
- 1idea properties文件中文乱码��_idea properties 乱码
- 2鸿蒙内部测试情况,华为鸿蒙内测被曝翻车?竟还能用安卓谷歌服务,真就EMUI换皮?...
- 3WebGL技术研究:Threejs、SceneJS、ThingJS等框架优缺点对比分析_threejs为什么不火
- 4LSTM数学计算公式_lstm计算公式
- 5在PC上安装Android SDK与Android模拟器 - 使用Android Studio 3.1.1_android sdk on pc
- 6功能磁共振成像(fMRI)的知识点_fmri矢状 冠状 轴状
- 7Linux线程同步(二)之使用信号量_两个线程等待同一个信号量
- 8realsense2+faster-rcnn+物体深度+物体宽度_关闭 enable_device_from_file
- 9Android studio 打Jar包问题_android studio release aar包classjar空
- 10华为eNSP实现企业内网双出接口访问外网(VRRP、MSTP、DHCP、NAT-easy IP、nat server、ACL)_vrrp接口与easy ip
论文Reinforcement Knowledge Graph Reasoning for Explainable Recommendation笔记;可解释的推荐系统
赞
踩
Reinforcement Knowledge Graph Reasoning for Explainable Recommendation
- abstract
与大多数现有的方法不同,这篇文章致力于实现明确的可解释推荐,在知识图谱中得到明确的理由从而进行推荐。
提出了一个 Policy-Guided Path Reasoning(PGPR)方法
提出了四个主要贡献,在introduction又详细写了下
- introduction
介绍了下当前方法存在的哪些问题:
1.利用知识图谱嵌入做推荐
1.1存在的问题:纯知识图谱嵌入,缺少发现多跳关系路径的能力 多跳关系路径是个啥??
1.2利用知识图谱嵌入增强协同过滤
存在的问题:是在相应的推荐项被选择后,再进行解释 具体怎么进行相应的解释不太清楚??
2.Another line of research investigates path-based recommendation
2.1 对知识图谱使用元路径进行推理(proposed the notion of meta-paths to reason over KGs.)
存在的问题:无法探索未连接的实体之间的关系
2.2 基于知识图谱路径嵌入的方法进行推荐,需要枚举user-item对之间的所有可能路径(developed a path embedding approach for recommendation over KGs that enumerates all the qualified paths between every user–item pair,and then trained a sequential RNN model from the extracted paths to predict the ranking score for the pairs.)
存在的问题:对于大的知识图谱,没有办法全部探索。
文章对此提出了他们的方法,不只是得到推荐项目的候选集,还有得到每个项目推荐的原因,可解释的证据。把推荐过程看成确定性马尔可夫决策过程。
agent从一个给定的user出发,学习找到用户潜在的感兴趣的项(item)。并且这个path history当作为什莫推荐给用户的解释。
如下图:

给定用户A,算法找到的item B 和F,推导路径(reasoning path)为{UserA → ItemA → BrandA → Item B} and {UserA → Feature B → Item F}.
实现上边的方法面临的挑战及解决方法:
1.如何正确的衡量推荐给用户的item,需要认真考虑终止情况(terminal conditions)和奖励(reward)
解决方案:搞了一个基于软奖励(soft reward strategy)的多跳评分函数,使用知识图谱中丰富的异构信息。
2.==这个没太看懂是个啥意思,关于这个action可能需要在后边的模型和实验再看下????==action的空间依赖于图的出度,某些点可能会非常大
解决方案:提出了一个user-conditional action pruning strategy来减少action空间
3.对于推荐,需要保证item和path的多样性,避免agent被限制在item的某一个区域
解决方案:design a policy-guided search algorithm to sample reasoning paths for recommendation in the inference phase具体咋做的还不太清楚???
