
- 1JetBrains 开发工具——免费教育许可申请流程_jetbrains教育
- 2springboot集成kafka多线程消费端的实现_springboot kafka多线程消费
- 3Python + Telnet基本使用_python telnet
- 4安装能调用GPU的pytorch版本_python安装pytorch gpu版本
- 5鸿蒙HarmonyOS4.0开发应用学习笔记_鸿蒙开发文档
- 6【项目实战】python影片数据爬取与数据分析django电影数据网络爬虫与分析系统(源码+答疑+文档报告PPT)
- 7WebSocket + Vue 简单聊天的实现_websocket+kafka+vue
- 8Scrapy_redis+scrapyd搭建分布式架构爬取知乎用户信息_scrapy-redis分布式局域网多台电脑之间怎么建立关联的
- 9基于STM32与FreeRTOS的四轴机械臂项目_基于stm32的机械臂项项目
- 10编写相亲交友源码,应该掌握的简写小技巧_相亲源代码
PySpark预计算ClickHouse Bitmap实践
赞
踩
1. 背景
ClickHouse全称是Click Stream,Data WareHouse,是一款高性能的OLAP数据库,既使用了ROLAP模型,又拥有着比肩MOLAP的性能。我们可以用ClickHouse用来做分析平台快速出数。其中的bitmap结构方便我们对人群进行交并。Bitmap位图的每一位表示一个数据(比如说一个用户)。假设5亿用户(一个用户4个字节),则需要5 * 10^8 * 4byte = 3GB,而压缩到32位的bitmap里只需要2^32bit = 512MB。压缩空间的同时,利用位运算还能快速处理人群集合。
常见的bitmap使用方法是将数据按维度打成窄表<user_id, attr_name, attr_value>,这里user_id已经mapping成int类型,然后明细存入ClickHouse中,并对attr_name or attr_value进行group by聚合,最后对id进行groupBitmapState (groupBitmap | ClickHouse Docs) 压缩成bitmap二进制格式存储到数据库里。导入方法可以是使用定时批量进行显式导入,或者使用ClickHouse物化视图的能力隐式导入。
总所周知,ClickHouse是一个MPP式的分布式数据库,引擎既负责计算又负责存储,因此ClickHouse的节点一般选择性能不错(也就是价格不便宜)的计算机。而且由于ClickHouse的任务和节点强绑定,因此节点数也不宜过多。在使用Replicated*引擎的时候(属于主从复制,利用ZooKeeper选出自己的主副本),节点过多会影响分布式性能。ClickHouse的Distributed表原则是谁执行谁负责,每个节点都负责把各个分片(shard)的数据发到其他分片上,节点过多则会增加传输故障的风险。简而言之,直接压缩bitmap对ClickHouse集群压力很大,而且消耗很高。
因此,我们希望可以预先计算bitmap的方式,用于分摊ClickHouse集群的压力。
2. 方案和实现
相对于MPP架构,还有另一种shared nothing架构,那就是hadoop生态的批处理架构。批处理架构和MPP架构的一大区别在于任务和节点分离。由于批处理架构有主从结构的存在,主节点主要做调配工作就可以了,如果有一台从节点变慢了那就给它分配更少的task。因此批处理架构可以使用大量廉价机器。如果我们可以利用hadoop生态事先对数据进行预处理,最后输出到ClickHouse,我们就即可以减少ClickHouse集群的负担而且可以加大结点数增加速度。
所以,这里要做的,就是将已经存入tdw的hive明细表,转成ClickHouse的bitmap类型。
