
- 1智能车的电机驱动DRV8833、DRV8833驱动直流电机、DRV8833接线图、DRV8833 PWM、DRV8833驱动代码
- 2【SpringBoot系列!】Spring Boot 3 核心技术和最佳实践_spring boot3 核心技术
- 3sql的基本用法-------修改字段默认值和属性
- 4iMazing2024激活码免费分享_imazing免费许可证码
- 5【springboot+vue项目(八)】VUE 与后端数据交互的3种方式_springboot和vue怎么交互
- 6Oracle权限详解_oracle comment权限
- 7重要一个设置 adb connect 由于目标计算机积极拒绝,无法连接。 (10061)_雷电模拟器 adb 连接 由于目标计算机积极拒绝,无法连接。 (10061)
- 8小区服务|基于SprinBoot+vue的小区服务管理系统(源码+数据库+文档)
- 9云计算:OVS 集群 使用 Geneve 流表
- 10为什么 APP 要用 token 而不用 session 认证?_web端用session认证吗 app端用token认证吗
「面试必背」Elasticsearch面试题(收藏)_es面试题
赞
踩
前言
随着企业对近实时搜索的迫切需求,Elasticsearch 受到越来越多的关注,无论是阿里、腾讯、京东等互联网企业,还是平安、顺丰等传统企业都对 Elasticsearch 有广泛的使用,但是在 Elasticsearch 6.8 发布以前,大部分 Elasticsearch 功能都是付费的,开源版本的 Elasticsearch 在集群管控方面能力有限,鉴于此,通用的实施方案就是给 Elasticsearch 添加一层网关,从而实现对 Elasticsearch 的管控。
Elasticsearch面试题
1、elasticsearch 了解多少,说说你们公司 es 的集群架构,索引数据大小,分片有多少,以及一些调优手段 。
- 面试官:想了解应聘者之前公司接触的 ES 使用场景、规模,有没有做过比较大规模的索引设计、规划、调优。
- 解答:如实结合自己的实践场景回答即可。
- 比如:ES 集群架构 13 个节点,索引根据通道不同共 20+索引,根据日期,每日递增 20+,索引:10分片,每日递增 1 亿+数据,每个通道每天索引大小控制:150GB 之内。
- 仅索引层面调优手段:
1.1、设计阶段调优
(1)根据业务增量需求,采取基于日期模板创建索引,通过 roll over API 滚动索引;
(2)使用别名进行索引管理;
