
热门标签
热门文章
- 1【MATLAB第51期】基于MATLAB的WOA-ORELM-LSTM多输入单输出回归预测模型,鲸鱼算法WOA优化异常鲁棒极限学习机ORELM超参数,修正LSTM残差_建立多输入单输出的修正方程的步骤
- 2【随笔】Git 高级篇 -- 远程与本地不一致导致提交冲突 git push --rebase(三十一)_git push 如何避免没有同步远程最新文件
- 3brew mysql 失败_Mac 用 brew 安装 MySQL 总是出错, 求解
- 4从C语言到C++过渡篇(快速入门C++)
- 512个C语言必背实例_c语言案例
- 62023-02-23 leetcode-数据结构_匈 利算法bfs
- 7北大发现了一种特殊类型的注意力头!
- 8关于时间复杂度和空间复杂度_论文的复杂度
- 9最优二叉搜索树问题(Java)_最优二叉搜索树java
- 10人工智能畅想——《人工智能简史》读后感_人工智能简史读后感
当前位置: article > 正文
机器学习——决策树算法_机器学习决策树算法
作者:我家小花儿 | 2024-05-01 16:56:09
赞
踩
机器学习决策树算法
一、决策树介绍
-
决策树是一种基于树结构来进行决策的分类算法,我们希望从给定的训练数据集学得一个模型(即决策树),用该模型对新样本分类。决策树可以非常直观展现分类的过程和结果,一旦模型构建成功,对新样本的分类效率也相当高。
-
最经典的决策树算法有ID3、C4.5、CART,其中ID3算法是最早被提出的,它可以处理离散属性样本的分类,C4.5和CART算法则可以处理更加复杂的分类问题。使用算法ID3, C4.5和C5.0生成树算法使用熵。这一度量是基于信息学理论中熵的概念。
-
分类树(决策树)是一种十分常用的分类方法。它是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。
-
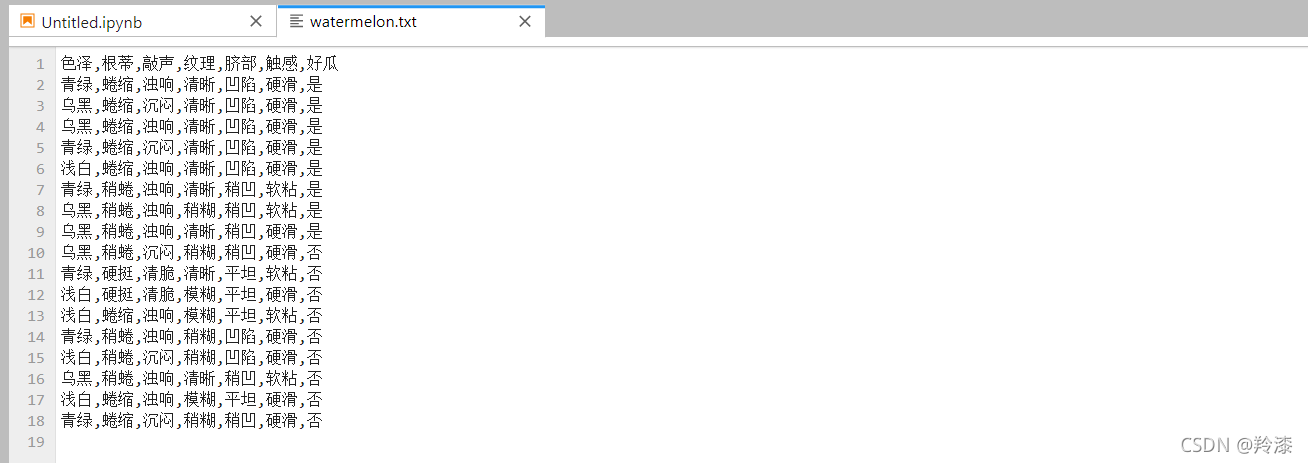
下面,我们就对以下表格中的西瓜样本构建决策树模型。
| 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
|---|---|---|---|---|---|---|
| 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
二、利用信息增益选择最优划分属性
样本有多个属性,该先选哪个样本来划分数据集呢?原则是随着划分不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一分类,即“纯度”越来越高。
- 信息熵
所谓信息熵,是一个数学上颇为抽象的概念,在这里不妨把信息熵理解成某种特定信息的出现概率。
样本集合D中第k类样本所占的比例p_k(k=1,2,…,|Y|),|Y|为样本分类的个数,则D的信息熵为:
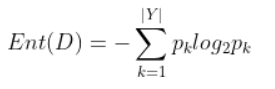
Ent(D)的值越小,则D的纯度越高。 - 信息增益
使用属性a对样本集D进行划分所获得的“信息增益”的计算方法是,用样本集的总信息熵减去属性a的每个分支的信息熵与权重(该分支的样本数除以总样本数)的乘积,通常,信息增益越大,意味着用属性a进行划分所获得的“纯度提升”越大。因此,优先选择信息增益最大的属性来划分。
西瓜样本集中,以属性“色泽”为例,它有3个取值{青绿、乌黑、浅白}
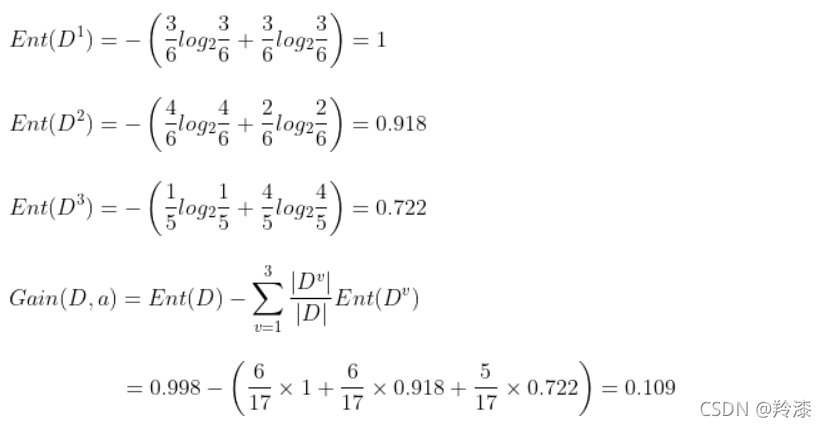
同理也可以计算出其他几个属性的信息增益,选择信息增益最大的属性作为根节点来进行划分,然后再对每个分支做进一步划分。
三、ID3代码实现
在代码路径下新建watermelon.txt文件
1.jupyter下python实现
- 导入模块
用pandas模块的read_csv()函数读取数据文本;用numpy模块将dataframe转换为list(列表);用Counter来完成计数;用math模块的log2函数计算对数。
#导入模块
import numpy as np
import pandas as pd
import math
import collections
- 1
- 2
- 3
- 4
- 5
- 导入数据
def import_data():
data = pd.read_csv('..watermelon.txt')
data.head(10)
data=np.array(data).tolist()
# 特征值列表
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
# 特征对应的所有可能的情况
labels_full = {}
for i in range(len(labels)):
labelList = [example[i] for example in data]
