
- 1【软考-中级】系统集成项目管理工程师-【6项目整体管理】_软考中级项目整体管理
- 2信息安全-工控安全需求分析与安全保护工程_电磁与工控安全
- 3谷粒商城快速启动_谷粒商城前端启动
- 4在 PyCharm 中高效使用 GitHub Copilot_pycharm copilot
- 5机器学习(四)——模型调参利器 gridSearchCV(网格搜索)
- 6selenium新版元素定位方法、元素操作与基本API_selenium更新定位方式
- 7单片机GD32F303RCT6 (Macos环境)开发 (十六)—— Eeprom AT24C08的读取_at24c08一次可以读几个字节
- 8大一暑假 前端vue3基于阿里云物联网平台获取单片机数据与数据可视化项目开发历程记录_vue 阿里云物联网平台
- 9eNSP毕业设计系列-《大型企业网》-BGP网络无nat
- 10为什么人工智能要用Python?答案在这里_为什么ai技术要用python
2018.06.06论文:12个NLP分类模型_nlp多分类模型
赞
踩
https://blog.csdn.net/u012052268/article/details/80698930
- 1 概述
- 2 模型细节:
- 2.1 快速文本(fastText)
- 2.2文本卷积神经网络(Text CNN)
- 2.3文本循环神经网络(Text RNN)
- 2.4 双向长短期记忆网络文本关系(BiLstm Text Relation)
- 2.5 两个卷积神经网络文本关系(two CNN Text Relation)
- 2.6 双长短期记忆文本关系双循环神经网络(BiLstm Text Relation Two RNN)
- 2.7 循环卷积神经网络(text-RCNN)
- 2.8 分层注意力
- 2.9具有注意的Seq2seq模型
- 2.10 Transformer(“Attention Is All You Need”)
- 2.11 循环实体网络(Recurrent Entity Network)
- 2.12 动态记忆网络
注1:本文翻译自GitHub上的一篇介绍,介绍了基于深度学习的文本分类问题。代码和部分模型介绍在GitHub上:https://github.com/DX2017/text_classification
注2:本文参考风起云杨译文:https://blog.csdn.net/qq_35273499/article/details/79498733 并加入自己的理解整理。
1 概述
这个库 的目的是探索用深度学习进行NLP文本分类的方法。它具有文本分类的各种基准模型。
它还支持多标签分类,其中多标签与句子或文档相关联(作者的一篇论文:链接:large scale muli-label text classification with deep learning)。
虽然这12个模型都很简单,可能不会让你在这项文本分类任务中游刃有余,但是这些模型中的其中一些是非常经典的,因此它们可以说是非常适合作为基准模型的。每个模型在模型类型(github代码)下都有一个测试函数。这个几个模型也可以用于构建问答系统,或者是序列生成。
如果你想了解更多关于文本分类,或这些模型可以应用的任务的数据集详细信息,可以点击链接进行查询,我们选择了一个:https://biendata.com/competition/zhihu/
1.1模型概览
这篇文章介绍的模型有以下:
- 1.fastText
- 2.TextCNN
- 3.TextRNN
- 4.RCNN
- 5.分层注意网络(Hierarchical Attention Network)
- 6.具有注意的seq2seq模型(seq2seq with attention)
- 7.Transformer(“Attend Is All You Need”)
- 8.动态记忆网络(Dynamic Memory Network)
- 9.实体网络:追踪世界的状态
- 10.Ensemble models
- 11.Boosting:
该模型是多模型堆叠而来的。每一层都是一个模型。结果将基于加在一起的logits,层之间的唯一链接是标签权重。每个标签的浅层预测误差率将成为下一层的权重。那些错误率很高的标签会有很大的权重。所以后面的层将更加关注那些错误预测的标签,并试图修复前一层的误差。结果是,我们可以得到一个很强大的模型。查看: a00_boosting/boosting.py
还包括一下其他模型:
- 1.BiLstm Text Relation
- 2.Two CNN Text Relation
- 3.BiLstm Text Relation Two RNN
1.2各模型效果对比:
性能(多标签标签预测任务,要求预测能够达到前5,300万训练数据,满分:0.5)

1.4 代码用法:
-
模型在xxx_model.py中
-
