
- 1软件测试个人求职简历该怎么写,模板在这里_软件测试简历怎么写
- 2蚂蚁金服面试及笔试(附自己的答案)_蚂蚁金服 线上笔试
- 3让你能进“大厂”的数据分析项目是长怎样?全套路线(建议收藏)_数据分析师如何进大厂
- 4深度学习 --- nlp\cv_深度学习cv nlp
- 5【Linux】shell脚本中为read加默认值_shell read 默认值
- 6Hudi源码|Insert源码分析总结(一)(整体流程)_hudi源码分析
- 7【性能 】浅谈性能优化办法_内存、cpu优化有哪些方法
- 8淘宝扭蛋机小程序搭建:轻松打造创新购物体验
- 9大数据框架对比:Hadoop、Storm、Samza、Spark和Flink_以下哪一个大数据处理框架更适合处理非实时的海量数据
- 10error: RPC failed; curl 56 GnuTLS recv error (-110): The TLS connection was non-properly terminated.
多任务之任务损失/梯度优化策略合集!
赞
踩
本文分享如何从loss和gradient方面,优化多任务模型,缓解负迁移或跷跷板的问题。不足之处,还望批评指正。
背景
最近工作中,有使用到多任务模型,但实际使用时,会面临负迁移、跷跷板等现象。
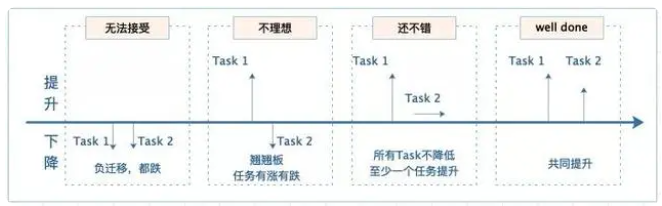
除了从模型角度优化,这里介绍从loss和gradient方面的优化策略。阿里云云栖号的一篇文章[1]总结的很好,多目标优化策略主要关注三个问题:
1. Magnitude(Loss量级):Loss值有大有小,出现取值大的Loss主导的现象,怎么办?
2. Velocity (Loss学习速度):任务有难有易,Loss学习速度有快有慢,怎么办?
3. Direction(Loss梯度冲突):多个Loss的反向梯度,更新方向冲突,出现翘翘板、负迁移现象,怎么办?
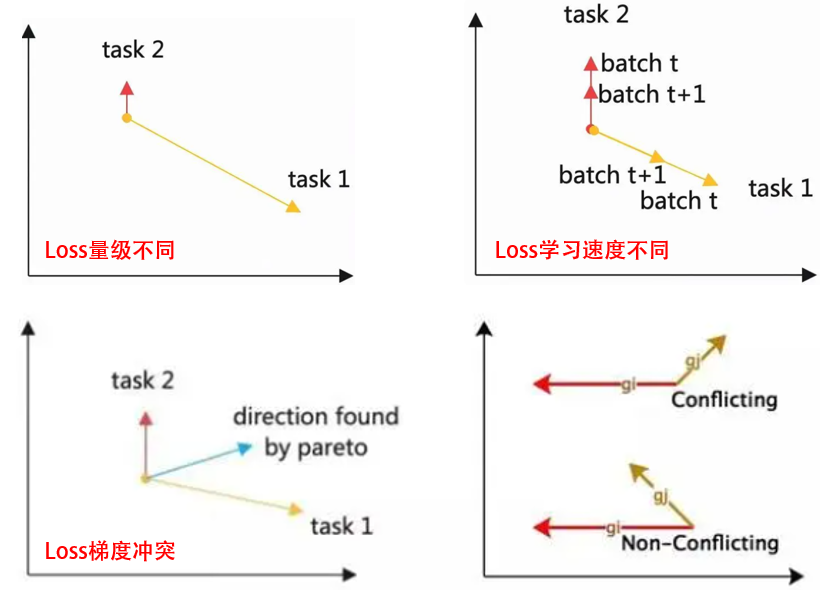
为了解决以上问题,本文分享以下8种方法:

1. Uncertainty Weighting
论文:Kendall, A., Gal, Y., & Cipolla, R. (2018). Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE conference on computer vision and pattern recognition
引用量:2047
损失函数中加入可学习的噪声参数σ,代表任务的不确定性,通过定义概率模型并最大化高斯似然估计,学习任务参数。
- 对于单个回归问题, ;
- 对于单个分类问题, ;
- 对于多任务, ;
- 以回归+分类问题为例, 。
其中, 表示网络输出, 为回归损失, 为分类损失cross entropy。
由于log惩罚项的存在,总损失可能出现负值的情况,将惩罚项改为 可以避免此情况发生。不确定性越大的任务,即噪声参数越大,得到的任务的损失权重越小,惩罚项可以防止噪声参数过大。
- def UW_Loss(labels, preds,
- log_vars,
- device="gpu:1"):
- """Uncertainty Weighting
- Kendall, A., Gal, Y., & Cipolla, R. (2018). Multi-task learning using uncertainty to weigh losses
- for scene geometry and semantics. In Proceedings of the IEEE conference on computer vision and
- pattern recognition(pp. 7482-7491).
