
- 1iOS 开发 Guideline 4.3 - Design - Spam
- 2Java 数组|链表实现栈数据结构_java以数组 链表存储栈中元素
- 3(二)Stable Diffussion 图生图模块-换头发颜色_stable diffusion 换发型
- 4C# 网络通信调试助手 (内有串口、TCP、UDP、http服务)_c# tcp调试助手
- 52.1 Vision-Language Pre-Training for Multimodal Aspect-Based Sentiment Analysis
- 6arduino uno R3驱动直流减速电机(蓝牙控制)_drv8833 arduino
- 7【深度学习目标检测】二十四、基于深度学习的疲劳驾驶检测系统-含数据集、GUI和源码(python,yolov8)_疲劳驾驶数据集
- 8经典对比学习模型及原理探索总结
- 9【已解决】pip安装 win32gui 报错 No module named ‘win32.distutils.command‘_pip install win32gui报错
- 10JBuilder2005实战JSP之日志和部署
astype强制转换不管用_用Python做数据分析的基本步骤(持续修改更新)
赞
踩

一、环境搭建
数据分析最常见的环境是Anaconda+Jupyter notebook
二、导入包
2.1数据处理包导入
- import numpy as np
- import pandas as pd
注:numpy是Numerical Python的简称,是一个科学计算的包,可用来矩阵运算,处理线性代数的常见问题。
pandas是panel data和data analysis的组合词,原来是用来处理计量经济学面板数据的工具,可以用来数据对齐、切割、取片、查重、去空等一系列操作。
2.2画图包导入
- import matplotlib.pyplot as plt
- import missingno as msno
- import seaborn as sns
- sns.set()
- sns.set_style('whitegrid', {'font.sans-serif':['simhei', 'Arial']})
注:matplotlib是常见的绘制图表的工具,seaborn是它的加强版,missingno是缺失值可视化处理的工具,sns.set()设置画图空间为 Seaborn 默认风格。后面的代码为处理中文字体。
2.3日期处理包导入
- import calendar
- from datetime import datetime
2.4jupyter notebook绘图设置
- %matplotlib inline
- %config InlineBackend.figure_format="retina"
注:%matplotlib inline是jupyter notebook里的命令,意思是将那些用matplotlib绘制的图显示在页面里而不是弹出一个窗口。
在分辨率较高的屏幕(例如 Retina 显示屏)上,notebook 中的默认图像可能会显得模糊,可用%config InlineBackend.figure_format="retina"来呈现分辨率较高的图片。
三、读取数据
- data = pd.read_csv(r"D:0工作数据集train_users_2.csv ")
- data = pd.read_excel(r" D:0工作excel6.xlsx ")
注:读取csv格式选第一种,读取excel表选第二种,“”内填文件所在位置。Excel只能存储十万多行数据,而csv(逗号分隔值文件格式)则能存储上亿行数据,所以数据分析中多以csv格式保存数据。
文件地址在文件的属性的对象名称中。
四、数据预览
1.数据集大小
Data.shape #输出列和行2.查看随便几行或前几行或后几行
- data.sample(5)
- data.head(5)
- data.tail(5)
3.查看数据类型
data.dtypes #会输出字段和字段类型4.查看数据的数量、无重复值、平均值、最小值、最大值等
- data.describe()
- data. describe(include='object')
5.查看字段名、类型、空值数为多少
data.info()五、数据处理
在数据的处理过程中,一般都需要进行数据清洗工作,如数据集是否存在重复,是否存在缺失,数据是否具有完整性和一致性,数据中是否存在异常值等。
1.把需要的字段挑选出来。
data.columns #看一下数据集的所有字段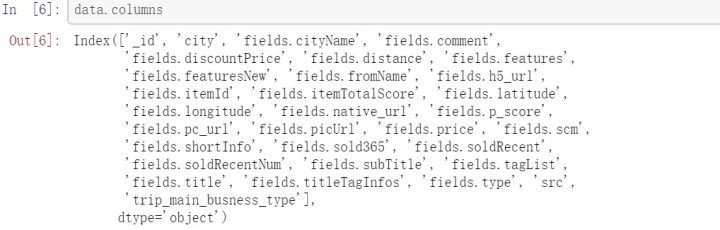
data.iloc[50] #随便挑一行看看数据的大致情况,以决定取舍哪些字段
- sample_data=['city', 'fields.comment', 'fields.discountPrice']