运行python xxx_train.py来训练模型
-
运行python xxx_predict.py进行推理(测试)。
- 运行环境:
python 2.7+tensorflow 1.1
TextCNN 模型已经可以转换成python 3.6版本
- 注意:
一些util函数是在data_util.py中的;典型输入如:“x1 x2 x3 x4 x5 label 323434”,其中“x1,x2”是单词,“323434”是标签;它具有一个将预训练的单词加载和分配嵌入到模型的函数,其中单词嵌入在word2vec或fastText中进行预先训练。
2 模型细节:
2.1 快速文本(fastText)
介绍
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,不过这个项目其实是有两部分组成的:
- 一部分是 文本分类paper:A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, Bag of Tricks for Efficient Text
Classification(高效文本分类技巧)。 - 另一部分是词嵌入学习(paper:P. Bojanowski*, E. Grave*, A. Joulin, T. Mikolov, Enriching Word Vectors with Subword Information(使用子字信息丰富词汇向量))。
本文主要关注FastText 用于文本分类,其词向量的用法可以参考博文:NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
fastText是Facebook于2016年开源的一个词向量计算和文本分类工具,在学术上并没有太大创新。但是它的优点也非常明显,在文本分类任务中,fastText(浅层网络)往往能取得和深度网络相媲美的精度,却在训练时间上比深度网络快许多数量级。在标准的多核CPU上, 能够训练10亿词级别语料库的词向量在10分钟之内。可以看出fastText有两个主要的特点:
1. 速度很快
2. 在速度的基础上精度较高 。
对应的解决办法就是:
- 层级简单 + embedding叠加 + 分层Softmax
- 字符级别的n-gram
解释
- 快的原因:
- 层级简单:
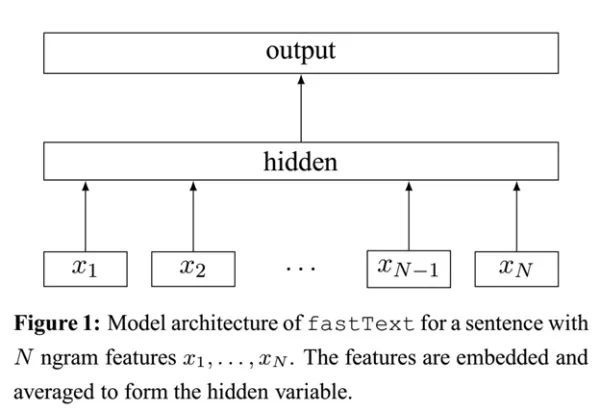
- 单词的embedding叠加获得的文档向量. 全连接参数由 n * L * 1024 变成 1 * L * 1024
- 在输出时,fastText采用了分层Softmax,大大降低了模型训练时间:
- 层级简单:
标准的Softmax回归中,要计算y=j时的Softmax概率:,我们需要对所有的K个概率做归一化,这在|y|很大时非常耗时。于是,分层Softmax诞生了,它的基本思想是使用树的层级结构替代扁平化的标准Softmax,使得在计算时,只需计算一条路径上的所有节点的概率值,无需在意其它的节点。
下图是一个分层Softmax示例:
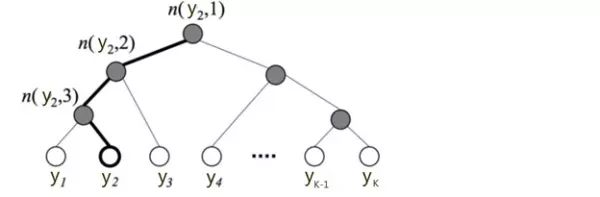
树的结构是根据类标的频数构造的霍夫曼树。K个不同的类标组成所有的叶子节点,K-1个内部节点作为内部参数,从根节点到某个叶子节点经过的节点和边形成一条路径。从根节点走到叶子节点,实际上是在做了3次二分类的逻辑回归。通过分层的Softmax,计算复杂度一下从|K|降低到log|K|。
- 准的原因:字符级别的n-gram:
word2vec把语料库中的每个单词当成原子的,它会为每个单词生成一个向量。这忽略了单词内部的形态特征,比如:“apple” 和“apples”,“达观数据”和“达观”,这两个例子中,两个单词都有较多公共字符,即它们的内部形态类似,但是在传统的word2vec中,这种单词内部形态信息因为它们被转换成不同的id丢失了。
为了克服这个问题,fastText使用了字符级别的n-grams来表示一个单词。对于单词“apple”,假设n的取值为3,则它的trigram有:
“<ap”, “app”, “ppl”, “ple”, “le>”- 1
其中,<表示前缀,>表示后缀。于是,我们可以用这些trigram来表示“apple”这个单词,进一步,我们可以用这5个trigram的向量叠加来表示“apple”的词向量。
这带来两点好处:(论文中怎么说》》》》》????)
-
对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
-
对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
总结
于是fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。github代码:p5_fastTextB_model.py
2.2文本卷积神经网络(Text CNN)