- """
- assert len(preds) == labels.shape[1]-1
- assert len(loss_weights) == labels.shape[1]-1
- labels = labels.to(device)
-
- # 计算各环节的ce
- # ['click','cart', 'order']
- loss1 = nn.functional.binary_cross_entropy(preds[0], labels[:,0])
- loss2 = nn.functional.binary_cross_entropy(preds[1], labels[:,1])
- loss3 = nn.functional.binary_cross_entropy(preds[2], labels[:,2])
- losses = [loss1, loss2, loss3]
-
-
- for i, log_var in enumerate(log_vars):
- log_var = log_var.to(device)
- losses[i] = (1/2) * (torch.exp(-log_var[0])**2) * losses[i] + torch.log(torch.exp(log_var[0])+1)
-
- loss = sum(losses)
- return loss, losses

2. MGDA
论文:Sener, O., & Koltun, V. (2018). Multi-task learning as multi-objective optimization. *Advances in neural information processing systems*, *31*.
引用量:638
代码:https://github.com/isl-org/MultiObjectiveOptimization
据[2]解释,作者将MTL看作一个带约束优化问题,求解过程相当于寻找帕累托最优过程。假定固有有一群任务和可分配的任务损失权重,从一种分配状态到另一种状态的变化中,在没有使任何任务境况变坏的前提下,使得至少一个任务变得更好,这就达到了帕累托最优化。
MTL的优化目标函数:
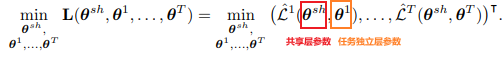