这篇文章的贡献:
1.他们说明了把知识图谱里边丰富的异构信息放到推荐问题,用以解释推理过程的重要意义
2.提出了基于强化学习的方法,通过使用软奖励机制(soft reward strategy),user-conditional action pruning,and the multi-hop scoring strategy
3.设计了基于beam-search的算法来高效的取样推理路径和候选item用于推荐
4.在几个Amazon 电子商务领域上进行测试,得到了好的结果和可解释的推理路径
-
2. Related work
2.1 Collaborative Filtering
2.2 Recommendation with Knowledge Graphs
2.3 Reinforcement Learning
2.1 Collaborative Filtering
早期的协同过滤使用user-item评分矩阵,使用基于用户或基于物品的协同过滤方法。随着降维方法的发展,潜在因子(latent factor)模型比如矩阵分解被用于推荐。随着深度学习和神经网络的发展,拓展了协同过滤方法,主要分为两种子类:the similarity learning approach , the representation learning approach。但上边的这些方法都很解释推荐结果。
2.2 Recommendation with Knowledge Graphs
之前的工作将知识图谱嵌入以帮助推荐。一个研究方向是将知识图谱嵌入作为丰富的内容信息(rich content information)增强推荐的性能;另一个研究方向尝试使用知识图谱中实体(entity)和路径信息作可解释的决定,但是之前工作存在的问题就是上边introduction提到的:先选择项再形成推荐或无法在大的知识图谱上使用
2.3 Reinforcement Learning
提了一些RL在推荐系统的使用,但没有知识图谱;一些使用了知识图谱,但是在QA工作上。最后说当前的工作没有在较大知识图谱的基础上使用强化学习实现推荐系统的工作。
-
3. Methodology
3.1 Problem Formulation
3.2 Formulation as Markov Decision Process
3.3 Multi-Hop Scoring Function
3.4 Policy-Guided Path Reasoning
3.1 Problem Formulation
给出了一个新的知识图谱的定义 G R G_R GR,包含一个子集合’USER’ entities U U U和一个子集合’Item’ entities I I I,满足集合 U , I U,I U,I都属于实体集,并且 U ∩ I = ∅ U\cap I=\varnothing U∩I=∅.两种实体之间的连接关系使用 r u i r_{ui} rui
表示。
定义一个K跳路径: p k ( e 0 , e k ) = e 0 ↔ r 1 e 1 ↔ r 2 . . . ↔ r k e k p_k(e_0,e_k)={e_0\stackrel{r_1}{\leftrightarrow}e_1 \stackrel{r_2}{\leftrightarrow}...\stackrel{r_k}{\leftrightarrow}e_k} pk(e0,ek)=e0↔r1e1↔r2...↔rkek,其中 e i − 1 ↔ r i e i e_{i-1}\stackrel{r_i}{\leftrightarrow}e_i ei−1↔riei表示 ( e i − 1 , r i , e i ) ∈ G R (e_{i-1},r_i,e_i)\in G_R (ei−1,ri,ei)∈GR或者 ( e i , r i , e i − 1 ) ∈ G R (e_{i},r_i,e_{i-1})\in G_R (ei,ri,ei−1)∈GR
定义一个KGRE-Rec问题:给定一个知识图谱 G R G_R GR,有 u ∈ U u\in U u∈U,整数 K K K。目的是找到一个推荐的项目集 { i n } n ∈ [ N ] ⫅ I \{i_n\}_{n\in [N]}\subseteqq I {in}n∈[N]⫅I,其中每一个( u , i n u,i_n u,in)都对应于一个推理路径 p k ( u , i n ) ( 2 ≤ k ≤ K ) p_k(u,i_n) (2\leq k \leq K) pk(u,in)(2≤k≤K)
为了同时得到推荐的item和推理路径,提出Policy-Guided Path Reasoning method(PGPR)方法。有如下流程图:

