
- 1Cesium介绍及3DTiles数据加载时添加光照效果对比_cesium光照
- 2RabbitMQ的死信队列详解及实现_获取死信队列中的信息
- 3PeLK:通过周边卷积的参数高效大型卷积神经网络
- 4react 暂存数据持久化_react store 数据持久化
- 5Map集合和Collections(集合工具类)_collections工具类中的binarysearch()方法中的key是map中的键吗
- 6如何解决Git合并分支造成的冲突_git合并出现冲突是如何解决的
- 7jmeter 性能测试结果分析_jmeter结果分析
- 8在Git上放一个静态页面并且可以访问_gitlab 怎么发布静态页面
- 9机械臂视觉抓取总结_机械臂目标定位与抓取
- 10Jupyter 进阶教程
使 Elasticsearch 和 Lucene 成为最佳向量数据库:速度提高 8 倍,效率提高 32 倍
赞
踩
作者:来自 Elastic Mayya Sharipova, Benjamin Trent, Jim Ferenczi
Elasticsearch 和 Lucene 成绩单:值得注意的速度和效率投资
我们 Elastic 的使命是将 Apache Lucene 打造成最佳的向量数据库,并继续提升 Elasticsearch 作为搜索和 RAG(Retrieval Augmented Generation)的最佳检索平台。我们对 Lucene 的投资是关键,以确保每个版本的 Elasticsearch 都能带来更快的性能和更大的规模。
在这篇博客中,我们总结了近期对 Elasticsearch 和 Apache Lucene 进行的增强和优化,这些提升在向量搜索性能上远超 Apache 9.9 和 Elasticsearch 8.12.x 所带来的性能增益。
向量搜索的整合到 Elasticsearch 中依赖于 Apache Lucene,Lucene 负责数据存储和检索的协调。Lucene 的架构将数据组织成段,这些段是不可变的单元,会定期合并。这种结构有助于有效管理倒排索引,这对文本搜索至关重要。对于向量搜索,Lucene 扩展了其功能,能够处理多维点,采用分层可导航小世界(hierarchical navigable small world - HNSW)算法来索引向量。
这种方法促进了可扩展性,使数据集可以超过可用 RAM 大小,同时保持性能。此外,Lucene 的基于段的方法提供了无锁搜索操作,支持增量变化并确保跨各种数据结构的可见性一致性。然而,整合本身带来了自己的工程挑战。合并段需要重新计算 HNSW 图,这会带来索引时间的开销。搜索必须覆盖多个段,可能导致潜在的延迟开销。此外,优化性能需要随着数据增长而扩展 RAM,这可能会引起资源管理的关注。