《卷积神经网络进行句子分类》ConvolutionalNeuralNetworksforSentenceClassification论文的实现
结构:降维—> conv —> 最大池化 —>完全连接层——–> softmax
github代码查看:p7_Text CNN_model.py
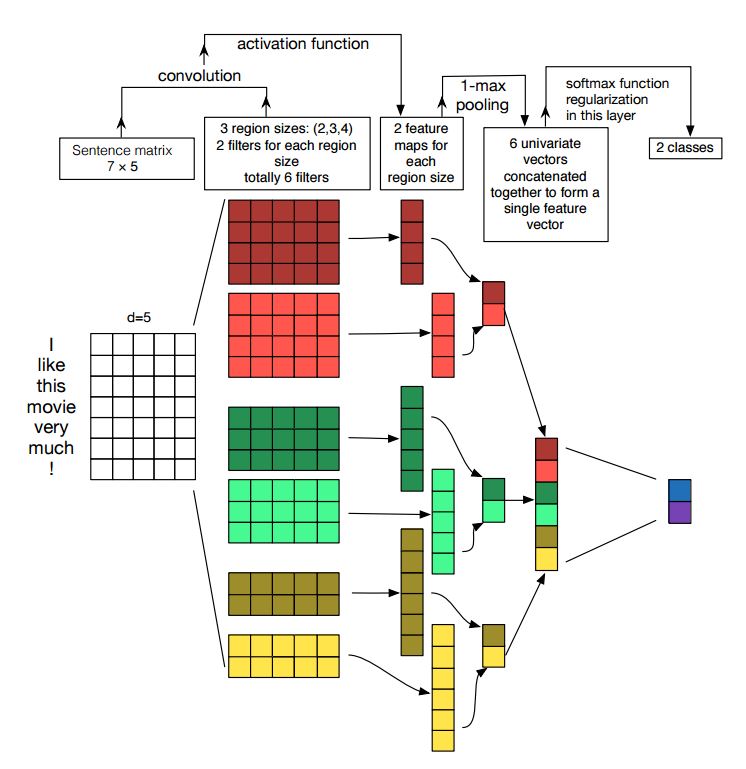
卷积神经网络是解决计算机视觉问题的主要手段。 现在我们将展示CNN如何用于NLP,特别是文本分类。句子长度会略有不同。 所以我们将使用padding来获得固定长度,n。
对于句子中的每个标记,我们将使用单词嵌入来获得一个固定的维度向量d。 所以我们的输入是一个二维矩阵:(n,d)。这跟CNN用于图象是类似的。
首先,我们将对我们的输入进行卷积计算。他是滤波器和输入部分之间的元素乘法。我们使用k个滤波器,每个滤波器是一个二维矩阵(f,d)注意d与词向量的长度相同。现在输出的将是k个列表,每个列表的长度是n-f+1。每个元素是标量(scalar)。请注意,第二维将始终是单词嵌入的维度。我们使用不同的大小的滤波器从文本输入中获取丰富的特征,这与n-gram特征是类似的。
其次,我们将卷积运算的输出做最大池化。对于k个特征映射,我们将得到k个标量。
第三,我们将连接所有标量来获得最终的特征。他是一个固定大小的向量。它与我们使用的滤波器的大小无关。
最后,我们将使用全连接层把这些特征映射到之前定义的标签。
2.3文本循环神经网络(Text RNN)
Github 代码查看:p8_Text RNN_model.py
尽管TextCNN能够在很多任务里面能有不错的表现,但CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter _size 的超参调节也很繁琐。CNN本质是做文本的特征表达工作,而自然语言处理中更常用的是递归神经网络(RNN, Recurrent Neural Network),能够更好的表达上下文信息。
模型结构:embedding—>bi-drectional lstm —> concat output –>average—–> softmax layer
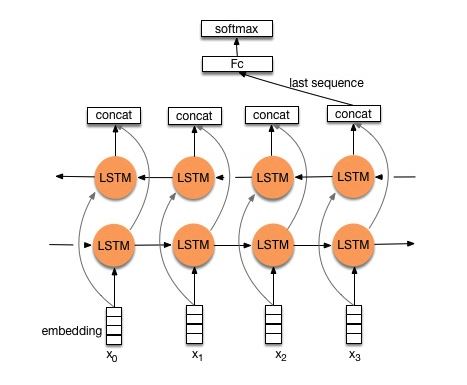
通过利用双向LSTM建模,然后输出最后一个词的结果直接接全连接层softmax输出了。
2.4 双向长短期记忆网络文本关系(BiLstm Text Relation)
Github 代码查看:p9_BiLstm Text Relation_model.py
结构:结构与Text RNN相同。但输入是被特别设计,直接把两个句子进行拼接。
例如:
# "how much is the computer? EOS price of laptop"---> label:1- 1
“EOS”是一个特殊的标记,将问题1和问题2分开。但是 模型并没有把两个句子分割开来,而是当做一个输入进行建模: 把 (背后的逻辑应该是 BiLstm 的自动“双向”建模能力)
2.5 两个卷积神经网络文本关系(two CNN Text Relation)
Github 代码查看:p9_two CNN Text Relation_model.py
结构:首先用两个不同的卷积来提取两个句子的特征,然后连接两个特征,使用线性变换层将投影输出到目标标签上,然后使用softmax二分类。
更多文档、代码参考 参见USTC大佬、iflytek之光 Randolph的github库:Text-Pairs-Relation-Classification
2.6 双长短期记忆文本关系双循环神经网络(BiLstm Text Relation Two RNN)
Github 代码查看:p9_BiLstm Text Relation Two RNN_model.py
结构:一个句子的一个双向lstm(得到输出1),另一个句子的另一个双向lstm(得到输出2)。拼接之后加全连接, 最后:softmax(输出1 输出0)
2.7 循环卷积神经网络(text-RCNN)
Github 代码查看:p71_TextRCNN_model.py
《用于文本分类的循环卷积神经网络》Recurrent Convolutional Neural Networks for Text Classification论文的实现。
结构:1)循环结构(卷积层)2)最大池化3)完全连接层+ softmax
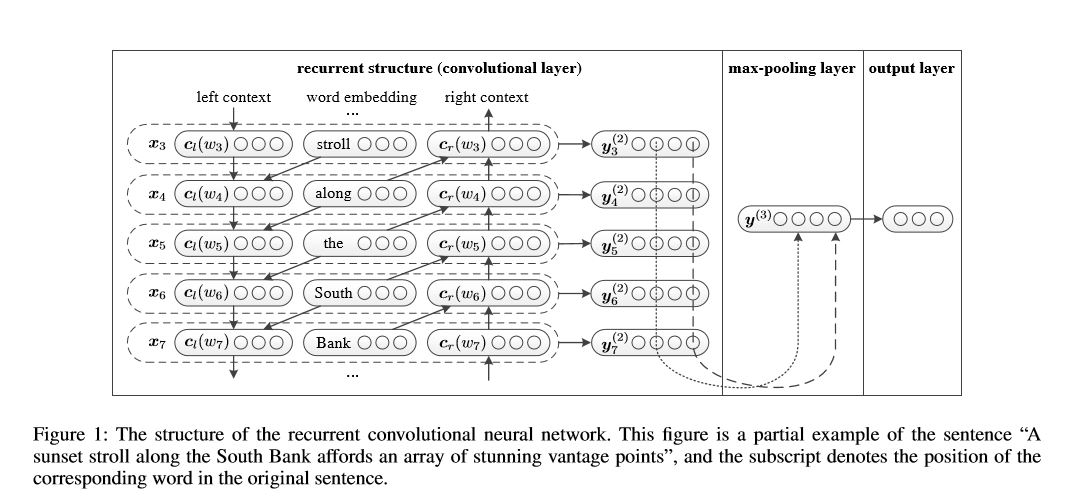
重点是 循环结构(卷积层),在循环神经网络中,加入了“上一个单词”的词向量,类似于 卷积神经网络的2-gram特征。这就是为什么是循环网络 却叫卷积层,重点代码如下:
- def get_context_left(self,context_left,embedding_previous):
- """
