
MySQL数据库、表常用命令_对数据录里的一个表执行命令
赞
踩
数据库(MySQL):是一个具体的软件(实现数据库这个软件中,会用到很多的数据结构),这类软件的功能就是管理数据(组织和描述),管理起来的目的,就是为了用SQL这样的语言进行“增删改查”。
一、数据库分类
1.关系型数据库:
要求数据格式得规范统一,组织的数据都是以表的方式,类似于excel,可以把同类数据放到同一个表中,每一行就是一条记录,每一个记录中包含了很多列,这些列的类型和含义要求是统一的。对数据的校验更加容易做到,也更严格。eg:Oracle:数据库圈子中的王者(收费)、MySql、SqlServer(学校使用)
2.非关系型数据库:
不要求数据的格式规范统—(数据的格式更加灵活),组织数据是以**“文档”/“键值对”**方式来组织的,每个记录就是一个“文档”,这个文档里有哪些属性字段,都不必完全相同。对数据校验没那么严格,但是更高效,更适合于现在的分布式系统。eg:MongoDBRedis、Hbase。
二、MySQL相关基础
(1)MySQL是通过服务器管理数据的。
MySQL服务器上有若干个数据库(视为一组数据逻辑上的集合)
一个数据库包含若干个表
一个表包含若干行(若干条记录)
一个行包含若干列(若干个字段)
(2)MySQL是把数据存储在“外存”上的(包括但不限于:硬盘、U盘、光盘、软盘)。
原因:1 MySQL要管理的数据量比较大
2 期望有更低的成本
3 期望能够持久化存储(掉电之后数据不丢失)
(3)数据由控制台显示到界面上的流程
控制台输入命令——mysql客户端构造一个请求——请求通过网络发送给服务器——服务器收到请求,并解析出其中的命令——服务器执行命令,完成增删查改操作——将结果打包成响应——通过网络把响应发回给客户端——客户端在解析后最终显示到界面上。
三、MySQL数据库基础操作
1.显示数据库
show databases
- 1
2.创建数据库
字符集名:数据库中默认的utf8有些表情(emoji表情)表示不了,改为utf8mb4就是完整的字符集。
校验规则更准确的是说:比较规则
create database [if not exists] 创建的数据名 [create_specification]
create_specification:
character set 指定数据库采用的字符集名
collate 指定数据库字符集的校验规则名
- 1
- 2
- 3
- 4
3.删除数据库
drop database [if exists] 数据库名
- 1
4.使用数据库
use 数据库名
- 1
四、常用数据类型
1.数值类型
unsignd已被弃用
| 数据类型 | 大小 | 说明 | 对应的java值 |
|---|---|---|---|
| bit[(m)] | M指定位数,默认为1 | 二进制数,M范围从1到64,存储数值范围从0到2^M-1 | 常用Boolean对应BIT,此时默认是1位,即只能存0和1 |
| tinyint | 1字节 | Byte | |
| smallint | 2字节 | Short | |
| int | 4字节 | Integer | |
| bigint | 8字节 | Long | |
| float(m,d) | 4字节 | 单精度,M指定长度,D指定小数位数。会发生精度丢失 | Float |
| double(m,d) | 8字节 | Double | |
| decimal(m,d) | m/d最大值+2 | 双精度,M指定长度,D表示小数点位数。精确数值 | BigDecimal |
| numeric(m,d) | m/d最大值+2 | 双精度,M指定长度,D表示小数点位数。精确数值 | BigDecimal |
2.字符串类型
| 数据类型 | 大小 | 说明 | 对应java值 |
|---|---|---|---|
| varchar(size) | 0-65535字节 | 可变长度字符串 | String |
| text | 0-65535字节 | 长文本数据 | String |
| mediumtext | 0-16 777 215字节 | 中等长度文本数据 | String |
| blob | 0-65535字节 | 二进制形式的长文本数据 | byte[] |
3.日期类型
| 数据类型 | 大小 | 说明 | 对应java值 |
|---|---|---|---|
| datetime | 8字节 | 范围从1000到9999年,不会进行时区的 检索及转换 | java.util.Date、 java.sql.Timestamp |
| timestamp | 4字节 | 范围从1970到2038年,自动检索当前时 区并进行转换。 | java.util.Date、 java.sql.Timestamp |
五、MySQL表基础操作
1.创建表
创建表之前要先选中数据库
create table [表名] (列名 列类型,列名 列类型);
- 1
2.查看表
(1)查看表
show tables
- 1
(2)查看指定表结构
desc [表名]
- 1
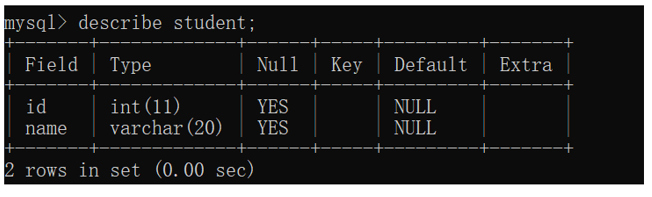
NULL:是否允许这个列的值为空值(null),类似于EXCLE里面有个值没填