Lucene 整合到 Elasticsearch 中带来了强大的向量搜索功能。这包括聚合、文档级安全、地理空间查询、预过滤,以及与各种 Elasticsearch 功能的完全兼容。想象一下使用地理边界框进行向量搜索,这是 Elasticsearch 和 Lucene 启用的一个示例用例。
Lucene 的架构为 Elasticsearch 内高效且多功能的向量搜索奠定了坚实的基础。让我们探讨一下我们为整合向量搜索到 Lucene 中而实施的优化策略和增强功能,这些都为开发人员提供了高性能和全面的功能集。
利用 Lucene 的分段架构实现多线程搜索
Lucene 的分段架构使得可以实现多线程搜索能力。Elasticsearch 的性能提升来自同时高效搜索多个段。通过利用所有可用 CPU 核心的处理能力,可以显著降低单个搜索的延迟。虽然这可能不会直接提高总体吞吐量,但这种优化将优先考虑最小化响应时间,确保用户尽快收到他们的搜索结果。
此外,这种优化对于 Hierarchical Navigable Small World(HNSW)搜索特别有益,因为每个图形是相互独立的,可以并行搜索,最大程度地提高效率,进一步加快检索速度。
拥有多个独立段的优势在架构层面上得到了延伸,特别是在无服务器(serverless)环境中。在这种新架构中,索引层负责创建新的段,每个段包含其自己的 HSNW 图。搜索层可以简单地复制这些段,而不会产生索引化的 CPU 成本。这种分离允许将大量计算资源专用于搜索,优化整体系统性能和响应能力。
加速多图向量搜索
尽管并行化带来了一些成效,每个段内的搜索仍然是独立进行的,无法知晓其他段搜索的进展。因此,我们将重点转向优化跨多个段的并发搜索效率。
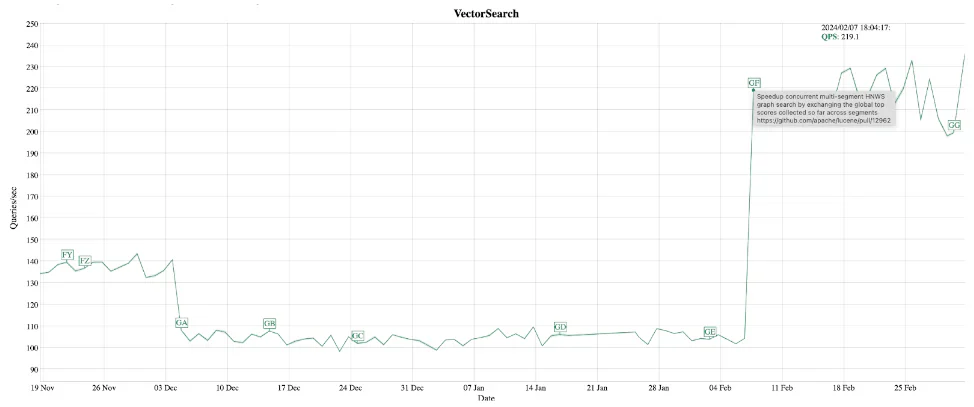
图表显示每秒查询次数从 104 次增加到 219 次。
认识到进一步提速的潜力,我们利用了优化词汇搜索的见解,使段内搜索之间能够进行信息交换,从而实现向量搜索的更好协调和效率。
我们加速多图向量搜索的策略围绕着在接近图中平衡探索和利用。通过调整扩展匹配集的大小,我们控制了运行时和召回率之间的权衡,这对于在多个图中实现最佳搜索性能至关重要。
在多图搜索场景中,挑战在于有效地导航各个图,同时确保全面的探索,以避免局部最小值。虽然独立搜索多个图会产生更高的召回率,但由于冗余的探索工作,会导致运行时增加。为了缓解这个问题,我们设计了一种策略,智能地在搜索之间共享状态,基于全局和本地竞争阈值做出知情的遍历决策。
这种方法涉及维护共享的全局和本地距离队列,根据每个图的本地搜索的竞争力动态调整搜索参数。通过同步信息交换并相应调整搜索策略,我们在保持与单图搜索相当的召回率的同时,实现了搜索延迟的显着改善。
这些优化的影响在我们的基准结果中是显而易见的。在并发搜索和索引场景中,我们观察到查询延迟减少了高达 60%!即使在索引操作之外进行查询,我们也观察到明显的加速和所需的向量操作数量的急剧减少。这些增强功能已集成到 Lucene 9.10 中,随后又集成到 Elasticsearch 8.13 中,为搜索增强了向量数据库的性能,同时保持了优秀的召回率。
利用 Java 最新进展实现疯狂的速度
在 Java 开发领域,自动向量化是一大福音,通过 HotSpot C2 编译器将标量操作优化为 SIMD(单指令多数据)指令。虽然这种自动优化是有益的,但它也有其局限性,特别是在需要对代码形状进行显式控制以获得更优性能的情况下。于是,引入了项目 Panama Vector API,这是 JDK 的最新增加,提供了一个 API,用于在运行时可靠地表达计算,这些计算被编译为 SIMD 指令。
Lucene 的向量搜索实现依赖于诸如点积、平方和余弦距离等基本操作,既有浮点型又有二进制型。传统上,这些操作都是由标量实现支持的,性能提升由 JIT 编译器完成。然而,最近的进展引入了一种范式转变,使开发人员能够显式地表达这些操作,以实现最佳性能。
以点积操作为例,这是一种基本的向量计算。传统上,使用 Java 进行标量算术实现,而最新的创新利用了 Panama Vector API,以一种有利于 SIMD 指令的方式表达点积计算。这种修订后的实现在输入数组上进行迭代,以批处理方式进行元素的乘法和累加,与底层硬件能力对齐。
通过利用 Panama Vector API,Java 代码现在可以无缝地与 SIMD 指令进行交互,释放出显著性能提升的潜力。当在兼容的 CPU 上执行编译后的代码时,将利用高级向量指令,如 AVX2 或 AVX 512,加速计算。反汇编编译后的代码会显示出针对底层硬件架构定制的优化指令。
将传统 Java 实现与利用 Panama Vector API 的实现进行微基准测试,可以明显看到性能的巨大提升。在各种向量操作和维度大小上,优化后的实现均以显著的优势胜过其前身,展示了 SIMD 指令变革性能量的一瞥。

微基准测试(micro-benchmark)比较了使用新的 Panama API(dotProductNew)和标量实现(dotProductOld)的点积操作。
除了微基准测试外,想象这些优化对现实世界的影响是非常令人兴奋的。向量搜索基准测试,如 SO Vector,展示了索引吞吐量、合并时间和查询延迟方面的显著增强。Elasticsearch,采纳了这些进步,通过默认方式整合了更快的实现,确保用户能够无缝地获得性能优势。

