
- 1飞桨领航团AI达人创造营笔记——深度学习模型训练和关键参数调优详解_ai训练常用参数 csdn
- 2模拟视频芯片ADV7392 PAL输出调试过程_adv739 fpga
- 3task 05: 排序,搜索,计数和集合_按照taskstatus排序
- 4python 调用AI作画
- 5Java Web应用开发项目实践--宿舍信息管理系统
- 6信息安全技术实验:数据的加密与解密_信息安全实验加密系统的设计实现
- 7hadoop的三大组件_Hadoop框架:Yarn基本结构和运行原理
- 8python爬虫爬取网站_完整的爬一个网址教程
- 9大华(华瑞)MVP常用组件的使用_大华mvp机器视觉软件
- 10基于8位AVR®处理器的 ATMEGA808-XUR、ATMEGA328P-MUR、ATMEGA328P-AUR、ATMEGA328-AUR微控制器(MCU)运行频率高达20MHz_atmega8和atmega328
从零开始在家用电脑上运行AI大模型_windows 部署一个ai大模型
赞
踩
原理:得益于llama.cpp等开源量化项目的不断发展,让我们有机会在不同平台,甚至没有显卡的情况下也能运行大模型。
本文参考了大量朋友圈大佬的部分博客以及部分引用,这里也给大佬引一波流,这个是他的个人博客,本文很多内容源于此:苏洋博客
1.安装docker
为了避免环境的折腾,预先可以安装好docker,后文很多操作也是基于docker完成。
window和mac都推荐直接安装Docker Desktop:Docker Desktop: The #1 Containerization Tool for Developers | Docker
window比较特殊一点 ,需要先开启wsl和虚拟化的相关配置,cpu也要先支持虚拟化。
好在网上教程很多,官方也有相关的文档,这里就不展开了,大家自己按需安装。
注:window要注意,因为docker默认的镜像等资源都是存放在c盘的,需要在安装好docker进行配置修改。
2.创建一个模型存放的目录
因为模型普遍比较大,选定一个大一点的存放空间是很有必要的。
我这里是在D盘创建了一个docker文件夹,用于挂载本地磁盘,作为docker数据卷,用来存放模型
3.下载相关的大模型
我的配置是i5+3070ti 显存不是很够,所以选了一个7b的中文模型,这个模型是:
GitHub - LinkSoul-AI/Chinese-Llama-2-7b: 开源社区第一个能下载、能运行的中文 LLaMA2 模型!
大家可以自行下载,对于国内的下载环境也比较友好,感谢大佬们的付出
全部开源,完全可商用的中文版 Llama2 模型及中英文 SFT 数据集,输入格式严格遵循 llama-2-chat 格式,兼容适配所有针对原版 llama-2-chat 模型的优化。
我下载到的是d盘docker下面。
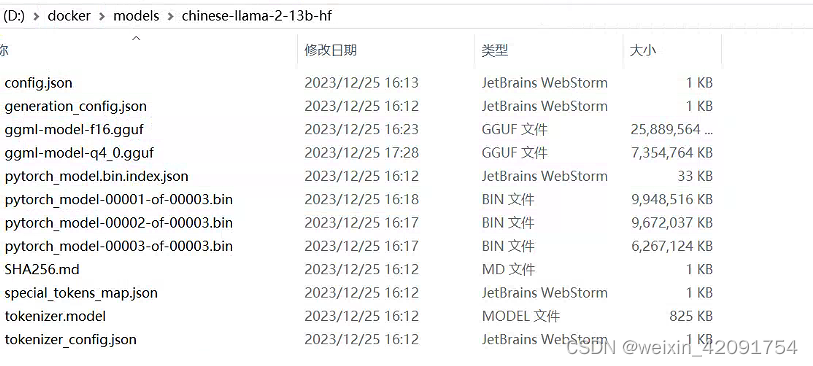
4.构建镜像
创建一个名叫 dockerfile 的文件
内容如下:
- FROM nvcr.io/nvidia/pytorch:23.10-py3
- RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple && \
- pip3 install --upgrade pip # enable PEP 660 support
- RUN sed -i 's/archive.ubuntu.com/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list && \
- sed -i 's/security.ubuntu.com/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list
- WORKDIR /app
- RUN pip3 install transformers==4.35.0 huggingface-hub==0.17.3 hf_transfer==0.1.4
- RUN apt-get update && apt-get install cmake -y && apt-get autoremove -y
在文件所在目录执行命令:
docker build -t soulteary/yi-34b-runtime:20231126 .这样你就得到了一个有基础环境的镜像了

5.启动镜像
docker run --rm -it -p 8080:8080 --gpus all --ipc=host --ulimit memlock=-1 -v D:\docker:/app soulteary/yi-34b-runtime:20231126 bash
6.编译使用 GPU 的 llama.cpp
- #下载llama.cpp
- git clone https://github.com/ggerganov/llama.cpp.git
-
- # 进入代码目录
- cd llama.cpp/
-
- #编译llama.cpp
- make -j LLAMA_CUBLAS=1
这里需要花费一定的时间,耐心等待编译完成就好
这时我们会得到一些之前没有的可执行文件,如:main, server等,待会我们会用到。
7.量化大模型
- # 安装需要的包
- python3 -m pip install -r requirements.txt
-
-
- # 预量化模型
- python3 convert.py ../chinese-llama-2-13b-hf/
完成后chinese-llama-2-13b-hf目录下会多出一个ggml-model-f16.gguf文件
然后我们进一步量化
./quantize ../chinese-llama-2-13b-hf/ggml-model-f16.gguf ../chinese-llama-2-13b-hf/ggml-model-q4_0.gguf q4_0完成后chinese-llama-2-13b-hf目录下会多出一个ggml-model-q4_0.gguf文件,这个就是我们待会用到的模型了
8.运行大模型
- #切换目录
- cd /app
-
- #拷贝启动文件到/app下, 这里我们使用server来启动,能给我们开启一个webui界面
- cp llama.cpp/server .
-
- #用server启动大模型
- ./server --ctx-size 2048 --host 0.0.0.0 --n-gpu-layers 32 --model ./chinese-llama-2-13b-hf/ggml-model-q4_0.gguf
这一步同样会花费很多时间
出现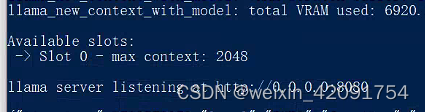
后就可以访问浏览器 http://127.0.0.1:8080/开始体验你的大模型了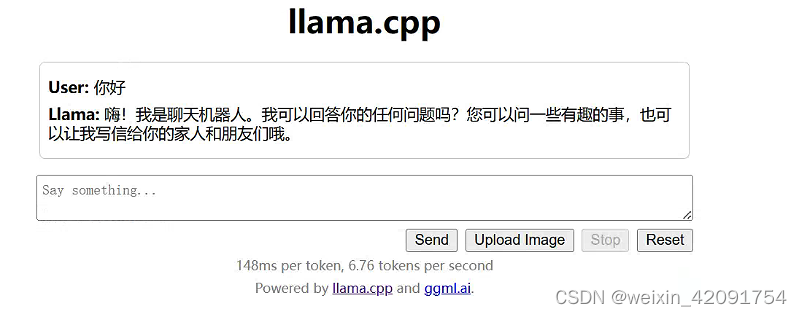
参考资料:
1.本地运行“李开复”的零一万物 34B 大模型 - 苏洋博客
2.GitHub - LinkSoul-AI/Chinese-Llama-2-7b: 开源社区第一个能下载、能运行的中文 LLaMA2 模型!

