
- 1SAP_MM_采购信息记录_PA认证总结_sap采购信息记录tcode
- 2HBase RowKey 的设计原则?_描述hbase的rowkey的设计原则
- 3HBase之Rowkey设计总结及易观方舟实战篇_h(key)=k%x,x的值
- 4利用RunnerGo数据大屏强化测试管理与决策_数据大屏测试数据
- 5mybaits-plus 相关yml配置详解
- 6UML模型图之类图——以图书馆管理系统为例_图书管理系统类图
- 7mysql左链表右链表区别_MySql链表语句--博客园老牛大讲堂
- 8[Qt的学习日常]--信号和槽
- 9mysql实战11 | 怎么给字符串字段加索引?
- 10【网络安全---漏洞复现】shiro550反序列化漏洞原理与漏洞复现和利用(基于vulhub,保姆级的详细教程)
一文盘点2023人工智能进展,不止大模型而已
赞
踩
西风 发自 凹非寺
量子位 | 公众号 QbitAI
2023年大模型千帆竞发,除此外AI领域还有哪些新突破?
来来来,畅销书《Python机器学习》作者Sebastian Raschka的年末总结已经准备好了。

看完才知道:
RLHF今年虽然爆火,但实打实用到的模型并不多,现在还出现了替代方案,有望从开源界“出圈”;
大模型透明度越来越低,透明度最高的是Llama 2,但得分也仅有54;
开源模型下一步不一定是“更大”,混合专家模型(MoE)可能是个突破点。
……
除了大语言模型,Sebastian Raschka还根据CVPR 2023打包了计算机视觉进展,最后还讲到了AI当前的一些局限性、以及对2024年的技术预测。
走过路过的网友们纷纷表示总结得很到位:
△机器翻译,仅供参考
下面我们一起来看看这份年度总结里都有啥。
2023 AI爆点:大语言模型
今年,大模型领域似乎没有出现实质性的创新技术,更多是基于去年的扩展:
ChatGPT(GPT-3.5)升级到GPT-4
DALL-E 2升级到DALL-E 3
Stable Diffusion 2.0升级到Stable Diffusion XL
……
但学界业界依旧忙得热火朝天,一些新趋势、新内容总结如下——
重要AI模型论文信息量骤减
首先,是业界研究者在论文中公开的研究细节越来越少。
OpenAI此前在GPT-1、GPT-2、GPT-3、InstructGPT的论文中,还详尽披露了模型架构和训练过程;
但从GPT-4开始,OpenAI完全不提构建过程。
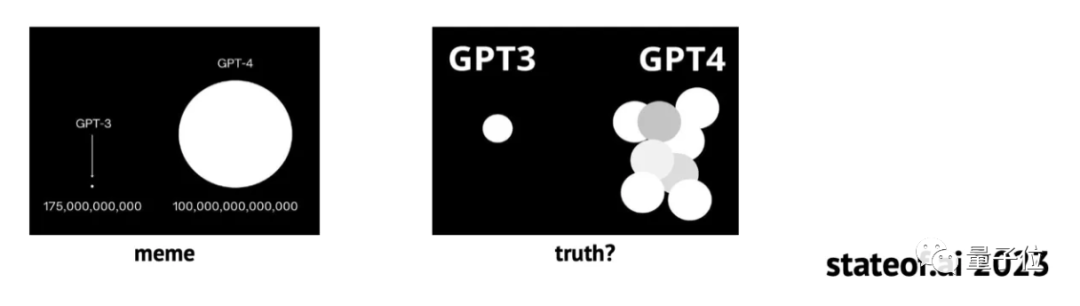
唯一不知真假的GPT-4架构信息,来源于坊间传闻:
GPT-4是由16个子模块构成的混合专家(MoE)模型,每个子模块拥有高达1110亿参数……
Meta亦是如此,在第一篇Llama论文中详细阐述了训练数据集,但Llama 2完全没提相关内容。
即便如此,Llama 2已经是一众大模型中最公开的了。斯坦福大学最近发布了一项关于大模型透明度指数的研究,Llama 2得分54,透明度排第一,GPT-4得分48,排第三。

