- 1金三银四铜五铁六,Offer收到手软!_拉钩专栏解锁,不怕截图吗
- 22018年计算机视觉顶会和人工智能顶级会议时间表_ieee conference on computer vision and pattern rec
- 3C-数据结构-retrieval搜索树
- 4SpringBoot高效批量插入百万数据_springboot 大批量数据导入
- 5快速达成目标的12种方_如果决定进行海外资源开发,迈克有哪几种可选方案,每个方案的优缺点是什么
- 6HashMap,ArrayMap,SparseArray源码分析及性能对比_hashmap和arraymap查找效率
- 7ROS(7)ROS2命令与学习_ros2发布话题命令
- 83D医学图像分割大模型 SegVol: Universal and Interactive Volumetric Medical Image Segmentation
- 9Python练习题013:分解质因数_python将一个正整数分解质因数。例如:输入90,打印出90=2*3*3*5。
- 10php做后端的优势,【后端开发】php和java的优势
大数据环境生态搭建3-Flink安装与配置_flink1.13.0安装
赞
踩
一 环境准备
<本次依赖的环境有JDK 和Hadoop>,可以参考小编前面的两篇博客
CSDN基础环境搭建 →大数据环境生态搭建1-准备阶段_小秃头_的博客-CSDN博客CSDN
hadoop环境搭建→大数据环境生态搭建2-Hadoop安装与配置_小秃头_的博客-CSDN博客
二 安装Flink
1)集群规划
| 主机名 | 角色 |
