
- 1eslint 规则
- 2在 CentOS 上安装 Docker 和 Docker Compose
- 3报考PMP好处,你知道多少?_项目管理pmp多大作用?
- 4java 语言实现深度优先搜索(DFS)图算法_java实现dfs
- 5Spring Boot 学习记录笔记【 五 】之前端Vue_ant design vue官方文档
- 6电脑的日常使用 0 笔记本电脑验机&使用体验帖_umis rpeyj1t24mkn2qwy硬盘
- 7以P2P网贷为例互联网金融产品如何利用大数据做风控?
- 8如何在 Python 中获取当前日期?_python获取当前日期
- 9使用HAL库开发STM32:ADC基础使用_hal_adc_start_dma
- 10mtest命令_uboot中mtest命令的用法(针对DDR3)
【文章系列解读】AI绘图必读模型:Derambooth和Textual Inversion
赞
踩
1. Dreambooth
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation (2022.8)
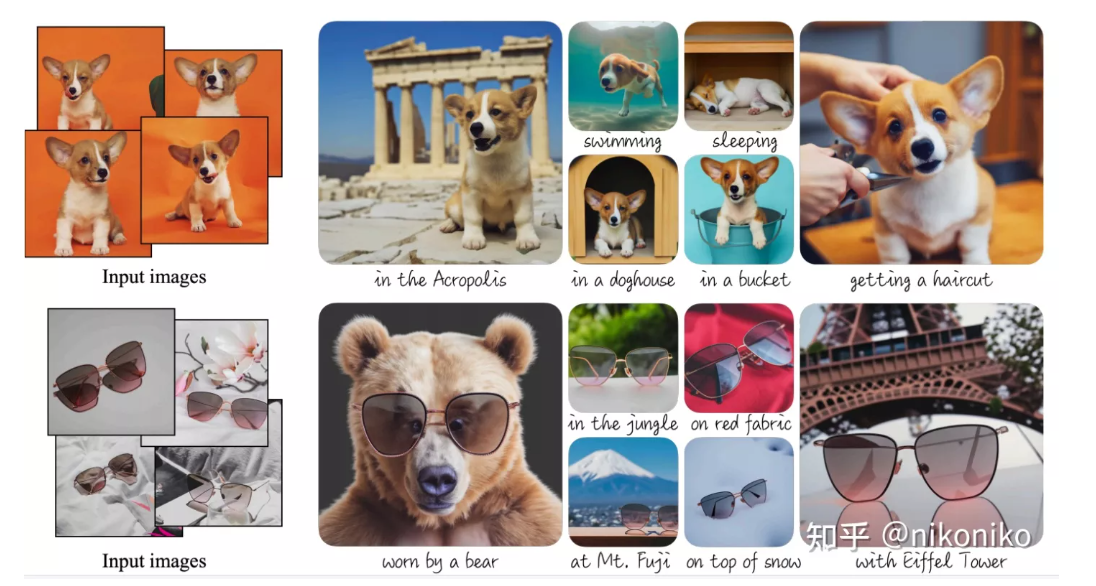
总体而言,文章想要实现的效果是输入3~5张图片(目前看是单物体的),通过文本“a [v] [class]”把输入的图片和prompt绑定起来,对模型进行finetune(例如图片上坐上,输入是若干张同一只狗的图片,以及a [v] [dog])。
为了避免模型过拟合在输入的狗上,文章引入了保留损失。保留损失意指,先通过预训练模型生成若干张狗这一类的图片。在训练的时候既指定了输入的狗,又能保留其他狗,这个域内其他品种的特征。
3.1 Dream Booth微调过程
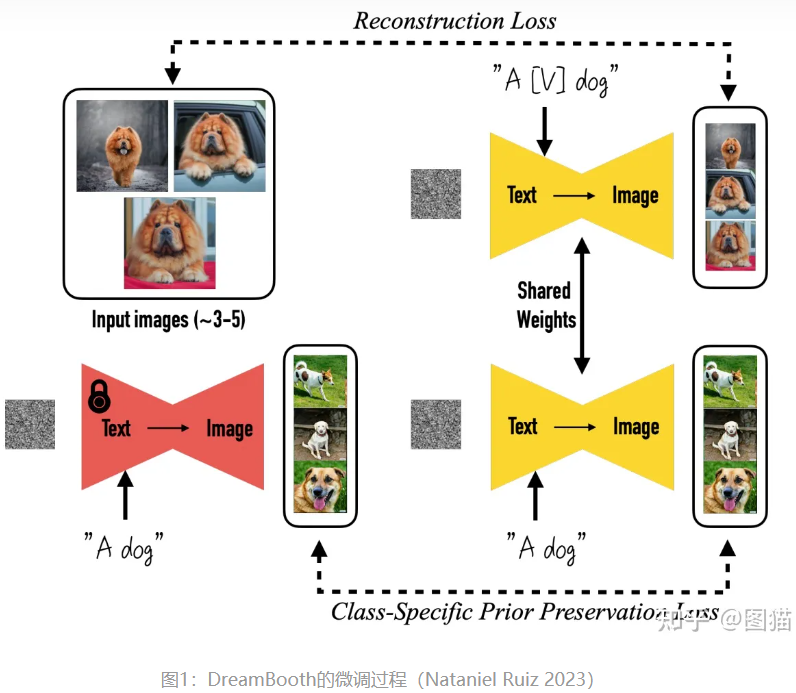
