version>hanlp-1.7.8</version>
- </dependency>
4、hanlp.properties配置data路径
/home/jar/Dict为linux上的路径,因为jar包是要上传到集群的

5、切词测试
将项目打成jar包,在hive中创建临时函数,测试