uniqueLabel = set(labelList)
labels_full[labels[i]] = uniqueLabel
return data,labels,labels_full
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 调用函数获取数据
data,labels,labels_full=import_data()
- 1
- 计算初始的信息熵,就是不分类之前的信息熵值
def calcShannonEnt(dataSet): """ 计算给定数据集的信息熵(香农熵) :param dataSet: :return: """ # 计算出数据集的总数 numEntries = len(dataSet) # 用来统计标签 labelCounts = collections.defaultdict(int) # 循环整个数据集,得到数据的分类标签 for featVec in dataSet: # 得到当前的标签 currentLabel = featVec[-1] # # 如果当前的标签不再标签集中,就添加进去(书中的写法) # if currentLabel not in labelCounts.keys(): # labelCounts[currentLabel] = 0 # # # 标签集中的对应标签数目加一 # labelCounts[currentLabel] += 1 # 也可以写成如下 labelCounts[currentLabel] += 1 # 默认的信息熵 shannonEnt = 0.0 for key in labelCounts: # 计算出当前分类标签占总标签的比例数 prob = float(labelCounts[key]) / numEntries # 以2为底求对数 shannonEnt -= prob * math.log2(prob) return shannonEnt

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 查看初始信息熵
print(calcShannonEnt(data)) # 输出为:0.9975025463691153
- 1

- 获取每个特征值的数量,这是为后面计算信息增益做准备
def splitDataSet(dataSet, axis, value): """ 按照给定的特征值,将数据集划分 :param dataSet: 数据集 :param axis: 给定特征值的坐标 :param value: 给定特征值满足的条件,只有给定特征值等于这个value的时候才会返回 :return: """ # 创建一个新的列表,防止对原来的列表进行修改 retDataSet = [] # 遍历整个数据集 for featVec in dataSet: # 如果给定特征值等于想要的特征值 if featVec[axis] == value: # 将该特征值前面的内容保存起来 reducedFeatVec = featVec[:axis] # 将该特征值后面的内容保存起来,所以将给定特征值给去掉了 reducedFeatVec.extend(featVec[axis + 1:]) # 添加到返回列表中 retDataSet.append(reducedFeatVec) return retDataSet
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 计算信息增益来确定最好的数据集划分
def chooseBestFeatureToSplit(dataSet, labels): """ 选择最好的数据集划分特征,根据信息增益值来计算 :param dataSet: :return: """ # 得到数据的特征值总数 numFeatures = len(dataSet[0]) - 1 # 计算出基础信息熵 baseEntropy = calcShannonEnt(dataSet) # 基础信息增益为0.0 bestInfoGain = 0.0 # 最好的特征值 bestFeature = -1 # 对每个特征值进行求信息熵 for i in range(numFeatures): # 得到数据集中所有的当前特征值列表 featList = [example[i] for example in dataSet] # 将当前特征唯一化,也就是说当前特征值中共有多少种 uniqueVals = set(featList) # 新的熵,代表当前特征值的熵 newEntropy = 0.0 # 遍历现在有的特征的可能性 for value in uniqueVals: # 在全部数据集的当前特征位置上,找到该特征值等于当前值的集合 subDataSet = splitDataSet(dataSet=dataSet, axis=i, value=value) # 计算出权重 prob = len(subDataSet) / float(len(dataSet)) # 计算出当前特征值的熵 newEntropy += prob * calcShannonEnt(subDataSet) # 计算出“信息增益” infoGain = baseEntropy - newEntropy #print('当前特征值为:' + labels[i] + ',对应的信息增益值为:' + str(infoGain)+"i等于"+str(i)) #如果当前的信息增益比原来的大 if infoGain > bestInfoGain: # 最好的信息增益 bestInfoGain = infoGain # 新的最好的用来划分的特征值 bestFeature = i #print('信息增益最大的特征为:' + labels[bestFeature]) return bestFeature
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 判断各个样本集的各个属性是否一致
def judgeEqualLabels(dataSet): """ 判断数据集的各个属性集是否完全一致 :param dataSet: :return: """ # 计算出样本集中共有多少个属性,最后一个为类别 feature_leng = len(dataSet[0]) - 1 # 计算出共有多少个数据 data_leng = len(dataSet) # 标记每个属性中第一个属性值是什么 first_feature = '' # 各个属性集是否完全一致 is_equal = True # 遍历全部属性 for i in range(feature_leng): # 得到第一个样本的第i个属性 first_feature = dataSet[0][i] # 与样本集中所有的数据进行对比,看看在该属性上是否都一致 for _ in range(1, data_leng): # 如果发现不相等的,则直接返回False if first_feature != dataSet[_][i]: return False return is_equal
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 绘制决策树(字典)
def createTree(dataSet, labels): """ 创建决策树 :param dataSet: 数据集 :param labels: 特征标签 :return: """ # 拿到所有数据集的分类标签 classList = [example[-1] for example in dataSet] # 统计第一个标签出现的次数,与总标签个数比较,如果相等则说明当前列表中全部都是一种标签,此时停止划分 if classList.count(classList[0]) == len(classList): return classList[0] # 计算第一行有多少个数据,如果只有一个的话说明所有的特征属性都遍历完了,剩下的一个就是类别标签,或者所有的样本在全部属性上都一致 if len(dataSet[0]) == 1 or judgeEqualLabels(dataSet): # 返回剩下标签中出现次数较多的那个 return majorityCnt(classList) # 选择最好的划分特征,得到该特征的下标 bestFeat = chooseBestFeatureToSplit(dataSet=dataSet, labels=labels) print(bestFeat) # 得到最好特征的名称 bestFeatLabel = labels[bestFeat] print(bestFeatLabel) # 使用一个字典来存储树结构,分叉处为划分的特征名称 myTree = {bestFeatLabel: {}} # 将本次划分的特征值从列表中删除掉 del(labels[bestFeat]) # 得到当前特征标签的所有可能值 featValues = [example[bestFeat] for example in dataSet] # 唯一化,去掉重复的特征值 uniqueVals = set(featValues) # 遍历所有的特征值 for value in uniqueVals: # 得到剩下的特征标签 subLabels = labels[:] subTree = createTree(splitDataSet(dataSet=dataSet, axis=bestFeat, value=value), subLabels) # 递归调用,将数据集中该特征等于当前特征值的所有数据划分到当前节点下,递归调用时需要先将当前的特征去除掉 myTree[bestFeatLabel][value] = subTree return myTree
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 调用函数并打印,就可以看到一个字典类型的树了
mytree=createTree(data,labels)
print(mytree)
- 1
- 2

- 绘制可视化树
import matplotlib.pylab as plt import matplotlib # 能够显示中文 matplotlib.rcParams['font.sans-serif'] = ['SimHei'] matplotlib.rcParams['font.serif'] = ['SimHei'] # 分叉节点,也就是决策节点 decisionNode = dict(boxstyle="sawtooth", fc="0.8") # 叶子节点 leafNode = dict(boxstyle="round4", fc="0.8") # 箭头样式 arrow_args = dict(arrowstyle="<-") def plotNode(nodeTxt, centerPt, parentPt, nodeType): """ 绘制一个节点 :param nodeTxt: 描述该节点的文本信息 :param centerPt: 文本的坐标 :param parentPt: 点的坐标,这里也是指父节点的坐标 :param nodeType: 节点类型,分为叶子节点和决策节点 :return: """ createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction', xytext=centerPt, textcoords='axes fraction', va="center", ha="center", bbox=nodeType, arrowprops=arrow_args) def getNumLeafs(myTree): """ 获取叶节点的数目 :param myTree: :return: """ # 统计叶子节点的总数 numLeafs = 0 # 得到当前第一个key,也就是根节点 firstStr = list(myTree.keys())[0] # 得到第一个key对应的内容 secondDict = myTree[firstStr] # 递归遍历叶子节点 for key in secondDict.keys(): # 如果key对应的是一个字典,就递归调用 if type(secondDict[key]).__name__ == 'dict': numLeafs += getNumLeafs(secondDict[key]) # 不是的话,说明此时是一个叶子节点 else: numLeafs += 1 return numLeafs def getTreeDepth(myTree): """ 得到数的深度层数 :param myTree: :return: """ # 用来保存最大层数 maxDepth = 0 # 得到根节点 firstStr = list(myTree.keys())[0] # 得到key对应的内容 secondDic = myTree[firstStr] # 遍历所有子节点 for key in secondDic.keys(): # 如果该节点是字典,就递归调用 if type(secondDic[key]).__name__ == 'dict': # 子节点的深度加1 thisDepth = 1 + getTreeDepth(secondDic[key]) # 说明此时是叶子节点 else: thisDepth = 1 # 替换最大层数 if thisDepth > maxDepth: maxDepth = thisDepth return maxDepth def plotMidText(cntrPt, parentPt, txtString): """ 计算出父节点和子节点的中间位置,填充信息 :param cntrPt: 子节点坐标 :param parentPt: 父节点坐标 :param txtString: 填充的文本信息 :return: """ # 计算x轴的中间位置 xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0] # 计算y轴的中间位置 yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1] # 进行绘制 createPlot.ax1.text(xMid, yMid, txtString) def plotTree(myTree, parentPt, nodeTxt): """ 