| hadoop101 | JobManager |
| hadoop102 | TaskManager |
| hadoop103 | TaskManager |
2)安装包下载
Index of /dist/flink/flink-1.13.0![]() https://archive.apache.org/dist/flink/flink-1.13.0/
https://archive.apache.org/dist/flink/flink-1.13.0/
3)将安装包上传到linux系统
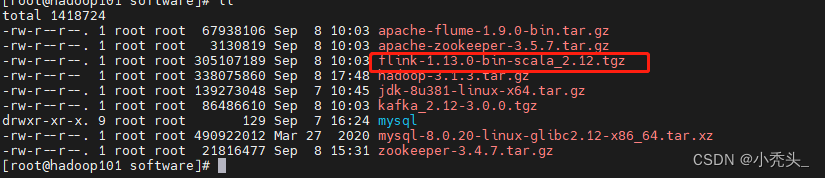
4)解压安装包,<并重命名>
tar -zxvf flink-1.13.0-bin-scala_2.12.tgz -C /opt/module/5)配置环境变量
- export FLINK_HOME=/opt/module/flink
- export PATH=$PATH:$FLINK_HOME/bin
6)修改flink-conf.yaml配置文件,配置JobManager节点
[root@hadoop101 conf]# vim flink-conf.yaml
7)修改workers文件,配置TaskManager节点
[root@hadoop101 conf]# vim workers
8)将hadoop101上的Flink包分发到hadoop102和hadoop103
- scp -r flink-1.13.0/ hadoop102:$PWD
- scp -r flink-1.13.0/ hadoop103:$PWD
9)启动集群