(3)每天凌晨定时对索引做 force_merge 操作,以释放空间;
(4)采取冷热分离机制,热数据存储到 SSD,提高检索效率;冷数据定期进行 shrink操作,以缩减存储;
(5)采取 curator 进行索引的生命周期管理;
(6)仅针对需要分词的字段,合理的设置分词器;
(7)Mapping 阶段充分结合各个字段的属性,是否需要检索、是否需要存储等。
1.2、写入调优
(1)写入前副本数设置为 0;
(2)写入前关闭 refresh_interval 设置为-1,禁用刷新机制;
(3)写入过程中:采取 bulk 批量写入;
(4)写入后恢复副本数和刷新间隔;
(5)尽量使用自动生成的 id。
1.3、查询调优
(1)禁用 wildcard;
(2)禁用批量 terms(成百上千的场景);
(3)充分利用倒排索引机制,能 keyword 类型尽量 keyword;
(4)数据量大时候,可以先基于时间敲定索引再检索;
(5)设置合理的路由机制。
1.4、其他调优
- 部署调优,业务调优等。
- 上面的提及一部分,面试者就基本对你之前的实践或者运维经验有所评估了。
2、elasticsearch 的倒排索引是什么
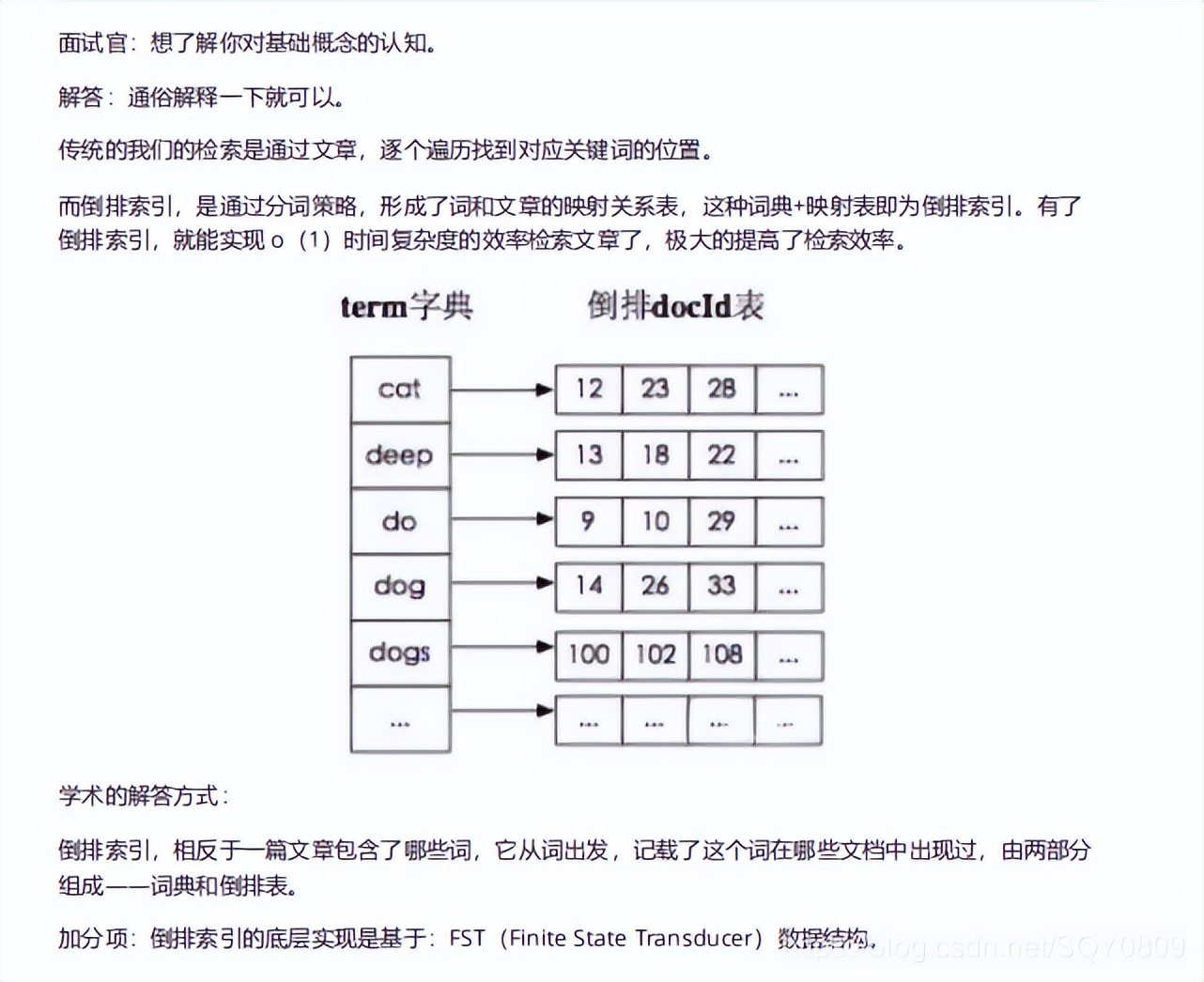
lucene 从 4+版本后开始大量使用的数据结构是 FST。FST 有两个优点:
(1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;
(2)查询速度快。O(len(str))的查询时间复杂度。
3、elasticsearch 索引数据多了怎么办,如何调优,部署
面试官:想了解大数据量的运维能力。
解答:索引数据的规划,应在前期做好规划,正所谓“设计先行,编码在后”,这样才能有效的避免突如其来的数据激增导致集群处理能力不足引发的线上客户检索或者其他业务受到影响。
如何调优,正如问题 1 所说,这里细化一下:
3.1 动态索引层面
基于模板+时间+rollover api 滚动创建索引,举例:设计阶段定义:blog 索引的模板格式为: blog_index_时间戳的形式,每天递增数据。这样做的好处:不至于数据量激增导致单个索引数据量非 常大,接近于上线 2 的32 次幂-1,索引存储达到了 TB+甚至更大。
一旦单个索引很大,存储等各种风险也随之而来,所以要提前考虑+及早避免。
3.2 存储层面
冷热数据分离存储,热数据(比如最近 3 天或者一周的数据),其余为冷数据。
对于冷数据不会再写入新数据,可以考虑定期 force_merge 加 shrink 压缩