虽然模型细节算是公司商业机密,但Sebastian Raschka认为这种趋势还是值得关注,因为它似乎会在2024持续。
大模型开卷上下文长度
今年大语言模型的另一个趋势是扩展输入的上下文长度。
此前GPT-4上下文长度还是32k时,竞品Claude 2就将上下文推进到100k tokens,且支持PDF文件输入。
随后GPT-4大更新,新版本GPT-4 Turbo刷新上下文长度纪录,已支持128k tokens。
一些编程工具,如GitHub Copilot,也在不断增加上下文窗口长度。
开源大模型比拼“小而美”
用更小的模型比肩大模型的性能,是开源圈的“新玩法”。
目前,多数现有开源大模型仍然是纯文本模型。
这些模型研究重点之一,是用小于100B参数的“小模型”对标GPT-4的文本处理能力。
甚至出现了很多可以单GPU运行的小模型,例如1.3B的phi1.5、7B的Mistral、7B的Zephyr。
Sebastian Raschka认为,开源模型的下一个突破点不一定是“更大”,或许MoE也可能把开源模型提升到新的高度。
这么做可能是考虑硬件资源成本、数据量、开发时间等因素。
但也有值得关注的开源多模态大模型,例如10月17日刚发布的Fuyu-8B。

Fuyu-8B在处理图像时,直接将图像切成小块,然后把这些小块输入到一个线性投影层,在这一层里面自动学习小块的向量表示,避免用额外的预训练编码器来提取图像特征,简化了模型架构和训练过程。
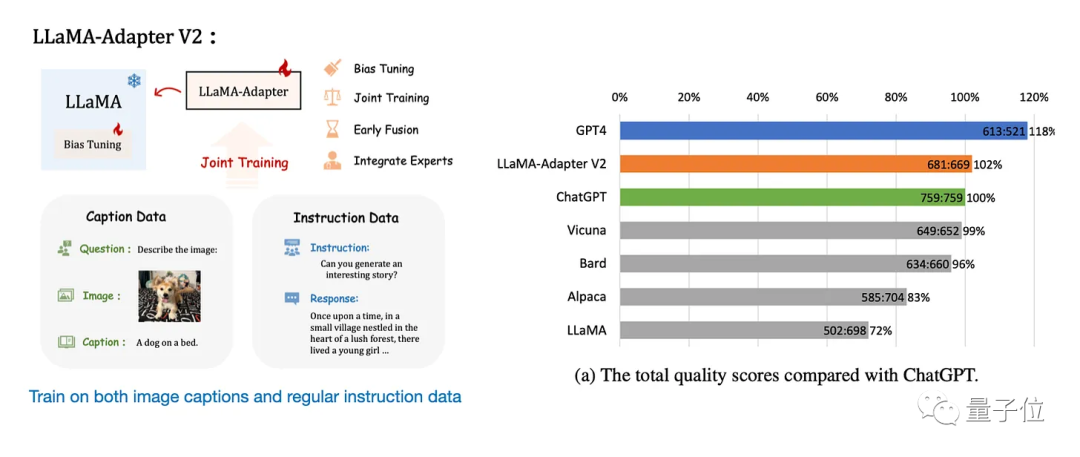
同时,Llama-Adapter v1、Llama-Adapter v2等微调方法的出现,有望将现有的大模型扩展到多模态领域。
RLHF平替已出现
RLHF(人类反馈强化学习)是大模型最受关注的技术之一,InstructGPT、ChatGPT、Llama 2中都用到了这种训练方法。

