
- 1【网络编程】Web服务器shttpd源码剖析——CGI支持实现
- 2Llama3-8B基于peft+trl进行SFT监督微调(命令行模式)_trl 与 sfttrainer 指令
- 3MySQL高效运行的秘密:BufferPool缓存机制深度剖析!_bufferpool的锁
- 4[程序员必会] idea操作git,commit/add/push/pull/merge/rebase,合并代码,回滚代码等详细教程_idea中如何提交合并代码
- 5git for windows 下载速度慢?_git update-git-for-windows 下载很慢
- 6前端本地记住密码、存密码 、加密_前端保存账号密码加密
- 751单片机 蜂鸣器播放音乐_单片机蜂鸣器播放音乐代码
- 8Kotlin 集合操作汇总_kotlin集合操作
- 9【软考高项】一、信息化发展之信息与信息化
- 10【Git】从0到1-搞定Git_0到1玩转git
UNet++ 理解
赞
踩
一、结构介绍
-
论文引言翻译:为了满足医学图像更精确分割的需求,我们提出了一种新的基于嵌套和密集跳跃连接的分割架构unet++。我们的架构背后的基本假设是,当来自编码器网络的高分辨率特征图在与来自解码器网络的相应语义丰富的特征图融合之前逐渐丰富时,该模型可以更有效地捕获前景对象的细粒度细节。我们认为,当来自解码器和编码器网络的特征映射在语义上相似时,网络将更容易处理学习任务。这与U-Net中常用的普通跳过连接形成对比,后者直接将高分辨率特征图从编码器快速推进到解码器网络,从而导致语义上不同的特征图融合。根据我们的实验,建议的架构是有效的,在U-Net和宽U-Net上产生了显着的性能增益。
-
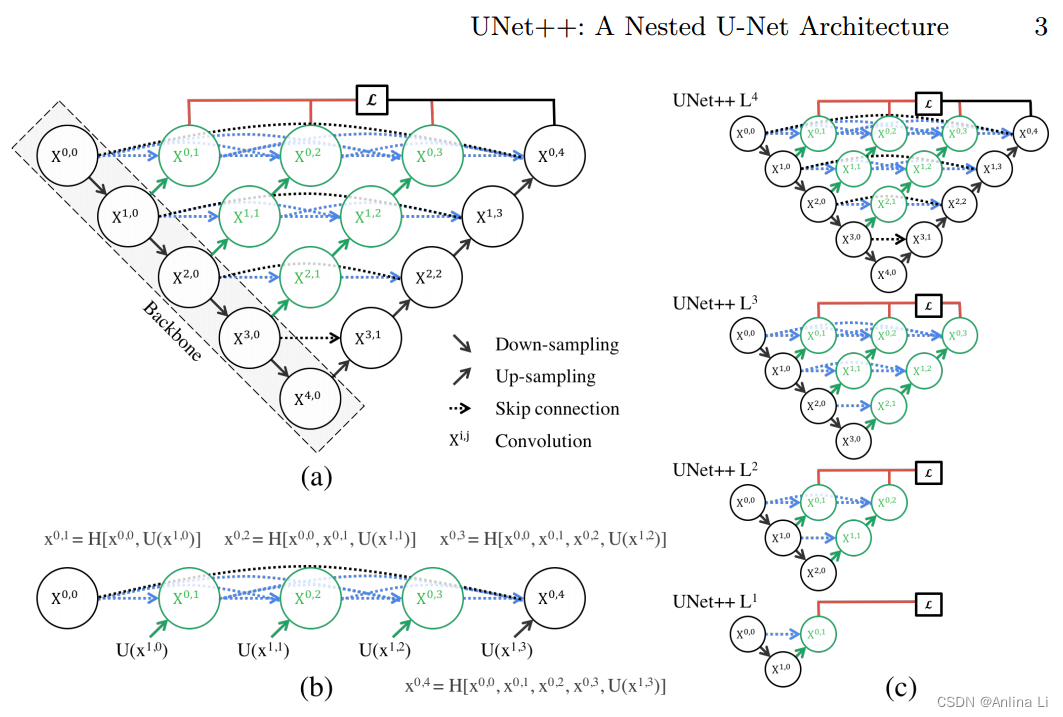
图1:(a) UNet++由编码器和解码器组成,它们通过一系列嵌套的密集卷积块连接在一起。unnet++背后的主要思想是在融合之前弥合编码器和解码器的特征映射之间的语义差距。例如,(X0;0,X1;3)之间的语义间隙使用具有三个卷积层的密集卷积块来桥接。在图形摘要中,黑色表示原始U-Net,绿色和蓝色表示跳跃路径上的密集卷积块,红色表示深度监督。红、绿、蓝三色组件将unet++和U-Net区分开来。(b) unet++的第一次跳跃路径的详细分析。©如果在深度监督下训练,unet++可以在推理时被修剪。
-
图a展示了UNet++的一个总体的概述。我们可以看到UNet++是由一个编码的子网络或骨干开始的,然后跟随了解码的子网络。UNet++和U-Net(黑色部分)不同的是重设计的跳跃路径(绿色和蓝色部分),重设计的跳跃路径连接了两个子网络,同时也利用了深度监督(红色部分)。
二、创新点与疑惑问题
1. 重设计跳跃路径
- 原本的跳跃连接是编码子网络的高分辨率特征图和解码子网络相对应的上采样输出相叠加,作者认为这会产生语义鸿沟。(语义鸿沟:我的理解是encoder最初的卷积得到的feature map表示的是低维的特征,对应尺寸的decoder的feature map 则已经经过了数次卷积,不是一个尺度的特征,U-Net中进行long-skip的融合会丢失一些信息。)
- 作者提出一种假设,把高分辨率的特征图和相应语义的特征图相融合的模型可以捕捉更多细节,同时可以使优化器完成一个简单的优化任务,所以重设计了一系列nested(嵌套的),dense(密集的) skip pathways(跳跃路径),抓取不同层次的特征通过叠加的方式整合,加入了更浅的U-Net,使得融合时的feature map尺度差异更小。(仅有长连接,梯度无法回传,只有短连接又失去了长连接的作用——长连接联系了输入图像的很多信息,有助于还原降采样所带来的信息损失,所以作者提出了长连接和短连接相结合的方法)
