
- 1魔百盒CM311-1a免拆机卡刷固件加+刷armbian装docker运行青龙面板
- 2基于YOLOv8深度学习的农作物幼苗与杂草检测系统【python源码+Pyqt5界面+数据集+训练代码】深度学习实战、目标检测
- 3海睿思分享 | 浅谈企业数据质量问题_数据中台中数据质量有哪些场景?
- 4技术速览|Meta Llama 2 下一代开源大型语言模型_llam2最大支持输入
- 5聊聊c#与Python以及IronPython
- 6NLP任务中常用的损失函数_nlp 损失函数分类
- 7图神经网络GAT最详细讲解(图解版)_gat网络
- 8计算机图形学 第10章 真实感图形_计算机制图是依据加色原则混合而获得的
- 9Mac系统 Redis下载与启动_mac redis下载
- 10error: src refspec master does not match any. 错误处理办法
使用Ollama和Go基于文本嵌入模型实现文本向量化
赞
踩
基于RAG+大模型的应用已经成为当前AI应用领域的一个热门方向。RAG(Retrieval-Augmented Generation)将检索和生成两个步骤相结合,利用外部知识库来增强生成模型的能力(如下图来自网络)。
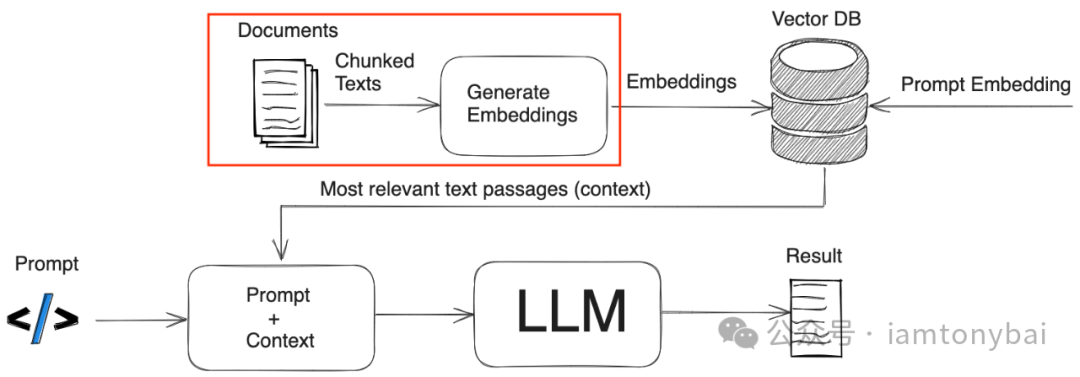
在RAG赋能的大模型应用中,关键的一步是将文本数据向量化后存储在向量数据库中(如上图的红框),以实现快速的相似度搜索,从而检索与输入查询相关的文本片段,再将检索到的文本输入给生成模型生成最终结果。
本文是我学习开发大模型应用的一篇小记,探讨的是如何使用Ollama和Go语言实现文本数据的向量化处理,这是开发基于RAG的大模型应用的前提和基础。
要进行文本向量化,我们首先要了解一下文本向量化的方法以及发展。
纵观文本向量化技术的发展历程,我们可以看到从早期的词袋模型(Bag-of-Words)、主题模型(Topic Models),到词嵌入(Word Embedding)、句嵌入(Sentence Embedding),再到当前基于预训练的文本嵌入模型(Pretrained Text Embedding Models),文本向量化的方法不断演进,语义表达能力也越来越强。
但传统的词袋模型忽略了词序和语义,主题模型又难以捕捉词间的细粒度关系,词嵌入模型(如Word2Vec、GloVe)虽然考虑了词的上下文,但无法很好地表征整个句子或文档的语义。近年来,随着预训练语言模型(如BERT、GPT等)的崛起,出现了一系列强大的文本嵌入模型,它们在大规模语料上进行预训练,能够生成高质量的句子/文档嵌入向量,广泛应用于各类NLP任务中。下图是抱抱脸(https://huggingface.co/)的最新文本嵌入模型的排行榜[1]:
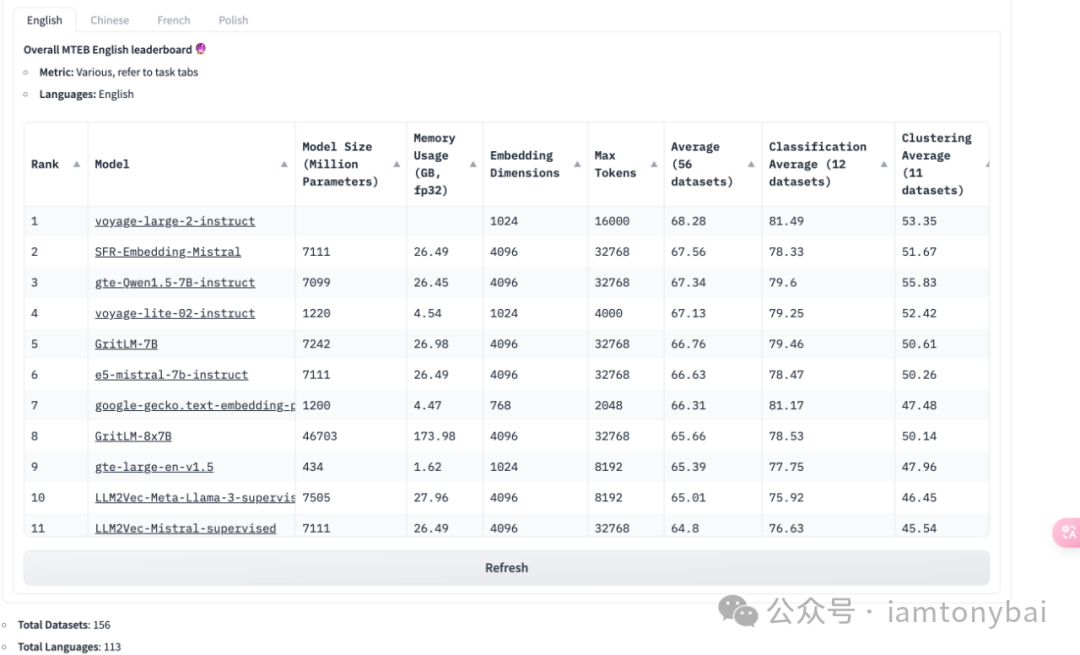
目前,基于大型预训练语言模型的文本嵌入已成为主流方法。这些模型在大规模无监督语料上预训练,学习到丰富的语义知识,生成的文本嵌入能较好地编码词语、短语和句子等多个层面的语义关系。Nomic AI[2]等组织发布了多种优秀的预训练文本嵌入模型,应用效果获得了较大提升。这种基于预训练的文本嵌入模型来实现文本数据向量化的方法也缓解了Go语言生态中文本向量化的相关库相对较少的尴尬,Gopher可以在预训练文本嵌入模型的帮助下将文本向量化。接下来,我们就来看看如何基于Ollama和Go基于文本嵌入模型实现文本向量化。
考虑到实验环境资源有限,以及Ollama对Text Embedding模型的支持[3],这里我选择了Nomic AI开源发布的nomic-embed-text v1.5模型[4],虽然在抱抱脸上它的排名并不十分靠前。
在《使用Ollama和OpenWebUI在CPU上玩转Meta Llama3-8B[5]》一文中,我已经粗略介绍过Ollama在本地运行大模型的基本步骤,如果你对Ollama的操作还不是很了解,可以先阅读一下那篇文章。
下面我们就用ollama下载nomic-embed-text:v1.5模型:
- $ollama pull nomic-embed-text:v1.5
- pulling manifest
- pulling manifest
- pulling 970aa74c0a90... 100% ▕██████████████████████████████████████████████████████████████████▏ 274 MB
- pulling c71d239df917... 100% ▕██████████████████████████████████████████████████████████████████▏ 11 KB
- pulling ce4a164fc046... 100% ▕██████████████████████████████████████████████████████████████████▏ 17 B
