
- 1动手学深度学习4.7 前向传播、反向传播和计算图-笔记&练习(PyTorch)
- 2可视化神经网络模型的工具Netron_netron 无法打开.bin,模型
- 3欧科云链OKLink:比特币第四次减半即将到来,收好这份数据宝典
- 4HTML 总结
- 5前端面试常见问题之跨域_使用内网ip就正常,使用域名就被cors拒绝
- 6Spring 实现AOP常见的两种方式(注解或者自定义注解)_aop注解实现
- 7高考志愿系统-模拟填报模块分析
- 8基于FPGA的交通信号灯设计_基于fpga的交通灯设计
- 9Git使用教程_git remote add origin git@
- 10uniapp 利用uni-list 和 uni-load-more 组件上拉加载列表
一文了解知识图谱能做什么、本文含Jiagu自然语言处理工具试用、知识图谱实战。(2)
赞
踩

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
2.2 Jiagu自然语言处理工具部署到本地
2.2.1下载Jiagu
首先我们进入OpenKG官网找到该项目开源的页面。这是思知机器人公司开源的一个知识图谱工具。然后我们进入Github进行下载该项目即可即可。

图2-1 OpenKG官网查看Jiagu

图2-2 Github查看Jiagu开源项目
2.2.2为Jiagu创建虚拟环境
我们首先需要安装有anaconda来创建环境
首先我们打开anaconda依次输入如下命令即可
conda create -n Jiagu python=3.8
conda activate Jiagu
然后再输入python3 setup.py install

图2-3 用anaconda创建一个虚拟环境
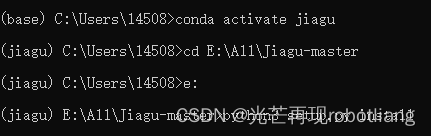
图2-4 安装JiaguNLP工具

图2-5 成功安装Jiagu
接下来安装numpy
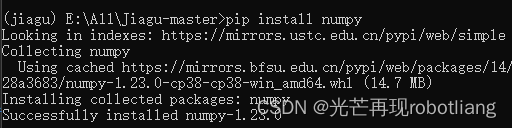
图2-6 numpy安装
接下来还需要再安装matplotlib
图2-7 matplotlib安装
这样我们所需的三个包,jiagu、matplotlib、numpy就安装完成了。
2.3 Jiagu实例运行使用
2.3.1分词、词性标注、命名实体识别
运行python代码如下:
import jiagu
#jiagu.init() # 可手动初始化,也可以动态初始化
text = ‘厦门明天会不会下雨’
words = jiagu.seg(text) # 分词
print(words)
pos = jiagu.pos(words) # 词性标注
print(pos)
ner = jiagu.ner(words) # 命名实体识别
print(ner)