图1的上半部分,做了以下几件事:
1、准备描述的句子(“一只松狮狗”)和对应句子的3-5张图片(3-5张松狮犬.jpg)
2、句子(Text)和图片(加噪声后的松狮.jpg)输入到SD模型中的编码器中进行编码,最后由解码器解码成图片。
3、生成的图片和原图进行比较,通过损失函数对生成器进行奖惩,更新权值。
图1的下半部分和上半部分几乎一致,只是去除句子中的目标特征(松狮)变成(一只狗),并提供对应图片(狗.jpg)进行训练。这部分的训练在论文中表示为扩散模型的先验知识的保留,假设我们只提供3-5张松狮图去进行微调,很容易造成生成结果的过拟合,导致失去原本基底模型的多样性能力。简单来说,微调成松狮模型后,模型生成其他狗狗的能力就弱化了(当然这可能也是我们需要的)。
下面是DreamBooth的整体损失函数:
E
x
,
c
,
ϵ
,
ϵ
′
,
t
[
w
t
∥
x
^
θ
(
α
t
x
+
σ
t
ϵ
,
c
)
−
x
∥
2
2
+
λ
w
t
′
∥
x
^
θ
(
α
t
′
x
p
r
+
σ
t
′
ϵ
′
,
c
p
r
)
−
x
p
r
′
2
2
,
Z
2
]
前半部分,是松狮图的损失函数:x 是原图,
(
a
t
x
+
σ
t
ϵ
)
\left(a_{t} x+\sigma_{t} \epsilon\right)
(atx+σtϵ) 是加噪后的图,
x
θ
^
\hat{x_{\theta}}
xθ^ 是扩散模型的去噪方法,它接收噪声图和文字,生成去噪后的图。通过L2像素损失对比 x 与
(
a
t
x
+
σ
t
ϵ
)
\left(a_{t} x+\sigma_{t} \epsilon\right)
(atx+σtϵ) 的差异。