- pulling 31df23ea7daa... 100% ▕██████████████████████████████████████████████████████████████████▏ 420 B
- verifying sha256 digest
- writing manifest
- removing any unused layers
- success
算上之前的Llama3模型,目前本地已经有了两个模型:
- $ollama list
- NAME ID SIZE MODIFIED
- llama3:latest 71a106a91016 4.7 GB 2 weeks ago
- nomic-embed-text:v1.5 0a109f422b47 274 MB 3 seconds ago
不过与llama3的对话模型不同,nomic-embed-text:v1.5是用于本文嵌入的模型,我们不能使用命令行来run该模型并通过命令行与其交互:
- $ollama run nomic-embed-text:v1.5
- Error: embedding models do not support chat
一旦模型下载成功,我们就可以通过Ollama的HTTP API来访问该模型了,下面是通过curl将一段文本向量化的命令:
- $curl http://localhost:11434/api/embeddings -d '{
- "model": "nomic-embed-text:v1.5",
- "prompt": "The sky is blue because of Rayleigh scattering"
- }'
- {"embedding":[-1.246808409690857,0.10344144701957703,0.6935597658157349,-0.6157534718513489,0.4244955778121948,-0.7677388191223145,1.4136837720870972,0.012530215084552765,0.007208258379250765,-0.858286440372467,1.02878999710083,0.6512939929962158,1.0005667209625244,1.4231345653533936,0.30222395062446594,-0.4343869090080261,-1.358498215675354,-1.0671193599700928,0.3035725951194763,-1.5876567363739014,-0.9811925888061523,-0.31766557693481445,-0.32180508971214294,0.5726669430732727,-1.4187577962875366,-0.23533311486244202,-0.3387795686721802,0.02435961365699768,-0.9517765641212463,0.4120883047580719,-0.4619484841823578,-0.6658303737640381,0.010240706615149975,0.7687620520591736,0.9147310853004456,-0.18446297943592072,1.6336615085601807,1.006791353225708,-0.7928107976913452,0.3333768844604492,-0.9133707880973816,-0.8000166416168213,-0.41302260756492615,0.32945334911346436,0.44106146693229675,-1.3581880331039429,-0.2830675542354584,-0.49363842606544495,0.20744864642620087,0.039297714829444885,-0.6562637686729431,-0.24374787509441376,-0.22294744849205017,-0.664574921131134,0.5489196181297302,1.0000559091567993,0.45487216114997864,0.5257866382598877,0.25838619470596313,0.8648120760917664,0.32076674699783325,1.79911208152771,-0.23030932247638702,0.27912014722824097,0.6304138898849487,-1.1762936115264893,0.2685599625110626,-0.6646256446838379,0.332780659198761,0.1742674708366394,-0.27117523550987244,-1.1485087871551514,0.07291799038648605,0.7712352275848389,...,]}