文中,作者总结一个方法:多重梯度下降算法 (multiple gradient descent algorithm, MGDA),该算法针对共享参数和任务独立参数,声明KKT (Karush-Kuhn-Tucker) 条件:
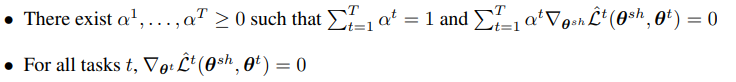
第二个条件,是让每个任务独立的参数梯度为0,直接对每个任务独立分支的部分上,各自做梯度下降即可。而第一个条件是要找到一个帕累托最优点 (即最好的alpha组合),使得共享层参数梯度为0。这边作者使用了Frank-Wolfe算法。

虽然Frank-Wolfe求解器有效率和质量,但我们需要对每个任务t计算其在共享层的参数梯度,用于反向传播,因此要T次反向传播后,才能前向传播1次。考虑到后向传播比前向传播耗时,本文提出一个更有效的办法,只需要1次反向传播。先把任务t的预测函数做个变换:从x为自变量,delta_sh和delta_t为参数,变换到以下,以表征函数作为自变量,delta_t为参数。而表征函数内部又是由x为自变量,delta_sh为参数。
如果将表征函数g下样本xi的表征,表达为zi,则我们可以得到共享层部分的帕累托最优的上界:
其中, ,对于所有任务来说,只需要1次反向传播。而 与alpha无关,可直接移除。最终目标函数变为:MGDA-UB (Multiple Gradient Descent Algorithm – Upper Bound)。 简单来说就是共享层的表征向量取代了原来的x。
源码上看,先看:MGDA先对共享层和任务独立层,获取梯度和反向传播。
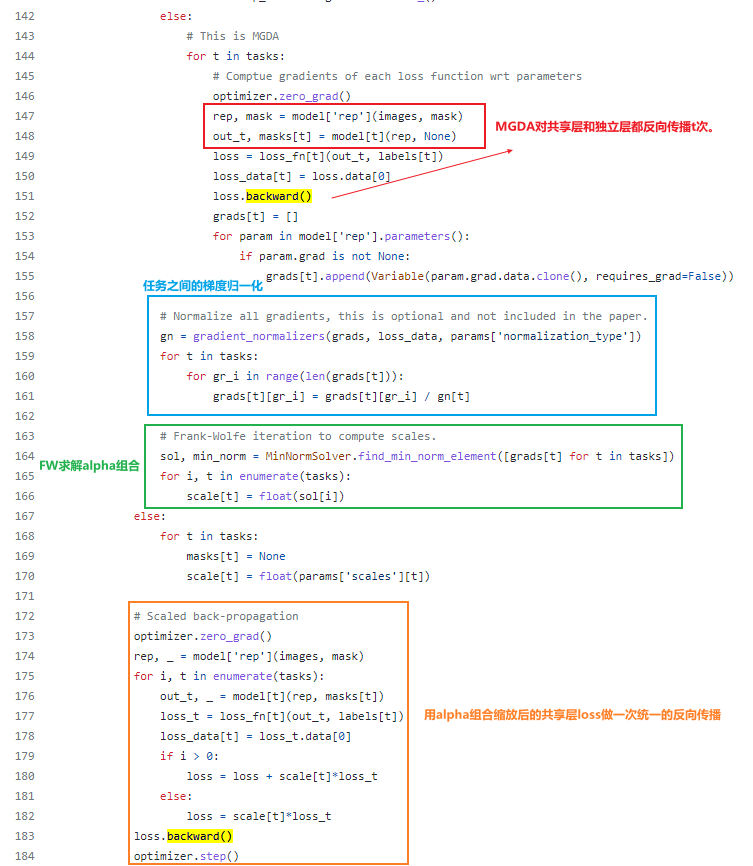
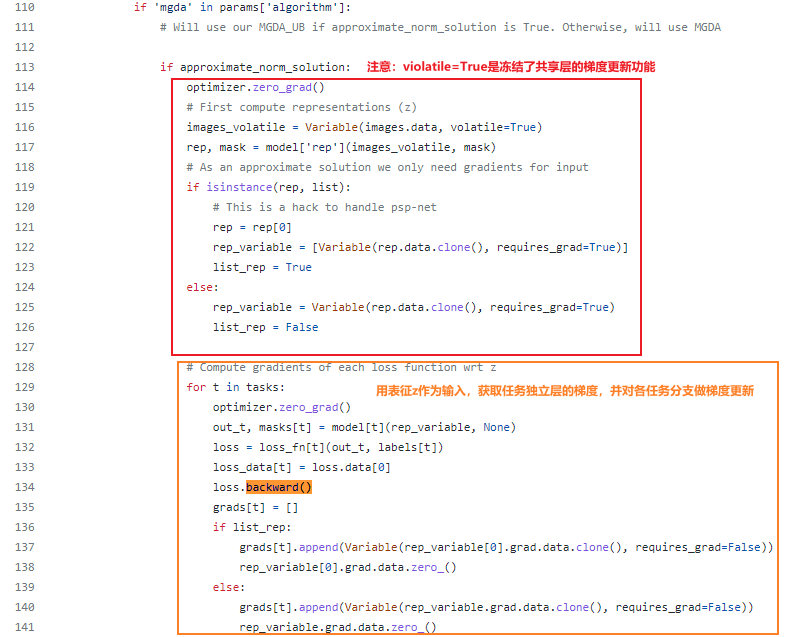
而MGDA-UB是冻结共享层的反向传播,先通过共享层获取表征向量,再对任务独立层算梯度和反向传播,最后基于任务独立层的梯度,算出alpha后,计算共享层的损失,进而反向传播。
3. GradNorm
论文:Chen, Z., Badrinarayanan, V., Lee, C. Y., & Rabinovich, A. (2018, July). Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks. In *International conference on machine learning* (pp. 794-803). PMLR.
