
- 1线性回归实战1:预测boston房价_波士顿房价预测
- 2使用nodejs+Socket打造P2P实现多人聊天室_node.js多人聊天室
- 3基于docker安装elastalert2进行日志监控报警_elastalert2 docker
- 4mysql的注入原理_MySQL教程(内含sql注入原理详解及方法)
- 52023-12-30 AIGC-LangChain指南-打造LLM的垂域AI框架_openagents
- 6二级题库(C语言)------ 第三套题_结构化程序使用什么语句会很便捷
- 7Android Studio 查看打开Room数据库数据
- 8【MATLAB第1期】LSTM/GRU网络回归/分类预测改进与优化合集(含录屏操作,持续更新)_matlablstm的例子
- 9文本的向量化表示总结
- 10leetCode 122.买卖股票的最佳时机 II 动态规划 + 状态转移 + 状态压缩
数学建模--数据预处理_数学建模数据处理
赞
踩
目录
一、数据统计
数据统计一般包括求矩阵最大、最小元素,求矩阵平均值和中值, 矩阵元素求和、求积,矩阵元素累加和与累乘积,求标准方差、相关系数、元素排序等。
直接举例子说明
1、行列式的最大元素和最小元素

- 命令如下:
- A=[12,45,58;25,60,-45;56,25,178;2,0,-13];
- max(A,[],2) %求每行最大元素
- ans =
- 58
- 60
- 178
- 2
- max(A) %求每列最大元素
- ans =
- 56 60 178
- min(min(A)) %求整个矩阵的最小元素。也可用命令:min(A(:))
- ans =
- -45
2、求向量的平均值和中值
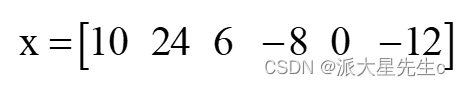
- 命令如下:
- x=[10,24,6,-8,0,-12]; %偶数个元素
- mean(x) %求此向量的平均值
- x =
- 10 24 6 -8 0 -12
- ans =
- 3.3333
- median(x) %求此向量的中值
- ans =
- 3
3、对矩阵做排序

- 命令如下:
-
- A=[0,-11,5;1,15,7;16,9,-20];
-
- sort(A) %对A的每列按升序排序
-
- ans =
-
- 0 -11 -20
-
- 1 9 5
-
- 16 15 7
-
-
-
- -sort(-A,2) %对A的每行按降序排列
-
- ans =
-
- 5 0 -11
-
- 15 7 1
-
- 16 9 -20
-
-
-
- [X,I]=sort(A) %对A按列排序,并将每个元素所在行号送矩阵I
-
- X =
-
- 0 -11 -20
-
- 1 9 5
-
- 16 15 7
-
- I =
-
- 1 1 3
-
- 2 3 1
-
- 3 2 2

二、数据优化(数据残缺值和异常值的处理)
插值和拟合都是数据优化的一种方法,当实验数据不够多时经常需要用到这种方法来画图。在MATLAB中都有特定的函数来完成这些功能。这两种方法的确别在于:
当测量值是准确的,没有误差时,一般用插值;
当测量值与真实值有误差时,一般用数据拟合。
1、数据残缺
①插值
对于一维曲线的插值,一般用到的函数yi=interp1(X,Y,xi,method) ,其中method包括nearst,linear,spline,cubic。
对于二维曲面的插值,一般用到的函数zi=interp2(X,Y,Z,xi,yi,method),其中method也和上面一样,常用的是cubic。
- %产生原始数据
- x=0:0.1:1;
- y=(x.^2-3*x+7).*exp(-4*x).*sin(2*x);
- subplot(2,2,1);
- plot(x,y);
- title('原始数据');
- %线性插值
- xx=0:0.01:1;
- y1=interp1(x,y,xx,'linear');
- %subplot(2,2,1)
- %plot(x,y,'o',xx,y1);
- %title('线性插值');
- %最邻近点插值
- y2=interp1(x,y,xx,'nearest');
- subplot(2,2,2)
- plot(x,y,'o',xx,y2);
- title('最邻近点插值');
- %三次插值
- y3=interp1(x,y,xx,'pchip');