注意:如果curl请求得到的应答是类似{"error":"error starting the external llama server: exec: "ollama_llama_server": executable file not found in $PATH "},可以尝试重启Ollama服务来解决:systemctl restart ollama。
Ollama没有提供sdk,我们就基于langchaingo[6]的ollama包访问ollama本地加载的nomic-embed-text:v1.5模型,实现文本的向量化。下面是示例的源码:
- // textembedding.go
- package main
-
- import (
- "context"
- "fmt"
- "log"
-
- "github.com/tmc/langchaingo/llms/ollama"
- )
-
- func main() {
- llm, err := ollama.New(ollama.WithModel("nomic-embed-text:v1.5"))
- if err != nil {
- log.Fatal(err)
- }
- ctx := context.Background()
- inputText := "The sky is blue because of Rayleigh scattering"
- result, err := llm.CreateEmbedding(ctx, []string{inputText})
- if err != nil {
- log.Fatal(err)
- }
-
- fmt.Printf("%#v\n", result)
- fmt.Printf("%d\n", len(result[0]))
- }

更新一下依赖:
- # go mod tidy
- go: finding module for package github.com/tmc/langchaingo/llms/ollama
- go: toolchain upgrade needed to resolve github.com/tmc/langchaingo/llms/ollama
- go: github.com/tmc/langchaingo@v0.1.9 requires go >= 1.22.0; switching to go1.22.3
- go: downloading go1.22.3 (linux/amd64)
- go: finding module for package github.com/tmc/langchaingo/llms/ollama
- go: found github.com/tmc/langchaingo/llms/ollama in github.com/tmc/langchaingo v0.1.9
- go: downloading github.com/stretchr/testify v1.9.0
- go: downloading github.com/pkoukk/tiktoken-go v0.1.6
- go: downloading gopkg.in/yaml.v3 v3.0.1
- go: downloading github.com/davecgh/go-spew v1.1.1
- go: downloading github.com/pmezard/go-difflib v1.0.0
- go: downloading github.com/google/uuid v1.6.0
- go: downloading github.com/dlclark/regexp2 v1.10.0
我本地的Go是1.21.4版本,但langchaingo需要1.22.0版本及以上,这里考虑向前兼容性[7],go下载了go1.22.3。
接下来运行一下上述程序:
- $go run textembedding.go
- [][]float32{[]float32{-1.2468084, 0.10344145, 0.69355977, -0.6157535, 0.42449558, -0.7677388, 1.4136838, 0.012530215, 0.0072082584, -0.85828644, 1.02879, 0.651294, 1.0005667, 1.4231346, 0.30222395, -0.4343869, -1.3584982, -1.0671194, 0.3035726, -1.5876567, -0.9811926, -0.31766558, -0.3218051, 0.57266694, -1.4187578, -0.23533311, -0.33877957, 