绘制出树的所有节点,递归绘制 :param myTree: 树 :param parentPt: 父节点的坐标 :param nodeTxt: 节点的文本信息 :return: """ # 计算叶子节点数 numLeafs = getNumLeafs(myTree=myTree) # 计算树的深度 depth = getTreeDepth(myTree=myTree) # 得到根节点的信息内容 firstStr = list(myTree.keys())[0] # 计算出当前根节点在所有子节点的中间坐标,也就是当前x轴的偏移量加上计算出来的根节点的中心位置作为x轴(比如说第一次:初始的x偏移量为:-1/2W,计算出来的根节点中心位置为:(1+W)/2W,相加得到:1/2),当前y轴偏移量作为y轴 cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff) # 绘制该节点与父节点的联系 plotMidText(cntrPt, parentPt, nodeTxt) # 绘制该节点 plotNode(firstStr, cntrPt, parentPt, decisionNode) # 得到当前根节点对应的子树 secondDict = myTree[firstStr] # 计算出新的y轴偏移量,向下移动1/D,也就是下一层的绘制y轴 plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD # 循环遍历所有的key for key in secondDict.keys(): # 如果当前的key是字典的话,代表还有子树,则递归遍历 if isinstance(secondDict[key], dict): plotTree(secondDict[key], cntrPt, str(key)) else: # 计算新的x轴偏移量,也就是下个叶子绘制的x轴坐标向右移动了1/W plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW # 打开注释可以观察叶子节点的坐标变化 # print((plotTree.xOff, plotTree.yOff), secondDict[key]) # 绘制叶子节点 plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode) # 绘制叶子节点和父节点的中间连线内容 plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key)) # 返回递归之前,需要将y轴的偏移量增加,向上移动1/D,也就是返回去绘制上一层的y轴 plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD def createPlot(inTree): """ 需要绘制的决策树 :param inTree: 决策树字典 :return: """ # 创建一个图像 fig = plt.figure(1, facecolor='white') fig.clf() axprops = dict(xticks=[], yticks=[]) createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) # 计算出决策树的总宽度 plotTree.totalW = float(getNumLeafs(inTree)) # 计算出决策树的总深度 plotTree.totalD = float(getTreeDepth(inTree)) # 初始的x轴偏移量,也就是-1/2W,每次向右移动1/W,也就是第一个叶子节点绘制的x坐标为:1/2W,第二个:3/2W,第三个:5/2W,最后一个:(W-1)/2W plotTree.xOff = -0.5/plotTree.totalW # 初始的y轴偏移量,每次向下或者向上移动1/D plotTree.yOff = 1.0 # 调用函数进行绘制节点图像 plotTree(inTree, (0.5, 1.0), '') # 绘制 plt.show() if __name__ == '__main__': createPlot(mytree)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
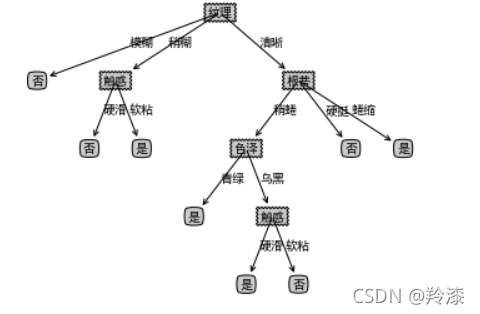
- 这里树少了一些标签,需要补全树之后再次输出