图表显示索引吞吐量从约 900 个文档/秒增加到约 1300 个文档/秒。
尽管 Panama Vector API 仍处于孵化阶段,但其质量和潜在的好处是不可否认的。Lucene 的务实方法允许选择性采用非最终的 JDK API,平衡了性能改进的承诺和维护考虑。通过 Lucene 和 Elasticsearch,用户可以轻松地利用这些进步,性能提升直接转化为实际工作负载。
将 Panama Vector API 整合到 Java 开发中,为性能优化开启了新时代,特别是在向量搜索场景中。通过采用硬件加速的 SIMD 指令,开发人员可以释放效率增益,在微基准测试和宏观级别基准测试中都可见。随着 Java 不断发展,利用其最新特性将性能推向新高度,丰富各种应用程序的用户体验。
最大化内存效率与标量量化
内存消耗一直是有效进行向量数据库操作的一个关注点,特别是在搜索大型数据集时。Lucene 引入了一个突破性的优化技术 —— 标量量化 —— 旨在显著减少内存需求,而不牺牲搜索性能。
考虑这样一个场景:查询数百万个高维度的 float32 向量需要大量内存,从而导致显著的成本。通过采用字节量化,Lucene 将内存使用量减少了大约 75%,为向量搜索操作的内存密集性提供了一个可行的解决方案。
为了将浮点数量化为字节,Lucene 实现了标量量化 —— 一种有损压缩技术,将原始数据转换为压缩形式,为节省空间牺牲了一些信息。Lucene 的标量量化实现在对召回率影响最小的情况下,实现了显著的空间节省,使其成为内存受限环境的理想解决方案。
Lucene 的架构由节点(node)、分片(shard)和段(segment)组成,这有助于有效分配和管理搜索文档。每个段存储原始向量、量化向量和元数据,确保优化的存储和检索机制。
Lucene 的向量量化随时间动态调整,通过在段合并操作期间调整分位数来保持最佳召回率。通过智能处理量化更新和必要时重新量化,Lucene 确保在数据分布变化时保持一致的性能。
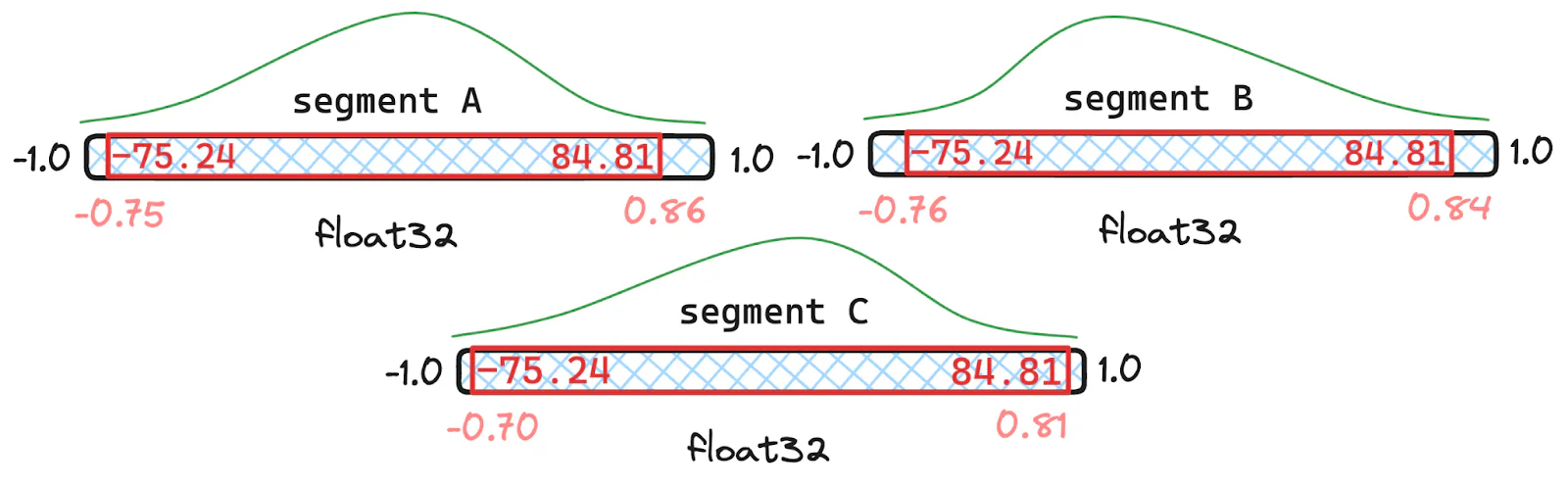
举例说明合并分位数,其中段 A 和 B 各有 1000 个文档,而段 C 只有 100 个文档。
实验结果显示,标量量化在减少内存占用的同时保持搜索性能的有效性。尽管与原始向量相比在召回率上有轻微的差异,Lucene 的量化向量提供了显著的速度改进,并且通过最小的额外向量实现了召回率的恢复。

量化向量与原始向量的 Recall@10。量化向量的搜索性能显著快于原始向量,并且通过获取仅 5 个额外向量即可快速恢复召回率;这在 quantized@15 中可见。