- subplot(2,2,3)
- plot(x,y,'o',xx,y3);
- title('三次插值');
- %三次样条插值
- y4=interp1(x,y,xx,'spline');
- subplot(2,2,4)
- plot(x,y,'o',xx,y4);
- title('三次样条插值');

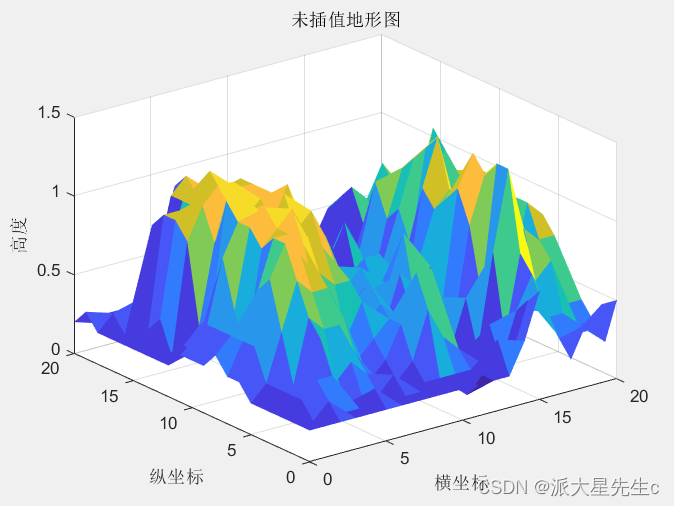
经典问题:利用给定的高度补充地图
- %插值基点为网格节点
- clear all
- y=20:-1:0;
- x=0:20;
- z=[0.2 0.2 0.2 0.2 0.2 0.2 0.4 0.4 0.3 0.2 0.3 0.2 0.1 0.2 0.2 0.4 0.3 0.2 0.2 0.2 0.2;
- 0.3 0.2 0.2 0.2 0.2 0.4 0.3 0.3 0.3 0.3 0.4 0.2 0.2 0.2 0.2 0.4 0.4 0.4 0.3 0.2 0.2;
- 0.2 0.3 0.3 0.2 0.3 1 0.4 0.5 0.3 0.3 0.3 0.3 0.2 0.2 0.2 0.6 0.5 0.4 0.4 0.2 0.2;
- 0.2 0.2 0.4 0.2 1 1.1 0.9 0.4 0.3 0.3 0.5 0.3 0.2 0.2 0.2 0.7 0.3 0.6 0.6 0.3 0.4;
- 0.2 0.2 0.9 0.7 1 1 1 0.7 0.5 0.3 0.2 0.2 0.2 0.6 0.2 0.8 0.7 0.9 0.5 0.5 0.4;
- 0.2 0.3 1 1 1 1.2 1 1.1 0.8 0.3 0.2 0.2 0.2 0.5 0.3 0.6 0.6 0.8 0.7 0.6 0.5;
- 0.2 0.4 1 1 1.1 1.1 1.1 1.1 0.6 0.3 0.4 0.4 0.2 0.7 0.5 0.9 0.7 0.4 0.9 0.8 0.3;
- 0.2 0.2 0.9 1.1 1.2 1.2 1.1 1.1 0.6 0.3 0.5 0.3 0.2 0.4 0.3 0.7 1 0.7 1.2 0.8 0.4;
- 0.2 0.3 0.4 0.9 1.1 1 1.1 1.1 0.7 0.4 0.4 0.4 0.3 0.5 0.5 0.8 1.1 0.8 1.1 0.9 0.3;
- 0.3 0.3 0.5 1.2 1.2 1.1 1 1.2 0.9 0.5 0.6 0.4 0.6 0.6 0.3 0.6 1.2 0.8 1 0.8 0.5;
- 0.3 0.5 0.9 1.1 1.1 1 1.2 1 0.8 0.7 0.5 0.6 0.4 0.5 0.4 1 1.3 0.9 0.9 1 0.8;
- 0.3 0.5 0.6 1.1 1.2 1 1 1.1 0.9 0.4 0.4 0.5 0.5 0.8 0.6 0.9 1 0.5 0.8 0.8 0.9;
- 0.4 0.5 0.4 1 1.1 1.2 1 0.9 0.7 0.5 0.6 0.3 0.6 0.4 0.6 1 1 0.6 0.9 1 0.7;
- 0.3 0.5 0.8 1.1 1.1 1 0.8 0.7 0.7 0.4 0.5 0.4 0.4 0.5 0.4 1.1 1.3 0.7 1 0.7 0.6;
- 0.3 0.5 0.9 1.1 1 0.7 0.7 0.4 0.6 0.4 0.4 0.3 0.5 0.5 0.3 0.9 1.2 0.8 1 0.8 0.4;
- 0.2 0.3 0.6 0.9 0.8 0.8 0.6 0.3 0.4 0.5 0.4 0.5 0.4 0.2 0.5 0.5 1.3 0.6 1 0.9 0.3;
- 0.2 0.3 0.3 0.7 0.6 0.6 0.4 0.2 0.3 0.5 0.8 0.8 0.3 0.2 0.2 0.8 1.3 0.9 0.8 0.8 0.4;
- 0.2 0.3 0.3 0.6 0.3 0.4 0.3 0.2 0.2 0.3 0.6 0.4 0.3 0.2 0.4 0.3 0.8 0.6 0.7 0.4 0.4;
- 0.2 0.3 0.4 0.4 0.2 0.2 0.2 0.3 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.5 0.7 0.4 0.4 0.3 0.3;