Default:列的默认值,此处就为null。可以用特殊手段来修改
Extra:额外的约束
3.删除表
drop table [表名]
- 1
六、MySQL表的CRUD
1.新增(create)
(1)单行数据+全列插入
insert into [表名] values (列的值,列的值...);
- 1
(2)多行数据 + 指定列插入
列名与create创建中的相对应
insert into [表名] (列名,列名...) values
(列的值,列的值...),
(列的值,列的值...);
- 1
- 2
- 3
注:MySQL默认字符集是拉丁文的,不支持中文utf8,要修改字符集。
通过模糊查询来查看当前字符集
show variables like '%character%';
database 数据库
server 服务器
- 1
- 2
- 3
2.查询(Retrieve)
(1)全列查询(查整列)
select * from 表名;
- 1
(2)指定列查询
临时表,不保存在内存和磁盘中。
select [列名],[列名]... from [表名];
- 1
(3)查询字段为表达式
比如查总数
select [表达式],[表达式]... from [表名];
- 1
(4)查询信息起别名
as可省略
select [列名],[表达式] as [别名] from [表名];
- 1
(5)去重查询:distinct
seclect distinct [列名],[表达式]... from [表名];
- 1
(6)排序:obey by
适合在硬盘上排序
可以指定按多列排序,若列1相同则按列2排。NULL视为最小值。
默认顺序:升序
desc:降序
select [列名],[表达式]...from [表名] obey by [列名1],[列名2] [desc];
- 1
(7)条件查询:where
比较运算符
| 运算符 | 说明 |
|---|---|
| >,>=,<,<= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=,<> | 不等于 |
| between a0 and a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| in(option,…) | 如果是 option 中的任意一个,返回 TRUE(1) |
| is null | 是 NULL |
| in not null | 不是 NULL |
| like | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符
| 运算符 | 说明 |
|---|---|
| and | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| or | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| not | 条件为 TRUE(1),结果为 FALSE(0) |
where条件可以使用表达式,不可以使用别名去设置条件
and的优先级高于or
模糊查询:like
-- %(通配符)匹配任意多个字符(也可以是数字)
-- _匹配的任意一个字符
select [列名] from [表名] where [列名] like '%茗%' --查到的都是中间有茗字的
select [列名] from [表名] where [列名] like '茗_' --查到的是茗啥
- 1
- 2
- 3
- 4
NULL的查询:is [not] null
select [列名] from [表名] where [列名] is not null --列名已知
select [列名] from [表名] where [列名] is null --列名未知
- 1
- 2
(8)分页查询:limit
有些数据太多要考虑到数据库服务器磁盘IO和数据库客户端到服务器的网络IO的容量,所以设置分页查询。
select ... from [表名] where obey by limit n;
-- 后两个表达意思一样 s 从第几条数据开始,n选几条结果
select ... from [表名] where obey by limit s,n;
select ... from [表名] where obey by limit n offset s;
eg:每页有3条记录,显示三页
select ... from [表名] where obey by limit 3 offset 0;-- 第一页,从0条数据开始
select ... from [表名] where obey by limit 3 offset 3;-- 第二页,从第3条数据开始
select ... from [表名] where obey by limit 3 offset 6;-- 第三页,从第6条数据开始
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
3.修改(Update)
updata [列名],[列名] set [列名]=[列名值],[列名]=[列名值] where 条件
- 1
4. 删除(Delete)
delect from [表名] where 条件;
- 1


