
- 1Android Room 数据库的坑_cursorwindowallocationexception: could not allocat
- 2ArcGIS中ObjectID,FID和OID字段有什么区别?_arcengine oid值字段
- 3PyTorch加载预训练模型的问题_pytorch resnet18 加载本地预训练模型
- 4onchange事件只生效一次的问题
- 5带你走进 ERNIE
- 6NLP原理及基础_ls自然语言处理
- 7在线客服的未来:AI客服
- 85年Java开发干到月薪38k?当初实习期2.5k的苦我也吃过..._南京5年java开发的薪资
- 9边缘AI工具-NanoEdge AI Studio 安装教程_nanoedge ai studio怎么下载
- 10AI 全自动玩斗地主,靠谱吗?Douzero算法教程
百度Python面试题_百度的面试题python方向
赞
踩
目录
4、请写出一段Python代码实现删除一个list里面的重复元素?
5、使用Python编程用sort进行排序,然后从最后一个元素开始判断?
6、Python里面如何拷贝一个对象?(赋值,浅拷贝,深拷贝的区别)
1、Python是如何进行内存管理的?
从三个方面来说:
一、对象的引用计数机制
二、垃圾回收机制
三、内存池机制
一、对象的引用计数机制
Python 内部使用引用计数,来保持追踪内存中的对象,所有对象都有引用计数。
引用计数增加的情况:
(1)一个对象分配一个新名称
(2)将其放入一个容器中(如列表、元组或字典)
引用计数减少的情况:
(1)使用 del 语句对对象别名显示的销毁
(2)引用超出作用域或被重新赋值
sys.getrefcount() 函数可以获得对象的当前引用计数,多数情况下,引用计数比你猜测得要大得多。对于不可变数据(如数字和字符串),解释器会在程序的不同部分共享内存,以便节约内存。
二、垃圾回收
(1)当一个对象的引用计数归零时,它将被垃圾收集机制处理掉。
(2)当两个对象 a 和 b 相互引用时,del 语句可以减少a 和 b 的引用计数,并销毁用于引用底层对象的名称。然而由于每个对象都包含一个对其他对象的应用,因此引用计数不会归零,对象也不会销毁(从而导致内存泄露)。为解决这一问题,解释器会定期执行一个循环检测器,搜索不可访问对象的循环并删除它们。
三、内存池机制
Python 提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
(1)Pymalloc 机制。为了加速 Python 的执行效率,Python 引入了一个内存池机制,用于管理对小块内存的申请和释放。
(2)Python 中所有小于256个字节的对象都使用 pymalloc 实现的分配器,而大的对象则使用系统的 malloc。
(3)对于 Python 对象,如整数和 List 都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
2、什么是lambda函数?它有什么好处?
lambda 表达式,通常是在需要一个函数,但是又不想费神去命名一个函数的场合下使用,也就是指匿名函数。
lambda 函数:首要用途是指点短小的回调函数
lambda[arguments]:expression示例代码:
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- # 公众号:AllTests软件测试
- add=lambda x,y:x+y
- print(add(2,3))
运行结果:输出5

3、Python里面如何实现tuple和list的转换?
直接使用 tuple 和 list 函数就行了,type()可以判断对象的类型。
4、请写出一段Python代码实现删除一个list里面的重复元素?
方法一:利用set集合实现
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- # 公众号:AllTests软件测试
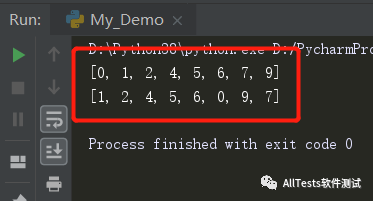
- info = [1, 2, 4, 1, 5, 6, 5, 0, 9, 0, 7, 7]
- result = list(set(info))
- print(result)
- result.sort(key=info.index)
- print(result)
运行结果:
方法二:使用字典函数
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- # 公众号:AllTests软件测试
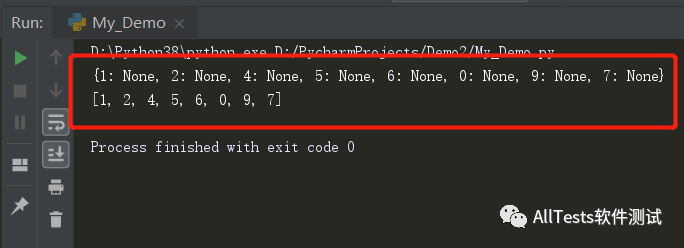
- info = [1, 2, 4, 1, 5, 6, 5, 0, 9, 0, 7, 7]
- result = {}
- result = result.fromkeys(info)
- print(result)
- result_list = list(result.keys())
- print(result_list)
运行结果:
方法三:列表推导式
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- # 公众号:AllTests软件测试
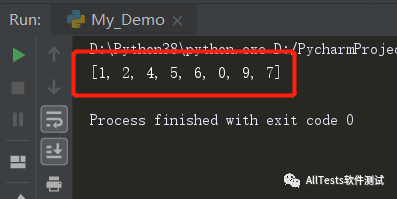
- info = [1, 2, 4, 1, 5, 6, 5, 0, 9, 0, 7, 7]
- lst = []
- res = [lst.append(i) for i in info if i not in lst]
- print(lst)
运行结果:
5、使用Python编程用sort进行排序,然后从最后一个元素开始判断?