- 0.2 0.2 0.3 0.2 0.2 0.3 0.2 0.2 0.2 0.2 0.2 0.1 0.2 0.4 0.3 0.6 0.5 0.3 0.3 0.3 0.2;
- 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0.4 0.7 0.4 0.2 0.4 0.5 0.5];
-
- %未插值直接画图
- figure(1) %创建图形窗口1,并激活
- surf(x,y,z);
- shading flat %用shading flat命令,使曲面变的光滑
- title('未插值地形图')
- xlabel('横坐标')
- ylabel('纵坐标')
- zlabel('高度')
-
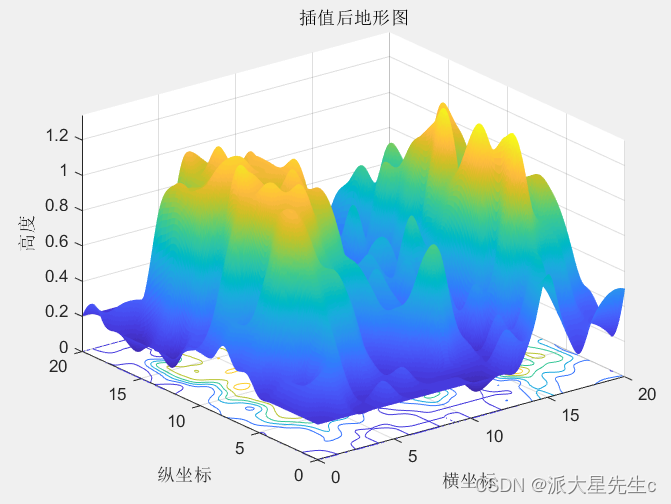
- %三次插值后画图
- %画地形图
- figure(2)
- xi=0:0.05:20;
- yi=20:-0.05:0;
- zi=interp2(x,y,z,xi',yi,'cubic'); %'cubic'三次插值
- surfc(xi,yi,zi); %底面带等高线
- shading flat
- title('插值后地形图')
- xlabel('横坐标')
- ylabel('纵坐标')
- zlabel('高度')
- %画立体等高线图
- figure(3)
- contour3(xi,yi,zi);
- title('立体等高线图')
- xlabel('横坐标')
- ylabel('纵坐标')
- zlabel('高度')
- %画等高线图
- figure(4)
- [c,h]=contour(xi,yi,zi);
- clabel(c,h); %用于为2维等高线添加标签
- colormap cool %冷色调
- title('平面等高线图')
- xlabel('横坐标')
- ylabel('纵坐标')
②拟合
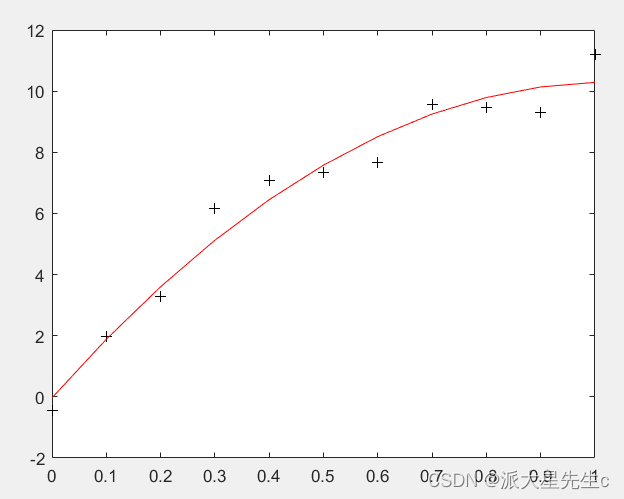
对于一维曲线的拟合,一般用到的函数p=polyfit(x,y,n)和yi=polyval(p,xi),这个是最常用的最小二乘法的拟合方法。
对于二维曲面的拟合,有很多方法可以实现,这里运用Spline Toolbox里面的函数功能。
- x = 0:0.1:1;
- y = [-0.447 1.978 3.28 6.16 7.08 7.34 7.66 9.56 9.48 9.30 11.2];
- A = polyfit(x,y,2) %A为拟合出来的函数
- z = polyval(A,x); %求多项式在x处的值z
- plot(x,y,'k+',x,z,'r')
③邻近替换
前/后一个非缺失值将其替换
最近的非缺失值替换
相邻的非离群值线性插值填充
- test_data1=fillmissing(test_data,'previous');
- test_data1=fillmissing(test_data,'next');
- test_data1=fillmissing(test_data,'nearest');
- test_data1=fillmissing(test_data,'linear');
④KNN算法填充
- from sklearn.metrics import nan_euclidean_distances
- import numpy as np
- from sklearn.impute import KNNImputer
-
- X = [[1, 2, np.nan], [3, 4, 3], [np.nan, 6, 5], [8, 8, 7]]
-
- # python的nan_euclidean_distances函数可计算含空值的距离矩阵
- nan_euclidean_distances(X, X)
-
- # python用KNNImputer进行空值填充
- X = [[1, 2, np.nan], [3, 4, 3], [np.nan, 6, 5], [8, 8, 7]]
- imputer = KNNImputer(n_neighbors=2)
- a = imputer.fit_transform(X)
- print(a)
2、数据异常
①拉依达准则
拉依达准则是用来发现数据异常值
- x=[1, 1.1, 1.2, 1.3, 1.4, 2, 1.2, 1.3, 1.5, 0.9, 0.8, 1.1, 11];
- inlier = [];outlier = [];
