
- 1Mac安装Tesseract的全过程,附带完整的错误和异常的解决办法。Java开源OCR识别_warning: parameter not found: enable_new_segsearch
- 2FPGA - ZYNQ Cache一致性问题
- 3Linux笔记1_虚拟机安装Linux操作系统
- 4『大模型笔记』视觉语言模型解释
- 5Redis的三种限流方法以及代码详解_java redis集群限流
- 6Kubernetes——Kubernetes命令操作集合_k logs -f
- 7【NLP】3 种强大的长文本摘要方法和实例
- 8【深度学习:评估指标】如何在计算机视觉中测量模型性能:综合指南
- 9通过SSH的方式使用Git提交代码_git push提交代码的时候如何调用提交到ssh路径(1)
- 10springboot启动源码分析1——初步初始化_bootstrapregistryinitializer
阿里开源Qwen-1.5-32B模型,性能超Mixtral MoE_qwen1.5-32b
赞
踩
简介
开源社区长期以来一直在寻求一种能在性能、效率和内存占用之间达到理想平衡的模型。尽管出现了诸如Qwen1.5-72B和DBRX这样的SOTA模型,但这些模型持续面临诸如内存消耗巨大、推理速度缓慢以及显著的微调成本等问题。当前,参数量约30B的模型往往在这方面被看好,得到很多用户的青睐。顺应这一趋势,阿里推出Qwen1.5语言模型系列的最新成员:Qwen1.5-32B和Qwen1.5-32B-Chat。

效果
Qwen1.5-32B 是 Qwen1.5 语言模型系列的最新成员,除了模型大小外,其在模型架构上除了GQA几乎无其他差异。GQA能让该模型在模型服务时具有更高的推理效率潜力。
以下对比展示了其与参数量约为30B或更大的当前最优(SOTA)模型在基础能力评估、chat评估以及多语言评估方面的性能。以下是对于基础语言模型能力的评估结果:
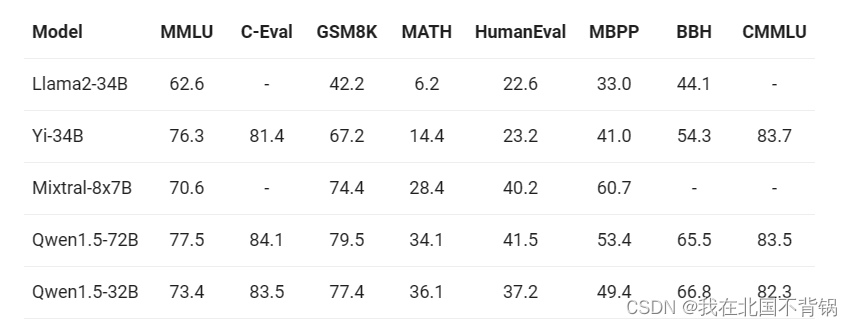
阿里Qwen-1.5-32B模型在多种任务上展现出颇具竞争力的表现,涵盖MMLU、GSM8K、HumanEval以及BBH等。相较于72B参数模型,Qwen1.5-32B虽在性能上有轻微下降,但在多数任务中仍优于其他30B级别模型,如Llama2-34B和Mixtral-8x7B。
在Chat模型的评估上,遵循Qwen1.5的评估方案,对它们在MT-Bench与Alpaca-Eval 2.0上的表现进行了测试。具体结果如下:
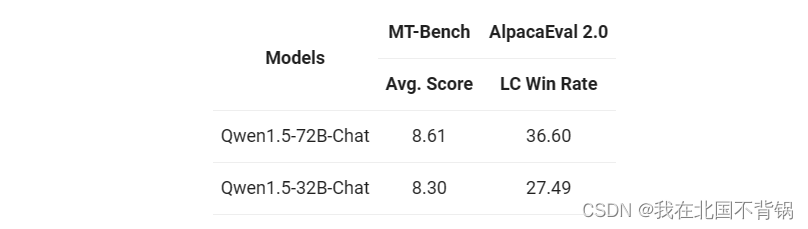
值得注意的是,Qwen1.5-32B-Chat的得分超过8分,且Qwen1.5-32B-Chat与Qwen1.5-72B-Chat之间的差距相对较小。这一结果表明,对于需要更高效、更经济实惠的应用解决方案的用户而言,32B模型是一个可行的选择。
本地使用
Qwen-1.5-32B模型使用与其他参数模型类似,这里推荐使用Ollama框架。
ollama run qwen:32b
- 1
在线体验
https://huggingface.co/spaces/Qwen/Qwen1.5-32B-Chat-demo