0.024359614, -0.95177656, 0.4120883, -0.46194848, -0.6658304, 0.010240707, 0.76876205, 0.9147311, -0.18446298, 1.6336615, 1.0067914, -0.7928108, 0.33337688, -0.9133708, -0.80001664, -0.4130226, 0.32945335, 0.44106147, -1.358188, -0.28306755, -0.49363843, 0.20744865, 0.039297715, -0.65626377, -0.24374788, -0.22294745, -0.6645749, 0.5489196, 1.0000559, 0.45487216, 0.52578664, 0.2583862, 0.8648121, 0.32076675, 1.7991121, -0.23030932, 0.27912015, 0.6304139, -1.1762936, 0.26855996, -0.66462564, 0.33278066, 0.17426747, -0.27117524, -1.1485088, 0.07291799, 0.7712352, -1.2570909, -0.6230442, 0.02963586, -0.4936177, -0.014295651, 0.5730515, ... , -0.5260737, -0.44808808, 0.9352375}}
- 768
我们看到输入的文本成功地被向量化了,我们输出了这个向量的维度:768。
注:文本向量维度的常见的值有200、300、768、1536等。
我们看到,基于Ollama加载的预训练文本嵌入模型,我们可以在Go语言中实现高效优质的文本向量化。将文本数据映射到语义向量空间,为基于RAG的知识库应用打下坚实的基础。有了向量后,我们便可以将其存储在向量数据库中备用,在后续的文章中,我会探讨向量数据库写入与检索的实现方法。
Gopher部落知识星球[8]在2024年将继续致力于打造一个高品质的Go语言学习和交流平台。我们将继续提供优质的Go技术文章首发和阅读体验。同时,我们也会加强代码质量和最佳实践的分享,包括如何编写简洁、可读、可测试的Go代码。此外,我们还会加强星友之间的交流和互动。欢迎大家踊跃提问,分享心得,讨论技术。我会在第一时间进行解答和交流。我衷心希望Gopher部落可以成为大家学习、进步、交流的港湾。让我相聚在Gopher部落,享受coding的快乐! 欢迎大家踊跃加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址[9]:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻) - https://gopherdaily.tonybai.com
我的联系方式:
微博(暂不可用):https://weibo.com/bigwhite20xx
微博2:https://weibo.com/u/6484441286
博客:tonybai.com
github: https://github.com/bigwhite
Gopher Daily归档 - https://github.com/bigwhite/gopherdaily

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。
参考资料
[1]
文本嵌入模型的排行榜: https://huggingface.co/spaces/mteb/leaderboard
[2]Nomic AI: https://www.nomic.ai/
[3]Ollama对Text Embedding模型的支持: https://ollama.com/search?q=embed&p=1
[4]nomic-embed-text v1.5模型: https://blog.nomic.ai/posts/nomic-embed-matryoshka
[5]使用Ollama和OpenWebUI在CPU上玩转Meta Llama3-8B: https://tonybai.com/2024/04/23/playing-with-meta-llama3-8b-on-cpu-using-ollama-and-openwebui/
[6]langchaingo: https://github.com/tmc/langchaingo
[7]向前兼容性: https://tonybai.com/2023/09/10/understand-go-forward-compatibility-and-toolchain-rule/
[8]Gopher部落知识星球: https://public.zsxq.com/groups/51284458844544
[9]链接地址: https://m.do.co/c/bff6eed92687