Lucene 的标量量化为向量搜索操作中的内存优化提供了一种革命性的方法。无需训练或优化步骤,Lucene 将量化无缝集成到其索引过程中,随着时间的推移自动适应数据分布的变化。随着 Lucene 和 Elasticsearch 的不断发展,广泛采用标量量化将为向量数据库应用程序的内存效率带来革命性变革,为大规模增强搜索性能铺平道路。
实现无缝压缩,对召回率影响最小
为了进一步改善压缩效果,我们的目标是将每个维度从 7 位减少到仅 4 位。我们的主要目标是在压缩数据的同时保持搜索结果的准确性。通过一些改进,我们成功将数据压缩了 8 倍,而不会使搜索结果变差。以下是我们的做法。
我们专注于在缩小数据的同时保持搜索结果的准确性。通过确保在压缩过程中不丢失重要信息,我们仍然可以在数据较少详细的情况下良好地找到所需内容。为了确保不丢失任何重要信息,我们添加了一个智能错误校正系统。
我们通过使用不同类型的数据和真实的搜索情况来测试我们的压缩改进,来检查我们的压缩效果。这有助于我们了解我们的搜索在不同压缩级别下的工作效果,以及通过更多压缩可能会失去的准确性。

对 100 个文档及其 10 个最近邻居的随机样本的 int4 点积值与相应的浮点值的比较。
这些压缩特性被设计用来轻松地与现有的向量搜索系统配合使用。它们帮助组织和用户节省空间,而无需在设置中做太多改变。通过这种简单的压缩,组织可以扩展其搜索系统,而不会浪费资源。
简而言之,将标量量化的每个维度移至 4 位对于提高压缩效率是一大进步。它使用户可以将其原始向量压缩 8 倍。通过精心优化、添加错误校正、使用真实数据进行测试和提供可扩展的部署,组织可以节省大量存储空间,而不会使搜索结果变差。这为高效和可扩展的搜索应用程序开辟了新的机会。
为二进制量化铺平道路
将每个维度减少到 4 位不仅带来了显著的压缩效益,而且为进一步提高压缩效率奠定了基础。具体来说,像将二进制量化引入 Lucene 这样的未来发展具有革命性地改变向量存储和检索的潜力。
在不断推动向量搜索压缩极限的努力中,我们正在积极地使用支撑我们现有优化策略的相同技术和原则,将二进制量化整合到 Lucene 中。我们的目标是实现向量维度的二进制量化,从而将向量表示的大小相比原始浮点格式减少 32 倍。
通过我们的迭代和实验,我们希望充分发挥向量搜索的潜力,同时最大化资源利用和可扩展性。敬请期待我们将二进制量化整合到 Lucene 和 Elasticsearch 的进展更新,以及它将对向量数据库存储和检索产生的变革性影响。
在 Lucene 和 Elasticsearch 中进行多向量集成
许多实际应用依赖于文本嵌入模型和大量文本输入。大多数嵌入模型都有标记限制,这需要将较长的文本分块成段落。因此,与单个文档相比,必须管理多个段落和嵌入,这可能会使元数据的保留变得复杂。