引用量:670
代码:https://github.com/hav4ik/Hydra/blob/master/src/applications/trainers/gradnorm.py
该文章[3]写的很详细,建议直接阅读它。GradNorm是基于不同任务的学习速度调整任务权重,学习速度越快,权重越小。
每个任务的学习速度反值r为: 计算任务i,在t轮下相较第1轮损失的差异,若第t轮损失变得很小,则 越小,代表该任务在历史训练的很快,而 为相对其他任务的训练速度反值,即r越小,该任务相比于其他任务来说,在历史训练中学习得更快。
得到学习速率后,便可以更新任务权重:

其中alpha为调整力度,它越大,调整力度越大。GradNorm整个训练流程为:

其中,小w为任务损失权重,而大写W为模型内部参数(W来自于共享层最后一层的参数)。若L(0)受网络参数的初始化剧烈影响,可适用理论初始值log(C),C为类别数量。另外,为了避免任务损失权重变为0,在L_grad求偏导时,将目标梯度 看作固定常数项。同时,为了将梯度归一化从全局学习率中解耦出来,每次梯度更新后,会对权重w重新归一化,以保证 。
4. DWA
论文:Liu, S., Johns, E., & Davison, A. J. (2019). End-to-end multi-task learning with attention. In *Proceedings of the IEEE/CVF conference on computer vision and pattern recognition* (pp. 1871-1880).
引用量:571
DWA全称是Dynamic Weight Average,受到GradNorm的启发,它也通过考虑每个任务的损失改变,去学习平均不同训练轮数下各任务的权重。GradNorm需要接触网络内部梯度,而DWA提出只要任务的损失数值,所以实施起来更简单。作者把任务k的权重lambda_k定义如下:
w_k计算损失相对衰减率,越小,说明学习速度越快。我们要减少其重要度,为此,喂入softmax获取各任务的权重,这样w_k越小,权重越小,即近期训练过程中学习速度快的任务,要给低的重要度。T越大,权重越趋近于1,因此任务权重更平均,所以T调大,有利于让各任务的权重更均匀。乘上K是为了确保各任务的权重之和为K,保证权重在同一量纲下缩放。DWA的缺点是容易受损失量级大的任务主导[3]。另外,前2轮w_k初始化为1。
- # dynamic weight averaging
- loss_weights = np.ones((model_params['total_epoch'], len(labels)))
- avg_task_loss = np.zeros((model_params['total_epoch'], len(labels)))
-
-
- for epoch in range(model_params['total_epoch']):
- # 前2轮w_k初始化为1
- if epoch == 0 or epoch == 1:
- pass
- # 算权重
- else:
- sum_w = []
- for i in range(len(labels)):
- w = avg_task_loss[epoch - 1, i] / avg_task_loss[epoch - 2, i]
- sum_w.append(np.exp(w / T))
- loss_weights[epoch] = [len(labels) * w / np.sum(sum_w) for w in sum_w]
-
-
- model.train()
- for step, batch in enumerate(train_loader):
- # model training code
-
-
- # save loss in each epoch 每epoch结束追加loss
- avg_task_loss[epoch] = [task_loss / len(train_loader) for task_loss in epoch_trn_multi_loss]
5. PE-LTR
论文:Lin, X., Chen, H., Pei, C., Sun, F., Xiao, X., Sun, H., ... & Jiang, P. (2019, September). A pareto-efficient algorithm for multiple objective optimization in e-commerce recommendation. In *Proceedings of the 13th ACM Conference on recommender systems* (pp. 20-28).