- :param context_left:
- :param embedding_previous:
- :return: output:[None,embed_size]
- """
- left_c=tf.matmul(context_left,self.W_l) #context_left:[batch_size,embed_size];W_l:[embed_size,embed_size]
- left_e=tf.matmul(embedding_previous,self.W_sl)#embedding_previous;[batch_size,embed_size]
- left_h=left_c+left_e
- context_left=self.activation(left_h)
- return context_left
-
- def get_context_right(self,context_right,embedding_afterward):
- """
- :param context_right:
- :param embedding_afterward:
- :return: output:[None,embed_size]
- """
- right_c=tf.matmul(context_right,self.W_r)
- right_e=tf.matmul(embedding_afterward,self.W_sr)
- right_h=right_c+right_e
- context_right=self.activation(right_h)
- return context_right

2.8 分层注意力
代码:p1_HierarchicalAttention_model.py
《用于文档分类的分层注意网络》Hierarchical Attention Networks for Document Classification 论文的实现。
结构:
- 词编码器:词级双向GRU,以获得丰富的词汇表征
- 词注意力:词级注意在句子中获取重要信息
- 句子编码器:句子级双向GRU,以获得丰富的句子表征
- 句子注意:句级注意以获得句子中的重点句子
- FC + Softmax
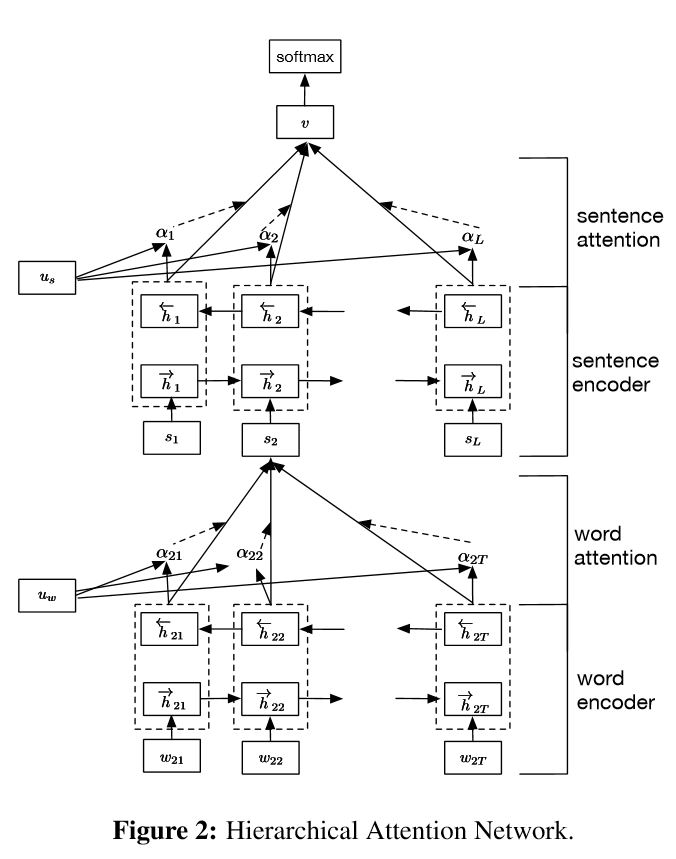
它有两个独特的特点:
1)它具有体现文件层次结构的层次结构
2)它在单词和句子级别使用两个级别的注意力机制,它使模型能够捕捉到不同级别的重要信息。
一个重要问题: ==Uw和Us 的来源 去向?==
计算方式:
- 就是一个 随机初始化的“权重向量”,通过训练更新, 每次计算出前向神经网络的隐层输出之后,乘以权重得到注意力向量。
从代码来研究:
- def AttentionLayer(self, inputs, name):
- #inputs是GRU的输出,size是[batch_size, max_time, encoder_size(hidden_size * 2)]
- with tf.variable_scope(name):
- # u_context是上下文的重要性向量,用于区分不同单词/句子对于句子/文档的重要程度,
- # 因为使用双向GRU,所以其长度为2×hidden_szie
- u_context = tf.Variable(tf.truncated_normal([self.hidden_size * 2]), name='u_context')
- #使用一个全连接层编码GRU的输出的到期隐层表示,输出u的size是[batch_size, max_time, hidden_size * 2]
- h = layers.fully_connected(inputs, self.hidden_size * 2, activation_fn=tf.nn.tanh)
- #shape为[batch_size, max_time, 1]
- alpha = tf.nn.softmax(tf.reduce_sum(tf.multiply(h, u_context), axis=2, keep_dims=True), dim=1)
- #reduce_sum之前shape为[batch_szie, max_time, hidden_szie*2],之后shape为[batch_size, hidden_size*2]
- atten_output = tf.reduce_sum(tf.multiply(inputs, alpha), axis=1)
- return atten_output
-
- ###########################################################################################
-
- 1. 词向量层:省略
-
- 2. 句子级注意力:
- def sent2vec(self, word_embedded):
- with tf.name_scope("sent2vec"):
- #GRU的输入tensor是[batch_size, max_time, ...].在构造句子向量时max_time应该是每个句子的长度,所以这里将
- #batch_size * sent_in_doc当做是batch_size.这样一来,每个GRU的cell处理的都是一个单词的词向量
- #并最终将一句话中的所有单词的词向量融合(Attention)在一起形成句子向量
-
- #shape为[batch_size*sent_in_doc, word_in_sent, embedding_size]
- word_embedded = tf.reshape(word_embedded, [-1, self.max_sentence_length, self.embedding_size])
- #shape为[batch_size*sent_in_doce, word_in_sent, hidden_size*2]
- word_encoded = self.BidirectionalGRUEncoder(word_embedded, name='word_encoder')
- #shape为[batch_size*sent_in_doc, hidden_size*2]
- sent_vec = self.AttentionLayer(word_encoded, name='word_attention')
- return sent_vec
-
- 3.文档级注意力
- def doc2vec(self, sent_vec):
- #原理与sent2vec一样,根据文档中所有句子的向量构成一个文档向量
- with tf.name_scope("doc2vec"):
- sent_vec = tf.reshape(sent_vec, [-1, self.max_sentence_num, self.hidden_size*2])
- #shape为[batch_size, sent_in_doc, hidden_size*2]
- doc_encoded = self.BidirectionalGRUEncoder(sent_vec, name='sent_encoder')
- #shape为[batch_szie, hidden_szie*2]
- doc_vec = self.AttentionLayer(doc_encoded, name='sent_attention')
- return doc_vec
- 4. 全连接层:省略
2.9具有注意的Seq2seq模型
具有注意的Seq2seq模型的实现是通过《共同学习排列和翻译的神经机器翻译》NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE来实现的。
首先学习一下什么是seq2seq模型:https://blog.csdn.net/qq_27505047/article/details/79531049
2.9.1 encoder to decoder
首先是第一篇《NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE》,这篇论文算是在自然语言处理(NLP)中第一个使用attention机制的工作,将attention机制用到了神经网络机器翻译(NMT),NMT其实就是一个典型的Seq2Seq模型,也就是一个encoder to decoder模型,传统的NMT使用两个RNN,一个RNN对源语言进行编码,将源语言编码到一个固定维度的中间向量,再使用一个RNN进行解码翻译到目标语言:

按照论文所述,encoder中的每个隐层单元的计算公式为:
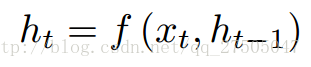
encoder的输出语义编码向量c为:
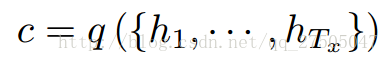
而decoder通过将联合概率p(y)分解成有序条件来定义翻译y的概率:
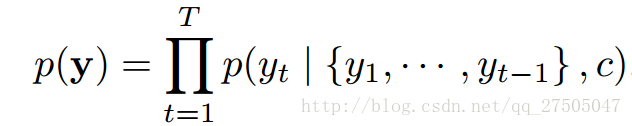
2.9.2 引入注意力机制
而引入注意力机制后的模型如下:
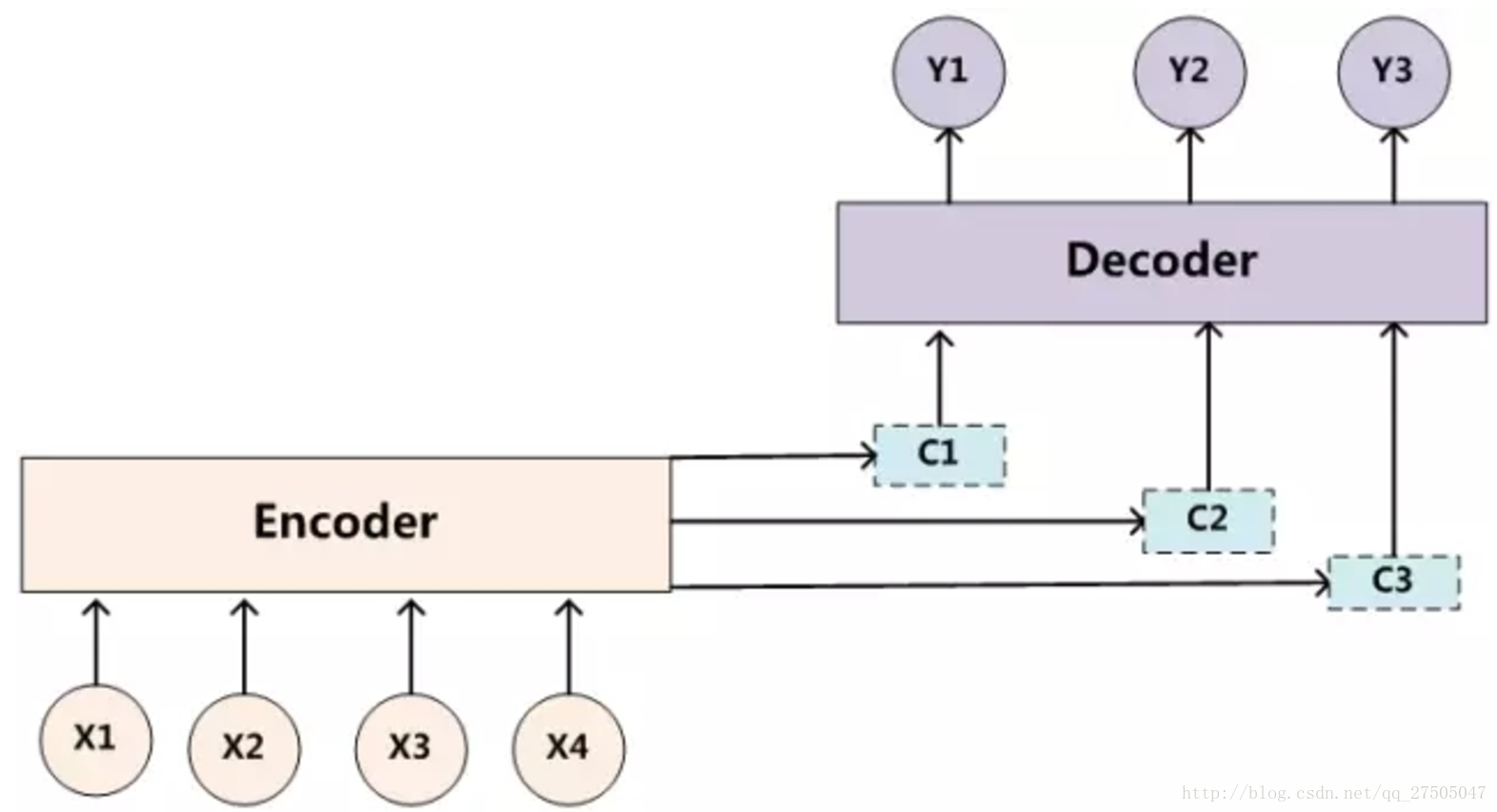
此时,关于p(y)的定义变化如下:

此处c变成了ci,即要输出的第i个单词时对应的ci向量,因此要如何计算ci向量时注意力机制实现的关键.但在此之前si的计算也变成了:
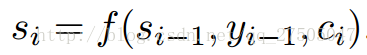
此时引入 论文示意图:
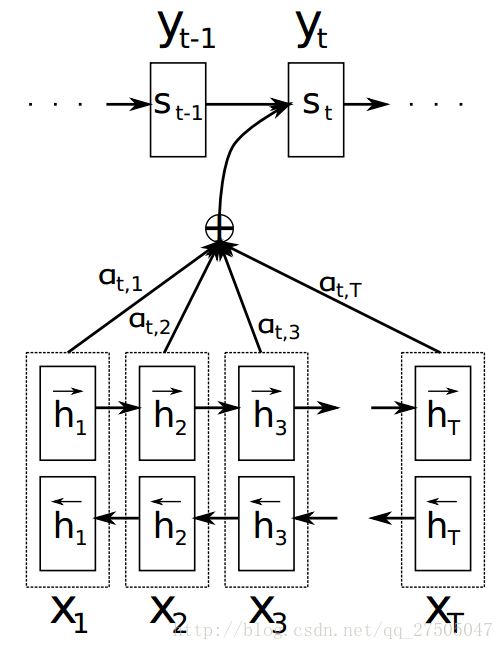
2.9.3 attention的计算方式
那么重点来了,这个系数a是怎么计算的呢?