[root@hadoop101 flink]# ./bin/start-cluster.sh


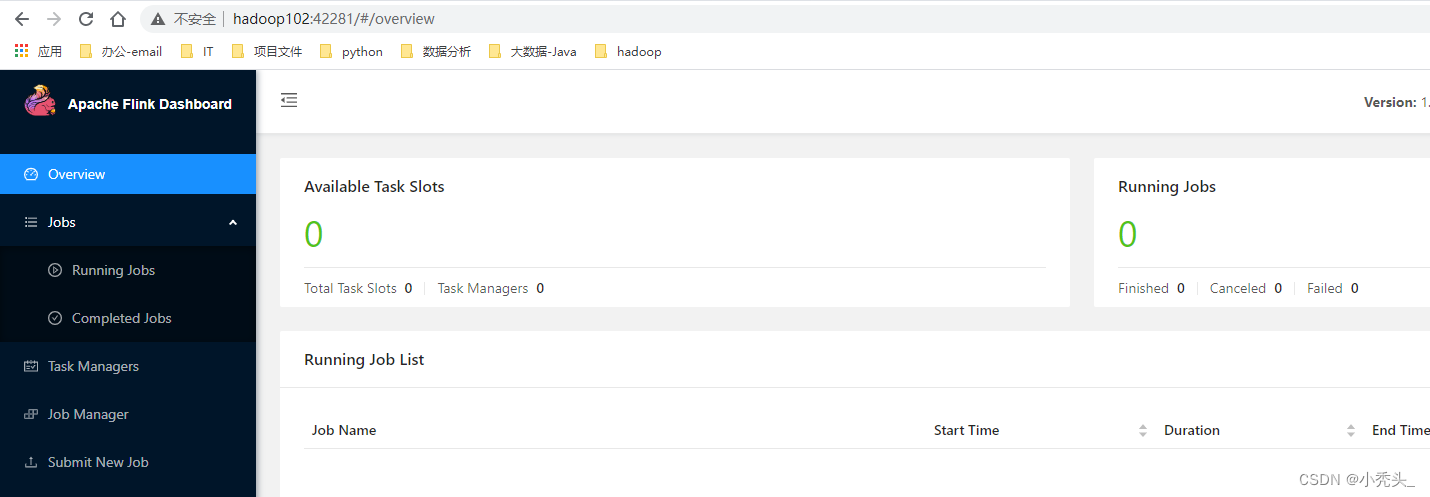
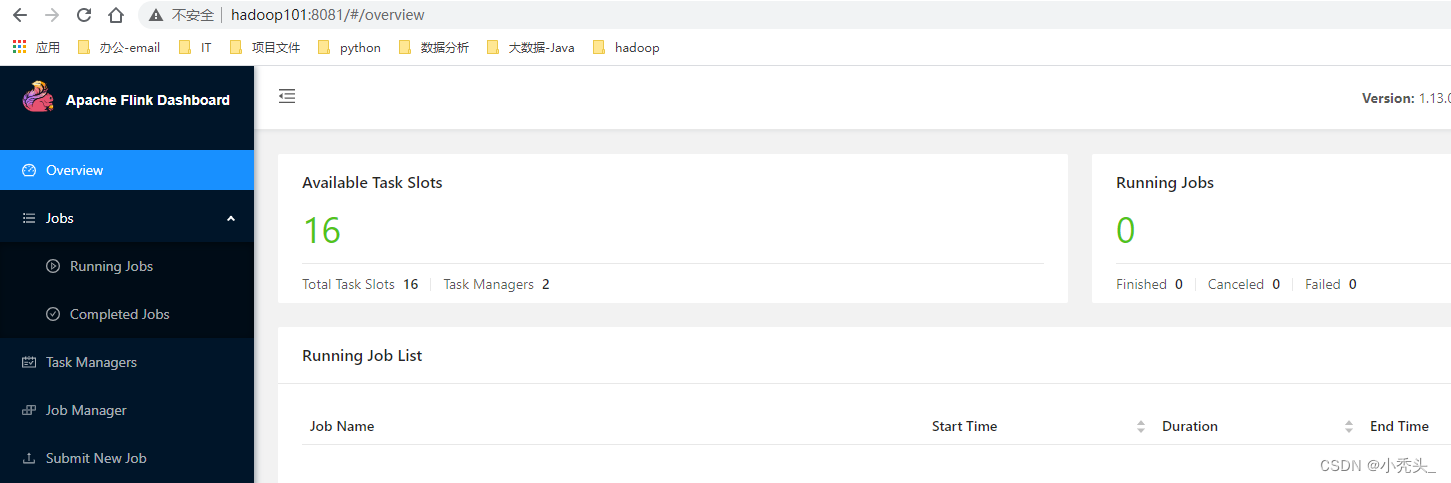
10)访问web端页面,默认端口8081
三 flink on yarn
1)需要将hadoop-yarn-api-3.1.3.jar 和 flink-shaded-hadoop-3-3.1.1.7.2.8.0-224-9.0.jar 两个jar包放到flink/lib目录里
[root@hadoop101 flink]# cp /opt/module/hadoop/share/hadoop/yarn/hadoop-yarn-api-3.1.3.jar /opt/module/flink/lib/也可以直接下载:https://repo1.maven.org/maven2/commons-cli/commons-cli/1.5.0/commons-cli-1.5.0.jar
下载好后,直接放到flink/lib即可
如果是hadoop2.x,还需要将flink-shaded-hadoop-2-uber-2.8.3-10.0.jar也放到flink/lib下
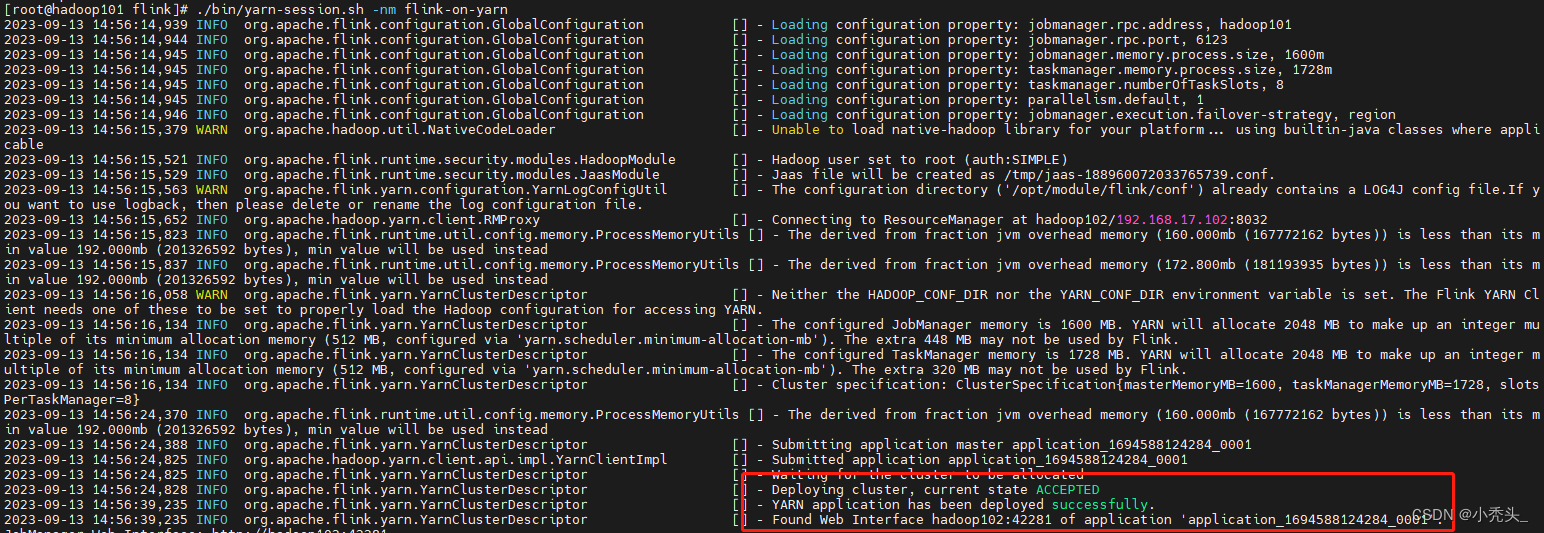
2)在yarn模式下启动flink集群
[root@hadoop01 bin]# ./yarn-session.sh -nm flink-on-yarn显示如下信息表示启动成功
3)访问web页面 http://hadoop102:42281