- 1【Docker】docker consul容器服务更新与发现
- 2数据结构之树_数据结构树叶
- 3Elasticsearch安装
- 4MATLAB算法实战应用案例精讲-【图像处理】三维重建(附MATLAB和python代码实现)_matlab体素法三维重构
- 5[Unity&精灵&对象]使用Instantiate,Resource.Load动态生成物体_(gameobject)instantiate(resources.load(
- 6openlayers 入门教程(十五):与 canvas、echart,turf 等交互_turfjs和openlayer
- 7OpenHarmony/HarmonyOS三方库使用指导_引用ohpm三方库的包依赖是在哪个配置文件中
- 8Docker 在容器中存储数据 - 使用 Device Mapper 存储驱动程序_使用storage-driver": "devicemapperdocker数据丢失
- 9SQLCoder-70b 成为领先的 AI SQL 模型_sqlcode 大模型训练
- 10ld 无法找到项目符号 链接失败_MacOS 链接特性:Two-Level Namespace
sql--索引使用规则_sql索引 or
赞
踩
参考:https://blog.csdn.net/baidu_37107022/article/details/77460464
https://blog.csdn.net/w1014074794/article/details/108806141


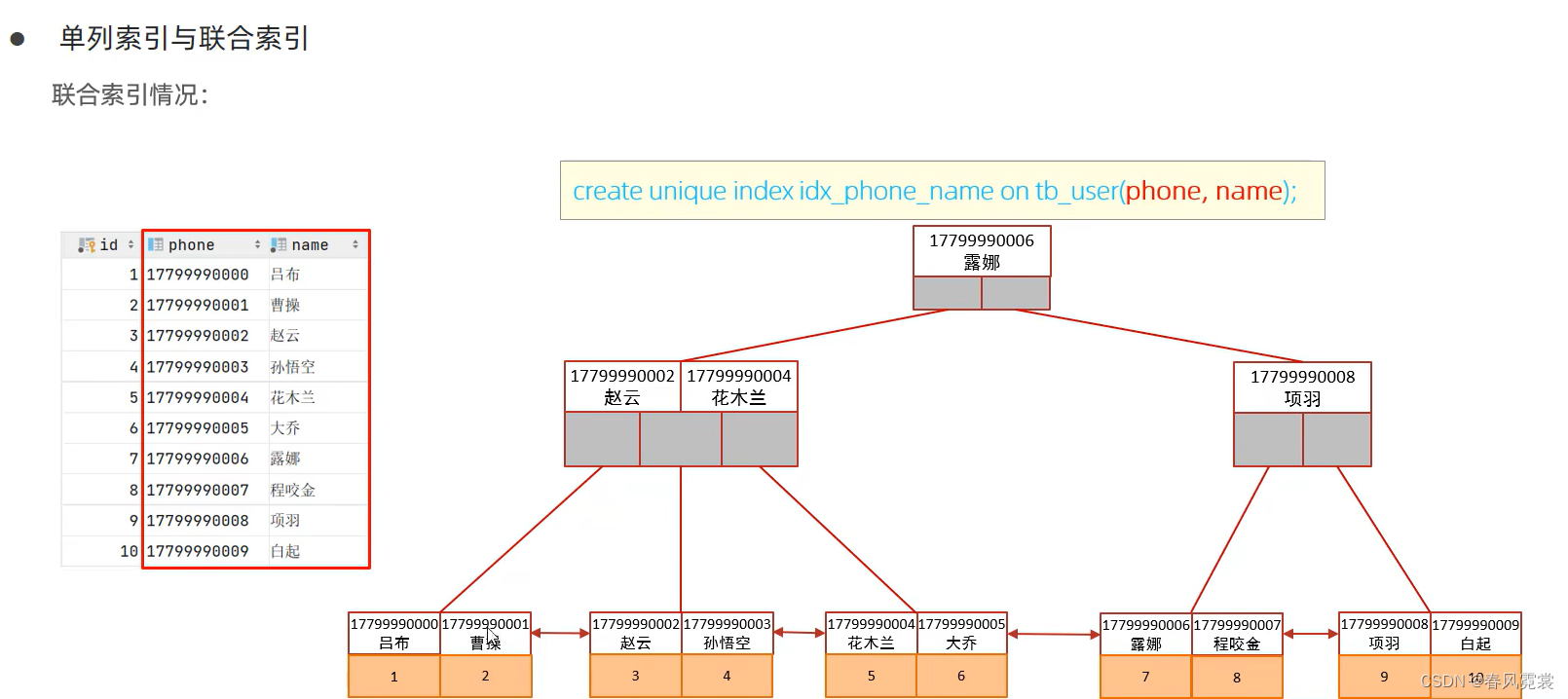
最左前缀法则(联合索引情况)
如果索引了多列(联合索引),要遵守最左前缀法则。最左前缀法则指的是查询从索引的最左列开始,并且不跳过索引中的列。
最左边的列必须存在,如果不存在,索引失效
如果跳跃某一列,索引将部分失效(后面的自动索引失效)
查询索引
show index from t_user
- 1

area_num和phone_num是联合索引:key_name相同,seq_in_index为1,2

范围查询(联合索引中)
联合索引中,出现范围(>,<),范围查询右侧的列索引失效
解决:业务情况下,尽量使用>=或者<=
索引列运算
不要再索引列上进行运算操作,索引将失效。