训练一个RL agent学习从一个user开始,在知识图谱环境中,查找‘好’的item;然后agent为每个用户抽取推荐项目的推理路径作为推荐项目的解释。
上边的图没太看懂
3.2 Formulation as Markov Decision Process
第一个操作是对于知识图谱 G R G_R GR添加双向边和自环
**State:**对于时刻t的状态 s t = ( u , e t , h t ) s_t=(u,e_t,h_t ) st=(u,et,ht)。其中u是用户实体, e t e_t et是时刻tagent到达的实体, h t h_t htis the history prior to step t
**Action:**定义action空间为在状态 s t s_t st时,从实体 e t e_t et可能出发的边和到达的实体。
A t = { ( r , e ) ∣ ( e t , r , e ) ∈ G R , e ∉ { e 0 , . . . e t − 1 } } A_t=\{(r,e)|(e_t,r,e)\in G_R,e\notin \{e_0,...e_{t-1}\}\} At={(r,e)∣(et,r,e)∈GR,e∈/{e0,...et−1}}
对于图中可能会有的节点出度过大,所以需要去掉一些,以使得action空间不至于过大,采用一个scoring function f ( ( r , e ) ∣ u ) f((r,e)|u) f((r,e)∣u)来计算用户u和边(r,e)的分数,得到一个新的action空间:
A − t ( u ) = { ( r , e ) ∣ r a n k ( f ( ( r , e ) ∣ u ) ) ≤ α , ( r , e ) ∈ A t } \overset{-}A_t(u)=\{(r,e)|rank(f((r,e)|u))\leq \alpha,(r,e)\in A_t\} A−t(u)={(r,e)∣rank(f((r,e)∣u))≤α,(r,e)∈At}
其中 α \alpha α是预先定义的整数
**Reward:**用户事先并不知道target item,所以reward不可以是binary的,agent被鼓励找到尽可能多‘’好‘’的路径。‘好’的路径定义为用户有较大的概率会去与其指向的item进行交互。
既然事先并不知道target,那终止状态的定义是个啥????还是说每一步的奖励都是这么定义呀??
对于终止状态 s T = ( u , e T , h T ) s_T=(u,e_T,h_T) sT=(u,eT,hT),基于另一个scoring function f ( u , i ) f(u,i) f(u,i),定义终止奖励 R T R_T RT如下:
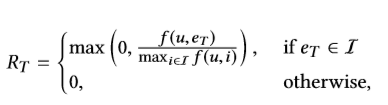
**Transition:**对于给定的状态和action,其转换到下一个状态的概率是固定的,为1
只有在初始状态 s 0 = ( u , u , ∅ ) s_0=(u,u,\varnothing) s0=(u,u,∅)时,为了简单,假定其是均匀分布。
Optimization:
强化学习的目标是学习到一个策略 π \pi π,使得期望奖励最大:
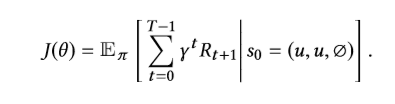
设计了一个policy network和一个value network。
The policy network π(·|s, A − u \overset{-}A_u A−u)takes as input the state vector s and binarized vector A − u \overset{-}A_u A−u of pruned action space A − ( u ) \overset{-}A(u) A−(u) and emits the probability of each action,with zero probability for the action out of A − ( u ) \overset{-}A(u) A−(u). The value network V − ( s ) \overset{-}V(s) V−(s)maps the state vector s to a real value

令所有网络的参数 Θ = { W 1 , W 2 , W p , W v } \Theta=\{W_1,W_2,W_p,W_v\} Θ={W1,W2,Wp,Wv}
梯度表示为:
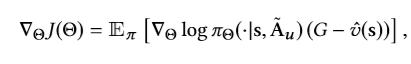
G为从状态s到终止状态的累计reward,使用discount factor γ \gamma γ
这个公式的求导还不太清楚???