- len = length(x);
- average1 = mean(x); % x中所有元素的均值
- standard1 = std(x); % x的标准差
- for i = 1:len % 遍历x向量,判断是否为偏离点,不是偏离点则存入inline
- if abs(x(i)-average1)<standard1*3
- inlier = [inlier x(i)];
- end
- end
-
-
- average2 = mean(inlier);
- standard2 = std(inlier);
- for i = 1:len % 遍历x向量,判断是否为偏离点,不是偏离点则存入outline
- if abs(x(i)-average2) >= standard2*3
- outlier = [outlier x(i)];
- end
- end
-
②替换异常值
替换方法跟缺失值的替换一致,我们可以直接将其看作缺失值进行处理,替换方法如上。
3、数据变换
①0-1标准化
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- # matplotlib inline
- # 数据标准化
- # (1)0-1标准化
- df = pd.DataFrame({"value1":np.random.rand(10)*20,
- 'value2':np.random.rand(10)*100})
- print(df.head())
- print('------')
- # 创建数据
-
- def data_norm(df,*cols):
- df_n = df.copy()
- for col in cols:
- ma = df_n[col].max()
- mi = df_n[col].min()
- df_n[col + '_n'] = (df_n[col] - mi) / (ma - mi)
- return(df_n)
- # 创建函数,标准化数据
- df_n = data_norm(df, 'value1', 'value2')
- print(df_n.head())#标准化数据
②z-score标准化
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
-
- df = pd.DataFrame({"value1": np.random.rand(10) * 100,
- 'value2': np.random.rand(10) * 100})
- print(df.head())
- print('------')
-
-
- # 创建数据
-
- def data_Znorm(df, *cols):
- df_n = df.copy()
- for col in cols:
- u = df_n[col].mean()
- std = df_n[col].std()
- df_n[col + '_Zn'] = (df_n[col] - u) / std # 平均值/标准差
- return (df_n)
-
-
- # 创建函数,标准化数据
-
- df_z = data_Znorm(df, 'value1', 'value2')
- u_z = df_z['value1_Zn'].mean()
- std_z = df_z['value1_Zn'].std()
- print(df_z)
- print('标准化后value1的均值为:%.2f, 标准差为:%.2f' % (u_z, std_z))
- # 标准化数据
- # 经过处理的数据符合标准正态分布,即均值为0,标准差为1
-
- # 什么情况用Z-score标准化:
- # 在分类、聚类算法中,需要使用距离来度量相似性的时候,Z-score表现更好
③标准化的应用
- # 八类产品的两个指标value1,value2,其中value1权重为0.6,value2权重为0.4
- # 通过0-1标准化,判断哪个产品综合指标状况最好
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
-
- df = pd.DataFrame({"value1": np.random.rand(10) * 30,
- 'value2': np.random.rand(10) * 100},