def makeTreeFull(myTree, labels_full, default): """ 将树中的不存在的特征标签进行补全,补全为父节点中出现最多的类别 :param myTree: 生成的树 :param labels_full: 特征的全部标签 :param parentClass: 父节点中所含最多的类别 :param default: 如果缺失标签中父节点无法判断类别则使用该值 :return: """ # 这里所说的父节点就是当前根节点,把当前根节点下不存在的特征标签作为子节点 # 拿到当前的根节点 root_key = list(myTree.keys())[0] # 拿到根节点下的所有分类,可能是子节点(好瓜or坏瓜)也可能不是子节点(再次划分的属性值) sub_tree = myTree[root_key] # 如果是叶子节点就结束 if isinstance(sub_tree, str): return # 找到使用当前节点分类下最多的种类,该分类结果作为新特征标签的分类,如:色泽下面没有浅白则用色泽中有的青绿分类作为浅白的分类 root_class = [] # 把已经分好类的结果记录下来 for sub_key in sub_tree.keys(): if isinstance(sub_tree[sub_key], str): root_class.append(sub_tree[sub_key]) # 找到本层出现最多的类别,可能会出现相同的情况取其一 if len(root_class): most_class = collections.Counter(root_class).most_common(1)[0][0] else: most_class = None# 当前节点下没有已经分类好的属性 # print(most_class) # 循环遍历全部特征标签,将不存在标签添加进去 for label in labels_full[root_key]: if label not in sub_tree.keys(): if most_class is not None: sub_tree[label] = most_class else: sub_tree[label] = default # 递归处理 for sub_key in sub_tree.keys(): if isinstance(sub_tree[sub_key], dict): makeTreeFull(myTree=sub_tree[sub_key], labels_full=labels_full, default=default)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
调用并再次绘制树
makeTreeFull(mytree,labels_full,default='未知')
createPlot(mytree)
- 1
- 2
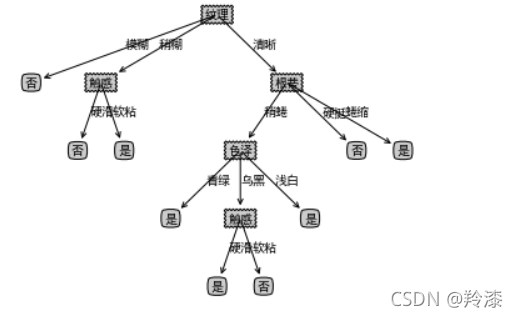
2. 使用sklearn实现ID3
- 导入包
# 导入包
import pandas as pd
from sklearn import tree
import graphviz
- 1
- 2
- 3
- 4
- 读取文件,可以看到读出来的数据
df = pd.read_csv('watermelon.txt')
df.head(10)
- 1
- 2
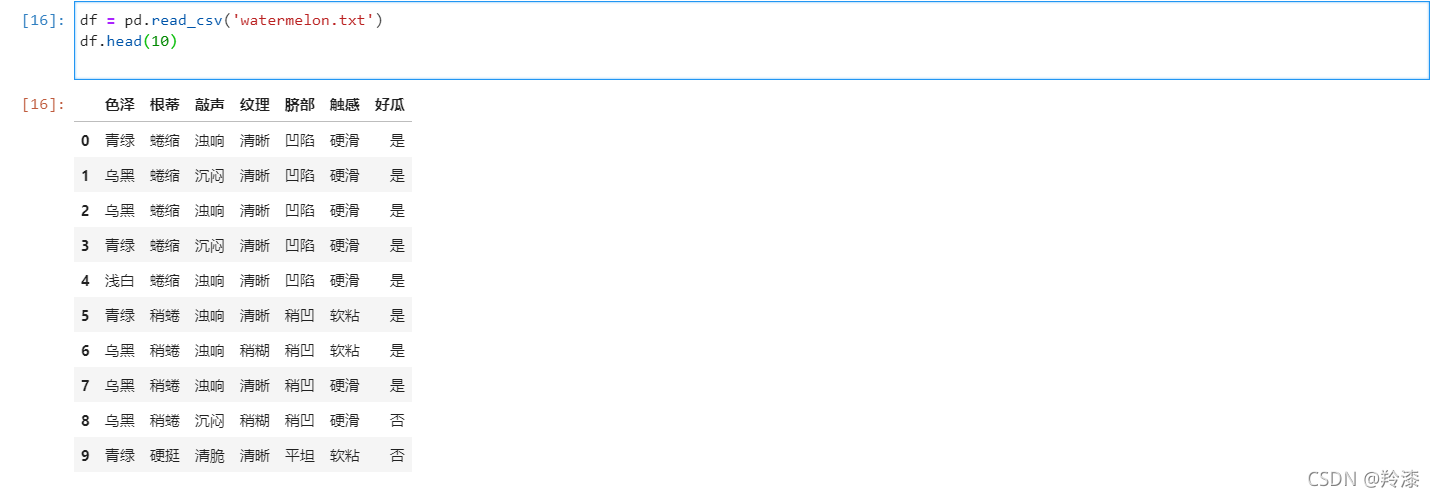
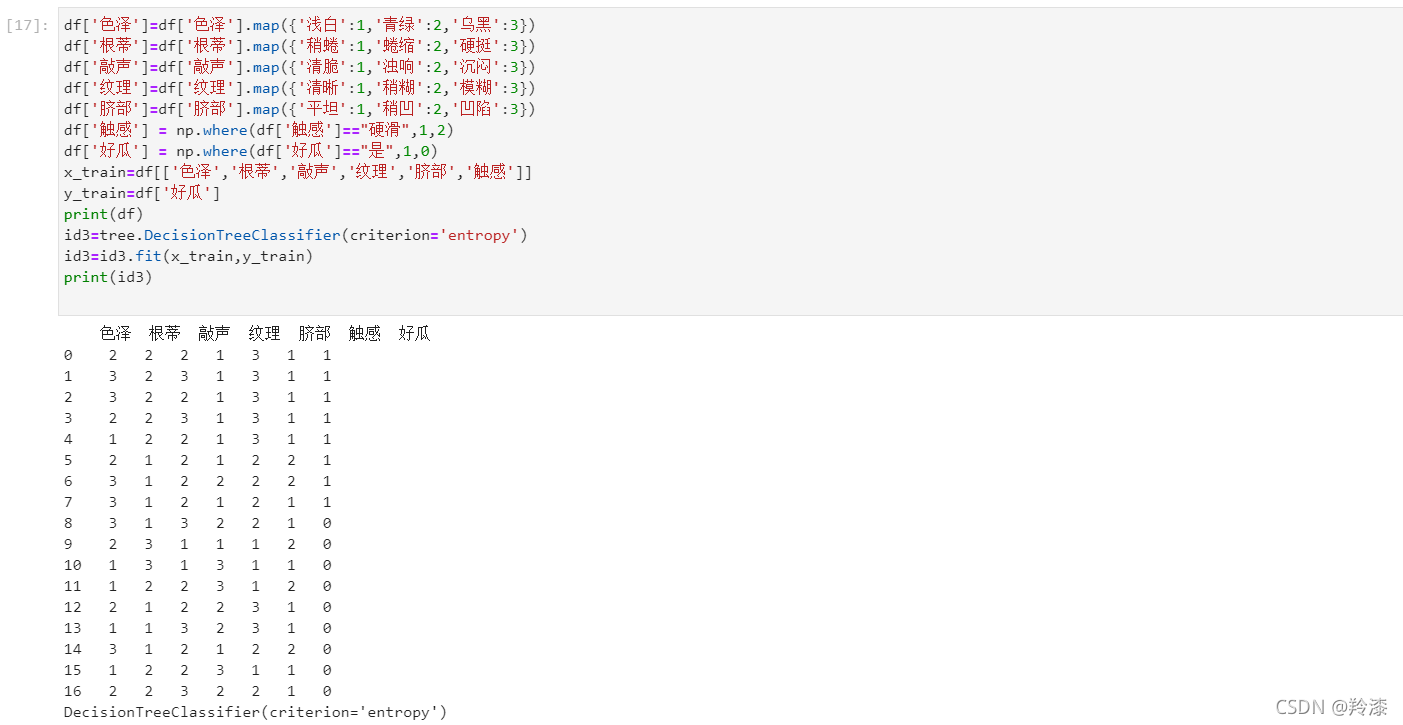
- 将特征值全部转化为数字
df['色泽']=df['色泽'].map({'浅白':1,'青绿':2,'乌黑':3})
df['根蒂']=df['根蒂'].map({'稍蜷':1,'蜷缩':2,'硬挺':3})
df['敲声']=df['敲声'].map({'清脆':1,'浊响':2,'沉闷':3})
df['纹理']=df['纹理'].map({'清晰':1,'稍糊':2,'模糊':3})
df['脐部']=df['脐部'].map({'平坦':1,'稍凹':2,'凹陷':3})
df['触感'] = np.where(df['触感']=="硬滑",1,2)
df['好瓜'] = np.where(df['好瓜']=="是",1,0)
x_train=df[['色泽','根蒂','敲声','纹理','脐部','触感']]
y_train=df['好瓜']
print(df)
id3=tree.DecisionTreeClassifier(criterion='entropy')
id3=id3.fit(x_train,y_train)
print(id3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
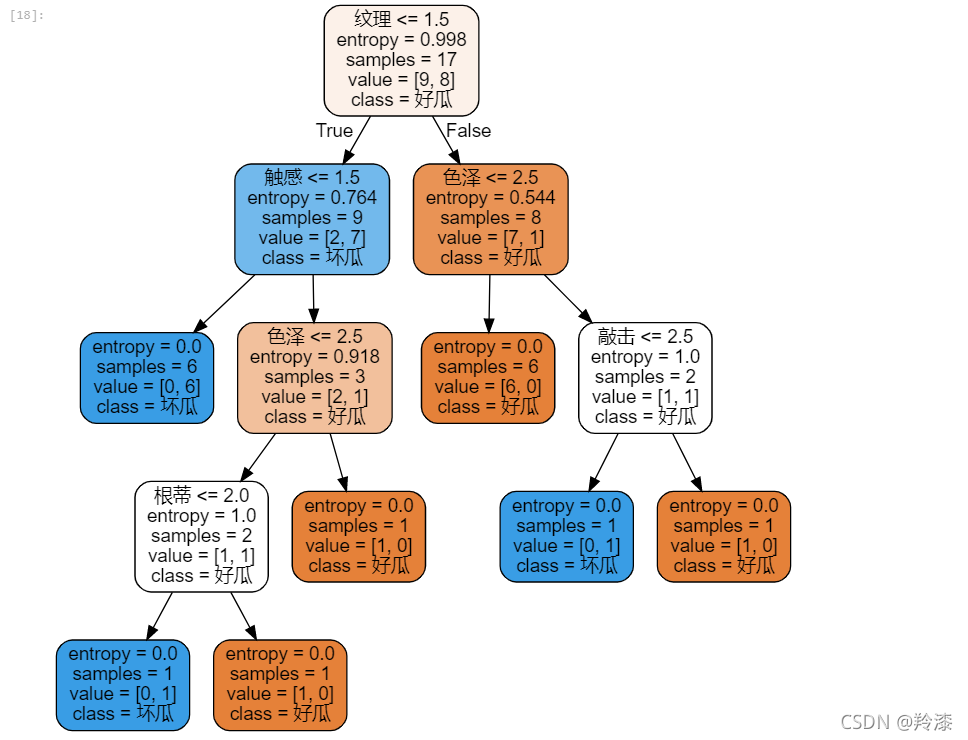
- 训练并进行可视化,DecisionTreeClassifier的参数为entropy时是id3算法,默认是CART算法,没有C4.5算法
