
- 1微服务: 04-springboot中rabbitmq的yml或properties配置,消息回收,序列化方式_rabbitmq yml配置
- 22023年最新最全的显卡深度学习AI算法算力排行(包括单精度FP32和半精度FP16的对比)_显卡算力排行2023
- 3spring security使用心得_loaduserbyusername 增加参数
- 4C++ Windows窗口程序:子窗口控件之按钮类button_bs_pushbutton
- 5STM32的GPIO端口的八种模式解析
- 6dex2jar 和 jd-gui 的安装与使用
- 7大数据技术之——zookeeper的安装部署_zookeeper安装部署
- 8自然语言处理_鲁骁 博士
- 9Pixhawk更换GPS协议 由默认ublox更换为NMEA GPGGA格式_pix光流怎和gps切换
- 10SQLITE中文编码转换的问题终于解决了。_sqlite 如何把存储的字符串格式改为gbk
写代码神器!48个主流代码生成LLM大模型盘点,包含专用、微调等4大类Code llama_编写代码的模型有哪些
赞
踩
写代码神器!48个主流代码生成LLM大模型盘点,包含专用、微调等4大类
学姐带你玩AI 2023-12-06 18:20
代码大模型具有强大的表达能力和复杂性,可以处理各种自然语言任务,包括文本分类、问答、对话等。这些模型通常基于深度学习架构,如Transformer,并使用预训练目标(如语言建模)进行训练。
在对大量代码数据的学习和训练过程中,代码大模型能够提升代码编写的效率和质量,辅助代码理解和决策,在代码生成、代码补全、代码解释、代码纠错以及单元测试等任务中都表现出十分出色的能力。
为了帮大家深入掌握代码大模型的发展历程和挑战,学姐这次整理了相关的48个模型以供同学们学习,分为了4大类,包括原始LM、LM改进、专用LM,以及微调模型。
原始LM
1.Lamda: Language models for dialog applications
用于对话应用程序的语言模型
模型简介:LaMDA是一种专门用于对话的神经网络语言模型,通过预训练和微调,可以显著提高其安全性和事实依据。在安全性方面,使用少量众包工人注释的数据进行微调的分类器过滤候选响应可以提高模型的安全性。在事实依据方面,允许模型咨询外部知识源可以使生成的响应基于已知来源。

2.Palm: Scaling language modeling with pathways
使用路径缩放语言模型
模型简介:本文介绍了一种名为PaLM的540亿参数密集激活Transformer语言模型,使用Pathways新机器学习系统在多个TPU Pod上进行高效训练。作者通过数百个语言理解和生成基准测试展示了规模缩放的持续优势,PaLM在一些多步推理任务上实现了突破性的性能,超过了最新的细调最先进技术和人类平均水平。此外,PaLM在多语言任务和源代码生成方面也表现出强大的能力。

3.Gpt-neox-20b: An open-source autoregressive language model
一个开源的自回归语言模型
模型简介:论文介绍了一种200亿参数的自回归语言模型GPT-NeoX-20B,该模型在Pile上进行训练,并通过允许性许可证向公众免费提供其权重。GPT-NeoX-20B是目前提交时公开可用权重最大的密集自回归模型。在这项工作中,作者描述了该模型的架构和训练,并在一系列语言理解、数学和基于知识的任务上评估了其性能。作者发现GPT-NeoX-20B是一个非常强大的少样本推理器,当评估5个示例时,其性能比类似的GPT-3和FairSeq模型获得更多收益。