- index=list('ABCDEFGHIJ'))
-
-
- # print(df.head())
- # print('------')
- # 创建数据"
- def data_norm(df, *cols):
- df_n = df.copy()
- for col in cols:
- ma = df_n[col].max()
- mi = df_n[col].min()
- df_n[col + '_n'] = (df_n[col] - mi) / (ma - mi)
- return df_n
-
-
- df_n1 = data_norm(df, 'value1', 'value2')
- # 进行标准化处理
-
- df_n1['f'] = df_n1['value1_n'] * 0.6 + df_n1['value2_n'] * 0.4
- df_n1.sort_values(by='f', inplace=True, ascending=False)
- df_n1['f'].plot(kind='line', style='--.k', alpha=0.8, grid=True)
- print(df_n1)
- # 查看综合指标状况
4、数据离散化
①等宽法
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
-
- # 等宽法 → cut方法
- ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
- # 有一组人员年龄数据,希望将这些数据划分为“18到25”,“26到35”,“36到60”,“60以上”几个面元,分成4个区间。
-
- bins = [18, 25, 35, 60, 100]
- cats = pd.cut(ages, bins)
- print(cats)
- print(type(cats))
- print('____')
-
- print(cats.codes, type(cats.codes)) # 0-3对应分组后的四个区间,用代号来注释数据对应区间,结果为ndarray;可以查看里边的等级
- print(cats.categories, type(cats.categories)) # 四个区间,结果为index
- print(pd.value_counts(cats)) # 按照区间计数
- print('-------')
- # cut结果含有一个表示不同分类名称的层级数组以及一个年龄数据进行标号的代号属性
-
- print(pd.cut(ages, [18, 26, 36, 61, 100], right=False))
- print('-------')
- # 通过right函数修改闭端,默认为True
-
- group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
- print(pd.cut(ages, bins, labels=group_names))
- print('-------')
- # 可以设置自己的区间名称,用labels参数
-
-
- df = pd.DataFrame({'ages': ages})
- group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
- s = pd.cut(df['ages'], bins) # 也可以 pd.cut(df['ages'],5),将数据等分为5份
- df['label'] = s
- cut_counts = s.value_counts(sort=False)
- print(df)
- print(cut_counts)
- # 对一个Dataframe数据进行离散化,并计算各个区间的数据计数
-
- plt.scatter(df.index, df['ages'], cmap='Reds', c=cats.codes)
- plt.grid()
- # 用散点图表示,其中颜色按照codes分类
- # 注意codes是来自于Categorical对象
②等频法
- # 等频法 → qcut方法
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- data = np.random.randn(1000)
- s = pd.Series(data)