后半部分,是狗图的损失函数:结构和前者一致,通过加入 λ \lambda λ 来控制影响权重,论文中表示,当 λ = 1 \lambda=1 λ=1 时,3-5张图片在1000次的训练后,仍旧获得不错的泛化结果。

3.2 细节展示
输入**(Text+Image),输出(Image)的过程,直接利用了扩散模型的能力去实现。**
下面仔细讲讲这里发生了什么?这里也可以进一步了解一下扩散模型。
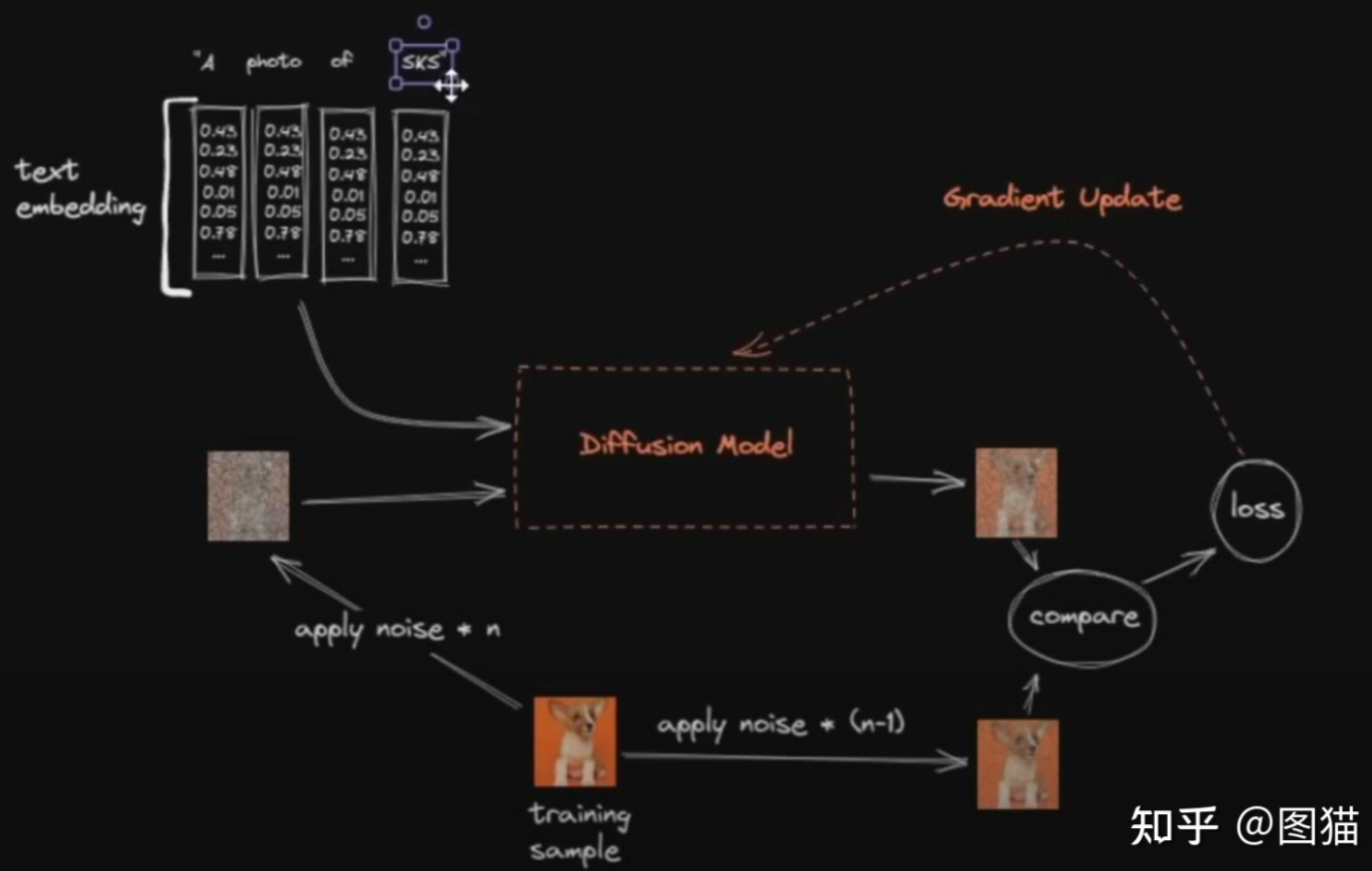
油管大佬关于DreamBooth微调过程示意图 https://www.youtube.com/watch?v=dVjMiJsuR5o
1、对于句子来说,每一个字会被拆分,压扁(flaten)到一个数组里。
2、对于图片来说,它分别被加噪n步与n-1步,生成两张噪声图 I n I_{n} In 与 I n − 1 I_{n-1} In−1 , I n I_{n} In 被输入到扩散模型中,且以文字做为条件引导,通过解码器(VAE)生成一张图片 I g e n I_{gen} Igen 。 I g e n I_{gen} Igen 会与 I n − 1 I_{n-1} In−1 通过L2损失函数作比较,以两者下一次生成的结果更相似作为目标,进行权重的调整。
3、这个过程不断重复,损失函数的值会不断震荡变小,最终生成的图片就很像原图了。同时,用于条件引导的句子也被模型学习了(这种方式和Condition GAN很像,Text即Condition),下次当这些词与一张面目全非的噪声图一起输入时,就能一层一层’去噪’成关键词背后指代的图片了。
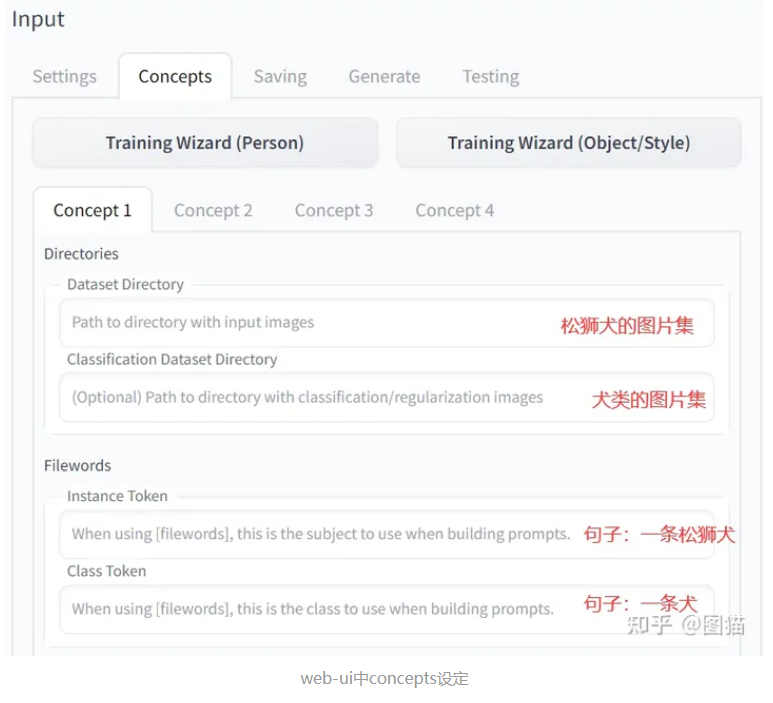
最后,我们看一下对应sd-webui中dreambooth的训练设定。这下就明白dataset和classification指的数据到底时什么了吧。