但分析公司stateof.ai发布的“2023AI现状报告”中显示,它还没有被广泛运用,可能是因为实现起来比较复杂。目前大多开源项目仍然专注于指令微调。

不过,RLHF的最新替代方案已经出现:直接偏好优化(DPO)。
这一方法由斯坦福大学研究团队提出。
DPO利用奖励函数到最优策略之间的映射关系,把强化学习问题转变成仅需要训练策略网络来拟合参考数据的问题。
也就是绕过了建模奖励函数,直接在偏好数据上优化语言模型。
用上DPO后,模型输出的质量也优于RLHF/PPO。
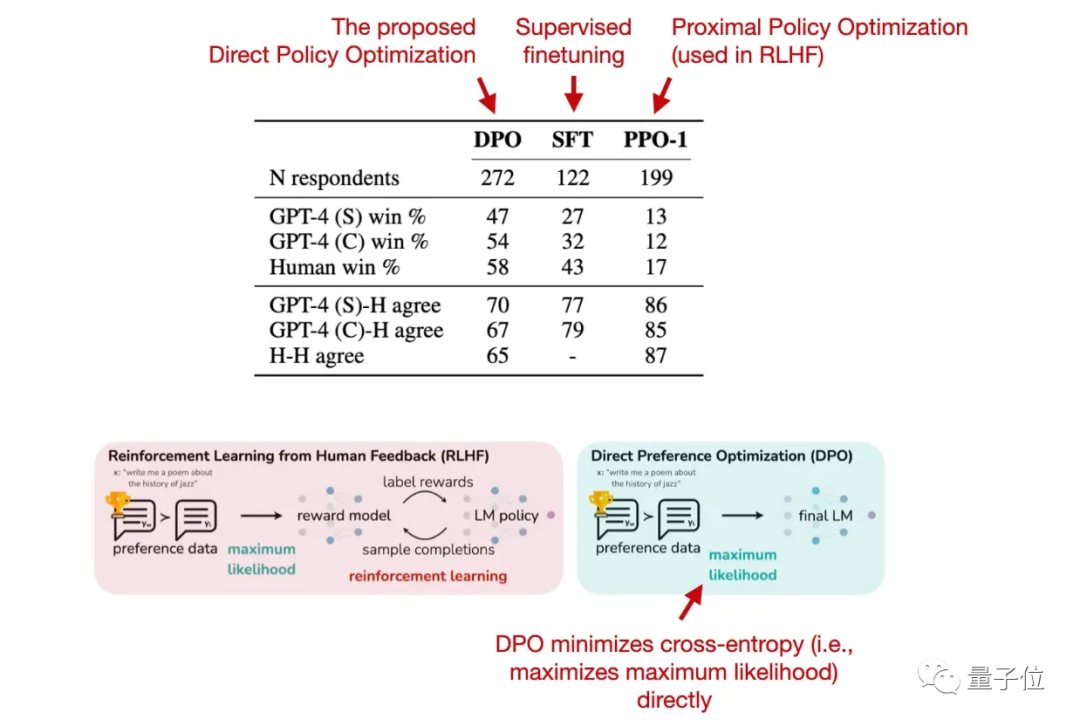
最近首个用DPO方法训练的开源大模型已出现,来自HuggingFace H4团队打造的Zephyr-7B,它在一些任务上已超过用RLHF训练的Llama 2-70B:

Transformer潜在新对手
今年还出现了一些Transformer的替代方案,比如循环RWKV、卷积Hyena。
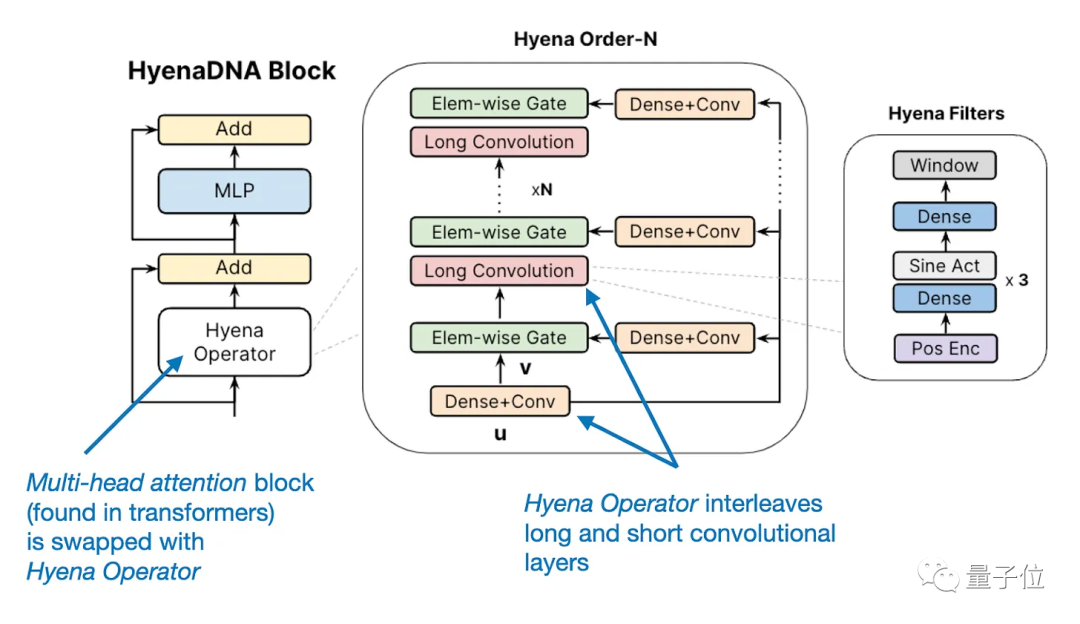
这些新的框架主要是用来提高模型效率,当然基于Transformer架构的大语言模型仍是主流。
大模型改变生产方式
大模型除了用来处理文本,也逐渐被用到提升生产力(Microsoft全家桶)和写代码(GitHub Copilot)等场景中。
Ark-Invest曾发布报告预测,编程助手能让编码任务的完成时间缩短约55%。
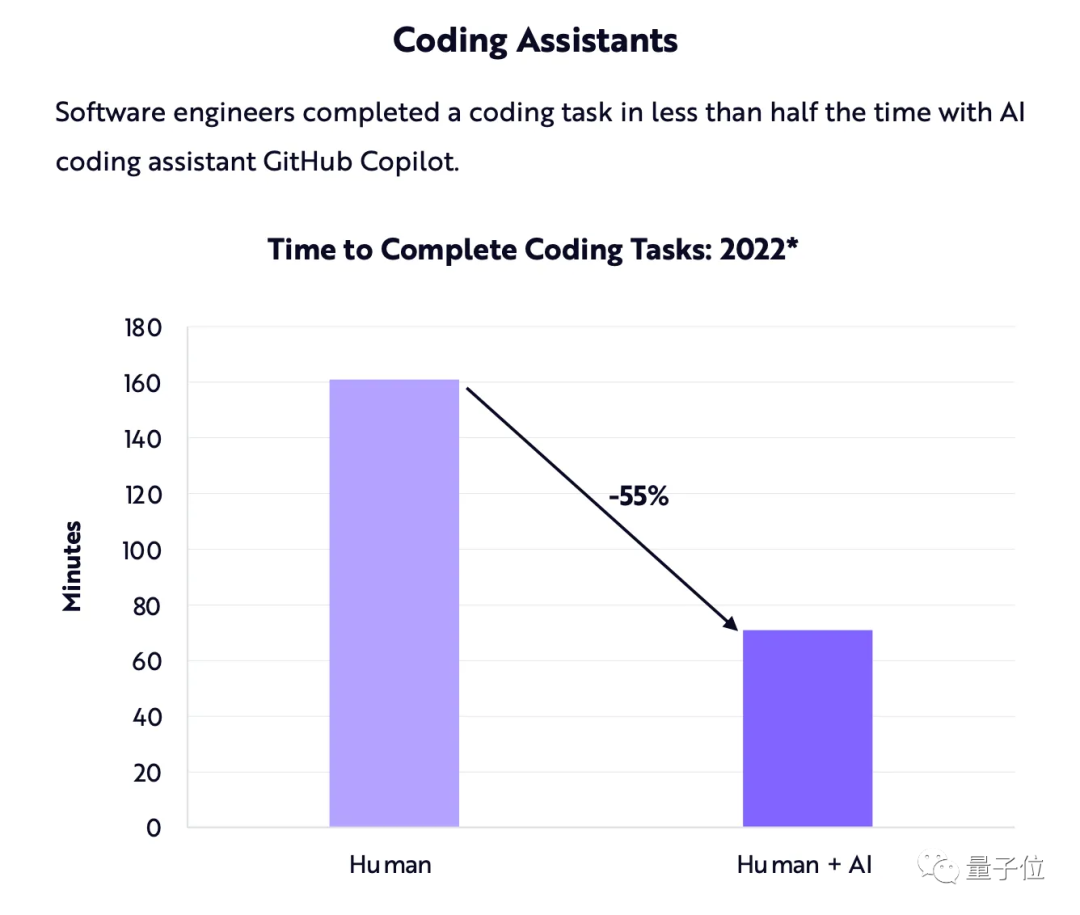
可以肯定,编码助手将继续存在,而且只会变得更好。
这对Stack Overflow(全球知名开发者问答网站)等平台意味着什么?
同样是“2023 AI现状报告”中,一张StackOverflow与GitHub的网站流量对比图,可以说明一些问题:
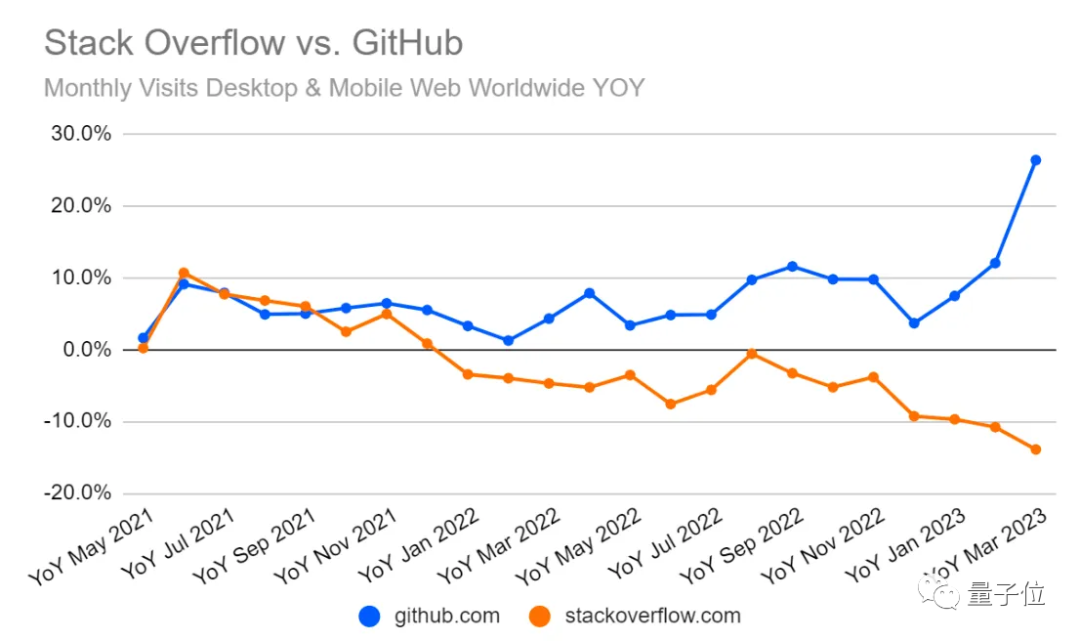
OK,以上就是大模型的一些新进展。
不过对于AI的“另半边天”计算机视觉而言,在2023年,这个领域也有许多不可忽视的新进展。
计算机视觉怎么样了?
今年大家都在重点关注大语言模型,但实际上,计算机视觉领域也取得了不少进展,从计算机视觉顶会CVPR 2023中就可以窥见一斑。