引用量:64
代码:https://github.com/weberrr/PE-LTR/blob/master/PE-LTR.py](https://github.com/weberrr/PE-LTR/blob/master/PE-LTR.py
本文是在阿里电商LTR (Learing to Rank) 场景下,提出用帕累托最优算法找到各任务适合的权重,跟前面提到的Multi-Objective Optimization的思路有些相似。直接看训练过程:

- 绿色部分:定义输入。初始化各任务权重为1/K,各任务目标的值约束边界。
- 橙色部分:定义输出。首轮先用初始权重加权求和多任务损失。
- 红色部分:批次更新。随机梯度下降更新模型参数,用PECsolver求解各任务的权重,加权求和多任务损失。
先定义损失函数: 其中, 。在真实场景里,不同目标的优先级不同。为了给目标们加入边界约束,即: ,c_i是在0-1的常数项,并且 。
除非是单目标,否则没法保证该问题的解决方法是帕累托有效,除非分配最适合的权重。所以作者,考虑KKT条件,获取到多目标的帕累托有效解决方案:
把上述公式再转换,得到:
为了求解该问题,作者提出了PECsolver:

简单来说,利用KKT条件来进行求解,放松条件求解w,然后考虑原约束调节进一步收紧解集。[4],涉及数学细节,感兴趣可阅读原文。
- def pareto_step(w, c, G):
- """
- ref:http://ofey.me/papers/Pareto.pdf
- K : the number of task
- M : the dim of NN's params
- :param W: # (K,1)
- :param C: # (K,1)
- :param G: # (K,M)
- :return:
- """
- GGT = np.matmul(G, np.transpose(G)) # (K, K)
- e = np.mat(np.ones(np.shape(w))) # (K, 1)
- m_up = np.hstack((GGT, e)) # (K, K+1)
- m_down = np.hstack((np.transpose(e), np.mat(np.zeros((1, 1))))) # (1, K+1)
- M = np.vstack((m_up, m_down)) # (K+1, K+1)
- z = np.vstack((-np.matmul(GGT, c), 1 - np.sum(c))) # (K+1, 1)
- hat_w = np.matmul(np.matmul(np.linalg.inv(np.matmul(np.transpose(M), M)), M), z) # (K+1, 1)
- hat_w = hat_w[:-1] # (K, 1)
- hat_w = np.reshape(np.array(hat_w), (hat_w.shape[0],)) # (K,)
- c = np.reshape(np.array(c), (c.shape[0],)) # (K,)
- new_w = ASM(hat_w, c)
- return new_w
-
-
- def ASM(hat_w, c):
- """
- ref:
- http://ofey.me/papers/Pareto.pdf,
- https://stackoverflow.com/questions/33385898/how-to-include-constraint-to-scipy-nnls-function-solution-so-that-it-sums-to-1
- :param hat_w: # (K,)
- :param c: # (K,)
- :return:
- """
- A = np.array([[0 if i != j else 1 for i in range(len(c))] for j in range(len(c))])
- b = hat_w
- x0, _ = nnls(A, b)
-
-
- def _fn(x, A, b):
- return np.linalg.norm(A.dot(x) - b)
-
-
- cons = {'type': 'eq', 'fun': lambda x: np.sum(x) + np.sum(c) - 1}
- bounds = [[0., None] for _ in range(len(hat_w))]
- min_out = minimize(_fn, x0, args=(A, b), method='SLSQP', bounds=bounds, constraints=cons)
- new_w = min_out.x + c
- return new_w
-
-
- loss_weights = np.full(len(labels)-1, 1/(len(labels)-1)) # (K,)
- w_constraint = np.full((len(labels)-1, 1), 0.) # (K, 1)
- for epoch in range(model_params['total_epoch']):
- model.train()
- for step, batch in enumerate(train_loader):
- con_feats = batch['features'].float().to(device)
- targets = batch['targets'].float().to(device)
-
- preds = model(con_feats) # 模型训练
- loss, task_loss, multi_losses = model.loss(targets, preds,
- loss_weights=loss_weights,
- device=device) # 计算损失
- optimizer.zero_grad() # 梯度清空
- loss.backward(retain_graph=True) # 计算梯度
-
- # G: (K, m)
- grads = []
- for l in task_loss:
- grad = []
- optimizer.zero_grad()
- l.backward(retain_graph=True)
- for param in model.parameters():
- if param.grad is not None:
- grad.append(param.grad.view(-1).cpu().detach().numpy())
- grads.append(np.hstack(grad))
- G = np.vstack(grads)
-
- loss_weights = pareto_step(len(labels)-1, w_constraint, G)
- optimizer.step() # 梯度回传
6. HTW
论文:Kongyoung, S., Macdonald, C., & Ounis, I. (2020). Multi-task learning using dynamic task weighting for conversational question answering.