注意机制计算过程:
- 计算每个编码器输入 与 解码器隐藏状态的相似度,以获得每个编码器输入的可能性分布。
- 计算 基于可能性分布的 编码器注意力的加权和。ci是所有具有概率αij的hj的期望。

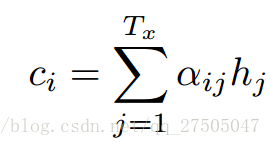
2.10 Transformer(“Attention Is All You Need”)
参考mijiaoxiaosan的博文:《对Attention is all you need 的理解》
参考 paperweekly 《一文读懂「Attention is All You Need」| 附代码实现》 https://yq.aliyun.com/articles/342508
带注意的 seq2seq是解决序列生成问题的典型模型,如翻译、对话系统。
Transformer,它仅仅依靠注意机制执行这些任务 (编码器 解码器 都只用attention),是快速的、实现新的最先进的结果。
结构如下:
- 编码器:
由N = 6个相同层的堆叠组成。
每个层都有两个子层。第一是多向自注意机制;第二个是全连接前馈网络。
- 解码器:
1.解码器由N = 6个相同层的堆叠组成。
2.除了每个编码器层中的两个子层之外,解码器多加入了一层 多向注意。
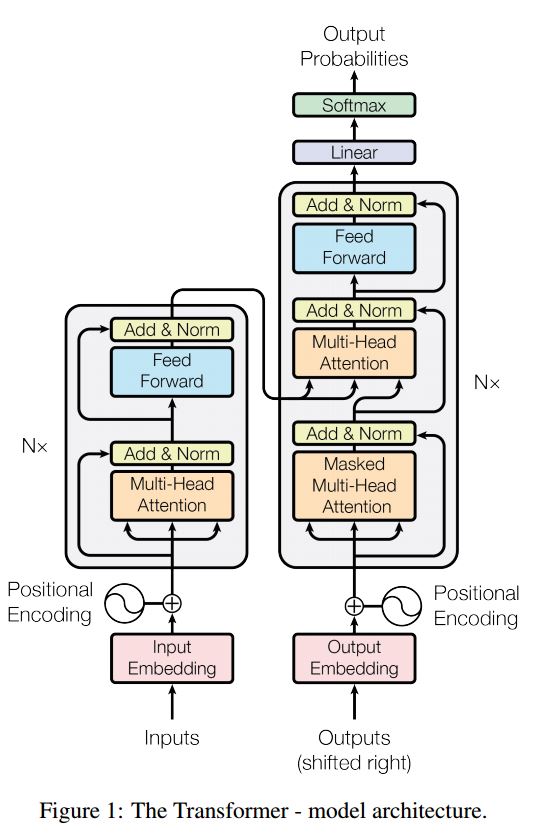
这个模型主要创新点: ==多头注意力 和位置编码== 关键点:
- ==位置编码==: 由于模型没有任何循环或者卷积,为了使用序列的顺序信息,需要将tokens的相对以及绝对位置信息注入到模型中去。论文在输入embeddings的基础上加了一个“位置编码”。位置编码和embeddings由同样的维度都是d 所以两者可以直接相加。 有很多位置编码的选择,既有学习到的也有固定不变的。本文中用了正弦和余弦函数进行编码。PosEnc(pos,2i)=sin(pos/100002i/dmodel)PosEnc(pos,2i)=sin(pos/100002i/dmodel)` `PE(pos,2i+1)=cos(pos/100002i/dmodel)PE(pos,2i+1)=cos(pos/100002i/dmodel)
其中的pos是位置,i是维度(比如50维的词向量 如果位置 和 确定了 )。 偶数维度用sin 奇数维度用cos。 最后将词向量与位置向量直接相加。 - ==多头注意力 的基本组成单位==:
- 普通注意力 :attention函数可以看作将一个query和一系列key-value对映射为一个输出(output)的过程(多数情况下 K和V是同一向量)事实上这种 Attention 的定义并不新鲜,但由于 Google 的影响力,我们可以认为现在是更加正式地提出了这个定义,并将其视为一个层地看待。。
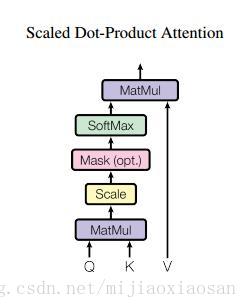
- 论文自创在普通attention的基础上加了一个Scale(缩放层):计算query和所有keys的点乘,然后每个都除以dk−−√(这个操作就是所谓的Scaled)。之后利用一个softmax函数来获取values的权重。 这样可以起到“归一化”的作用。Mask层没看懂。
- 总的来说 attention公式如下:Attention(Q,K,V)=softmax(QKTdk√)VAttention(Q,K,V)=softmax(QKTdk)V 。只要稍微思考一下就会发现,这样的 Self Attention模型并不能捕捉序列的顺序。换句话说,如果将 K,V 按行打乱顺序(相当于句子中的词序打乱),那么 Attention 的结果还是一样的。但是对于 NLP 中的任务来说,顺序是很重要的信息,它代表着局部甚至是全局的结构,学习不到顺序信息,那么效果将会大打折扣。于是 Google 再祭出了一招——Position Embedding,也就是上面的“位置向量”。
- 普通注意力 :attention函数可以看作将一个query和一系列key-value对映射为一个输出(output)的过程(多数情况下 K和V是同一向量)事实上这种 Attention 的定义并不新鲜,但由于 Google 的影响力,我们可以认为现在是更加正式地提出了这个定义,并将其视为一个层地看待。。
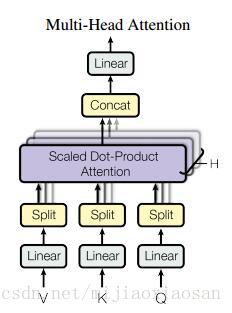
