
- 1python error 解决方案_non-ascii character in file
- 2hadoop安装及基本使用
- 3记一次处理项目漏洞_rocketmq whiteremoteaddress
- 4php数组中是否包含某字符串中,PHP如何测试数组中某个值是否存在(部分)在字符串中?...
- 5Java的基础入门
- 6Hive超详细安装_安装配置hive
- 7机器人学Robotics学习资料 | 我的SLAM入门路线分享_机器人控制学习路线
- 8软件测试面试题(二):Jmeter面试_jmeter压测面试题
- 9人工智能——机器学习概述_什么是ai机器学习
- 10Hive on Spark配置_hive1.1.0配置spark2.2.0
人体姿态识别(教程+代码)_人体姿态识别算法代码
赞
踩
模型效果
从下图可以清楚的看到,提出的模型可以对人眼以及嘴巴进行描述。
最终的是对每个关节点进行了划分和表示。

前言
从视频中进行人体姿势估计在各种应用中都扮演着关键角色,例如量化身体锻炼、手语识别和全身手势控制。例如,它可以成为瑜伽、舞蹈和健身应用的基础。它还可以在增强现实中将数字内容和信息覆盖在物理世界之上。
模型介绍
提出的人体识别模型是一种高保真度的身体姿势跟踪机器学习解决方案,可以从RGB视频帧中推断出整个身体的33个3D标记和背景分割掩码,利用先前BlazePose研究,该研究还为ML Kit Pose Detection API提供支持。值得注意的是,目前最先进的方法主要依赖于强大的桌面环境进行推断,而我们的方法可以在大多数现代手机、桌面/笔记本电脑上实现实时性能,甚至在Python和Web上也可以使用可谓是功能十分强大!
算法介绍
这个解决方案利用了一种两步探测器-跟踪器机器学习流程,决方案中已经被证明是有效的。使用探测器,该流程首先定位帧内的人/姿势感兴趣区域(ROI)。然后,跟踪器使用ROI裁剪帧作为输入,在ROI内预测姿势标记和分割掩码。请注意,对于视频用例,只有在需要时才会调用探测器,即在第一帧和跟踪器无法在上一帧中识别身体姿势存在时。对于其他帧,该流程只需从上一帧的姿势标记中派生ROI。
模型
人物/姿势检测模型(BlazePose检测器)
该检测器受我们自己的轻量级BlazeFace模型的启发,该模型用作MediaPipe面部检测的代理人物检测器。它明确预测另外两个虚拟关键点,以牢固描述人体的中心、旋转和比例,形成一个圆。灵感来自于达·芬奇的《维特鲁威人》,我们预测一个人的臀部中点、围绕整个人的圆的半径以及连接肩膀和臀部中点的线的倾斜角度。
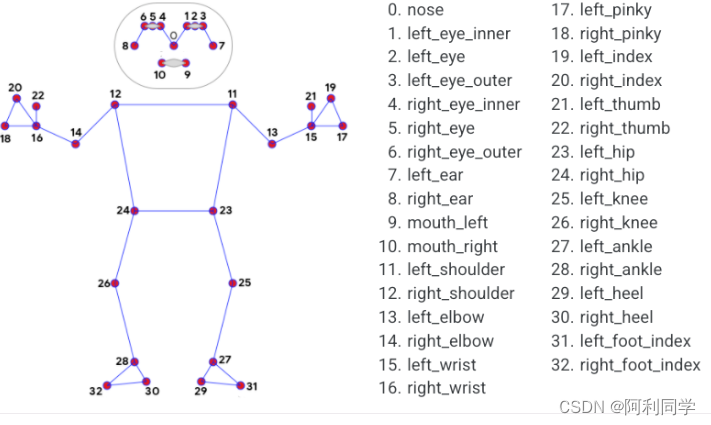
算法代码
核心代码部分 顺便看下效果

支持的配置选项:
static_image_mode(静态图像模式)
model_complexity(模型复杂度)
smooth_landmarks(平滑标记点)
enable_segmentation(启用分割)
smooth_segmentation(平滑分割)
min_detection_confidence(最小检测置信度)
min_tracking_confidence(最小跟踪置信度)
with mp_pose.Pose(
#全部代码----->q1309399183<---------
static_image_mode=True,
model_complexity=2,
enable_segmentation=True,
min_detection_confidence=0.5) as pose:
for idx, file in enumerate(IMAGE_FILES):
image = cv2.imread(file)
image_height, image_width, _ = image.shape
# Convert the BGR image to RGB before processing.
results = pose.process(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
if not results.pose_landmarks:
continue
print(
f'Nose coordinates: ('
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].x * image_width}, '
f'{results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].y * image_height})'
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
算法结论和效果展示
该流程是作为一个e图实现的,它使用了姿势标记模块中的姿势标记子图,并使用专用的姿势渲染器子图进行渲染。姿势标记子图在内部使用了姿势检测模块中的姿势检测子图。

代码部分可私信交流
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