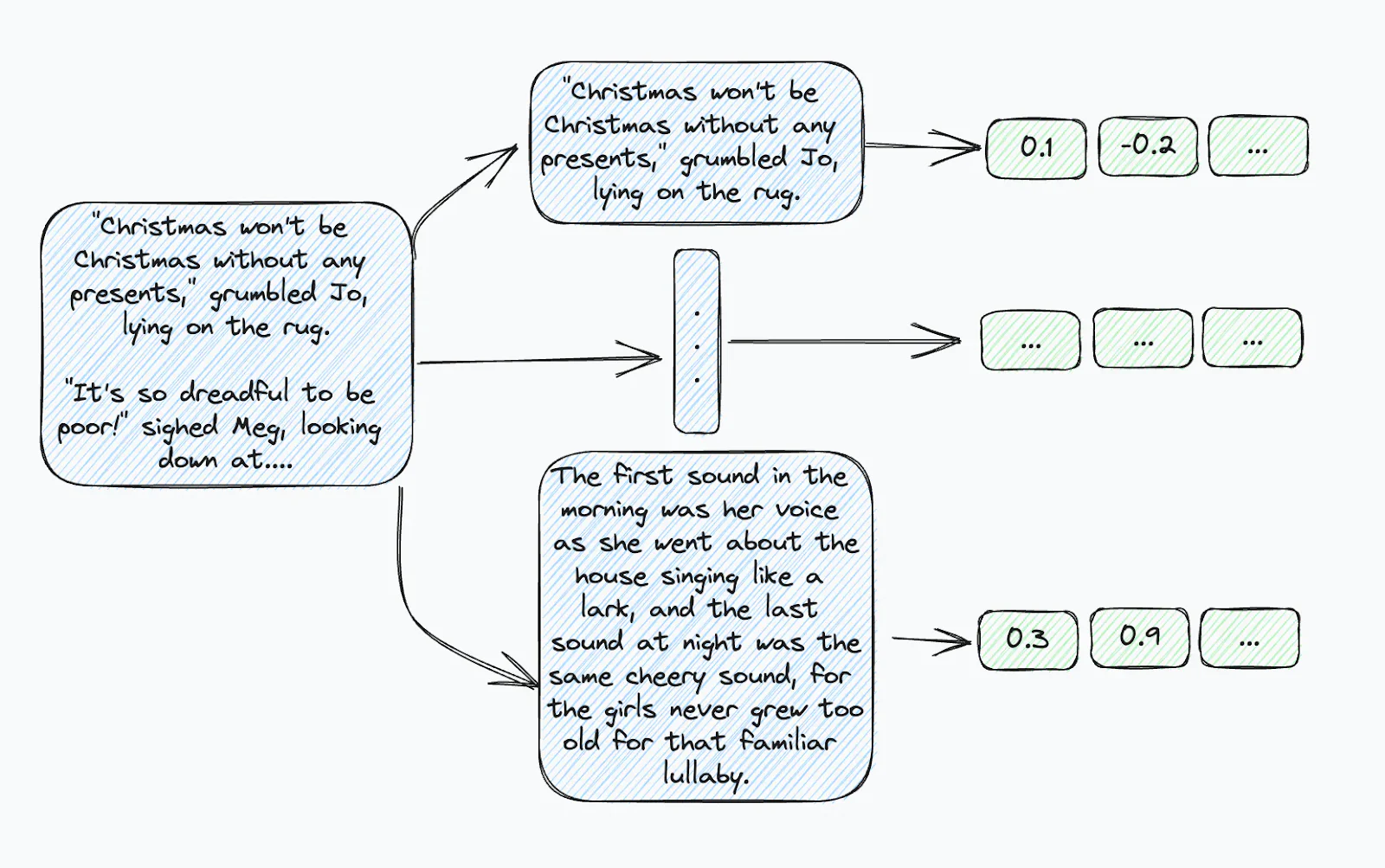
现在,比如说你有一个关于书《小妇人》第一章的单一元数据,你需要为每个句子索引这些信息数据。
Lucene 的 “join” 功能是 Elasticsearch nested 字段类型的核心部分,提供了一个解决方案。这一功能使得在一个顶级文档中可以包含多个嵌套文档,允许跨嵌套文档进行搜索并随后与其父文档进行连接。那么,我们如何在 Elasticsearch 中为嵌套字段中的向量提供支持呢?
关键在于 Lucene 如何在搜索子向量段落时回到父文档。这里的平行概念是在 kNN 方法中关于预过滤与后过滤的讨论,因为连接的时机显著影响结果的质量和数量。为了解决这个问题,Lucene 的最新增强功能使得在搜索 HNSW 图时可以预先与父文档进行连接。
实际上,预连接确保在检索查询向量的 k 个最近邻居时,算法返回的是 k 个最近的文档而不是段落。这种方法在不复杂化 HNSW 算法的情况下使结果更多样化,只需要在每个存储的向量上增加最小的额外内存开销。
通过利用某些限制来提高效率,例如父文档和子文档的不相交集合以及文档 ID 的单一性。这些限制允许使用位集进行优化,快速识别父文档 ID。
有效地搜索大量文档需要在 Lucene 中投资于 nested 字段和 joins。这项工作帮助存储和搜索代表长文本中段落的密集向量,使得在 Lucene 中的文档搜索更加有效。总的来说,这些进步代表了在 Lucene 的向量数据库检索领域向前迈出了令人兴奋的一步。
暂时总结
客户正在使用 Elastic 的向量数据库和向量搜索技术构建下一代 AI 启用的搜索应用程序。例如,Roboflow 被超过 50 万名工程师使用,用于创建数据集、训练模型,并将计算机视觉模型部署到生产环境中。Roboflow 使用 Elastic 的向量数据库来存储和搜索数十亿个向量嵌入。
我们致力于使 Elasticsearch 和 Lucene 在每个版本发布时成为最好的向量数据库。我们的目标是让人们更轻松地搜索所需的内容。通过我们在这篇博客中讨论的一些投资,取得了显著的进步,但我们的工作还未完成!
说 AI 生态系统正在迅速发展实在是轻描淡写。在 Elastic,我们希望为开发人员提供最灵活和开放的工具,以跟上所有创新 —— 包括最近版本直至 8.13 和无服务器 (serverless).
想将 RAG 集成到你的应用程序中吗?想要尝试在向量数据库中使用不同的 LLMs 吗? 请查看我们在 Github 上的样例笔记本,例如 LangChain、Cohere 等,并参加即将开始的 Elasticsearch 工程师培训!