今年CVPR 2023共接收了2359篇论文,大多数研究都集中于以下4个主题,Sebastian Raschka逐个进行了介绍。
视觉Transformer突破限制
先来看看关注度最高的视觉Transformer。
效仿已取得巨大成功的语言Transformer架构,视觉Transformer(ViT)最初在2020年出现。
视觉Transformer原理与语言Transformer类似,是在多头注意力块中使用相同的自注意力机制。
不同的是,视觉Transformer不标记单词,而是标记图像,同样能取得不错的效果,但它一直有一个局限:相对资源密集且效率低于CNN,导致实际应用受阻。
今年在CVPR论文“EfficientViT:Memory Efficient Vision Transformer with Cascaded Group Attention”中,研究人员介绍了一种新的高效架构来解决这一限制——
相比原来的MobileViT,EfficientViT方法最多快了6倍。
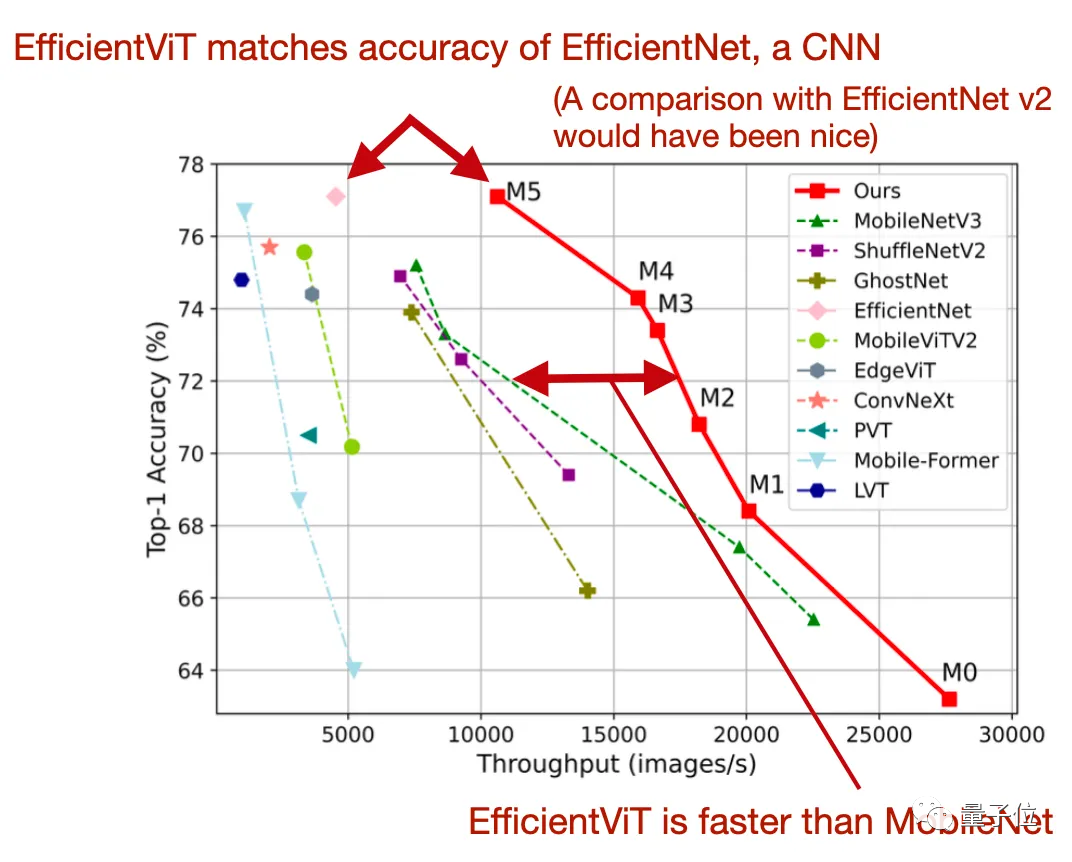
主要创新点有两个,一是全连接层之间的单个内存绑定多头自注意力模块,二是级联群注意力。
扩散模型又有新玩法
Stable Diffusion让扩散模型爆火,这类模型所用的方法是:
模型训练时,逐渐往训练数据中掺入噪声,直到变成纯噪声。然后再训练一个神经网络,让模型反向学习去噪,从噪声中合成数据。