-
4.BLOOM: A 176b-parameter open-access multilingual language model
-
5.lama: Open and efficient foundation language models
-
6.GPT-4 technical report
-
7.lama 2: Open foundation and finetuned chat models
-
8.Textbooks are all you need II: phi-1.5 technical report
LM改进
1.Evaluating large language models trained on code
评估基于代码训练的大型语言模型
模型简介:Codex是一个用GPT模型微调的代码生成器,它在GitHub Copilot中有应用。在HumanEval评估集中,Codex的表现优于GPT-3和GPT-J。此外,通过从模型中重复采样,可以生成对困难提示的有效解决方案。然而,Codex存在局限性,例如难以处理描述长操作链的文档字符串以及将操作绑定到变量的能力。最后,作者讨论了部署强大的代码生成技术可能带来的更广泛的影响,包括安全、隐私和伦理问题。
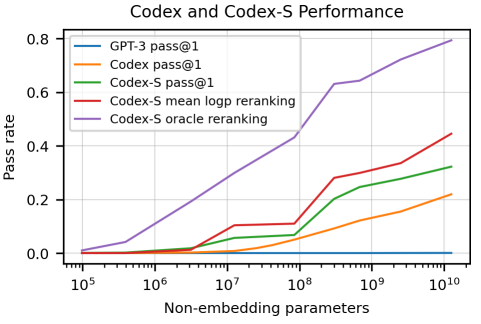
2.Solving quantitative reasoning problems with language models
使用语言模型解决定量推理问题
模型简介:本文介绍了一种名为Minerva的大型语言模型,该模型在一般自然语言数据上进行预训练,并在技术内容上进行了进一步的训练。该模型在技术基准测试中实现了最先进的性能,而无需使用外部工具。作者还对物理学、生物学、化学、经济学和其他需要定量推理的科学领域的200多个本科水平的问题进行了评估,发现该模型可以正确回答近三分之一的问题。

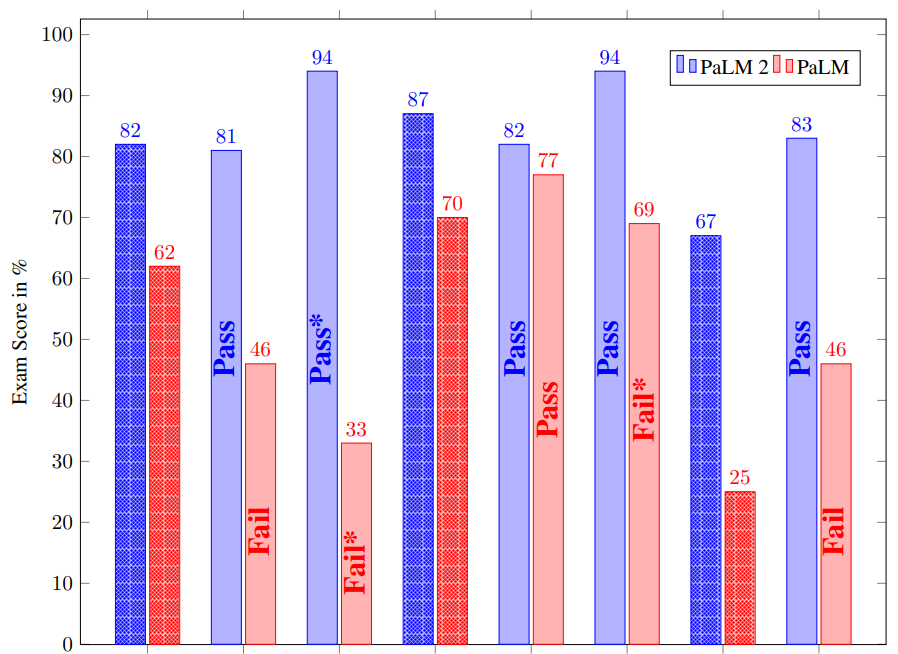
3.Palm 2 technical report
Palm 2技术报告
模型简介:本文介绍了一种新型最先进的语言模型,该模型具有更好的多语言和推理能力,并且比其前身PaLM更计算高效。PaLM 2是一种基于Transformer的模型,使用多种目标进行训练。通过在英语和多语言语言以及推理任务上的广泛评估,作者证明PaLM 2在不同模型大小下对下游任务的质量有显著提高,同时表现出比PaLM更快和更高效的推理。
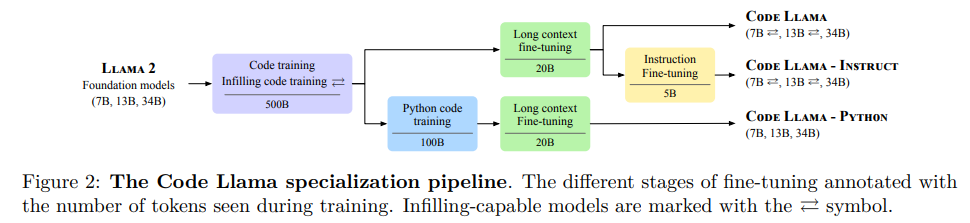
4.Code llama: Open foundation models for code
开放源代码模型
模型简介:论文提出了一个大型语言模型家族CodeLlama,可以生成代码,具有先进性能、开箱即用的填充能力以及对编程任务的指令跟随能力。作者提供了多种版本,覆盖各种应用,所有模型都在16k个令牌的序列上进行训练,并在最多100k个令牌的输入上有所改进。该模型在几个基准测试中表现出色,作者也发布了CodeLlama的Python版本。
专用LM
1. Learning and evaluating contextual embedding of source code
学习与评估源代码的上下文嵌入
模型简介:本文介绍了一种名为CuBERT的开源代码理解BERT模型,该模型使用GitHub上740万个Python文件的去重语料库进行预训练。作者还创建了一个包含五个分类任务和一个程序修复任务的开源基准测试集,类似于文献中提出的代码理解任务。作者将CuBERT与不同的Word2Vec标记嵌入、BiLSTM和Transformer模型以及已发布的最先进模型进行了比较,结果表明,即使使用较短的训练时间和较少的标记示例,CuBERT也能超越所有其他模型。