3.3 Multi-Hop Scoring Function
定义了一个k-hop pattern:

之前定义使得图中存在双向边和自环,所以根据边在路径中的方向不同,分别有forward和backward。增加了一个新的定义1-reverse k-hop pattern:

定义一个general multi-hop scoring function f ( e 0 , e k ∣ r − k , j ) f(e_0,e_k|\overset{-}r_{k,j}) f(e0,ek∣r−k,j):
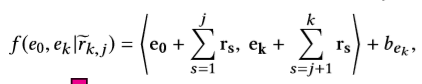
是一个点积运算,e,r是entity e和relation r的d维向量表示, b e k b_{ek} bek是entity e的偏置
Scoring Function for Action Pruning:
![ [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0hZVd333-1586169379542)(C:\Users\17806\AppData\Roaming\Typora\typora-user-images\image-20200406113539058.png)]](https://img-blog.csdnimg.cn/20200406184102121.png)
感觉是对于一个路径,当碰到其中出现的第一个不属于用户的entity e,将其索引 k e k_e ke作为最小的k,然后使用上式的方法进行计算。
Scoring Function for Reward:
对于 ( u , r u i , i ) ∈ G R (u,r_{ui},i)\in G_R (u,rui,i)∈GR,scoring function for reward定义为: f ( u , i ) = f ( u , i ∣ r − 1 , 1 ) f(u,i)=f(u,i|\overset{-}r_{1,1}) f(u,i)=f(u,i∣r−1,1)
Learning Scoring Function
这部分没太看懂,看的很迷???????????
3.4 Policy-Guided Path Reasoning
基于知识图谱,通过训练好的policy network解决推荐问题
直接根据policy得到n条路径无法保证多样性。所以采用algorithm 1
如果一个路径是以item结束的,则就将其保存下来.
对于相同的item,可能会有多条路径,采用生成的概率Q_T进行排序,得到每个item的唯一路径。
通过reward在不同的item中排序选择出候选集
-
4. EXPERIMENTS
介绍这篇文章实验的benchmark,介绍实验相关的实验设置;以及消融实验(ablation studies)s
4.1 Data Description
4.2 Experimental Setup
4.3 Quantitative Analysis
4.4 Influence of Action Pruning Strategy
4.5 Multi-Hop Scoring Function
4.6 Sampling Size in Path Reasoning
4.7 History Representation
4.1 Data Description
数据集共分为四个领域:CDs and Vinyl, Clothing, Cell Phones and Beauty
其中每个领域或者说category是由一个包含五种类别的实体(entity)和7种关系(relation)的知识图谱。具体情况见下表:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7flI5DNL-1586169379545)(C:\Users\17806\AppData\Roaming\Typora\typora-user-images\image-20200406163140883.png)]](https://img-blog.csdnimg.cn/20200406184033975.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM3OTU5MjAy,size_16,color_FFFFFF,t_70)
可以看到Mention和Described_by的关系个数比较多,文章中说和feature有关,可能会含有较多的没有实际含义的词,然后使用TF-IDF进行消除,最终每个数据集有少于5000个feature word和TF-IDF score$>$0.1
4.2 Experimental Setup
实验baseline和评估方式,以及具体参数的设置:
baseline:BPR , BPR-HFT , VBPR , TransRec , DeepCoNN , CKE , JRL
评估方法:**Normalized Discounted Cumulative Gain(NDCG), Recall, HitRatio(HR) and Precision (Prec.). **
其中比较重要的有最大路径长度设置为3,==关于history vector h t h_t ht的具体定义为: e t − 1 , r t e_{t-1},r_t et−1,rt向量的组合,所以状态向量 s t = ( u , e t , e t − 1 , r t ) s_t=(u,e_t,e_{t-1},r_t) st=(u,et,et−1,rt)
4.3 Quantitative Analysis
运行结果如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mWtQz8MV-1586169379547)(C:\Users\17806\AppData\Roaming\Typora\typora-user-images\image-20200406170638907.png)]](https://img-blog.csdnimg.cn/20200406184010244.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM3OTU5MjAy,size_16,color_FFFFFF,t_70)