引用量:5
在现有的MTL权重分配方法中,对所有任务都是一视同仁,但其实存在一些业务场景是有主次任务之分。HTW (Hybrid Task Weighting) 则是分别对主任务和辅助任务分别使用:
- 主任务:Abridged Linear Schedule。设置一个step阈值,t_tao = T/10,即前10%的训练step是用于主任务的warm-up (任务权重=当前step数t/总step数T),后90%的steps,主任务的权重为1。这里warm-up的目的应该是让模型训练初期能从辅助任务中学习到一些有利于主任务的信息,然后后期再专心学习主任务。这里step=epoch总数*train_loader的循环step数;
- 辅助任务:Loss-Balanced Task Weighting (LBTW)。对于每个batch,任务的权重lambda是step=t下的loss除以首轮下的loss,即某任务学习速度越快,它的权重越趋向于0。另外,引入alpha=0.5用于平衡任务权重。
整个训练流程如下:

7. PCGrad
论文:Yu, T., Kumar, S., Gupta, A., Levine, S., Hausman, K., & Finn, C. (2020). Gradient surgery for multi-task learning. *Advances in Neural Information Processing Systems*, *33*, 5824-5836.
引用量:353
代码:https://github.com/chenllliang/Gradient-Vaccine/blob/17fa758fdd4f87475ee2847db6fc0a013631fee3/fairseq/fairseq/optim/pcgrad.py
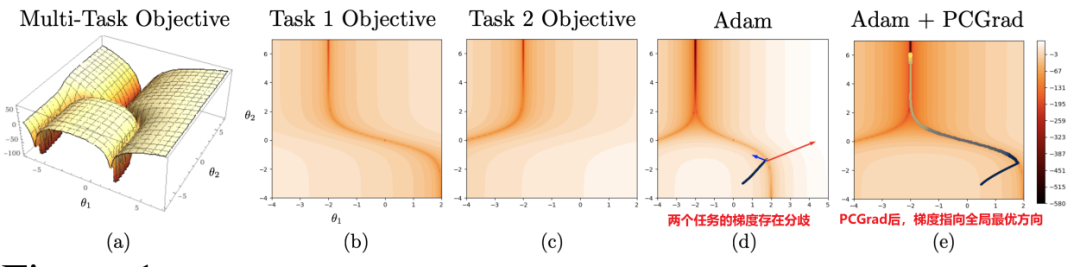
如果两个梯度在方向上存在冲突,就把任务i的梯度投影到具有冲突梯度的任何其他任务j的梯度的法向量平面上。如下图所示,若任务i和任务j的余弦相似度是正值,如图(d),不相互冲突,那任务i和j保持各自原有梯度,做更新。若如图(a),梯度方向有相互冲突,对于任务i的梯度,就把它投影在任务j梯度的法向量上,如图(b),作为任务i的新梯度去更新。对于任务j就反之,如图(c)。
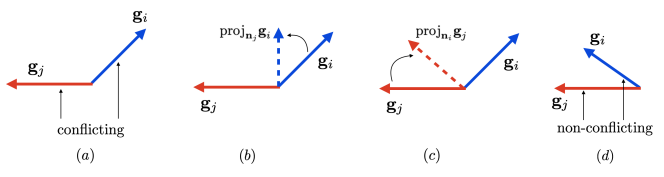
投影计算方式如下[5]:
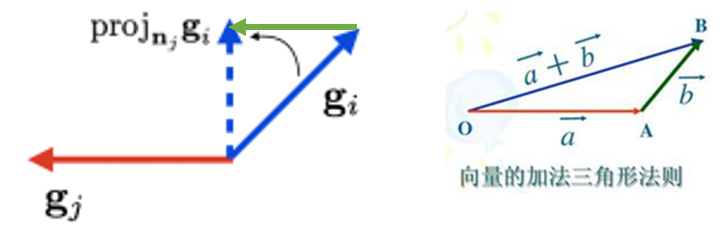
如上图所示,gi和gj有冲突,所以要把gi投影在gj的法向量平面上作为任务i的新梯度 (即蓝色虚线)。假设绿色向量为a*gj,基于向量的加法三角形法则,可以得到蓝色虚线x=gi+a*gj。之后做以下计算,便可得到a和蓝色虚线向量 (即任务i的新梯度):
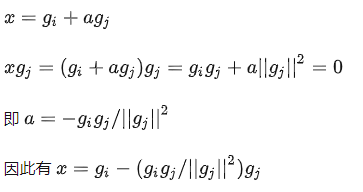
效果如下:
整体训练流程如下:

- # Compute gradient projections.
