
- 1【数据分析报告】携程客户分析与流失预测_携程数据分析
- 2三维重建中如何进行深度测距
- 3496.下一个更大元素
- 4支持向量机(SVM)算法简介_支持向量机的基本思想
- 5C++代码调试,基于visual studio篇_visusl stdio调试c++
- 6安卓高级控件(下拉框、列表类视图、翻页类视图、碎片Fragment)_安卓下拉框控件
- 7SoundStream VS Lyra: 谷歌今年新推出的两款AI音频编解码器有何不同?
- 8Android 消息推送之MQTT及采坑_mqttandroidclient订阅成功收不到消息
- 9AI视频教程下载:使用ChatGPT进行市场营销
- 10Window下部署使用Stable Diffusion AI开源项目绘图_stable diffusion开源项目
SparkSQL的数据结构DataFrame构建方式(Python语言)_spark 造数据
赞
踩
SparkSQL 是Spark的一个模块, 用于处理海量结构化数据,其提供了两个操作SparkSQL的抽象,分别是DataFrame和DataSet,spark2.0之后,统一了DataSet和DataFrame,以后只有DataSet。
以Python、R语言开发Spark,使用没有泛型的DataSet,即DataFrame结构。Java、Scala语言开发Spark,既可以使用带泛型的DataSet数据结构,也可以使用不带泛型的DataFrame数据结构
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库的二维表格,带有Schema元信息(可以理解为数据库的列名和类型)
RDD、DataFrame、DataSet的区别
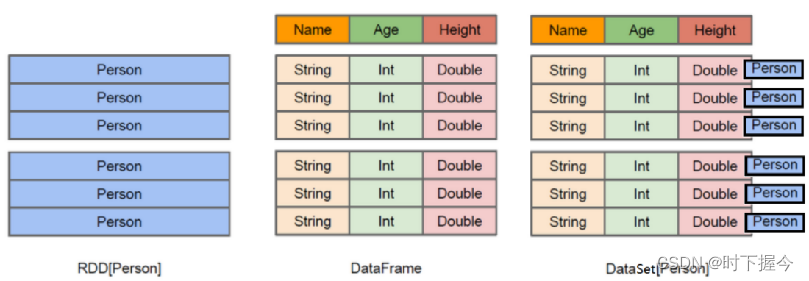
RDD: 存储的直接就是对象, 比如在图中, 存储的就是一个Person的对象
DataFrame:提供了详细的结构信息schema列的名称和类型
DataSet:Preston对象中数据按照结构化方式存储, 同时保留对象的类型,
1.定义元数据
schema = StructType() \
.add(StructField('name', StringType(), nullable=True)) \
.add(StructField('age', IntegerType(), nullable=True))
- 1
- 2
- 3
schema = StructType(fields=[
StructField('name', StringType(), True),
StructField('age', IntegerType(), True)
])
- 1
- 2
- 3
- 4
2.转DataFrame
要保证每一个元素的类型应该为 列表/元组/字典类型, 否则在转换为DF的时候, 无法识别
df = scRdd.toDF(schema=schema)
df = scRdd.toDF(schema='name string,age integer')
df = scRdd.toDF(schema=['name', 'age'])
- 1
- 2
- 3
3.创建DataFrame
sparkContext rdd对象、pandas dataFrame对象作为参数传给函数createDataFrame,直接创建对象
df = sparkSession.createDataFrame(
data=scRdd,
schema=schema)
df = sparkSession.createDataFrame(
data=pandasDF,
schema='name string,age integer')
df = spark.createDataFrame(
data=[('李四',20),('张三',18),('王五',25)],
schema='name,age' )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.DataFrame接收外部文件
采用Text读取方式来读取外部文件的数据, 仅会产生一列数据,一行数据为一列, 默认的列名为value 支持修改列名. 数据类型必须是String
df = ss.read.format("text").schema("line string").load(path='file:///data/stu.txt')
- 1
CSV 是可以读取多列的数据, 默认会根据逗号进行切割处理, 一个作为一列来展示
CSV相关的参数说明:
sep: 指定字段之间的分隔符号, 默认为逗号
header: 是否存在头信息, 默认为False. 如果为True, 表示将文件的第一行作为表头
inferSchema: 是否自动识别字段的类型, 默认为False
encoding: 读取数据的编码集, 默认为UTF-8
df = ss.read.format('csv')
.schema('id int,dept_name string')
.option('sep', ',')
.option('header', True) \
.option('inferSchema', False) \
.option('encoding', 'utf-8') \
.load(path='file:///data/stu.txt')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
另一种写法:
ss.read.csv(
schema='id int,dept_name string',
seq=',',
load='file:///data/stu.txt',
header=True,
inferSchema=False,
encoding='utf-8'
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
读取JSON文件,也支持多列读取,当没有设置shcema的时候,自动识别文件数据,将key当作字段名称。
也支持自定义schema信息,但设置的字段名称要和文件中的key值保持一致,否则无法匹配。同时可以基于shema约束字段顺序
json字符串结构化的时候,字段没有值的用null代替
df = ss.read.json(
schema='id int,name string,address string,age int',
path='file:///export/data/remote_pyspark_workspace/data/stu.json'
)
- 1
- 2
- 3
- 4
5. sparkSession.read
sparkSession.read读取的数据源,一般用DataFrame对象封装
mysql_df = ss.read.jdbc(
'jdbc:mysql://up01:3306/tfec_tags?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false&user=root&password=123456',
'tbl_basic_tag')
mysql_df = mysql_df.select('rule').where('id=14')
- 1
- 2
- 3
- 4
mysql_df = spark.read.format('jdbc'). \
option('url', 'jdbc:mysql://up01:3306/tfec_tags?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false'). \
option('user', 'root'). \
option('password', '123456'). \
option('query', 'select id,rule,pid from tbl_basic_tag where id=14 or pid=14').load()
- 1
- 2
- 3
- 4
- 5
从ES读取数据源,Spark需要Elasticsearch_Hadoop插件
es_df = spark.read.format('es'). \
option('es.nodes', 'up01:9200'). \
option('es.resource','tfec_tbl_users_idx'). \
option('es.read.field.include', 'id,gender'). \
load()
- 1
- 2
- 3
- 4
- 5