字符串不加引号
字符串类型字段使用时,不加引号,索引将失效
explain select * from where phone = 1343589
- 1
应该加上单引号:
explain select * from where phone = '1343589'
- 1
模糊查询
如果仅仅是尾部模糊匹配,索引不会失效。如果是头部模糊匹配,索引失效。
or连接的条件
用or分割开的条件,如果or前的列有索引,而后面的列没有索引,那么涉及索引都不会被用到。只有两侧都有索引时才会被用到
解决:or的两边用到的字段必须全部都要有索引
数据分布影响
如果mysql评估使用索引比全表更慢,则不使用索引。
比如如果差is null或is not null,当数据全是null,或大部分是null(都不是null,或大部分都不是null)时,会选择走全表扫描,因为会比走索引的效率还高
sql提示(同时有联合索引(复合索引)和单列索引)
当同时有联合索引(复合索引)和单列索引时,一般时有数据库默认选择的,但我们可以使用sql提示,让数据库明确走那个索引!
user index:提示使用某个索引
ignore index:提示不使用某个索引
force index :强制使用某个索引

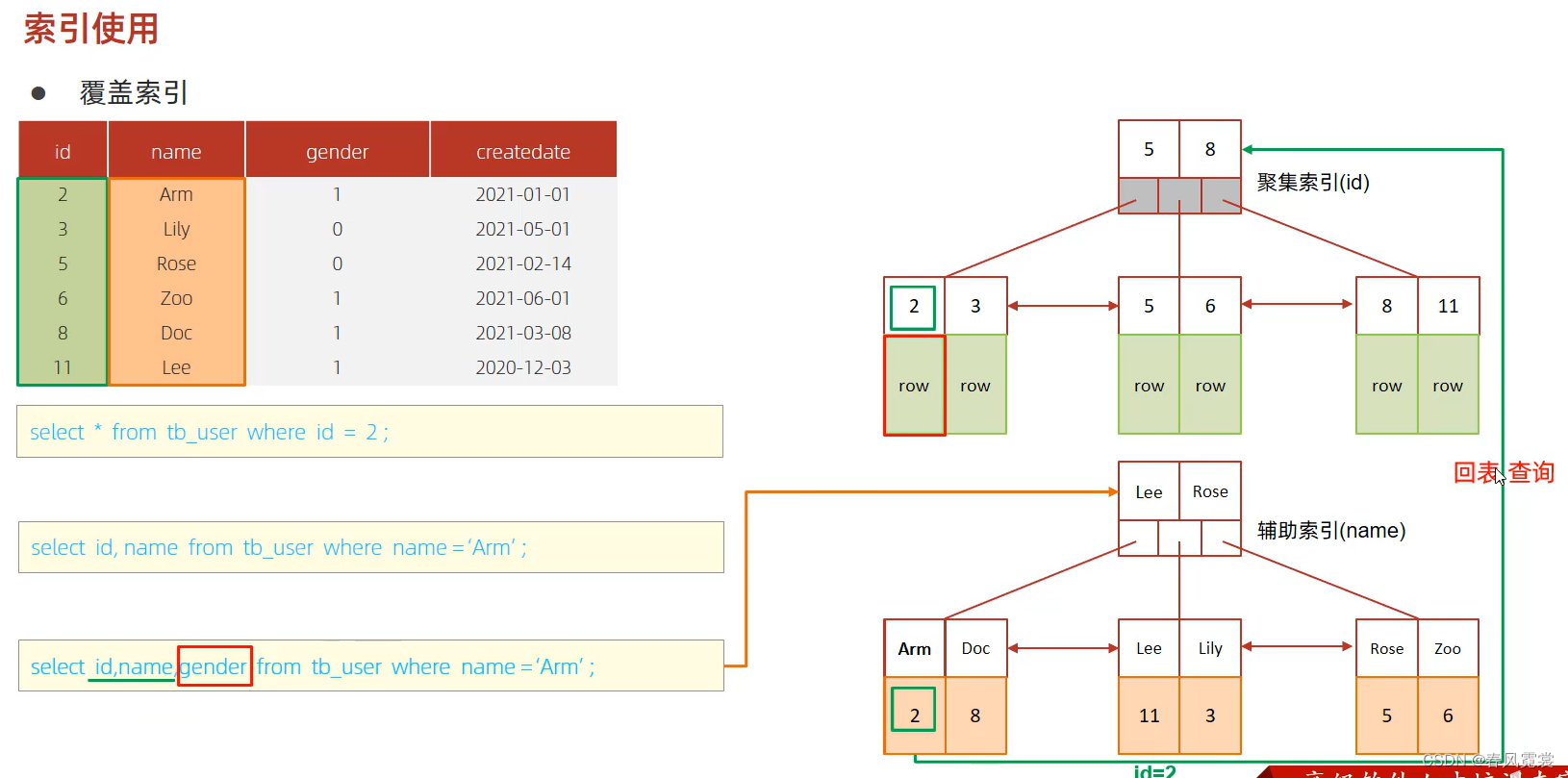
覆盖索引、回表查询