id3=tree.DecisionTreeClassifier(criterion='entropy')
id3=id3.fit(x_train,y_train)
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
dot_data = tree.export_graphviz(id3
,feature_names=labels
,class_names=["好瓜","坏瓜"]
,filled=True
,rounded=True
)
graph = graphviz.Source(dot_data)
graph
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
四、C4.5算法实现
- C4.5算法介绍
C4.5是决策树核心算法ID3的改进算法,所以步骤和ID3是一样的,只是把信息增益变为信息增益率了,就是算出来信息增益之后再除以该特征的信息熵。 - 由于变得不多,只是把得到信息增益的那步再增加一步,得到信息增益率
## 实现C4.5算法 def chooseBestFeatureToSplit_4(dataSet, labels): """ 选择最好的数据集划分特征,根据信息增益值来计算 :param dataSet: :return: """ # 得到数据的特征值总数 numFeatures = len(dataSet[0]) - 1 # 计算出基础信息熵 baseEntropy = calcShannonEnt(dataSet) # 基础信息增益为0.0 bestInfoGain = 0.0 # 最好的特征值 bestFeature = -1 # 对每个特征值进行求信息熵 for i in range(numFeatures): # 得到数据集中所有的当前特征值列表 featList = [example[i] for example in dataSet] # 将当前特征唯一化,也就是说当前特征值中共有多少种 uniqueVals = set(featList) # 新的熵,代表当前特征值的熵 newEntropy = 0.0 # 遍历现在有的特征的可能性 for value in uniqueVals: # 在全部数据集的当前特征位置上,找到该特征值等于当前值的集合 subDataSet = splitDataSet(dataSet=dataSet, axis=i, value=value) # 计算出权重 prob = len(subDataSet) / float(len(dataSet)) # 计算出当前特征值的熵 newEntropy += prob * calcShannonEnt(subDataSet) # 计算出“信息增益” infoGain = baseEntropy - newEntropy infoGain = infoGain/newEntropy #print('当前特征值为:' + labels[i] + ',对应的信息增益值为:' + str(infoGain)+"i等于"+str(i)) #如果当前的信息增益比原来的大 if infoGain > bestInfoGain: # 最好的信息增益 bestInfoGain = infoGain # 新的最好的用来划分的特征值 bestFeature = i #print('信息增益最大的特征为:' + labels[bestFeature]) return bestFeature
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 创建树的函数还是改了一下,免得混淆
def createTree_4(dataSet, labels): """ 创建决策树 :param dataSet: 数据集 :param labels: 特征标签 :return: """ # 拿到所有数据集的分类标签 classList = [example[-1] for example in dataSet] # 统计第一个标签出现的次数,与总标签个数比较,如果相等则说明当前列表中全部都是一种标签,此时停止划分 if classList.count(classList[0]) == len(classList): return classList[0] # 计算第一行有多少个数据,如果只有一个的话说明所有的特征属性都遍历完了,剩下的一个就是类别标签,或者所有的样本在全部属性上都一致 if len(dataSet[0]) == 1 or judgeEqualLabels(dataSet): # 返回剩下标签中出现次数较多的那个 return majorityCnt(classList) # 选择最好的划分特征,得到该特征的下标 bestFeat = chooseBestFeatureToSplit_4(dataSet=dataSet, labels=labels) print(bestFeat) # 