- ==Multi-Head Attention 多头注意力==:本文结构中的Attention并不是简简单单将一个attention应用进去。作者发现对 原始向量 进行h 次不同的attention,再拼接起来 效果特别好。所谓“多头”(Multi-Head),就是只多做几次同样的事情(参数不共享),然后把结果拼接。
分别对每一个映射之后的得到的queries,keys以及values进行attention函数的并行操作,最后拼接成output值。具体操作细节如以下公式。 MultiHead(Q,K,V)=Concat(head1,...,headh)MultiHead(Q,K,V)=Concat(head1,...,headh) where:headi=Attention(QWiQ,KWiK,VWiV)where:headi=Attention(QWiQ,KWiK,VWiV) 结构示意图:
2.11 循环实体网络(Recurrent Entity Network)
这篇论文是facebook AI在2017年的ICLR会议上发表的,文章提出了Recurrent Entity Network的模型用来对world state进行建模,根据模型的输入对记忆单元进行实时的更新,从而得到对world的一个即时的认识。该模型可以用于机器阅读理解等领域。
输入:
- 故事:它是多句话,作为上下文。
- 问题:一个句子,这是一个问题。
- 回答:一个单一的标签。
和之前的模型一样,Entity Network模型共分为Input Encoder、Dynamic Memory和Output Model三个部分。如下图的架构图所示:
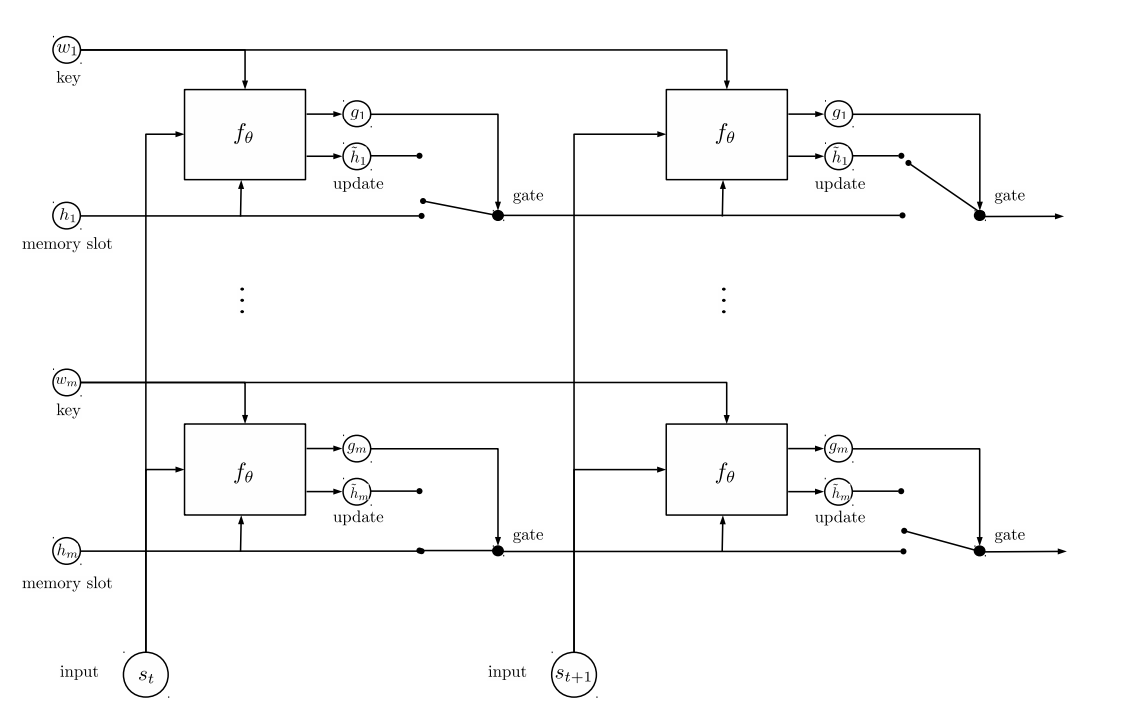
模型结构:
1.输入编码层:利用RNN或者LSTM等时序神经网络模型,使用最后一个时间步长的状态作为句子编码 来编码故事(上下文)和查询(问题)st就是固定长度的句子的向量表示。
2.动态记忆:
a. 通过使用键的“相似性”,输入故事的值来计算门控。
b. 通过转换每个键,值和输入来获取候选隐藏状态。
c. 组合门和候选隐藏状态来更新当前的隐藏状态。
t时刻输入st时,每个隐含层状态hj通过st和key wj来更新,更新公式如下:
gj←σ(sTthj+sTtwj)gj←σ(stThj+stTwj)
hj~←ϕ(Uhj+Vwj+Wst)hj~←ϕ(Uhj+Vwj+Wst)
hj←hj+gj⊙hj~hj←hj+gj⊙hj~
hj←hj∥hj∥hj←hj‖hj‖
例如:
- Mary picked up the ball.
- Mary went to the garden.
- Where is the ball?
前两句是文本,最后一句是问题。由第一句得到在时间步长t的句子表达st,由第二句得到时间步长t+1的句子表达st+1。
- 当st被读取,w1记录实体Mary,h1记录实体状态Mary拿了一个ball;
- w2记录实体ball,h2记录实体状态ball被Mary拿着;
- 然后st+1被读取,读取到Mary,因为w1是记录Mary的key,位置寻址项sTt+1w1变化,门函数被激活,更新h1实体状态Mary去了garden;
-
因为h2记录ball被mary拿着,因此内容寻址项sTt+1h2变化,门函数被激活,更新h2的实体状态球被mary拿着,球在garden。
- Output Model
在原文中使用了一层的记忆网络,因此得到最后一个时间步长的隐层向量hj以后,就可以直接输出。
- Output Model
2.12 动态记忆网络
原文:《Ask me anything: dynamic memory networks for natural language processing》
博客参考:https://blog.csdn.net/javafreely/article/details/71994247
Question answering 是自然语言处理领域的一个复杂问题. 它需要对文本的理解力和推理能力.DMN 的输入包含事实输入,问题输入,经过内部处理形成片段记忆,最终产生问题的答案.
DMN 由4个模块组成:
- 输入模块: 将原生文本输入编码成分布式向量表示. NLP 问题中,输入可以是一个句子,一个故事,电影评论,新闻文章或者维基百科文章等. 它的输入是 Work embedding(如通过 word2vec 或 GloVe 编码).
- 问题模块: 同输入模块类似,也是一个 RNN 网络. 输出是最后隐藏节点.