- data = data[col_keep] #选取想要的字段
2.数据类型转换
使用astype()函数
- data['fields.discountPrice'] =data['fields.discountPrice'].astype(float)
- data['fields.price']=data['fields.price'].astype(float)
- data['fields.soldRecentNum']=data['fields.soldRecentNum'].astype(int)
3.日期段数据处理。
如果给的数据是2020-01-01 05:20:15格式,那么可以采取下面的代码从"datetime"字段中,提取date、hour、weekday、month。
3.1提取“date”
data["date"] = data.datetime.apply(lambda x: x.split()[0])注:就是把它按空格切成两段,然后取第一段。
lambda函数也叫匿名函数,即没有具体名字的函数,它允许快速定义单行函数,用在任何需要函数的地方,这区别于def。
apply函数,返回括号中的参数。
split(sep),sep表示用于分割的字符。它通过指定字符进行切片。
3.2提取"hour"
data["hour"]=data.datetime.apply(lambda x: x.split()[1].split(":")[0])注:就是先把它按空格切成两段取第二段,再按分号切,取第一段。
3.3提取"weekday"
- datestr=data.datetime[1].split()[0]
- data["weekday"]=data.date.apply(lambda datestr:calendar.day_name[datetime.strptime(datestr,"%Y-%m-%d").weekday()])
注:按空格把时间分成两段取第一段,把它变成合适的时间格式,得出是星期几
通过datetime.strptime()函数把字符串转化为datetime格式
%Y 四位数的年份表示(000-9999)%m 月份(01-12)%d 月内中的一天(0-31)
weekday()函数返回的是当前日期所在的星期数。
3.4提取"month"
data["month"]=data.date.apply(lambda datestr:calendar.month_name[datetime.strptime(datestr,"%Y-%m-%d").month])4.变量映射处理
数据集中"season","weather"字段属于定性变量,将定性变量的数值取值,做映射处理,转化为描述性取值。
例如季节映射处理:
data[“season_label”]=data.season.map({1:”Spring”,2:”Summer”})5.重复值处理
- data.duplicated() #按行查看缺失值
- data.duplicated().sum() #缺失值总数
- data.duplicated([‘a’]) #查看a列是否有重复值
- any(data.duplicated())
- data.drop_duplicates() #去掉重复值
- df.drop(col_names_list, axis=1, inplace=True) #删除不需要的某列
- data.drop_duplicates(‘a’)
6.缺失值处理
6.1使用missingno可视化地查看缺失值
- msno.matrix(data,figsize=(12,5)) #matrix是矩阵的意思
- msno.bar(data) #条形图
- msno.heatmap(data,figsize=(16,7))
- #heatmap热度图,当变量1和变量2的系数都是1,代表当变量1缺失,变量2也缺失。
6.2使用isnull()函数继续查看缺失值
- data.isnull() #查看所有值是否为空值
- data.city.isnull() #查看city行是否为空值
- data.isnull().any() #判断各个列是否为空值
- data[data.isnull().values==True] #可以只显示缺失值的行列,判断缺失值的位置
- data.isnull().sum().sort_values(ascending=False) #将各个字段的空值总数统计出来,倒序排列
- data.isnull().any(axis=1).sum()/data.shape[0] #缺失值所占比例
6.3缺失值处理的方法
缺失值处理的三种方法:直接使用含有缺失值的特征;删除含有缺失值的特征(该方法在包含缺失值的属性含有大量缺失值而仅仅包含极少量有效值时才是有效的);缺失值补全。
6.3.1删除法