大多数扩散模型使用CNN架构并采用基于CNN的U-Net。
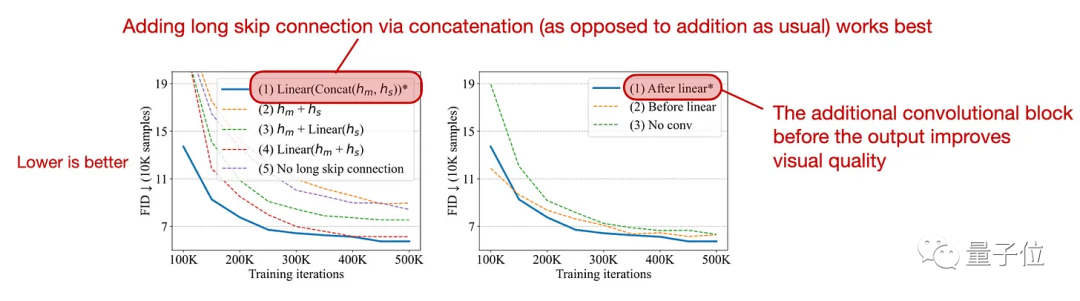
但今年“All are Worth Words:A ViT Backbone for Diffusion Models”这项研究中,研究人员试图将扩散模型中的卷积U-Net骨干(backbone)与ViT交换,变成U-ViT。
研究人员评估了新架构,在条件图像生成任务中,新的U-ViT扩散模型可与最好的GAN相媲美,优于其它扩散模型;在文本到图像生成方面,它优于在同一数据集上训练的其它模型。
3D重建新方法击败NeRF
3D重建是计算机视觉的研究重点之一,在3D扫描、虚拟现实、增强现实、电影和视频游戏中的3D建模和动作捕捉中都有运用。
今年SIGGRAPH 2023最佳论文中,有一篇被称为三维重建领域“爆炸性”新技术——Gaussian Splatting(高斯溅射)。
一举突破NeRF与之前的渲染引擎难兼容、需要专门设计硬件、渲染开销的老大难问题。

这种方法的核心是使用3D高斯作为场景表示,通过优化各向异性协方差矩阵来表示复杂场景。
论文还提出了交错的3D高斯参数优化和自适应密度控制方法,设计了快速、可微分的GPU栅格化方法,支持各向异性斑点,并实现快速反向传播,可以达到高质量的新视图合成,而且实现了首个1080p分辨率下的实时渲染。

只用很少的训练时间,Gaussian Splatting可以达到InstantNGP的最高质量,训练51分钟,性能甚至比Mip-NeRF360要好。
最近,华中科技大学&华为研究团队又继续提出了4D Gaussian Splatting。

4D Gaussian Splatting实现了实时的动态场景渲染,同时可保持高效的训练和存储效率。
在RTX 3090 GPU上,4D Gaussian Splatting以800×800分辨率达到70 FPS的性能,同时保持了与之前的最先进方法相媲美甚至更高的质量水平。
这项研究一出,网友沸腾直呼:
彻底改变三维重建。

当然,Sebastian Raschka也分享了CVPR上一些NeRF(Neural Radiance Fields)方法的新进展。
NeRF主要是通过训练神经网络来学习场景中每个点的颜色和密度,然后使用这些信息来生成逼真的3D场景渲染图像。
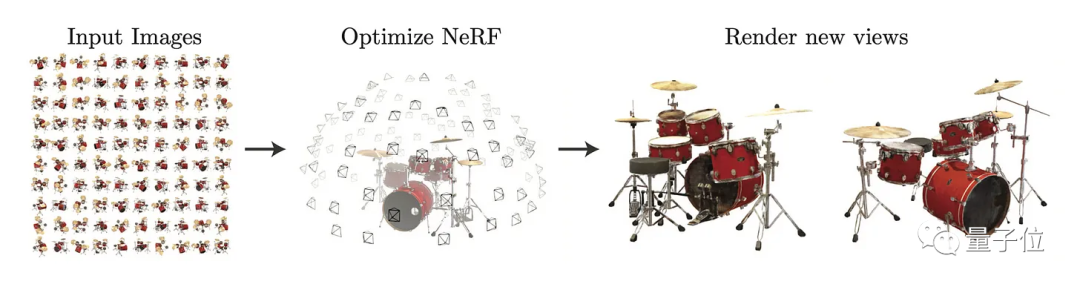
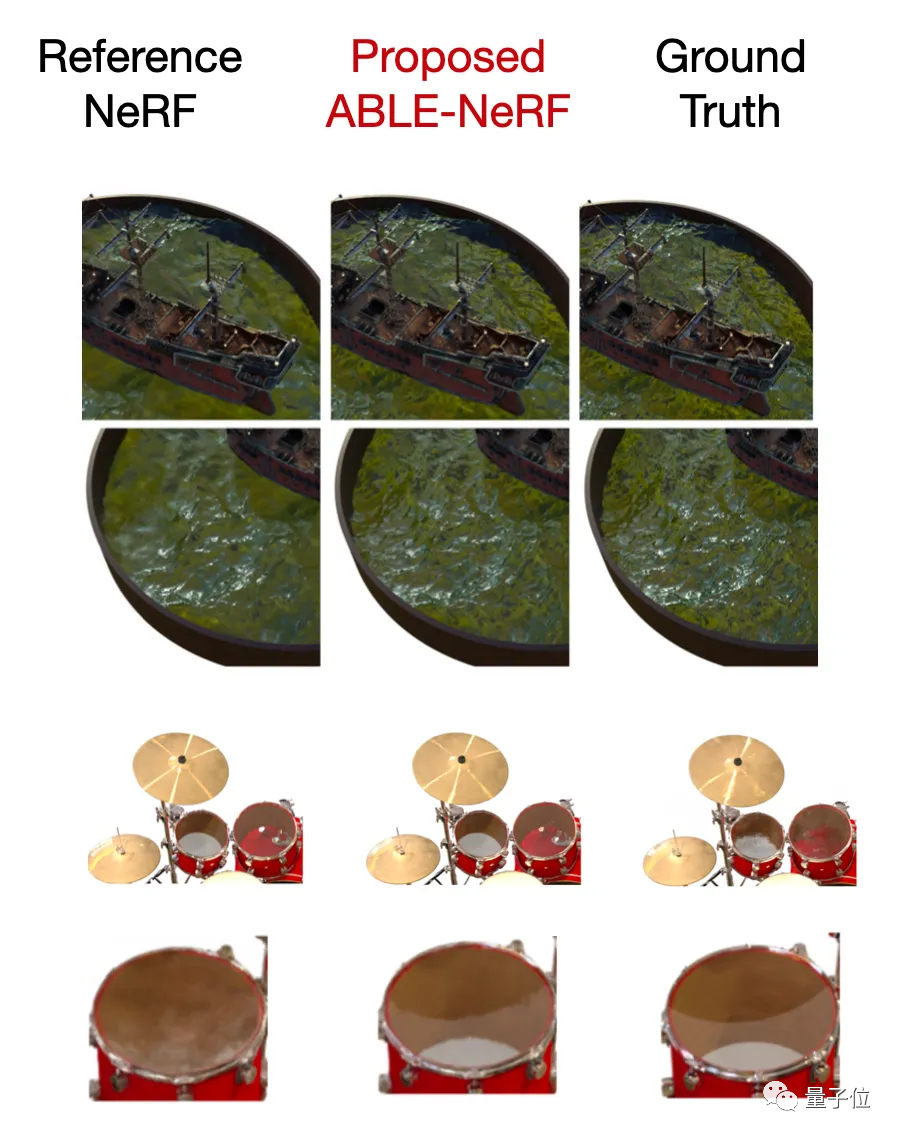
但NeRF有一个缺点是:有光泽的物体通常看不清,半透明物体的颜色也很模糊。
在“ABLE-NeRF:Attention-Based Rendering with Learnable Embeddings for Neural Radiance Field”这项研究中,研究人员通过引入基于自注意力的框架和可学习的嵌入解决这一问题,并提高了半透明和光泽表面的视觉质量。
目标检测和分割
目标检测和分割是经典的计算机视觉任务。
这两个任务还是有区别的,目标检测是关于预测边界框和相关标签,分割是对每个像素进行分类,来区分前景和背景。

△目标检测(左)和分割(右)
此外还可以细分为语义分割、实例分割、全景分割三个类别。
一项名为“Mask DINO:Towards A Unified Transformer based Framework for Object Detection and Segmentation”的研究,扩展了DINO方法。
Mask DINO性能优于所有现有的物体检测和分割系统。
DINO是一种带有改进去噪锚盒的DETR,而DETR是Facebook AI提出的一种端到端目标检测模型,它使用了Transformer架构,提供了一种更简单灵活的目标检测方法。
AI局限&展望未来
虽然AI领域这一年来取得了诸多进展,但依旧存在一些局限性,主要包括以下几点:
1、大模型幻觉
大语言模型依然存在着生成有毒内容和幻觉的问题。
今年出现了不少解决方案,包括RLHF和英伟达推出的NeMO Guardrails等,但这些方案要么难实施,要么处理得不到位。

目前为止,还没有找到一个可靠的方法,既能解决这一问题又不损害大模型的正向性能。
2、版权争议
与此同时,AI领域版权争议日益严峻。
各大模型厂商没少被起诉,之前开源数据集Books3也因侵权问题惨遭下架,Llama、GPT-J等都用它训练过。
总的来看,很多相关规定还在起草和修改过程中。
3、评估标准不统一
学术研究领域,基准测试和排名榜单可能已经失效是个问题。
用于测试的数据集可能已经泄露,成为了大语言模型的训练数据。
虽然通过询问人类偏好来评估大模型的效果是一个普遍的方法,但这种方式较为复杂。
还有许多研究报告使用GPT-4来评估。

4、收益尚不明确
生成式AI还在探索阶段,虽然无论是文本还是图像生成工具,在特定场景下确实能给人们提供帮助。
但这些工具是否真的能给公司带来收益,尤其是在高昂的运行成本面前,业界还在激烈讨论。
有报道称,OpenAI去年的运营亏损了5.4亿美元。直到最近又有消息指出,OpenAI现在每月能赚取8000万美元,有望弥补或甚至超出它的运营开支。
5、虚假图像泛滥
生成式AI带来的另一个问题是假图片和视频在社交媒体泛滥。
这个问题由来已久,PS等工具也能,而AI技术简易快捷,正在将此现象推向一个新的高度。
目前也有其它AI系统尝试自动识别AI产生的内容,但无论是文本、图片还是视频,这些系统的可靠性都不高。
6、数据集稀缺
涉及版权等争议,不少公司(Twitter/X、Reddit等)关闭了免费的API接入点,这样做既是为了增加收益,也是为了阻止数据采集器搜集平台数据用于AI训练。
之后一个好的方法可能是,建立一个众包数据集的平台,编写、收集和整理那些已经明确允许用于LLM训练的数据集。
展望2024,Sebastian Raschka认为大语言模型会在计算机科学之外的STEM研究领域发挥更大影响。
另一方面,由于高性能GPU紧缺,各大公司纷纷开发定制的AI芯片,问题关键在于怎样让这些硬件全面、稳定支持主流深度学习框架。
开源界,更多MoE(专家模型)也值得期待,共同创建数据集、DPO在开源模型中取代传统监督式微调也都是未来式。
Sebastian Raschka是谁?
Sebastian Raschka于2017年获得密歇根州立大学博士学位,曾是威斯康星大学麦迪逊分校统计学助理教授。
2022年Sebastian Raschka离职,加入初创公司Lightning AI成为其首席AI教育官。
此外,他还是包括《Python机器学习》在内的多本畅销书的作者。

他经常在自己的AI博客Ahead of AI中总结AI领域的各项研究,已揽获大波粉丝。

参考链接:
[1]https://magazine.sebastianraschka.com/p/ai-and-open-source-in-2023
[2]https://magazine.sebastianraschka.com/p/ahead-of-ai-10-state-of-computer
[3]https://twitter.com/dotey/status/1721204481369498004
— 完 —
「量子位2023人工智能年度评选」企业申报倒计时!
今年,量子位2023人工智能年度评选从企业、人物、产品/解决方案三大维度设立了5类奖项!扫码参与评选 ⬇️
MEET 2024大会已经开启报名!> 点此跳转报名 <

点这里声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