- 片段记忆模块: 片段记忆模块通过注意力机制决定关注输入数据的那些部分,并根据之前的记忆和问题产生新的记忆.
- 回答模块:回答模块也是一个 GRU 网络.其中上次输出和问题一起作为gru节点的输入。 根据最终记忆,产生问题的回答.
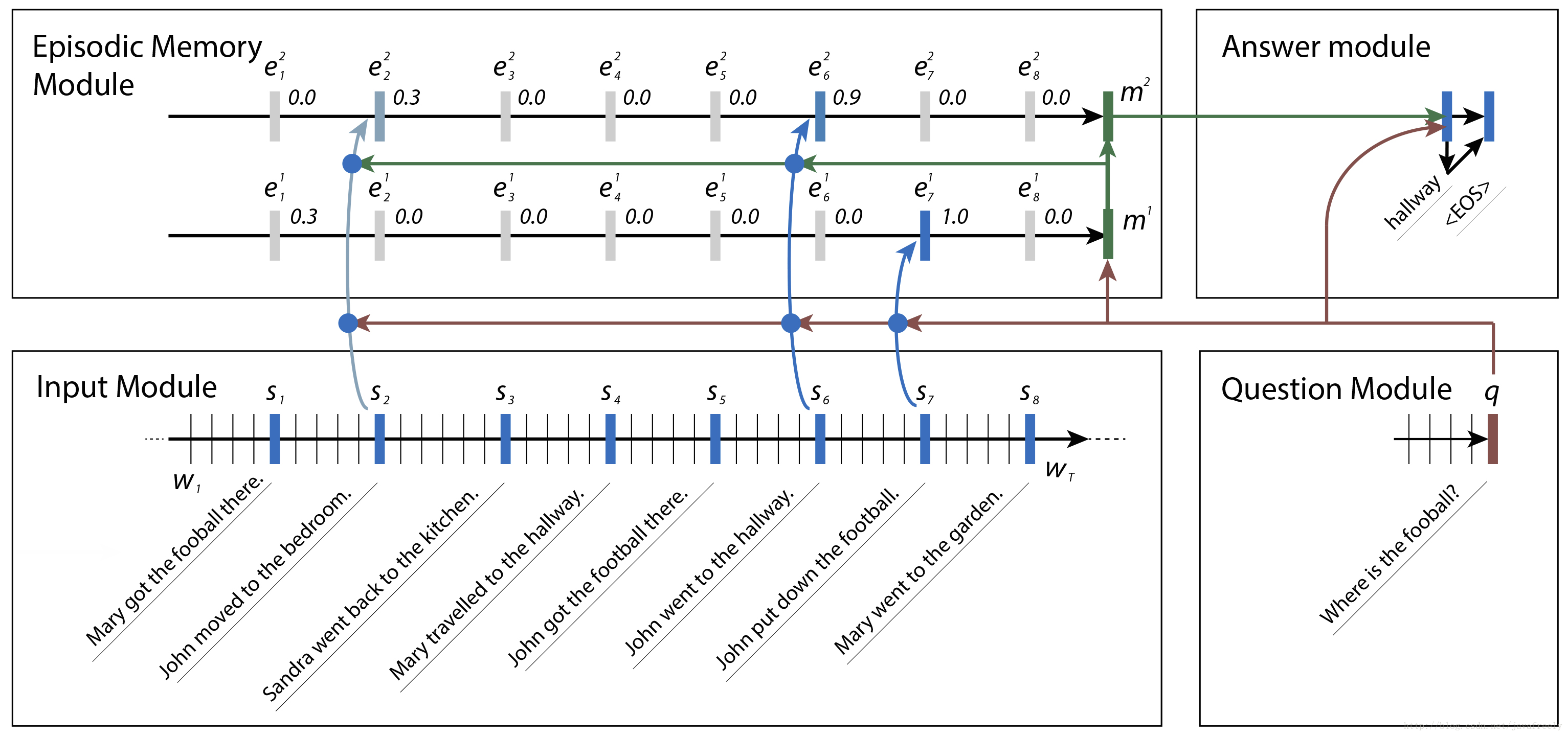
-
输入模块
- 输入模块是一个 RNN 网络. 它的输入是 Work embedding(如通过 word2vec 或 GloVe 编码). 输入是 TI个单词 w1,…,wTI .
- 在每个时间点 t,RNN 更新其隐藏状态 ht=RNN(L[wt],ht−1) . L 是 word embedding matrix.
- 在输入只有一个句子的情况下,输入模块输出 RNN 的所有隐藏状态.
- 在输入是多个句子的情况下,我们将所有句子拼接,并在每个句子末尾插入句末 token. RNN 每个句末 token 位置的隐藏状态作为输出.
- 输入模块的输出序列为 Tc 个 fact representation c. 其中 ctct 是输出序列的第 t 个元素. 输入多个句子的情况下,TC 是句子个数.
- RNN 的选择: 原生的 RNN 性能较差, GRU 和 LSTM 性能差不多,但 LSTM 的计算更加昂贵,所以一般使用 GRU.
-
问题模块
- 同输入模块类似,也是一个 RNN 网络.
- 输出是最后隐藏节点 qTQ. (不同于输入模块,输入模块的输出是多个隐藏节点)
-
片段记忆模块
- 每个迭代都根据之前的记忆mi−1mi−1、问题q 和事实 c 产生新的片段 ei.新的episode (e)等于eit=G(ct,mm−1,q)eti=G(ct,mm−1,q) (其中初始: m 0 = q) (e每次都带着q)
- 在当前E之下:片段记忆在输入模块输出的事实 c 上迭代,更新内部的片段记忆.mi=GRU(ei,mi−1)mi=GRU(ei,mi−1)
- 注意力机制:本文使用门控功能作为我们的注意机制,门函数 G(c,m,q)=σ(W(2)tanh(W(1)z(c,m,q)+b(1))+b(2)) 来衡量当前 句子的关注力
-
回答模块
- 回答模块也是一个 GRU 网络.
- 初始值为 a0=mTM
- 输出为 yt=softmax(W(a)at)
- 隐藏状态 at=GRU([yt−1,q],at−1), 上次输出和问题一起作为输入