- cats = pd.qcut(s,4) # 按四分位数进行切割,可以试试 pd.qcut(data,10)
- print(cats.head())
- print(pd.value_counts(cats))
- print('------')
- # qcut → 根据样本分位数对数据进行面元划分,得到大小基本相等的面元,但并不能保证每个面元含有相同数据个数
- # 也可以设置自定义的分位数(0到1之间的数值,包含端点) → pd.qcut(data1,[0,0.1,0.5,0.9,1])
-
- plt.scatter(s.index,s,cmap = 'Greens',c = pd.qcut(data,4).codes)
- plt.xlim([0,1000])
- plt.grid()
- # 用散点图表示,其中颜色按照codes分类
- # 注意codes是来自于Categorical对象
三、数据降维
1、主成分分析
①主成分分析简介
主成分分析是一种降维算法,它能将多个指标转换为少数几个主成分,这些主成分是原始变量的线性组合,且彼此之间互不相关,其能反映出原始数据的大部分信息。一般来说,当研究的问题涉及到多变量且变量之间存在很强的相关性时,我们可考虑使用主成分分析的方法来对数据进行简化。
②主成分分析计算步骤
标准化处理
计算标准化样本的协方差矩阵
计算R的特征值和特征向量
计算主成分贡献率以及累计贡献率
写出主成分
根据系数分析主成分代表的意义
③案例分析
主成分分析指标解释案例
主成分分析的一大难点是指标意义模糊,难以解释,下面这个例子可以辅助理解。


上表的累计贡献率 = 当前项贡献率 + 之前的累计贡献率。当累计贡献率 > 80%时,剩下的特征向量可以舍弃。

上面的分析需要一定的语言组织能力,也需要一定运气成分,若难以解释,或者强行解释,或者换方法。
案例参考文章:原文链接:https://blog.csdn.net/qq1198768105/article/details/119898545


- clear;clc
- % load data1.mat % 主成分聚类
- load data2.mat % 主成分回归
-
- [n,p] = size(x); % n是样本个数,p是指标个数
-
- %% 第一步:对数据x标准化为X
- X=zscore(x); % matlab内置的标准化函数(x-mean(x))/std(x)
-
- %% 第二步:计算样本协方差矩阵
- R = cov(X);
-
- %% 注意:以上两步可合并为下面一步:直接计算样本相关系数矩阵
- R = corrcoef(x);
- disp('样本相关系数矩阵为:')
- disp(R)
-
- %% 第三步:计算R的特征值和特征向量
- % 注意:R是半正定矩阵,所以其特征值不为负数
- % R同时是对称矩阵,Matlab计算对称矩阵时,会将特征值按照从小到大排列哦
- % eig函数的详解见第一讲层次分析法的视频
- [V,D] = eig(R); % V 特征向量矩阵 D 特征值构成的对角矩阵
-
-
- %% 第四步:计算主成分贡献率和累计贡献率
- lambda = diag(D); % diag函数用于得到一个矩阵的主对角线元素值(返回的是列向量)
- lambda = lambda(end:-1:1); % 因为lambda向量是从小大到排序的,我们将其调个头
- contribution_rate = lambda / sum(lambda); % 计算贡献率
- cum_contribution_rate = cumsum(lambda)/ sum(lambda); % 计算累计贡献率 cumsum是求累加值的函数
- disp('特征值为:')
- disp(lambda') % 转置为行向量,方便展示
- disp('贡献率为:')
- disp(contribution_rate')
- disp('累计贡献率为:')
- disp(cum_contribution_rate')
- disp('与特征值对应的特征向量矩阵为:')
- % 注意:这里的特征向量要和特征值一一对应,之前特征值相当于颠倒过来了,因此特征向量的各列需要颠倒过来
- % rot90函数可以使一个矩阵逆时针旋转90度,然后再转置,就可以实现将矩阵的列颠倒的效果
- V=rot90(V)';
- disp(V)
- %% 计算我们所需要的主成分的值