- def proj_grad(grad_task):
- """计算投影梯度"""
- for k in range(num_tasks):
- inner_product = tf.reduce_sum(grad_task*grads_task[k])
- proj_direction = inner_product / tf.reduce_sum(grads_task[k]*grads_task[k])
- grad_task = grad_task - tf.minimum(proj_direction, 0.) * grads_task[k]
- return grad_task
8. GradVac
论文:Wang, Z., Tsvetkov, Y., Firat, O., & Cao, Y. (2020). Gradient vaccine: Investigating and improving multi-task optimization in massively multilingual models. *arXiv preprint arXiv:2010.05874*.
引用量:57
代码:https://github.com/chenllliang/Gradient-Vaccine
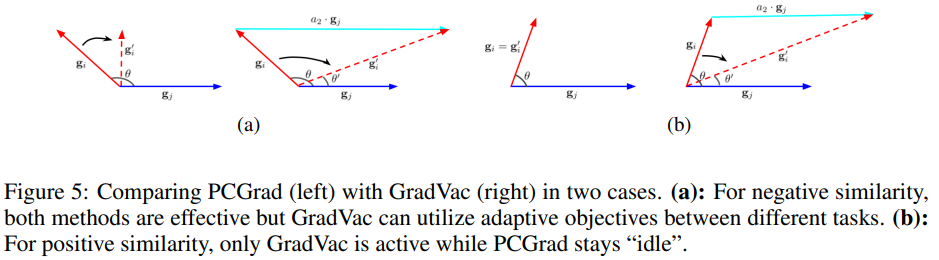
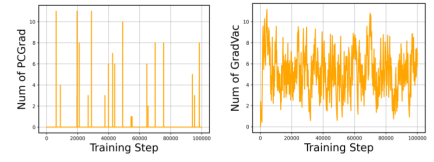
PCGrad只在梯度之间的余弦相似度为负值时生效,这导致PCGrad在训练过程中的表现是非常稀疏的,如下面的左图,而真实情况,存在不少任务梯度之间是正余弦相似度,但它们却没被PCGrad考虑,于是作者提出GradVac。
当两个任务有正梯度相似度 ,当PCGrad忽略非负的 ,但它也还可能会对相似任务之间有小的损害,例如法语和西班牙语。因此,假设我们有相似度目标为 (即两个任务之间的normal余弦相似度),我们便更换梯度g_i的幅度和方向以满足该目标。特别的是,我们更换的g_i是要满足由g_i和g_j构成的向量空间内的条件:a1*g_i+a2*g_j。因为a1和a2的线性组合有无限个,所以简化将a1固定为1,然后对g_i和g_j的平面应用正弦定律,求解a2,然后获取任务i的新梯度:
论文附录E有详细推导过程:

公式中的相似度目标 范围是[-1,1],但现在有个问题是如何设置合适的目标,作者分析发现梯度之间的互相作用随着任务、层数和训练轮数剧烈改变,为了考虑这3个因素去制定合适的相似度目标,作者为任务i和j,以及第k层网络,提出指数平滑变量(EWA):
其中, 。beta为超参。由于该方法先发制人地处理正负相似度的梯度关系,作者把该刚发称作Gradient Vaccine (GradVac)。
整个训练过程如下:

总结
总结如下:

参考资料
[1] 多任务多目标 CTR 预估技术 - 阿里云云栖号,文章: https://baijiahao.baidu.com/s?id=1713545722047735100&wfr=spider&for=pc
[2] 深度学习的多个loss如何平衡?- 陈瀚清的回答 - 知乎:https://www.zhihu.com/question/375794498/answer/2657267272
[3] 多目标样本权重-GradNorm和DWA原理详解和实现 - 知乎:https://zhuanlan.zhihu.com/p/542296680
[4] 阿里多目标优化: PE-LTR - 知乎:https://zhuanlan.zhihu.com/p/159459480
[5] 多任务学习——【ICLR 2020】PCGrad - 知乎:https://zhuanlan.zhihu.com/p/395220852
- 推荐阅读:
-
- 我的2022届互联网校招分享
-
- 我的2021总结
-
- 浅谈算法岗和开发岗的区别
-
- 互联网校招研发薪资汇总
- 2022届互联网求职现状,金9银10快变成铜9铁10!!
-
- 公众号:AI蜗牛车
-
- 保持谦逊、保持自律、保持进步
-
- 发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
- 发送【1222】获取一份不错的leetcode刷题笔记
-
- 发送【AI四大名著】获取四本经典AI电子书