尽量使用覆盖索引(查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到),减少select。*
当覆盖索引(二级索引)中的索引列中没有要查询的字段时,就会回表查询(回到聚集索引查到一条完整信息)。
前缀索引
当字段类型为字符串(varchar,text等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO,影响查询效率。此时可以只将字符串的一部分前缀,建立索引,这样可以大大节约索引空间,从而提高索引效率。
语法:
create index index_name on table_name(column(n));
- 1
前缀的长度:
可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
select count(distinct email)/count(*) from tb_user;
select count(distinct substring(email,1,5))/count(*) from tb_user;
- 1
- 2
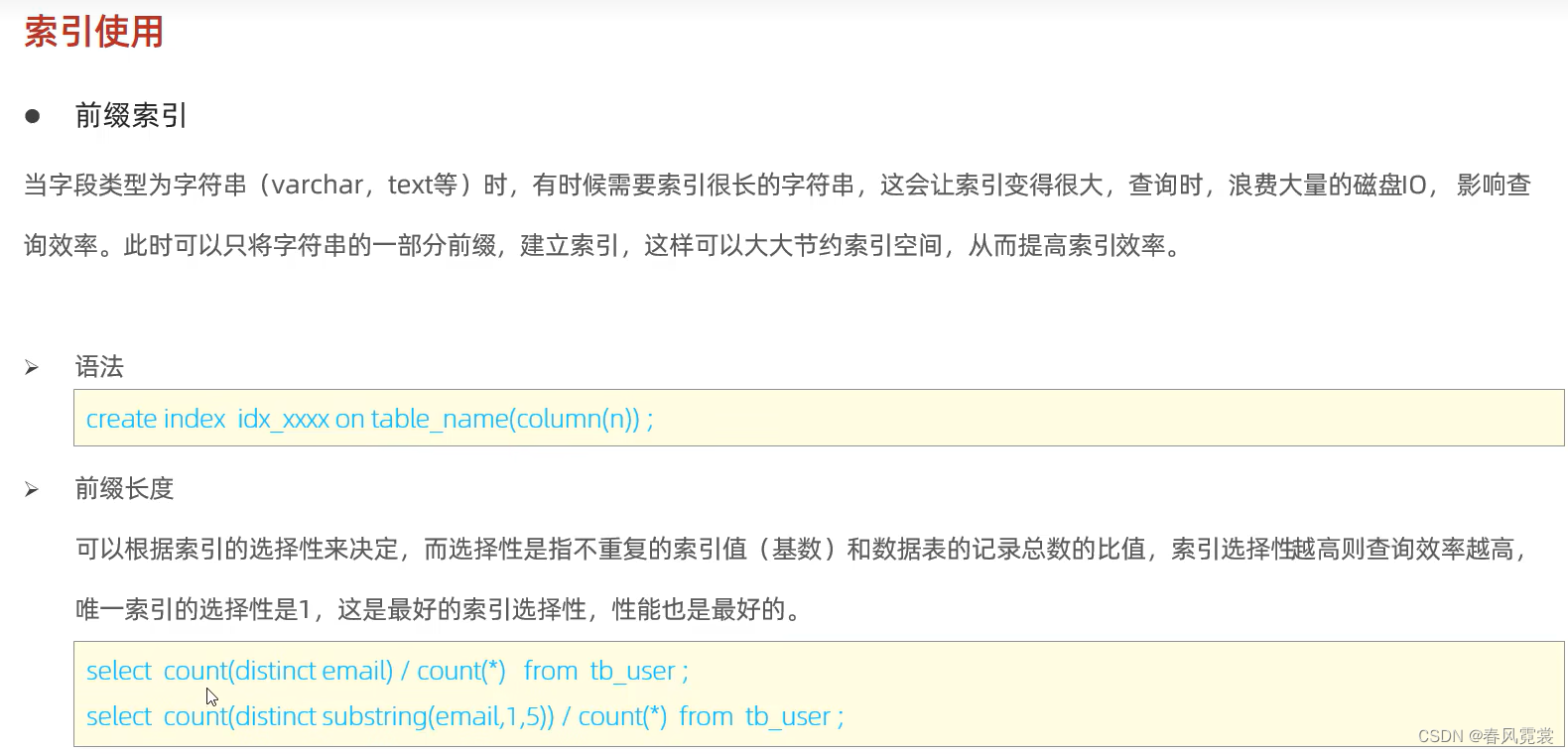
截取后该字段不重复的数量 / 该字段的总数 >0.95就比较好了
执行计划Extra为null时,走了回表查询:


单利索引、联合索引