
- 1聚类(三)FUZZY C-MEANS 模糊c-均值聚类算法——本质和逻辑回归类似啊
- 2Python3: Command not found(Mac OS)
- 3如何检测Web网站使用的是什么JS框架--一个很好用的工具_怎么看网页是用什么框架写的
- 4递归与回溯(Java实现)_java 递归返回的还是上次的对象
- 5CRC的verilog实现_任意多项式的crc verilog
- 6100道Python面试基础题收好了,可收藏_8.1.12.2如果现在有一台刚安装了winxp的计算机,请简单说明如何能够让以上程序 得
- 7Ubuntu搭建DNS服务器的组建与配置_ubuntu dns服务器
- 8网站项目管理规范指南_机关软件开发
- 9机器学习EM算法_算法目的是期望值最大化,它的收敛速度与数据缺失率有关,缺失率高则收敛速度慢,反
- 10HIVE----count(distinct ) over() 无法使用解决办法_hive count distinct over
RNN成长记(四):Attention机制_引入了注意力机制后的编码器-解码器模型
赞
踩
在这篇文章里,我们将尝试使用带有注意力机制的编码器-解码器(encoder-decoder)模型来解决序列到序列(seq-seq)问题
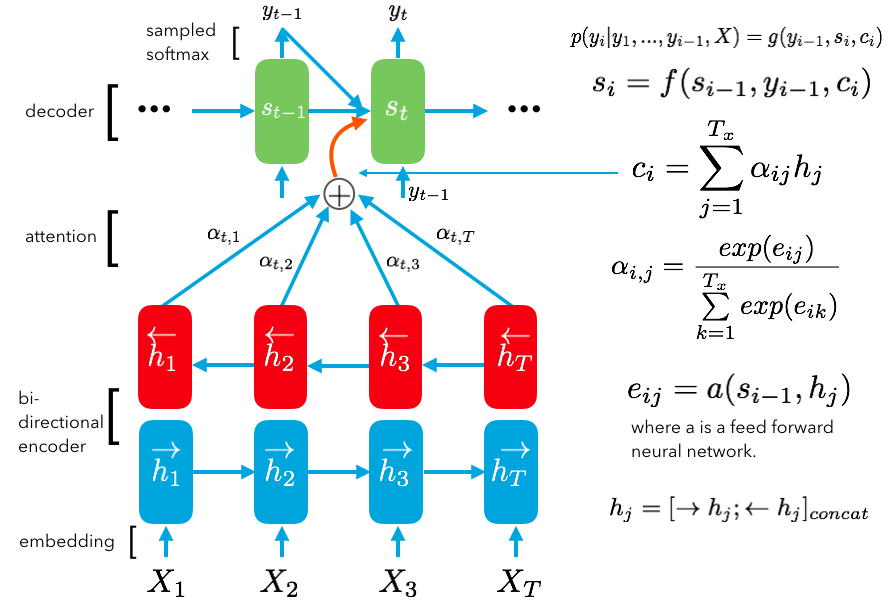
首先,让我们来一窥整个模型的架构并且讨论其中一些有趣的部分,然后我们会在先前实现的不带有注意力机制的编码器-解码器模型基础之上,添加注意力机制。我们将慢慢引入注意力机制,并实现模型的推断。。注意:这个模型并非当下最好的模型,更何况这些数据还是我在几分钟内草率地编写的。这篇文章旨在帮助你理解使用注意力机制的模型,从而你能够运用到更大的数据集上,并且取得非常不错的结果。
带有注意力机制的编码器-解码器模型:
这张图片是第一张图的更为具体的版本,包含了更多细节。让我们从编码器开始讲起,直到最后解码器的输出。首先,我们的输入数据是经过填充(Padding)和词嵌入(Embedding)处理的向量,我们将这些向量交给带有一系列 cell(上图中蓝色的 RNN 单元)的 RNN 网络,这些 cell 的输出称为隐藏状态(hidden state,上图中的h0,h1等),它们被初始化为零,但在输入数据之后,这些隐藏状态会改变并且持有一些非常有价值的信息。如果你使用的是一个 LSTM 网络(RNN 的一种),我们会把 cell 的状态 c 和隐藏状态 h 一起向前传递给下一个 cell。对于每一个输入(上图中的 X0等),在每一个 cell 上我们都会得到一个隐藏状态的输出,这个输出也会作为下一个 cell 输入的一部分。我们把每个神经元的输出记作 h1 到 hN,这些输出将会成为我们注意力模型的输入。
在我们深入探讨注意力机制之前,先来看看解码器是怎么处理它的输入以及如何产生输出的。目标语言经过同样的词嵌入处理后作为解码器的输入,以 GO 标识开始,以 EOS 和其后的一些填充部分作为结束。解码器的 RNN cell 同样有着隐藏状态,并且和上面一样,被初始化为零且随着数据的输入而产生变化。这样看来,解码器和编码器似乎没有什么不同。事实上,它们的不同之处在于解码器还会接收一个由注意力机制产生的上下文向量 ci作为输入。在接下来的部分里,我们将详细地讨论上下文向量是如何产生的,它是基于编码器的所有输入以及前面解码器 cell 的隐藏状态所产生的一个非常重要的成果:上下文向量能够指导我们在编码器产生的输入上如何分配注意力,来更好地预测接下来的输出。