本人更熟悉Python生态圈,因此选用了PySpark来完成这个任务(对于scala/java生态我也走通并复现了文章SparkSQL & ClickHouse RoaringBitmap使用实践_spark clickhouse bitmap-CSDN博客的细节,有需要的可以私下交流,这里也不铺开了)。我们解决问题的方式,是从简单到复杂到最后实现。
2.1 PySpark udf聚合bitmap
第一步要解决的问题,是如何将多个用户压缩到bitmap里,这里我们先假定已经有了一个bitmap类,add user进去就可以了。我们先按照传统做法,对user进行id映射,将string类型的id转化成int,然后将维度表打成窄表,类似于如下建表语句:
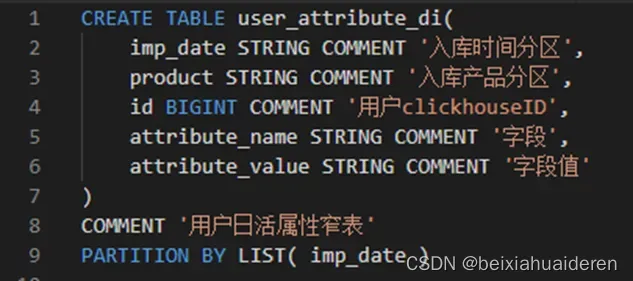
并读取hive表,做一些需要的过滤和处理操作,载入到spark dataframe里。

PySpark可以使用udf很方便地去实现自定义操作。它有两种udf,自带的udf和pandas_udf,但是按照本人的经验,pandas_udf虽然更方便也更快(默认提供了group by),但是不同的spark版本会有一些意想不到的bug,比如0之前会有偶发性的rdd位置错乱。所以在不确定公司内部具体spark情况,稳妥起见使用自带udf(pyspark.sql.functions.udf — PySpark 3.1.1 documentation, Python Aggregate UDFs in PySpark - Dan Vatterott )。
对于udf,我们可以使用collect_list,去实现group by后传入udf输出单列的功能。代码类似于如下:
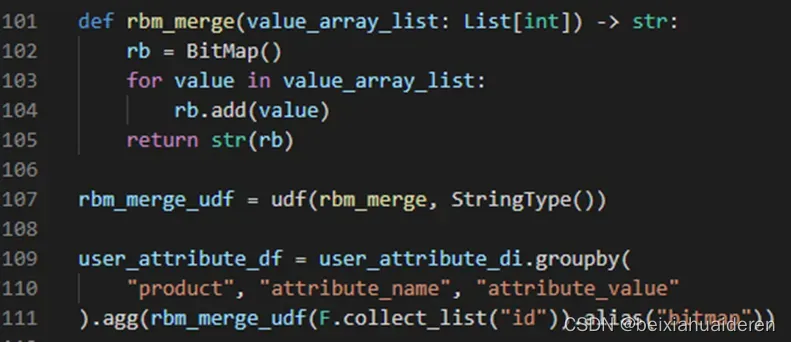
udf函数的输入是一个list,返回了一个单值作为一个新的udf列。到这里,我们就完成了第一个部分。
2.2 bitmap二进制序列化
接下来第二部分是最麻烦的部分,就是如何实现上文的bitmap。这里,这个bitmap的特性是序列化成二进制后可以被ClickHouse读取使用。
我们需要知道ClickHouse怎么使用bitmap的。这里对照着ClickHouse的源码(AggregateFunctionGroupBitmapData.h)和ClickHouse遇见RoaringBitmap-CSDN博客这篇文章的解读,我们可以一览ClickHouse bitmap的设计和实现。
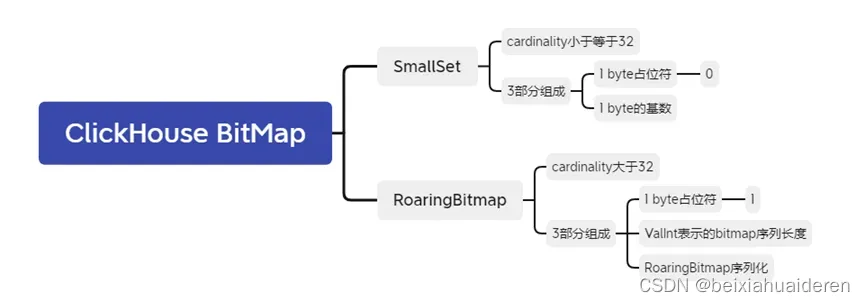
ClickHouse并不是简单的压缩。在文档里也可以看到(https://clickhouse.com/docs/en/sql-reference/functions/bitmap-functions/):对于位图基数cardinality小于等于32的时候,使用了Set对象(源码里叫做SmallSet),对于大于32的时候,使用了RoaringBitmap对象。最后的输出,是将bitmap序列化成一个紧密排列的二进制对象。
这是写入方法:https://github.com/ClickHouse/ClickHouse/blob/master/src/AggregateFunctions/AggregateFunctionGroupBitmapData.h#L122-L138
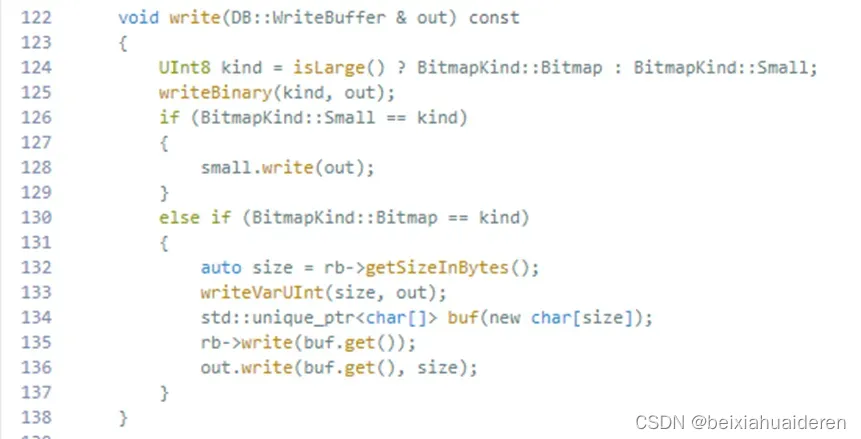
我们先来看看小于等于32的情况,使用了smallset(ClickHouse使用内部实现的SmallSet<T, small_set_size> https://github.com/ClickHouse/ClickHouse/blob/master/src/Common/HyperLogLogWithSmallSetOptimization.h#L28),它在数据量小的时候会更快。它分为3部分,1 byte占位符(这里是0,表示小于等于32),1 byte的基数(2^8次方,但这里基数最大是2^5=32),和byte array(这里注意,是一个数字占了4 byte)。PySpark代码如下:

这里对byte array用一个for循环将bitmap输入进去,最后用b""将整个二进制对象的数组拼接成一个完全的二进制对象。
接下来看大于32的情况,它也是3部分,1 byte占位符(这里是1,表示大于32),bitmap数的Valint表示,最后一部分是bitmap的序列化直接做字节。
这里补充一下,无论是Smallset还是RoaringBitmap,ClickHouse的bitmap都是使用了小端序,如果没有指定,可能会产生一些奇怪的结果。python的大小端序语法可参见通过python理解大端小端_小端是高位补零-CSDN博客。
第二部分使用Varint用来表示第三部分RoaringBitmap最后序列化后的字节数。在ClickHouse的源码可见(ClickHouse/src/IO/VarInt.h at master · ClickHouse/ClickHouse · GitHub)。

Varint的长度计算在ClickHouse/src/IO/VarInt.h at master · ClickHouse/ClickHouse · GitHub。不过python的bytes不需要,这里可以跳过,对java/scala的ByteBuffer就需要(需要预先预留字节位)。Varint的计算逻辑见Carl's Blog和ClickHouse源码阅读(0000 1101) —— ClickHouse是如何读写数据的(readVarUInt和writeVarUInt方法解析)_clickhouse writevaruint-CSDN博客 。讲得很详细,这里不赘述。
第三部分是整个ClickHouse bitmap的核心,这里使用了RoaringBitmap(GitHub - RoaringBitmap/RoaringBitmap: A better compressed bitset in Java: used by Apache Spark, Netflix Atlas, Apache Pinot, Tablesaw, and many others)。位图bitmap的问题是数据越稀疏,空间就越浪费。有很多算法尝试解决这个问题,压缩位图,比如WAH、EWAH、Concise等,RoaringBitmap是其中的佼佼者。它的主要思路是对32位无符号整数高低分桶。具体可见(高效压缩位图RoaringBitmap的原理与应用 - 简书 )
RoaringBitmap有不同的实现,对于ClickHouse,使用的是CRoaring(https://github.com/RoaringBitmap/CRoaring)。各种语言的api实现都共享同一种序列化格式,这让我们可以使用python/java/scala进行序列化,然后用c++(ClickHouse)进行读取。格式具体见(GitHub - RoaringBitmap/RoaringFormatSpec: Specification of the compressed-bitmap Roaring format),官方说法如下:
这里我们使用了python版本的api(https://pyroaringbitmap.readthedocs.io/en/stable),源码(https://github.com/Ezibenroc/PyRoaringBitMap)。pip安装,然后需要对整个spark集群都更新这个library。这个库底层仍是CRoaring,因为python很容易对c/c++做wrapper封装。
PySpark入ClickHouse的代码如下:
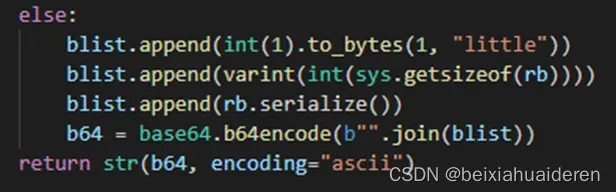
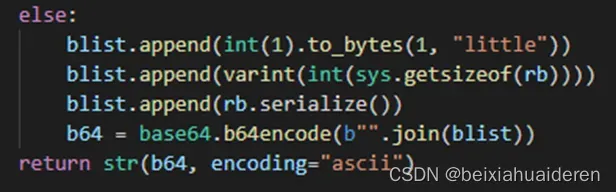