考虑他们的方法发现有效路径的效率:
其中有效路径的定义如下:有效路径的定义:在三跳以内,从user出发,以item结束。一个路径中最多四个实体。
具体的测试结果如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a62yfzvs-1586169379548)(C:\Users\17806\AppData\Roaming\Typora\typora-user-images\image-20200406172717232.png)]](https://img-blog.csdnimg.cn/20200406183858541.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM3OTU5MjAy,size_16,color_FFFFFF,t_70)
4.4 Influence of Action Pruning Strategy
评估模型在不同大小的action空间下的表现
随着action空间的变大,整体的效果是由一个向下的趋势
具体情况如下:

![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ABraUURn-1586169379552)(C:\Users\17806\AppData\Roaming\Typora\typora-user-images\image-20200406173657387.png)]](https://img-blog.csdnimg.cn/20200406183806735.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM3OTU5MjAy,size_16,color_FFFFFF,t_70)
4.5 Multi-Hop Scoring Function
探索多跳评分函数是否能够促进模型的表现,使用2-hop进行entity和item的训练。
具体的结果表示在上4.4节中的图,有1-hop和2-hop的对比,可以看出提升显著。文章中分析是多跳评分函数在长距离中捕捉到了实体之间的联系。
原文:This improvement mainly stems from the effectiveness of the multi-hop scoring function, which captures interactions between entities with longer distance. For example, if a user purchases an item and the item belongs to a category, the 2-hop scoring function enhances the relevance between User entity and Category entity through the 2-hop pattern {Purchase,Belong_to}.
4.6 Sampling Size in Path Reasoning
探讨在sampling size的大小对于推荐效果的影响(we study how the sampling size for path reasoning influences the recommendation performance of our method. )
因为之前定义最大路径为3,所以对于sampling size有一个定义 ( K 1 , K 2 , K 3 ) (K_1,K_2,K_3) (K1,K2,K3)
具体的含义为sample 最高(具体是概率还是啥不太清楚?????好像是概率????)的 K t K_t Kt个action,在步数t
运行结果:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CaInDeDC-1586169379555)(C:\Users\17806\AppData\Roaming\Typora\typora-user-images\image-20200406180813155.png)]](https://img-blog.csdnimg.cn/20200406183743410.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzM3OTU5MjAy,size_16,color_FFFFFF,t_70)
其实对于这个结果我看的很迷,感觉发现不了啥东西
文章中的分析意思大概是说最初的两个action的选择主要是确定一个大的方向:类似于抵达哪种类型的item,在经过两层之后,方向已经确定,policy network趋于收敛,选择一个最优的action得到好的item
4.7 History Representation
评估不同的history计算对模型的影响。
no history (0-step)
last entity e t − 1 e_{t-1} et−1 with relation r t r_t rt (1-step)
last two entities e t − 2 , e t − 1 e_{t-2},e_{t-1} et−2,et−1 , with relations r t − 1 , r t r_{t-1},r_t rt−1,rt (2-step)
具体的运行结果如下:
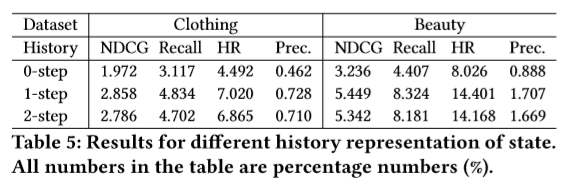
对于0-step结果差的原因为:没有充足的历史信息提供给agent来学习得到一个好的策略
对于2-step结果差的原因:作者也不是很确定,只是说可能的原因是因为过多的历史信息可能是多余的,甚至可能误导agent。
-
5. CASE STUDY ON PATH REASONING
举例说明咋可解释推荐的
-
6. CONCLUSIONSANDFUTUREWORK
可能将他们的方法应用于product search , social recommendation , model time-evolving graphs so as to provide dynamic decision support (对时间演化图进行建模,以提供动态决策支持)

