
- 1docker错误 download failed after attempts=6 :net/http :tls handshake timeout_docker: error pulling image configuration: downloa
- 2[附源码]java+ssm计算机毕业设计医院药品进销存系统【源码+数据库+LW+部署】_公立医院的进销存数据需要本地部署吗?
- 3Netbeans的编译和打包ant脚本----英文版_netbeans ant
- 4操作系统内核概念
- 5关于计算机如何区分有符号数与无符号数_有符号数和无符号数的区别
- 6mybatis动态SQL对数据库执行增删改查学习笔记_getusercountbyroleid为根据角色id查询该角色下是否有用户信息。返回该角色id下的
- 7西南科技大学数字电子技术实验一(数字信号基本参数与逻辑门电路功能测试及FPGA 实现)FPGA部分_大学数电实验
- 8SAP HR 工资核算异常的一些处理方式_sap 重新入职人员工资核算 报错期间开始 2023.10.01 早于最早可能的 ra 运行日期
- 9Windows 源码编译 MariaDB_mariadb odbc 驱动源码 windows 下 如何编译
- 10报错:The installer has encountered an unexpected error installing this package 使用超管运行安装文件
【基础知识】FPN分割代码分析_self.reduce4 = conv1x1(2048, 256)
赞
踩
转载:语义分割网络 - FPN 结构及代码
另一篇写的也很好,有识别中ROI的讲解 从代码细节理解 FPN (Feature Pyramid Networks for Object Detection)
FPN用于语义分割
FPN虽然是一个特征提取网络,但之前很多都是用于目标检测的。在何凯明的全景分割论文中,就用了FPN进行语义分割,大致结构如下:
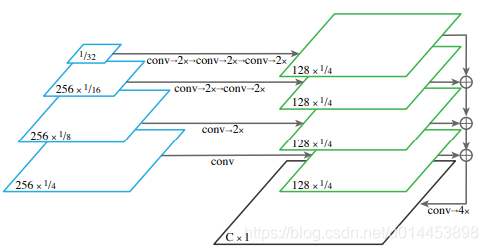
蓝色的框是卷积后的特征图。绿色框部分就相当于predit的部分。
可以看到,当用FPN做语义分割时,每个特征图(蓝色框)都会进行(卷积+两倍上采样)操作,提升到原图的1/4分辨率,再加在一起,最后再通过4倍上采样,提升到与原图相等的分辨率。
(上图的256和128表示特征图的通道数,分数1/4,1/8等等表示当前特征图缩小为原图的几分之几,C代表总类别数,x1表示与原图大小是相等的)
最后返回一个与原图大小相等的,通道数为类别数的特征图。
以上from: pytorch 利用FPN(特征金字塔网络)进行语义分割(训练代码+预测代码)
附上文代码:https://github.com/Andy-zhujunwen/FPN-Semantic-segmentation
以下from: https://zhuanlan.zhihu.com/p/82746292
初识 FPN
FPN 全称 Feature Pyramid Network,翻译过来就是特征金字塔网络。何为特征金字塔,深度卷积神经网络(DCNN)提取的不同尺度特征组成的金字塔形状。本文提出了一种新型的特征融合方式,虽然距离论文提出的时间比较久了,但直到现在该结构仍较常用,尤其是在检测小目标时值得一试。
本篇论文的目的是为了合理利用特征金字塔中不同尺度的语义信息。实际上在本篇文章之前,已经有很多特征融合的方式,本文开篇就介绍了各种多尺度特征的融合方式:

- (a) Featurized image pyramid,为了获取不同尺度的特征,这种方式需要将同一张图片的不同尺寸分别输入网络,分别计算对应的 feature map 并预测结果,这种方式虽然可以提升预测精度但计算资源消耗太大,在实际工业应用中不太现实。
- (b) Single feature map,分类任务常用的网络结构,深层特征包含了丰富的语义信息适用于分类任务,由于分类任务对目标的位置信息并不敏感所以富含位置信息的浅层特征没用被再次使用,而这种结构也导致了分类网络对小目标的检测精度并不高。
- (c) Pyramid feature hierarchy,SSD 的多尺度特征应用方式,在不同尺度的特征上进行预测。关于这种方式作者在文中专门说了一段儿,意思是 SSD 中应用的浅层特征还不够"浅",而作者发现更浅层的特征对检测小目标来说非常重要。
- (d) Feature Pyramid Network,本篇的主角,一种新的特征融合方式,在兼顾速度的同时提高了准确率,下面会介绍细节。
- (e) U-net 所采用的结构,与 (d) 的整体结构类似,但只在最后一层进行预测。
FPN 结构细节
FPN 的结构较为简单,可以概括为:特征提取,上采样,特征融合,多尺度特征输出。FPN 的输入为任意大小的图片,输出为各尺度的 feature map。与 U-net 类似, FPN 的整个网络结构分为自底向上 (Bottom-Up) 和自顶向下 (Top-Down) 两个部分,Bottom-Up 是特征提取过程,对应 Unet 中的 Encoder 部分,文中以 Resnet 作为 backbone,其中使用的 bottleneck 结构:

Top-Down 将最深层的特征通过层层的上采样,采样至与 Bottom-Up 输出对应的分辨率大小,与之融合后输出 feature map,融合方式为对应位置相加,而 Unet 采用的融合方式为对应位置拼接,关于两者的差异我之前在 Unet 这篇文章中提过,这里就不再赘述。在下图中放大的部分中,包含了 3 个步骤:1. 对上层输出进行 2 倍的上采样,2. 对 Bottom-Up 中与之对应的 feature map 的进行 1x1 卷积,以保证特征 channels 相同,3. 将上面两步的结果相加。
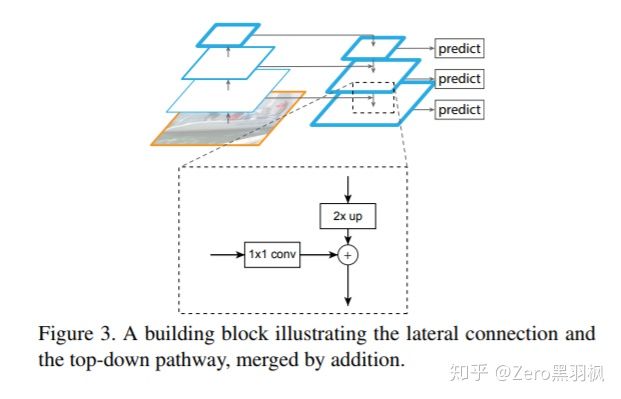
以上就是 FPN 的基本结构了,简单且有效,这也符合何凯明大神一贯的作风,下面介绍代码实现过程。
代码
FPN 结构比较简单且文中说明的很清楚,大家有空可以自己实现一下。下面是文章中对网络结构的叙述以及 Pytorch 版本的实现,欢迎留言讨论。
- Bottom-Up
This process is independent of the backbone convolutional architectures, and in this paper we present results using ResNets.
文中选择 Resnet 作为 Bottom-Up,直接把 torchvision 中的 Resnet 拿来用:
- self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
- self.bn1 = nn.BatchNorm2d(64)
- self.relu = nn.ReLU(inplace=True)
- self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
-
- # Bottom-up stages
- self.layer1 = self._make_layer(block, 64, layers[0], stride=1)
- self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
- self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
- self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
- Top layer
To start the iteration, we simply attach a 1×1 convolutional layer on C5 to produce the coarsest resolution map.
We set d = 256 in this paper and thus all extra convolutional layers have 256-channel outputs.
对 C5(layer4 的输出) 进行 1x1 的卷积确保特征金字塔的每一层都是 256 个 channels。
self.toplayer = conv1x1(2048, 256)- Top-Down
With a coarser-resolution feature map, we upsample the spatial resolution by a factor of 2 (using nearest neighbor upsampling for simplicity).
每次上采样的倍数为 2,且使用 nearest 插值。
F.upsample(x, size=(H,W), mode='nearest')The upsam3 pled map is then merged with the corresponding bottom-up map (which undergoes a 1×1 convolutional layer to reduce channel dimensions) by element-wise addition.
Bottom-Up 输出的 C2,C3,C4 都需要进行 1x1 的卷积确保特征金字塔的每一层都是 256 个 channels。
- self.laterallayer1 = conv1x1(1024, 256)
- self.laterallayer2 = conv1x1( 512, 256)
- self.laterallayer3 = conv1x1( 256, 256)
Finally, we append a 3×3 convolution on each merged map to generate the final feature map, which is to reduce the aliasing effect of upsampling.
最终还需要一个 3x3 的卷积才能得到最后的 feature map,此举是为了减小上采样的影响。
- # Final conv layers
- self.finalconv1 = conv3x3(256, 256)
- self.finalconv2 = conv3x3(256, 256)
- self.finalconv3 = conv3x3(256, 256)
至此,要用的基本模块都有了,那么整个前向传播的过程:
- def forward(self, x):
- # Bottom-Up
- c1 = self.relu(self.bn1(self.conv1(x)))
- c1 = self.maxpool(c1)
- c2 = self.layer1(c1)
- c3 = self.layer2(c2)
- c4 = self.layer3(c3)
- c5 = self.layer4(c4)
-
- # Top layer && Top-Down
- p5 = self.toplayer(c5)
- p4 = self._upsample_add(p5, self.laterallayer1(c4))
- p3 = self._upsample_add(p4, self.laterallayer2(c3))
- p2 = self._upsample_add(p3, self.laterallayer3(c2))
-
- # Final conv layers
- p4 = self.finalconv1(p4)
- p3 = self.finalconv2(p3)
- p2 = self.finalconv3(p2)
- return p2, p3, p4, p5

论文中是将 FPN 作为一个结构嵌入到 Fast R-CNN 等网络中来提升网络的表现,那么可否将 FPN 直接用于语义分割任务?答案是可以,一个思路是将 FPN 输出的所有 feature map 相加为 1 层,上采样至原图分辨率可得输出,也有不错的效果。
以上代码已经放在我的 github,欢迎 star:
https://link.zhihu.com/?target=https%3A//github.com/FroyoZzz/CV-Papers-Codes