但实操中,仍旧需要我们自己去实验,到底要不要加入分类数据。结合原理与消融实验能更好理解输入输出的前因后果。毕竟机器学习很玄学。
(这么说来,我这篇文章也没啥意义,还得自己试)
2. Textual Inversion
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion (2022.8)
AI画画:Textual Inversion, Hypernetwork, Dreambooth
Textual Inversion:它根据模型引用给定的图像并选择最匹配的图像。做的迭代越多越好。通过寻找一个 latent 空间来描述一个近似训练图的复杂概念,并将该空间分配给关键字。Textual Inversion 作为扩展当前模型的迷你“模型”。解析 prompt 时,关键字会利用嵌入来确定要从中提取哪些标记及其相关权重。训练只是找出代表源材料所需的正确标记。
Hypernetwork:它会改变图像的整个输出,而无需在提示中调用它来浪费您宝贵的token,它可以在您的设置选项卡中进行设置,该选项卡将自动应用于您的所有图像。
Dreambooth:它将给定内容插入到输出中,缺点是如果你用 Dereambooth,它会用训练图替换所有相似的对象。模型通过N步学习,学会给定图像与新关键字之间的关系;此关键字在标记化后,将类似于 latent 空间。
Textual Inversion是一种从少量示例图像中捕获新概念的技术,是一种用于控制文本到图像的管线。它通过在embedding space管线的文本编码器中学习新的“单词”来实现此目的。然后可以在text prompts中使用这些特殊单词,以实现对结果图像的非常精细的控制。(最新研究发现,只要给AI喂3-5张图片,AI就能抽象出图片里的物体或风格,再随机生成个性化的新图片。)