data.dropna(axis=0, how='any', subset=None, inplace=False)注:axis:表示轴向。默认为0,表示删除所有含有空值的行。
how:表示删除的方式。默认为any。为any的时候,表示只要存在缺失值就删除。为all的时候,表示全部是缺失值才能删除。
subset:表示删除的主键,默认为全部。
inplace:表示是否对原数据进行操作。默认为False,不对原数据操作。
6.3.2定值替换法
data.fillna(value=None,method=None,axis=None,limit=None)value:表示传入的定值。可为某一个值,dict,Series,DataFrame。无默认。
method:此参数存在,则不传入value。表示使用前一个非空值或后一个非空值进行缺失值填补。无默认。
axis:表示轴向。
limit:表示插补多少次。默认全量插补。
- data.fillna(1111) #所有空值都填入1111
- data.fillna({'一班':-60,'二班':-70,'三班':-80}) # 分别填补
- data.fillna(df.mean()) # 将每一列的空值插补为该列的均值
- data.fillna(method = 'ffill') # 用上一个数值进行填补
6.3.3插补法
删除法简单易行,但是会引起数据结构变动,样本减少;而替换法使用难度较低,但是会影响数据的标准差,导致信息量变动。在面对数据缺失问题时,除了这两种方法之外,还有一种常用的方法——插值法。
常见的缺失值补全方法:均值插补、同类均值插补、建模预测、高维映射、多重插补、极大似然估计、压缩感知和矩阵补全。
线性插值是一种相对来说较为简单的插值方法,它针对已知的值求出线性方程,通过求解线性方程得到缺失值。
- from scipy.interpolate import interp1d # 注意这里是数字1,不是l
- num = df['一班'][df['一班'].notnull()] # 不为空的数据
- LinearInsValue1 = interp1d(linear.index, linear.values, kind='linear')
- LinearInsValue1(df['一班'][df['一班'].isnull()].index)
五、可视化
5.1相关性分析,画热力图
correlation=data[["a1","a2","a3""a4","a5"]].corr()注:corr()函数,分析这data数据集中这几个变量之间的相关关系,得到相关矩阵。应先把非数值型字段通过映射处理转换为数值型字段
DataFrame.corr(method='pearson', min_periods=1)
参数说明:method:可选值为{‘pearson’,‘kendall’,‘spearman’}
pearson:Pearson相关系数来衡量两个数据集合是否在一条线上面,即针对线性数据的相关系数计算,针对非线性数据便会有误差。
kendall:用于反映分类变量相关性的指标,即针对无序序列的相关系数,非正太分布的数据。
spearman:非线性的,非正太分析的数据的相关系数
min_periods:样本最少的数据量
返回值:各类型之间的相关系数DataFrame表格。
- mask = np.array(correlation) #将关系矩阵存入数组中
- mask[np.tril_indices_from(mask)] = False #返回下三角的索引
- fig,ax= plt.subplots() #将plt.subplots()函数的返回值赋值给fig和ax两个变量,fig即figure
- fig.set_size_inches(20,10) #设置图形尺寸
- sns.heatmap(correlation, mask=mask,vmax=.8, square=True,annot=True)
- plt.show()
5.2箱型图
箱形图最大的优点就是不受异常值的影响(异常值也称为离群值),可以以一种相对稳定的方式描述数据的离散分布情况。
基本代码如下:
- fig=plt.figure(figsize=(6,4)) #设置画布
- sns.boxplot(data=data1['count']) #设置箱型图数据
- plt.title('This is my title')
- plt.ylabel('aaaaaa') #设置y坐标轴
- sns.despine(bottom=True)
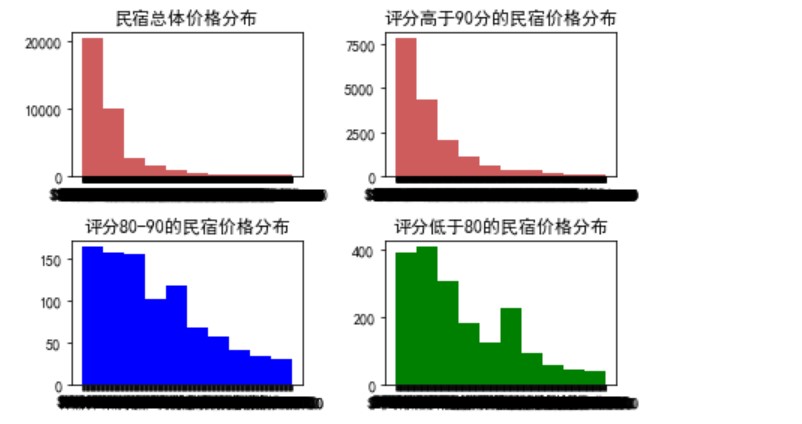
5.3多个直方图对比分析
直方图(Histogram),又称质量分布图,是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据类型,纵轴表示分布情况。