解码器的每一个 cell 利用编码器产生的输入,和前一个 cell 的隐藏状态以及注意力机制产生的上下文向量来计算,最后经过 softmax 函数产生最终的目标输出。值得注意的是,在训练的过程中,每个 RNN cell 只使用这三个输出来获得目标的输出,然而在推断阶段中,我们并不知道解码器的下一个输入是什么。因此我们将使用解码器之前的预测结果来作为新的输入。
现在,让我们仔细看看注意力机制是怎么产生上下文向量的。
注意力机制:
上图是注意力机制的示意图,让我们先关注注意力层的输入和输出部分:我们利用编码器产生的所有隐藏状态以及上一个解码器 cell 的输出,来给每一个解码器 cell 生成对应的上下文向量。首先,这些输入都会经过一层 tanh 函数来产生一个形状为 [N, H] 的输出矩阵e,编码器中每个 cell 的输出都会产生对应解码器中第 i 个 cell 的一个 eij。接下来对矩阵 e 应用一次 softmax 函数,就能得到一个关于各个隐藏状态的概率,我们把这个结果记作 alpha。然后再利用 alpha 和原来的隐藏状态矩阵 h 相乘,使得每个 h 中的每一个隐藏状态获得个权重,最后进行求和就得到了形状为 [N, H] 的上下文向量 ci,实际上这就是编码器产生的输入的一个带有权重分布的表示。
在训练开始,这个上下文向量可能会比较随意,但是随着训练的进行,我们的模型将会不断地学习编码器产生的输入中哪一部分是重要的,从而帮助我们在解码器这一端产生更好的结果。
Tensorflow 实现:
现在让我们来实现这个模型,其中最重要的部分就是注意力机制。我们将使用一个单向的 GRU 编码器和解码器,和前面那篇文章里使用的非常类似,区别在于这里的解码器将会额外地使用上下文向量(表示注意力分配)来作为输入。另外,我们还将使用 Tensorflow 里的 embedding_attention_decoder()接口。
首先,让我们来了解一下将要处理并传递给编码器/解码器的数据集。
数据:
我为模型创建了一个很小的数据集:20 个英语和对应的西班牙语句子。这篇教程的重点是让你了解如何建立一个带有软注意力机制的编码器-解码器模型,来解决像机器翻译等的序列到序列问题。所以我写了关于我自己的 20 个英文句子,然后把他们翻译成对应的西班牙语,这就是我们的数据。
首先,我们把这些句子变成一系列 token,再把 token 转换成对应的词汇 id。在这个处理过程中,我们会建立一个词汇词典,使我们能够从 token 和词汇 id 之间完成转换。对于我们的目标语言(西班牙语),我们会额外地添加一个 EOS 标识。接下来我们将对源语言和目标语言转换得来的一组 token 进行填充操作,将它们补齐至最大长度(分别是它们各自的数据集中的最长句子长度),这将成为最终我们要喂给我们模型的数据。我们把经过填充的源语言数据传给编码器,但我们还会对目标语言的输入做一些额外的操作以获得解码器的输入和输出。
最后,输入就长成下面这个样子:
这只是数据集中的一个例子,向量里的 0 都是填充的部分,1 是 GO 标识,2 则是一个 EOS 标识。下图是数据处理过程更一般的表示,你可以忽略掉 target weights 这一部分,因为我们的实现中不会用到它。