- m =input('请输入需要保存的主成分的个数: ');
- F = zeros(n,m); %初始化保存主成分的矩阵(每一列是一个主成分)
- for i = 1:m
- ai = V(:,i)'; % 将第i个特征向量取出,并转置为行向量
- Ai = repmat(ai,n,1); % 将这个行向量重复n次,构成一个n*p的矩阵
- F(:, i) = sum(Ai .* X, 2); % 注意,对标准化的数据求了权重后要计算每一行的和
- end
2、因子分析(FA)
①应用场景
减少分析变量个数
通过对变量间相关关系的探测,将原始变量分组,即将相关性高的变量分为一组,用共性因子来代替该变量
使问题背后的业务因素的意义更加清晰呈现
②步骤
1、选择分析的变量
2、计算所选原始变量的相关系数矩阵
3、提取公共因子
4、因子旋转
5、计算因子得分
③模型分析
以废气排放为例说明主成分降维处理过程
1、评价标准体系的构建
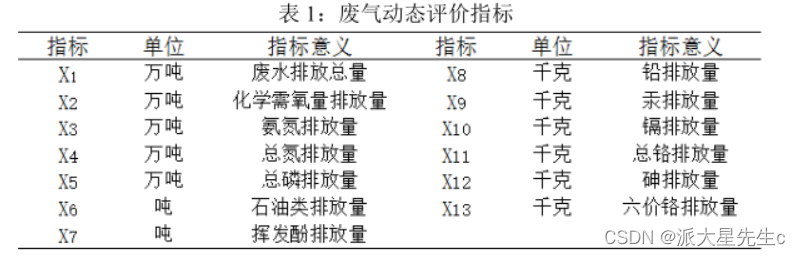
2、因子分析
因子分析首先将原始数据标准化处理,建立相关系数矩 阵并计算其特征值和特征向量,接着从中选择特征值大于等 于1的特征值个数为公共因子数,或者根据因子对X的累计贡献 率大于80%来确定公共因子,求得因子载荷矩阵, 后计算公因子得分和综合得分。
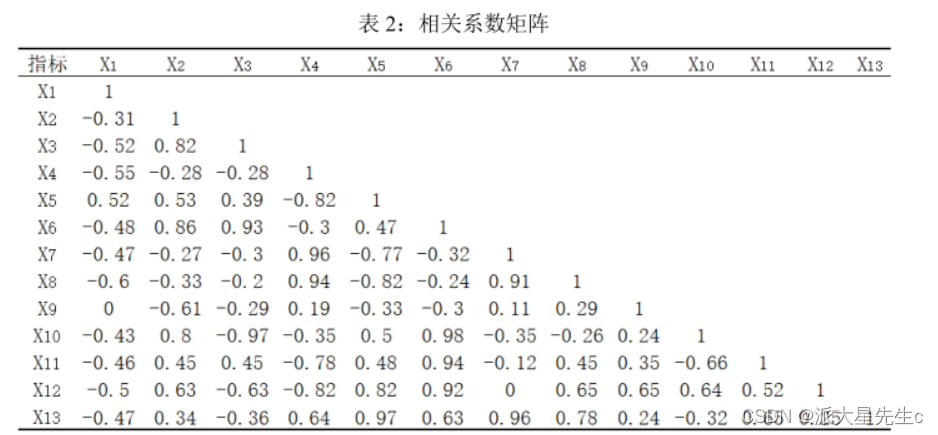
观察相关系数矩阵表 2,可以发现所选取指标之间存在着一定的相关关系,其中 X3 和 X6、X4 和
X7、 X7 和 X8 分别存在着较强的相关性,相关系数分别为 0.96、 0.96、0.91,这进一步验证了对所选指标做因子分析的科学性和必要性。计算相关系数矩阵的特征值、贡献率及累计贡献率如
所示:
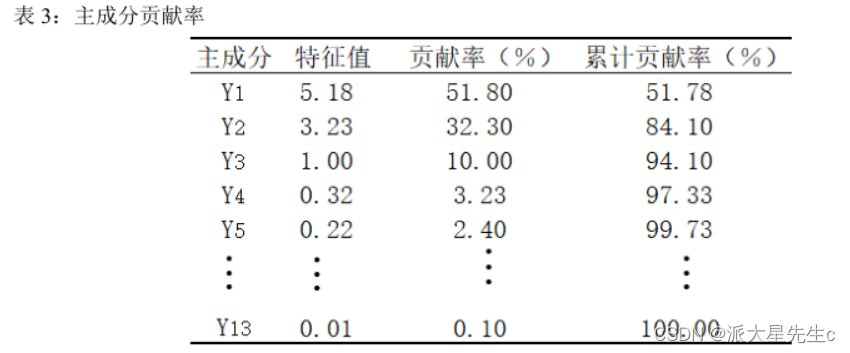
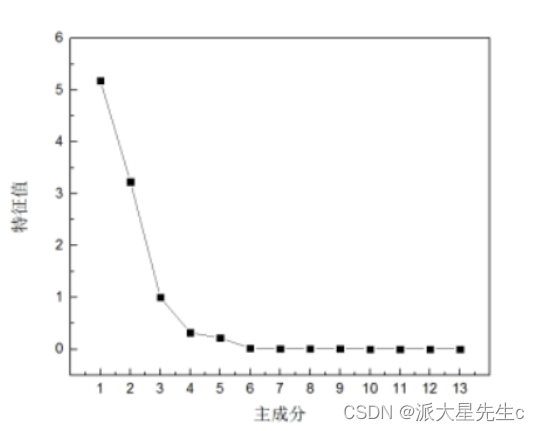
确定提取的主成分个数可综合考虑 3 个方面:
(1)提取的所有特征值大于某一特定特征值,一般特定值设为 1,本文同样以 1 为标准;
(2) 提取的主成分的累计贡献率要大于 85%,即所提取的主成分要能够概括原有指标的绝大部分信息; 由表 3 可知,前 3 个主成分的累计贡献率已经达到了94.01%,满足按照累计贡献率大于 85% 确定主成分个数的原则;
(3) 以做主成分分析时生成的碎石图 (Scree Plot) 做参考,碎石图是按照特征值大小排列的,以特征值为纵坐标、因子数为横坐标生成的主成分散点图,有明显的拐点,一般取拐点前所有的因子及拐点后第一个因子作为主成分 。
观察图 4 可得,第一、第二个主成分的特征值较大,其余几个均较小,碎石图在第三个特征值出现
拐点。
根据上述分析,在本研究中选取前 3 个主成分对河南省水资源使用情况进行动态分析,从表 3
和 4,我们可以看出前 3 个主成分已经能够概括绝大部分的原始信息,因此提取 3 个主成分因子是
合理的. 提取 3 个主成分用于概括原有 10 个指标的绝大部分信息,这既达到了降维、简化的目的,又在一定程度上保证了后续研究结果能准确有效地反映出河南省水资源使用情况动态变化的基本特征。计算主成分的载荷矩阵, 主成分载荷是指提取的 3 大主成分与各变量指标之间的相关系数如表4:

④代码实现
- clc,clear
- r=[1.000 0.577 0.509 0.387 0.462
- 0.577 1.000 0.599 0.389 0.322
- 0.509 0.599 1.000 0.436 0.426
- 0.387 0.389 0.436 1.000 0.523
- 0.462 0.322 0.426 0.523 1.000];
- %下面利用相关系数矩阵求主成分解,val的列为r的特征向量,即主成分的系数
- [vec,val,con]=pcacov(r);%val为r的特征值,con为各个主成分的贡献率
- f1=repmat(sign(sum(vec)),size(vec,1),1); %构造与vec同维数的元素为±1的矩阵
- vec=vec.*f1; %修改特征向量的正负号,每个特征向量乘以所有分量和的符号函数值
- f2=repmat(sqrt(val)',size(vec,1),1);
- a=vec.*f2 %构造全部因子的载荷矩阵
- a1=a(:,1) %提出一个因子的载荷矩阵
- tcha1=diag(r-a1*a1') %计算一个因子的特殊方差