这里,get_statistics()["cardinality"]获取基数,sys.getsizeof(rb)可以获取rb序列后的字节数,见Expose roaring_bitmap_portable_size_in_bytes as __sizeof__. by urdvr · Pull Request #40 · Ezibenroc/PyRoaringBitMap · GitHub (类似的,java API里是rb.serializedSizeInBytes()),rb.serialize()按照RoaringBitmap的序列化规则进行序列化,这里是已经封装好了。
在这里其实本人尝试了很多方案,也绕了很多弯路,比如使用了bytearray去承接byte数组(bytearray的值最大是256),比如直接存python struct(https://docs.python.org/zh-cn/3/library/struct.html)的格式而不是string后的base64,比如to_bytes没指定大小端序,对源码结构不熟没指定正确的位数等等,太多就不赘述了。给个脑图:
在这一步的最后,我们需要对bitmap进行抽样检测。这个是从SparkSQL & ClickHouse RoaringBitmap使用实践_spark clickhouse bitmap-CSDN博客里学到的,我们对二进制对象,进行base64编码(encode)再转成string类型,可以做到快速可视化二进制并来校验我们的结果是否正确。
base64编码是使用64个可打印的ASCII字符将二进制字节序列数据编码成字符串。通过使用base64将二进制数据序列化为二进制字符串来实现将内存里的二进制字节固化到磁盘或者网络传输。具体资料可见 Base64编码及编码性能测试_base64性能-CSDN博客 。
简单使用一个ClickHouse SQL去执行一下,并编码成base64的字符串
 结果是
结果是
 同样地,我们打印在PySpark里的dataframe的值,可以看到
同样地,我们打印在PySpark里的dataframe的值,可以看到

两者的ASCII码是一致的,说明我们的字节已经做到了兼容ClickHouse读取格式。
2.3 hive bitmap出库ClickHouse
最后一步,我们已经有了一个预处理好的兼容ClickHouse bitmap的hive表,我们需要hive出库到ClickHouse里。
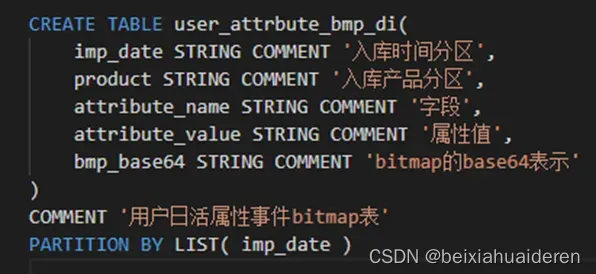
由于公司的tdw工具没法往hive表里写入binary类型,我们只能考虑直接写入base64的string进去。这里对id聚合,然后打成bitmap再写入新的字段bmp_base64。建表语句如下:
利用ClickHouse自带的物化表达式(CREATE TABLE | ClickHouse Docs ),我们可以很容易新增一列bitmap列。MATERIALIZED关键字的含义接近于DEFAULT和ALIAS,也就是默认值。此外,当 SELECT 中有星号(select *)时,查询也不返回这一列。这是为了在把用SELECT * 得到的数据插到回表中的时候,不指定列名也不会改变数据。
ClickHouse建表语句如下:
本地表:
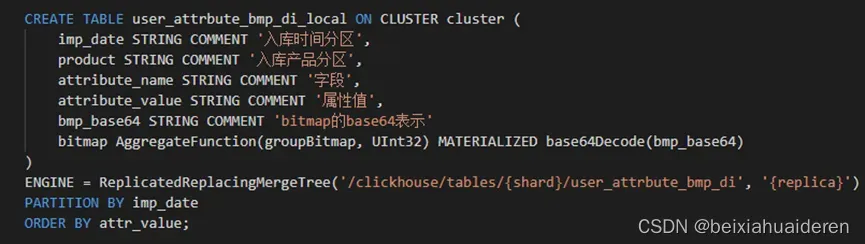
分布式表:

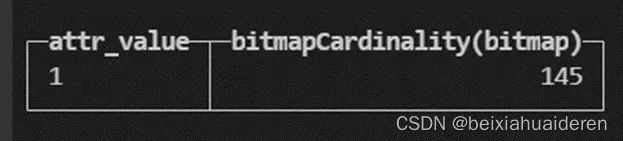
select attr_value, bitmapCardinality(bitmap) from user_attrbute_bmp_di_cluster可以得到如下样例:
至此,我们的Spark-ClickHouse的bitmap之旅到了一段落了。
3. 总结
- 减少了ClickHouse集群计算压力,大大缩短了hive表出库时间(不需要出库明细数据,只需要出库对应的bitmap)。
- 可以将明细长时间存于hive表里,而不用留在ClickHouse中(物化视图需要明细),降低存储成本。
- 使用Python生态圈,减少数据同学的上手难度,同时也打通了其他Python分析工具。

