
- 1卡尔曼滤波融合库函数+Arduino实例_arduino卡尔曼函数库
- 2FineBl概述
- 3大型语言模型的语义搜索(一):关键词搜索_如何查看大模型的关键词
- 4记录分享vue3通过web3.js连接MetaMask的流程及签名、验签方法_vue 开发web3.js
- 5Fastadmin vps离线安装插件失败解决方案(转发)_fastadmin插件离线安装
- 6List of BAPI's_docp269
- 7git 如何撤销某次远程仓库的提交_git撤销远程提交
- 8Spark集群的搭建
- 9Stable Diffusion使用controlnet报错 mat1 and mat2 shapes cannot be multiplied问题_runtimeerror: mat1 and mat2 shapes cannot be multi
- 10linux 查看io 进程,如何查看具体进程的IO情况?
Python图像处理之图片文字识别(OCR)_python图像ocr
赞
踩
OCR与Tesseract介绍
将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR)。可以实现OCR 的底层库并不多,目前很多库都是使用共同的几个底层OCR 库,或者是在上面进行定制。
Tesseract 是一个OCR 库,目前由Google 赞助(Google 也是一家以OCR 和机器学习技术闻名于世的公司)。Tesseract 是目前公认最优秀、最精确的开源OCR 系统。
除了极高的精确度,Tesseract 也具有很高的灵活性。它可以通过训练识别出任何字体(只要这些字体的风格保持不变就可以),也可以识别出任何Unicode 字符。
Tesseract的安装与使用
Tesseract的Windows安装包下载地址为: http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe ,下载后双击直接安装即可。安装完后,需要将Tesseract添加到系统变量中。在CMD中输入tesseract -v, 如显示以下界面,则表示Tesseract安装完成且添加到系统变量中。
Linux 用户可以通过apt-get 安装:
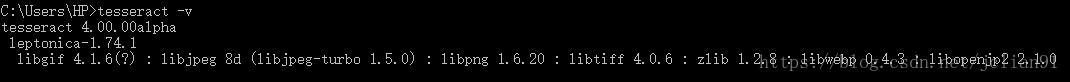
$sudo apt-get tesseract-ocr
- 1
用Tesseract可以识别格式规范的文字,主要具有以下特点:
• 使用一个标准字体(不包含手写体、草书,或者十分“花哨的”字体)
• 虽然被复印或拍照,字体还是很清晰,没有多余的痕迹或污点
• 排列整齐,没有歪歪斜斜的字
• 没有超出图片范围,也没有残缺不全,或紧紧贴在图片的边缘
下面将给出几个tesseract识别图片中文字的例子。
首先是E://figures/other/poems.jpg, 输入命令 tesseract E://figures/other/poems.jpg E://figures/other/poems.txt, 则会将poems.jpg中的识别文字写入到poems.txt中,如下图:
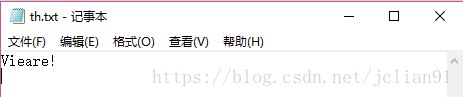
接着是稍微有点倾斜的文字图片th.jpg,识别情况如下:
可以看到识别的情况不如刚才规范字体的好,但是也能识别图片中的大部分字母。
最后是识别简体中文,需要事先安装简体中文语言包,下载地址为:https://github.com/tesseract-ocr/tessdata/find/master/chi_sim.traineddata ,再讲chi_sim.traineddata放在C:\Program Files (x86)\Tesseract-OCR\tessdata目录下。我们以图片timg.jpg为例:
输入命令:





tesseract E://figures/other/timg.jpg E://figures/other/timg.txt -l chi_sim
- 1
识别结果如下:
只识别错了一个字,识别率还是不错的。
最后加一句,Tesseract对于彩色图片的识别效果没有黑白图片的效果好。

pytesseract
pytesseract是Tesseract关于Python的接口,可以使用pip install pytesseract安装。安装完后,就可以使用Python调用Tesseract了,不过,你还需要一个Python的图片处理模块,可以安装pillow.
输入以下代码,可以实现同上述Tesseract命令一样的效果:
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
text = pytesseract.image_to_string(Image.open('E://figures/other/poems.jpg'))
print(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
运行结果如下:

参考文献
- Python网络数据采集 【美】 Ryan Mitchell 人民邮电出版社
- https://blog.csdn.net/dcrmg/article/details/78233459?locationNum=7&fps=1
- http://www.inimei.cn/archives/297.html
***注意:***本人现已开通微信公众号: 轻松学会Python爬虫(微信号为:easy_web_scrape), 欢迎大家关注哦~~