2.Codebert: A pre-trained model for programming and natural languages
一种用于编程和自然语言的预训练模型
模型简介:论文介绍了一种新的预训练模型CodeBERT,用于编程语言和自然语言。该模型使用基于Transformer的神经网络架构进行开发,并使用混合目标函数进行训练,以支持下游的自然语言代码搜索、代码文档生成等应用。作者通过微调模型参数在两个NL-PL应用上评估了CodeBERT的性能,结果表明,CodeBERT在这些任务上表现出色。
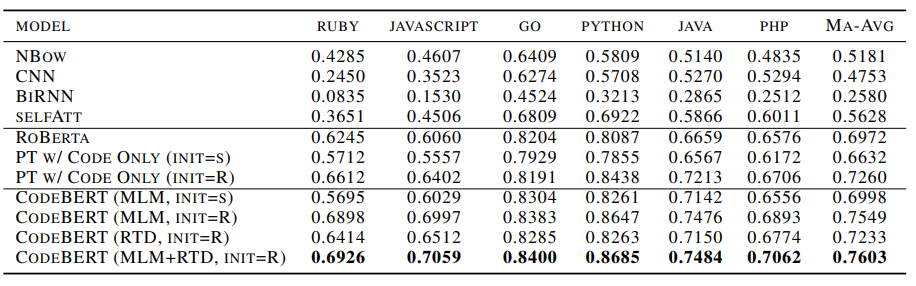
3.Graphcodebert: Pre-training code representations with data flow
基于数据流的代码表征预训练模型
模型简介:论文介绍了一种基于数据流的代码表征预训练模型Graphcodebert,该模型考虑了代码的内在结构。作者使用数据流作为语义级别的代码结构,而不是采用抽象语法树(AST)这样的语法级别的代码结构。作者还引入了两个结构感知的预训练任务,并在四个任务上评估了该模型,结果表明该模型在代码搜索、克隆检测、代码翻译和代码优化等任务上表现出色。