- a2=a(:,[1,2]) %提出两个因子的载荷矩阵
- tcha2=diag(r-a2*a2') %计算两个因子的特殊方差
- ccha2=r-a2*a2'-diag(tcha2) %求两个因子时的残差矩阵
- gong=cumsum(con) %求累积贡献率
-
-
-
- clc,clear
- load data.txt; %把原始数据保存在纯文本文件data.txt中
- n=size(data,1);
- x=data(:,1:4); y=data(:,5); %分别提出自变量x和因变量y的值
- ——————————————————————————————————
- 如果不需要检验,则不需要把y列入原始数据中,把矩阵x的大小改变一下,以及下文中的m,m为原始数据中变量的个数。
- ——————————————————————————————————
- m=4;%m为变量的个数
- x=zscore(x); %数据标准化
- r=cov(x); %求标准化数据的协方差阵,即求相关系数矩阵
- [vec,val,con]=pcacov(r); %进行主成分分析的相关计算
- c=cumsum(con);
- i=1;
- while ((c(i)<90)&(con(i+1)>10))
- i=i+1;
- end
- num=i;
- f1=repmat(sign(sum(vec)),size(vec,1),1);
- vec=vec.*f1; %特征向量正负号转换
- f2=repmat(sqrt(val)',size(vec,1),1);
- a=vec.*f2; %求初等载荷矩阵
- am=a(:,1:num); %提出num个主因子的载荷矩阵
- [b,t]=rotatefactors(am,'method', 'varimax'); %旋转变换,b为旋转后的载荷阵
- bt=[b,a(:,num+1:end)]; %旋转后全部因子的载荷矩阵
- contr=sum(bt.^2); %计算因子贡献
- rate=contr(1:num)/sum(contr); %计算因子贡献率
- fprintf('综合因子得分公式:F=');
- for i=1:num
- fprintf('+%f*F%d',rate(i),i);
- end
- fprintf('\n');
- coef=inv(r)*b; %计算得分函数的系数
- coef=coef';
- for i=1:num
- fprintf('各个因子得分函数为F%d=',i);
- for j=1:m
- fprintf('+(%f)*x_%d',coef(i,j),j);
- end
- fprintf('\n');
- end
- %如果仅仅因子分析,程序到此为止
- %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
- score=x*coef';%计算各个因子的得分
- weight=rate/sum(rate); %计算得分的权重
- Tscore=score*weight'; %对各因子的得分进行加权求和,即求各企业综合得分
- [STscore,ind]=sort(Tscore,'descend'); %对企业进行排序
- display=[score(ind,:)';STscore';ind']; %显示排序结果
- fprintf('排序结果如下:');
- for i=1:num
- fprintf('第%d行为F%d得分,',i,i);
- end
- fprintf('第%d行为综合因子得分,第%d为原序列\n',num+1,num+2);
- disp(display);
- [ccoef,p]=corrcoef([Tscore,y]); %计算F与资产负债的相关系数
- [d,dt,e,et,stats]=regress(Tscore,[ones(n,1),y]);%计算F与资产负债的方程
- fprintf('因子分析法的回归方程为:F=%f+(%f*y)',d(1),d(2));
- if (stats(3)<0.05)%判断是否通过显著性检验的结果
- fprintf('\n在显著性水平0.05的情况下,通过了假设检验。\n');
- else
- fprintf('\n在显著性水平0.05的情况下,通不过假设检验。\n');
- end该MATLAB源代码的displsy为最终排序结果。

