
热门标签
热门文章
- 1Flask-cms 后台模块 --项目类型(四)
- 2【玩转 EdgeOne】- 腾讯云下一代边缘加速CDN EdgeOne 是安全加速界的未来吗?
- 3MySQL获取当前日期、时间、时间戳函数_mysql当前日期函数
- 4Eclipse中使用GIT更新项目
- 56套粒子群算法(内含matlab代码)_指数递减和余弦递减惯性权重粒子群算法
- 6Mysql 获取当前时间函数 (类似于sql server 中的 getDate())_数据库中怎么求现在时间
- 7m基于扩频解扩+LDPC编译码的通信链路matlab误码率仿真,调制对比QPSK,16QAM,64QAM,扩频参数可设置_qpsk扩频和不扩频对比csdn
- 8FPGA实现串口(UART)_fpga uart
- 9新手学习Python_age = int(input('请输入年龄:')) hrrest = int(input('请输入
- 10[Maya API] lesson25_Maya API 中的多边形处理 - MFnMesh/MItMesh_maya api mesh
当前位置: article > 正文
计算机视觉开发人员的新朋友:SAM(分段任意模型,教程含源码)
作者:我家小花儿 | 2024-04-11 03:36:37
赞
踩
分段任意模型
花在注释上的时间可能很快就会成为过去。
Meta 的 FAIR 实验室最近推出了 Segment Anything Model,这是一种先进的图像分割模型,旨在彻底改变计算机视觉。它可以根据输入提示(例如点或框)生成高质量的对象蒙版。该模型还可以为图像中的所有对象生成蒙版。
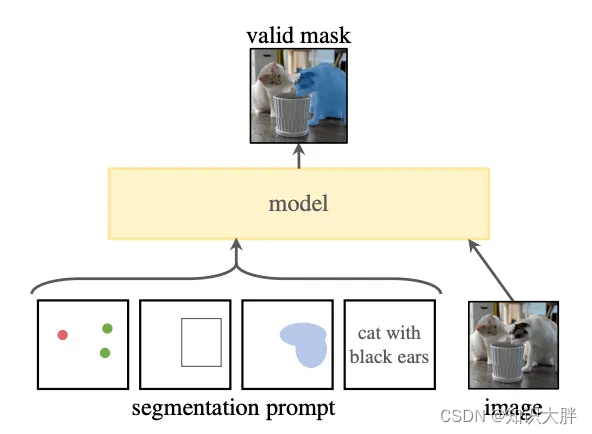
有什么大不了的?
如果您花了数小时在 LabelImg、LabelMe 或像我一样的任何其他注释工具上注释图像,您也会明白为什么 SAM 是我们的新朋友。分割注释是一项非常耗时且乏味的任务。例如,要注释图像中的人物,您必须在其身体周围放置多个点以捕获不同的边缘和曲线并为人物创建蒙版。而使用 SAM 时,模型会分割图像,您只需确认掩模并添加标签“Person”即可。
一个有趣的特性: SAM 拥有零样本泛化能力。这是指模型在未经过明确训练的图像分割任务上表现良好的能力,而不需要额外的训练或微调。
自己尝试一下
演示页面可让您感受模型的功能。在这里查看:
https: //segment-anything.com/demo
- 1
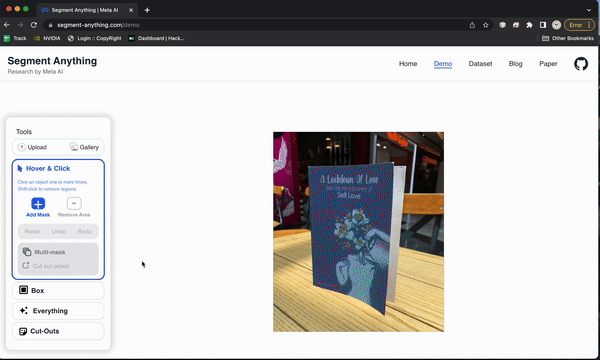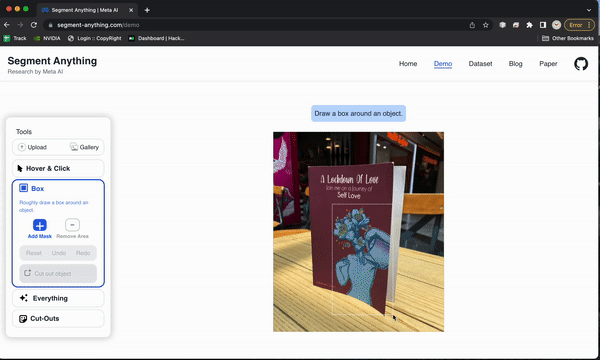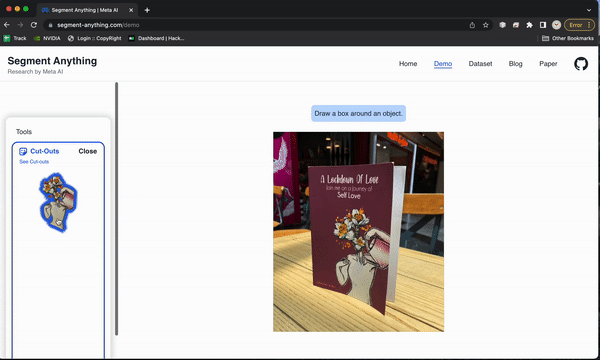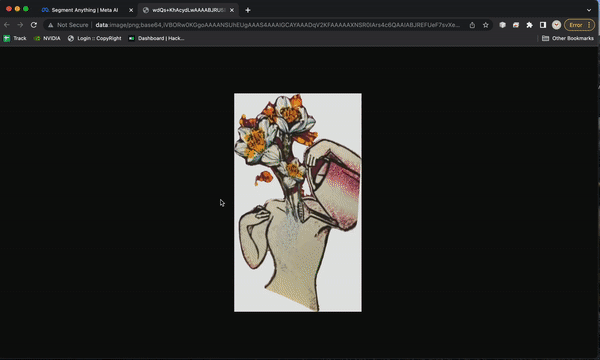
设置代码库并尝试模型也非常简单。我花了大约20分钟。以下是我所遵循的步骤的概述
- 安装 PyTorch 和 TorchVision
- 安装的段任何东西
- 我安装了一些提到的用于掩模后处理的其他库。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/402686
推荐阅读
相关标签