扫码添加小享,回复“代码大模型”
免费获取模型原文+代码合集

-
4.Syncobert: Syntax-guided multi-modal contrastive pre-training for code representation
-
5.CODE-MVP: learning to represent source code from multiple views with contrastive pre-training
-
6.Intellicode compose: code generation using transformer
-
7.Codexglue: A machine learning benchmark dataset for code understanding and generation
-
8.A systematic evaluation of large language models of code
-
9.Codegen: An open large language model for code with multi-turn program synthesis
-
10.CERT: continual pretraining on sketches for library-oriented code generation
-
11.Pangu-coder: Program synthesis with function-level language modeling
-
12.Codegeex: A pre-trained model for code generation with multilingual evaluations on humaneval-x
-
13.Textbooks are all you need
-
14.Codefuse-13b: A pretrained multi-lingual code large language model
-
15.Incoder: A generative model for code infilling and synthesis
-
16.Santacoder: don’t reach for the stars!
-
17.Starcoder: may the source be with you!
-
18.Multi-task learning based pre-trained language model for code completion
-
19.Unixcoder: Unified cross-modal pre-training for code representation
-
20.Pymt5: multi-mode translation of natural language and python code with transformers
-
21.Studying the usage of text-to-text transfer transformer to support code-related tasks
-
22.DOBF: A deobfuscation pre-training objective for programming languages
-
23.Unified pre-training for program understanding and generation
-
24.Codet5: Identifier-aware unified pre-trained encoder-decoder models for code understanding and generation
-
25.Sptcode: Sequence-to-sequence pre-training for learning source code representations
-
26.Competition-level code generation with alphacode
-
27.Natgen: generative pre-training by "naturalizing" source code
-
28.Codet5+: Open code large language models for code understanding and generation
代码微调
1.Wizardcoder: Empowering code large language models with evolinstruct
使用evolinstruct为大型语言模型提供动力
模型简介:本文介绍了WizardCoder模型,它通过将Evol-Instruct方法应用于代码领域,为大型语言模型提供了更强的能力。作者在四个著名的代码生成基准测试上进行了实验,结果表明该模型比其他开源的大型语言模型表现更好,甚至超过了一些封闭的语言模型。

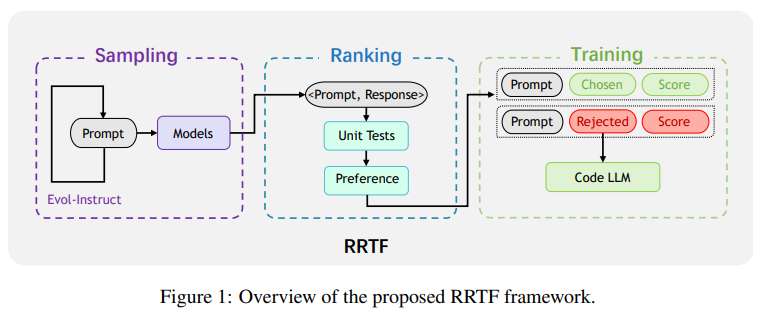
2.Pangu-coder2: Boosting large language models for code with ranking feedback
使用排名反馈提高大型语言模型的代码能力
模型简介:论文提出了一种新的RRTF(Rank Responses to align Test&Teacher Feedback)框架,可以有效且高效地提高预训练的大型语言模型的代码生成能力。在该框架下,作者提出了PanGu-Coder2,它在OpenAI HumanEval基准测试上达到了62.20%的pass@1。此外,通过对CoderEval和LeetCode基准测试进行广泛评估,作者表明PanGu-Coder2始终优于之前的所有Code LLM。
3.Octopack: Instruction tuning code large language models
指令调优代码大型语言模型
模型简介:该论文介绍了通过使用Git提交中的代码更改和人类指令,对大型语言模型进行指令调优的方法。这种方法利用了自然结构的Git提交,将代码更改与人类指令配对起来。他们编译了一个包含4TB数据的数据库CommitPack,涵盖了350种编程语言的Git提交。在16B参数的StarCoder模型上,与其他指令调优模型进行基准测试,该方法在HumanEval Python基准上取得了最佳性能(46.2% pass@1)。

-
4.Mftcoder: Boosting code llms with multitask fine-tuning
-
5.Compilable neural code generation with compiler feedback
-
6.Coderl: Mastering code generation through pretrained models and deep reinforcement learning
-
7.Execution-based code generation using deep reinforcement learning
-
8.RLTF: reinforcement learning from unit test feedback