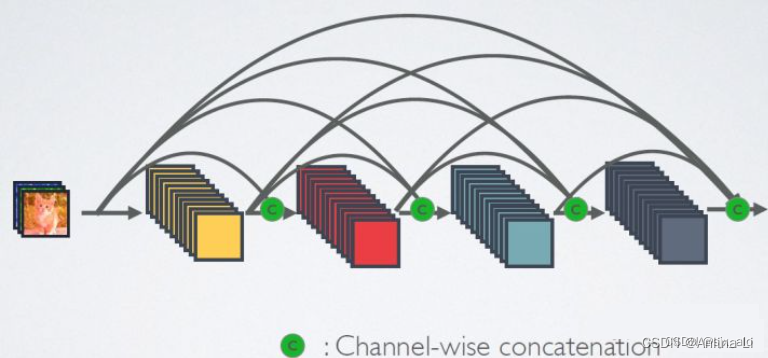
2. 密集连接
DenseNet网络与Resnet、GoogleNet类似,都是为了解决深层网络梯度消失问题的网络。
- Resnet从深度方向出发,通过建立前面层与后面层之间的“短路连接”或“捷径”,从而能训练出更深的CNN网络。
- GoogleNet从宽度方向出发,通过Inception(利用不同大小的卷积核实现不同尺度的感知,最后进行融合来得到图像更好的表征)。
- DenseNet从特征入手,通过对前面所有层与后面层的密集连接,来极致利用训练过程中的所有特征,进而达到更好的效果和减少参数。
3. 深度监督
我们提出在UNet ++中使用深度监督,使模型可以在两种模式下运行:
- 精准模式:对所有分割分支的输出取均值
- 快速模式:最终分割图从其中一个分支中选择,这个选择决定了模型修剪的程度和速度。
为什么可以剪枝?
-
因为在深监督的过程中,每个子网络的输出都其实已经是图像的分割结果了,所以如果小的子网络的输出结果已经足够好了,我们可以随意的剪掉那些多余的部分了。
-
在测试的阶段,由于输入的图像只会前向传播,扔掉这部分对前面的输出完全没有影响的,而在训练阶段,因为既有前向,又有反向传播,被剪掉的部分是会帮助其他部分做权重更新的。测试时,剪掉部分对剩余结构不做影响,训练时,剪掉部分对剩余部分有影响。
如何剪枝?剪枝好处?
-
将数据集分成训练集和验证集,根据子网络在验证集的结果来决定剪多少,剪枝越多参数越少,在不影响准确率的前提下,剪枝可以降低计算时间。
-
L1只有0.1M,而L4有9M,也就是理论上如果L1的结果我是满意的,那么模型可以被剪掉的参数达到98.8%。不过根据我们的四个数据集,L1的效果并不好。但是其中有三个数据集显示L2的结果和L4已经非常接近了,也就是说对于这三个数据集,在测试阶段,我们不需要用9M的网络,用半M的网络足够了。
-
剪枝应用最多的就是在移动手机端了,根据模型的参数量,如果L2得到的效果和L4相近,模型的内存可以省18倍。还是非常可观的数目。
三、总结
- UNet++在跳跃路径内有卷积层,搭建了编码特征图和解码特征图之间的语义鸿沟(semantic gap)
- UNet++在跳跃路径上有密集的跳跃连接,这改善了梯度流
- UNet++还有深度监督,能够进行模型的修剪和改进,或者在最坏的情况下达到与仅使用一个损耗层相当的性能
详细解释:
- 密集连接:DenseNet,这一层的输入是前面几层的输出的拼接
- 深度监督:在神经网络前向传播过程中有隐藏层神经元(中间卷积)对中间卷积进行分割结果的最终预测,得到的分割图像,这是一个对中间过程的监督,也就是深度监督
- 重设计跳跃路径:金字塔结构。黑色部分是原始UNet,中间加了绿色和蓝色部分,外边缘加了红色部分。绿色是密集连接的卷积,接受之前所有的输入,进行卷积。蓝色部分是应对绿色部分密集连接的传递方向。红色部分是深度监督,一条红色线出来的是一个深度监督的结果,代表一个金字塔级别。
- 剪枝:仅在快速模式下进行剪枝。c图得到了四个金字塔级别的监督结果,如果2比起4没有差多少,那么2后的全部进行剪枝。
参考文章
精读论文UNet++: A Nested U-Net Architecture for Medical Image Segmentation(附翻译)_unet++原论文-CSDN博客