图2-8 分词、词性标注、命名实体识别
2.3.2 demo测试
接下来我们运行demo进行测试
测试代码如下:
import jiagu
jiagu.init() # 可手动初始化,也可以动态初始化
text = ‘苏州的天气不错’
words = jiagu.seg(text) # 分词
print(words)
words = jiagu.cut(text) # 分词
print(words)
pos = jiagu.pos(words) # 词性标注
print(pos)
ner = jiagu.ner(words) # 命名实体识别
print(ner)
字典模式分词
text = ‘思知机器人挺好用的’
words = jiagu.seg(text)
print(words)
jiagu.load_userdict(‘dict/user.dict’) # 加载自定义字典,支持字典路径、字典列表形式。
jiagu.load_userdict([‘思知机器人’])
words = jiagu.seg(text)
print(words)
text = ‘’’
该研究主持者之一、波士顿大学地球与环境科学系博士陈池(音)表示,“尽管中国和印度国土面积仅占全球陆地的9%,但两国为这一绿化过程贡献超过三分之一。考虑到人口过多的国家一般存在对土地过度利用的问题,这个发现令人吃惊。”
NASA埃姆斯研究中心的科学家拉玛·内曼尼(Rama Nemani)说,“这一长期数据能让我们深入分析地表绿化背后的影响因素。我们一开始以为,植被增加是由于更多二氧化碳排放,导致气候更加温暖、潮湿,适宜生长。”
“MODIS的数据让我们能在非常小的尺度上理解这一现象,我们发现人类活动也作出了贡献。”
NASA文章介绍,在中国为全球绿化进程做出的贡献中,有42%来源于植树造林工程,对于减少土壤侵蚀、空气污染与气候变化发挥了作用。
据观察者网过往报道,2017年我国全国共完成造林736.2万公顷、森林抚育830.2万公顷。其中,天然林资源保护工程完成造林26万公顷,退耕还林工程完成造林91.2万公顷。京津风沙源治理工程完成造林18.5万公顷。三北及长江流域等重点防护林体系工程完成造林99.1万公顷。完成国家储备林建设任务68万公顷。
‘’’
keywords = jiagu.keywords(text, 5) # 关键词抽取
print(keywords)
summarize = jiagu.summarize(text, 3) # 文本摘要
print(summarize)
jiagu.findword(‘input.txt’, ‘output.txt’) # 根据大规模语料,利用信息熵做新词发现。
知识图谱关系抽取
text = ‘姚明1980年9月12日出生于上海市徐汇区,祖籍江苏省苏州市吴江区震泽镇,前中国职业篮球运动员,司职中锋,现任中职联公司董事长兼总经理。’
knowledge = jiagu.knowledge(text)
print(knowledge)
情感分析
text = ‘很讨厌还是个懒鬼’
sentiment = jiagu.sentiment(text)
print(sentiment)
文本聚类(需要调参)
docs = [
“百度深度学习中文情感分析工具Senta试用及在线测试”,
“情感分析是自然语言处理里面一个热门话题”,
“AI Challenger 2018 文本挖掘类竞赛相关解决方案及代码汇总”,
“深度学习实践:从零开始做电影评论文本情感分析”,
“BERT相关论文、文章和代码资源汇总”,
“将不同长度的句子用BERT预训练模型编码,映射到一个固定长度的向量上”,
“自然语言处理工具包spaCy介绍”,
“现在可以快速测试一下spaCy的相关功能,我们以英文数据为例,spaCy目前主要支持英文和德文”
]
cluster = jiagu.text_cluster(docs)
print(cluster)
代码运行结果截图如下:
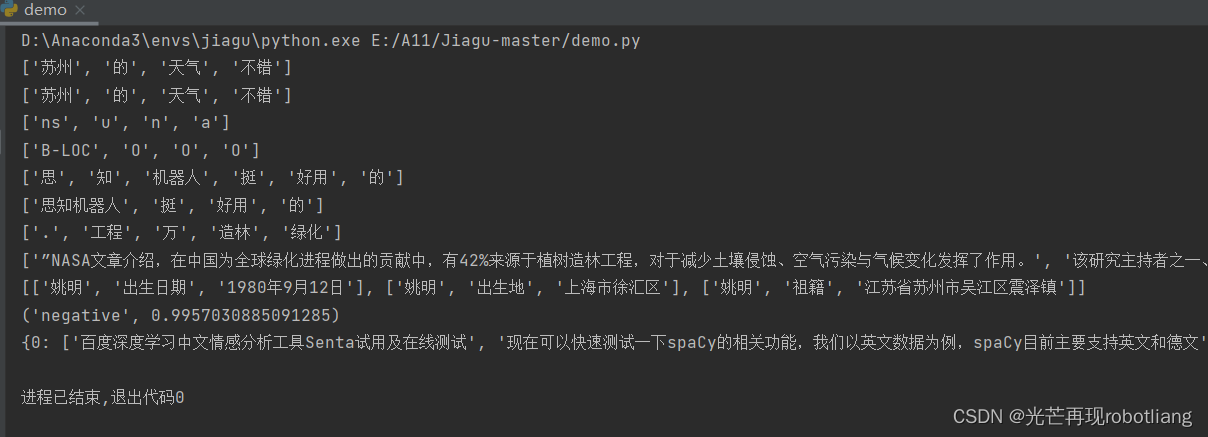
图2-9 demo运行成功
2.3.3中文分词
运行代码如下:
import jiagu
text = ‘汉服和服装、维基图谱’
words = jiagu.seg(text)
print(words)
jiagu.load_userdict(‘dict/user.dict’) # 加载自定义字典,支持字典路径、字典列表形式。
jiagu.load_userdict([‘汉服和服装’])
words = jiagu.seg(text) # 自定义分词,字典分词模式有效
print(words)
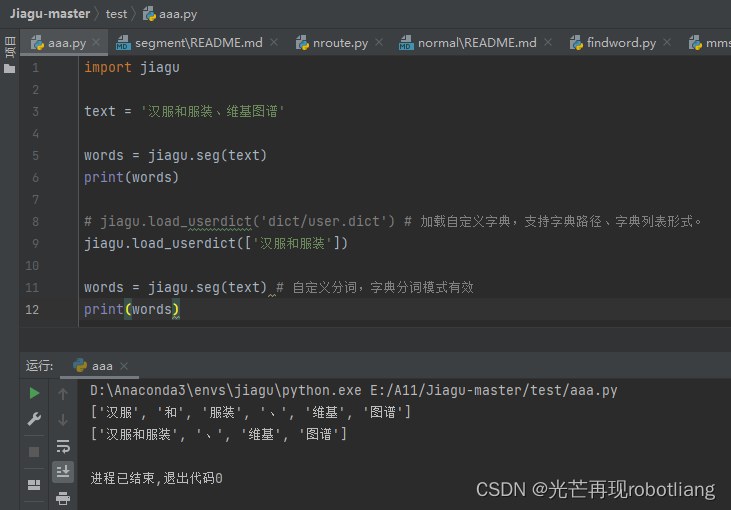
图2-10运行中文分词
2.3.4知识图谱关系抽取
本案例只能使用百科的描述进行测试。作者提出效果更佳的后期将会开放api。
代码如下:
import jiagu
吻别是由张学友演唱的一首歌曲。
《盗墓笔记》是2014年欢瑞世纪影视传媒股份有限公司出品的一部网络季播剧,改编自南派三叔所著的同名小说,由郑保瑞和罗永昌联合导演,李易峰、杨洋、唐嫣、刘天佐、张智尧、魏巍等主演。
text = ‘姚明1980年9月12日出生于上海市徐汇区,祖籍江苏省苏州市吴江区震泽镇,前中国职业篮球运动员,司职中锋,现任中职联公司董事长兼总经理。’
knowledge = jiagu.knowledge(text)
print(knowledge)