得到最好特征的名称 bestFeatLabel = labels[bestFeat] print(bestFeatLabel) # 使用一个字典来存储树结构,分叉处为划分的特征名称 myTree = {bestFeatLabel: {}} # 将本次划分的特征值从列表中删除掉 del(labels[bestFeat]) # 得到当前特征标签的所有可能值 featValues = [example[bestFeat] for example in dataSet] # 唯一化,去掉重复的特征值 uniqueVals = set(featValues) # 遍历所有的特征值 for value in uniqueVals: # 得到剩下的特征标签 subLabels = labels[:] subTree = createTree(splitDataSet(dataSet=dataSet, axis=bestFeat, value=value), subLabels) # 递归调用,将数据集中该特征等于当前特征值的所有数据划分到当前节点下,递归调用时需要先将当前的特征去除掉 myTree[bestFeatLabel][value] = subTree return myTree
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 调用函数,看一下字典型的树
mytree_4=createTree_4(data,labels)
print(mytree_4)
- 1
- 2

- 然后补全之后再可视化
makeTreeFull(mytree_4,labels_full,default='未知')
createPlot(mytree_4)
- 1
- 2
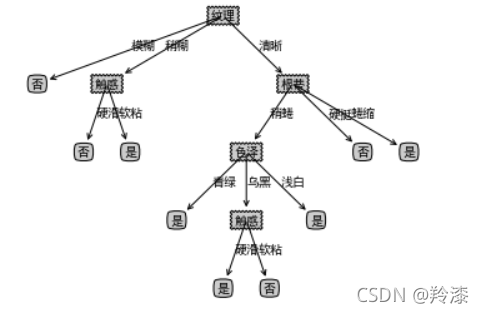
五、CART算法实现
- CART介绍
CART算法是一种二分递归分割技术,把当前样本划分为两个子样本,使得生成的每个非叶子结点都有两个分支,因此CART算法生成的决策树是结构简洁的二叉树。由于CART算法构成的是一个二叉树,它在每一步的决策时只能是“是”或者“否”,即使一个feature有多个取值,也是把数据分为两部分。 - 使用sklearn库实现,导入包
import pandas as pd
from sklearn import tree
import graphviz
- 1
- 2
- 3
- 导入数据并读取
df = pd.read_csv('watermelon.txt')
df.head(10)
- 1
- 2
- 将特征值化为数字
df['色泽']=df['色泽'].map({'浅白':1,'青绿':2,'乌黑':3})
df['根蒂']=df['根蒂'].map({'稍蜷':1,'蜷缩':2,'硬挺':3})
df['敲声']=df['敲声'].map({'清脆':1,'浊响':2,'沉闷':3})
df['纹理']=df['纹理'].map({'清晰':1,'稍糊':2,'模糊':3})
df['脐部']=df['脐部'].map({'平坦':1,'稍凹':2,'凹陷':3})
df['触感'] = np.where(df['触感']=="硬滑",1,2)
df['好瓜'] = np.where(df['好瓜']=="是",1,0)
x_train=df[['色泽','根蒂','敲声','纹理','脐部','触感']]
y_train=df['好瓜']
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 训练得到树,并且可视化
# 构建模型并训练
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
gini=tree.DecisionTreeClassifier()
gini=gini.fit(x_train,y_train)
#实现决策树的可视化
gini_data = tree.export_graphviz(gini
,feature_names=labels
,class_names=["好瓜","坏瓜"]
,filled=True
,rounded=True
)
gini_graph = graphviz.Source(gini_data)
gini_graph
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

六、总结
决策树理解还是不难的,就是要清楚每种算法的划分依据,步骤大致是先计算评判标准,后面再根据评判结果排序,最后根据顺序来递归建树。
参考文献
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/519829
推荐阅读
相关标签