直方图是数值数据分布的精确图形表示。这是一个连续变量(定量变量)的概率分布的估计,并且被卡尔·皮尔逊(Karl Pearson)首先引入。它是一种条形图。为了构建直方图,第一步是将值的范围分段,即将整个值的范围分成一系列间隔,然后计算每个间隔中有多少值。这些值通常被指定为连续的,不重叠的变量间隔。间隔必须相邻,并且通常是(但不是必须的)相等的大小。
可以先看某变量的所占比例,如某件商品购买的男女比例。
np.round(fans_num/fans_num.sum()*100,2) 
代码示例如下:
- ax =plt.subplot(221) #布局在第一行的左图
- data1=data.price
- plt.hist(data1,color='indianred') #设置直方图要填入的数据和颜色
- ax.set_title("民宿总体价格分布") #设置标题
-
- ax=plt.subplot(222) #布局在第一行的右图
- data2 = data[data['review_scores_rating']>90].price
- plt.hist(data2,color='indianred')
- ax.set_title("评分高于90分的民宿价格分布")
-
- ax=plt.subplot(223) #布局在第二行的左图
- data3 = data[(data['review_scores_rating']<90)
- &(data['review_scores_rating']>80)].price
- plt.hist(data3,color='blue')
- ax.set_title("评分80-90的民宿价格分布")
-
- ax=plt.subplot(224) #布局在第二行的右图
- data4 = data[data['review_scores_rating']<=80].price
- plt.hist(data4,color='green')
- ax.set_title("评分低于80的民宿价格分布")
- plt.tight_layout() # tight_layout会自动调整子图参数,使之填充整个图像区域。

5.4地图分析
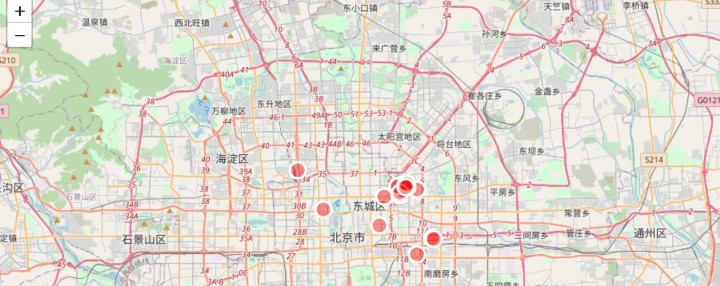
Folium是Python中功能强大的数据可视化库,主要用于帮助人们可视化地理空间数据。使用Folium,只要知道其纬度和经度值,就可以创建世界上任何位置的地图。此外,Folium创建的地图本质上是交互式的,因此可以在渲染地图后放大和缩小,这是一个非常有用的功能。
代码示例如下:
- import folium #导入库,可使用anaconda安装
- latitude =39.87 #设置所在城市的维度,这里是北京的维度
- longitude =116.51 #设置经度
- limit=20
- data =data.iloc[0:limit,:] #iloc是位置索引,取出前20行
- incidents =folium.map.FeatureGroup() #FeatureGroup会处理来自子图层的鼠标事件和自定义事件
- for lat,lng,in zip(data.latitude,data.longitude): #for x ,y in zip(listx,listy): x和y会组成一个元组,一起运行
- incidents.add_child(
- folium.CircleMarker( #为地图添加圆圈标记部件
- [lat, lng],
- radius=10, #圆圈半径
- color='white', #用于控制圆圈的颜色,默认为蓝色
- fill=True, #当为True时,圆圈内部将被填充上色彩,默认不填充
- fill_color='red', #圆圈内部的填充色
- fill_opacity=0.4 #圆圈内部透密度
- )
- )
- #有些时候我们希望我们的地图不光是死板的展示信息,
- #还能根据鼠标的点击事件,来唤起更多的信息展示内容,
- #即为地图添加更多的子内容,我们使用add_child()来完成各种子内容的添加
- san_map = folium.Map(location=[latitude, longitude], zoom_start=10)
- san_map.add_child(incidents)
官方文档:https://python-visualization.github.io/folium/
官方示例:
https://nbviewer.jupyter.org/github/python-visualization/folium/tree/master/examples/nbviewer.jupyter.org参考案例:https://www.cnblogs.com/feffery/p/9282808.html
未完,待修改
注:部分代码取材于
半砚墨:python数据分析实例:共享单车租用影响因素探索zhuanlan.zhihu.com