图2-11 运行关系抽取
2.3.5关键词抽取
代码如下:
import jiagu
text = ‘’’
该研究主持者之一、波士顿大学地球与环境科学系博士陈池(音)表示,“尽管中国和印度国土面积仅占全球陆地的9%,但两国为这一绿化过程贡献超过三分之一。考虑到人口过多的国家一般存在对土地过度利用的问题,这个发现令人吃惊。”
NASA埃姆斯研究中心的科学家拉玛·内曼尼(Rama Nemani)说,“这一长期数据能让我们深入分析地表绿化背后的影响因素。我们一开始以为,植被增加是由于更多二氧化碳排放,导致气候更加温暖、潮湿,适宜生长。”
“MODIS的数据让我们能在非常小的尺度上理解这一现象,我们发现人类活动也作出了贡献。”
NASA文章介绍,在中国为全球绿化进程做出的贡献中,有42%来源于植树造林工程,对于减少土壤侵蚀、空气污染与气候变化发挥了作用。
据观察者网过往报道,2017年我国全国共完成造林736.2万公顷、森林抚育830.2万公顷。其中,天然林资源保护工程完成造林26万公顷,退耕还林工程完成造林91.2万公顷。京津风沙源治理工程完成造林18.5万公顷。三北及长江流域等重点防护林体系工程完成造林99.1万公顷。完成国家储备林建设任务68万公顷。
‘’’
keywords = jiagu.keywords(text, 5) # 关键词
print(keywords)

图2-12运行关键词抽取
2.3.6情感分析
代码如下:
import jiagu
text = ‘很讨厌还是个懒鬼’
sentiment = jiagu.sentiment(text)
print(sentiment)

图2-13 运行情感分析
2.3.7文本聚类
代码如下:
import jiagu
docs = [
“百度深度学习中文情感分析工具Senta试用及在线测试”,
“情感分析是自然语言处理里面一个热门话题”,
“AI Challenger 2018 文本挖掘类竞赛相关解决方案及代码汇总”,
“深度学习实践:从零开始做电影评论文本情感分析”,
“BERT相关论文、文章和代码资源汇总”,
“将不同长度的句子用BERT预训练模型编码,映射到一个固定长度的向量上”,
“自然语言处理工具包spaCy介绍”,
“现在可以快速测试一下spaCy的相关功能,我们以英文数据为例,spaCy目前主要支持英文和德文”
]
cluster = jiagu.text_cluster(docs)
print(cluster)
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
固定长度的向量上",
“自然语言处理工具包spaCy介绍”,
“现在可以快速测试一下spaCy的相关功能,我们以英文数据为例,spaCy目前主要支持英文和德文”
]
cluster = jiagu.text_cluster(docs)
print(cluster)
[外链图片转存中…(img-AJvL8rDz-1715722127997)]
[外链图片转存中…(img-daCJmmJr-1715722127997)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