示例代码:
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- # 公众号:AllTests软件测试
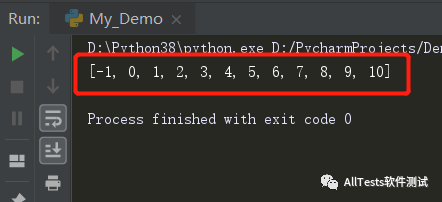
- a=[1,-1,2,4,2,4,5,6,8,7,10,0,5,5,7,6,8,9,0,3]
- a.sort()
- last=a[-1]
- for i in range(len(a)-2,-1,-1):
- if last==a[i]:
- del a[i]
- else:
- last=a[i]
- print(a)
运行结果:
6、Python里面如何拷贝一个对象?(赋值,浅拷贝,深拷贝的区别)
赋值(=):就是创建了对象的一个新的引用,修改其中任意一个变量都会影响到另一个。
浅拷贝:创建一个新的对象,但它包含的是对原始对象中包含项的引用,如果用引用的方式修改其中一个对象,另外一个也会修改改变。
(完全切片方法;工厂函数,如 list();copy 模块的 copy() 函数)
深拷贝:创建一个新的对象,并且递归的复制它所包含的对象,修改其中一个,另外一个不会改变。
(copy 模块的 deep.deepcopy() 函数)
7、介绍一下except的用法和作用?
try..-except…except…[else…][finally]执行 try 下的语句,如果引发异常,则执行过程会跳到 except 语句。对每个 except 分支顺序尝试执行,如果引发的异常与 except 中的异常组匹配,执行相应的语句。如果所有的 except 都不匹配,则异常会传递到下一个调用本代码的最高层 try 代码中。try 下的语句正常执行,则执行else 块代码。如果发生异常,就不会执行。如果存在 finally 语句,最后总是会执行。
8、Python中pass语句的作用是什么?
pass 语句不会执行任何操作,一般作为占位符或者创建占位程序。
9、介绍一下Python中range()函数的用法?
range() 函数可创建一个整数列表,一般用在 for 循环中。
range(start, stop[, step])参数说明:
- start: 计数从 start 开始,默认是从0开始。例如 range(5) 等价于range(0,5)
- stop: 计数到 stop 结束,但不包括 stop。例如 range(0,5) 是 [0, 1, 2, 3, 4] 没有5
- step:步长,默认为1。例如 range(0,5) 等价于 range(0,5,1)
10、如何用Python来进行查询和替换一个文本字符串?
可以使用 re 模块中的 sub() 函数或者 subn() 函数来进行查询和替换。
格式:
sub(replacement, string[,count=0])replacement 是被替换成的文本,string 是需要被替换的文本,count 是一个可选参数,指最大被替换的数量。
示例代码:
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- # 公众号:AllTests软件测试
- import re
- p=re.compile('蓝色|白色|红色')
- print(p.sub('彩色','蓝色袜子和红色鞋子'))
- print(p.sub('彩色','蓝色袜子和红色鞋子',count=1))
运行结果:
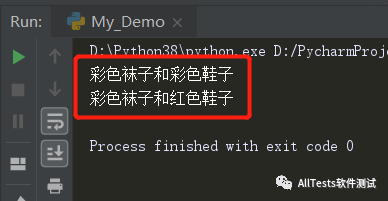
subn() 方法执行的效果跟sub() 一样,不过它会返回一个二维数组,包括替换后的新的字符串和总共替换的数量。
11、Python里面match和search的区别?
match() 和 search() 两者都是测试正则表达式与字符串是否匹配。不同的是,match() 如果在字符串的开头有0个或更多个字符,符合正则表达式模式,返回相关匹配的实例对象,如果字符串不符合正则表达式模式则返回None;而search()则不同,扫描整个字符串,如果产生了一个匹配正则模式就寻找到这个位置,返回相关匹配的对象。如果没有位置能够匹配这个模式则返回 None。
12、Python里面如何生成随机数?
在 Python 中用于生成随机数的模块是 random,在使用前需要 import 导入。
- random.random():生成一个 0-1 之间的随机浮点数
- random.uniform(a,b):生成[a,b]之间的浮点数
- random.randint(a,b):生成[a,b]之间的整数
- random.randrange(a,b,step):在指定的集合[a,b)中,以 step 为基数随机取一个数
- random.choice(sequence):从特定序列中随机取一个元素,这里的序列可以是字符串,列表,元组等
精彩推荐


