
- 1浅析Java虚拟机的垃圾回收机制(GC)_java gc垃圾回收机制
- 2软件行业 职位 英文简称_软测职位职称英文简称
- 3Mac如何安装brew_mac brew安装
- 4java二叉树的深度_Java实现二叉树的深度计算
- 5项目实战:一套基于SpringBoot+Vue+App的智能家居系统(含源码)_spring boot wifi模块 app
- 6【Docker】Docker Network(网络)
- 7win10创建python虚拟环境-virtualenv_virtualenvwrapper-win
- 8hive 、spark 、flink之想一想_hive spark flink
- 9Uniapp和原生aar混合使用初体验_uniapp aar
- 10TCP、UDP客户端
机器学习-Anomaly Detection_根据f1值或者查准率与查全率的比例来选择ε
赞
踩
Problem Motivation
异常检测(Anomaly detection)是机器学习算法的一个常见应用。这种算法的一个有趣之处在于:它虽然主要用于非监督学习问题,但从某些角度看,它又类似于一些监督学习问题。
假想你是一个飞机引擎制造商,当你生产的飞机引擎从生产线上流出时,你需要进行 QA
(质量控制测试),而作为这个测试的一部分,你测量了飞机引擎的一些特征变量,比如引擎运转时产生的热量,或者引擎的振动等等。

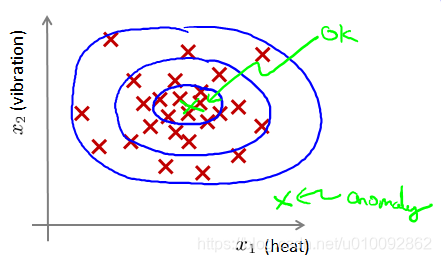
这里的每个点、 每个叉, 都是你的无标签数据。这样,异常检测问题可以定义如下:我
们假设后来有一天,你有一个新的飞机引擎从生产线上流出,而你的新飞机引擎有特征变量xtest。
给定数据集 x(1),x(2),…,x(m),我们假使数据集是正常的,我们希望知道新的数据 xtest 是不是异常的,即这个测试数据不属于该组数据的几率如何。我们所构建的模型应该能根据该测试数据的位置告诉我们其属于一组数据的可能性 p(x)。
这种方法称为密度估计,表达如下:
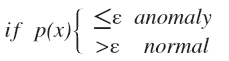
模型 p(x) =我们其属于一组数据的可能性
通过 p(x)<ε 检测非正常用户。
异常检测主要用来识别欺骗。例如在线采集而来的有关用户的数据,一个特征向量中可
能会包含如:用户多久登录一次,访问过的页面,在论坛发布的帖子数量,甚至是打字速度等。尝试根据这些特征构建一个模型,可以用这个模型来识别那些不符合该模式的用户。
再一个例子是检测一个数据中心,特征可能包含:内存使用情况,被访问的磁盘数量,
CPU 的负载,网络的通信量等。根据这些特征可以构建一个模型,用来判断某些计算机是不是有可能出错了。
Gaussian Distribution
高斯分布,也称为正态分布。
通常如果我们认为变量 x 符合高斯分布 x~N(μ,σ2)则其概率密度函数为:
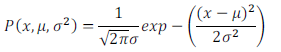
利用已有的数据来预测总体中的 μ 和 σ2 的计算方法如下:
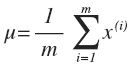
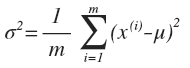
高斯分布样例:

