
- 1基于FPGA的简易计算器Verilog代码Quartus仿真_verilog模拟计算器
- 2鸿蒙开发-UI-布局-栅格布局_鸿蒙vp
- 3Interview之AI:人工智能领域岗位求职面试—人工智能算法工程师知识框架及课程大纲(AI基础之数学基础/数据结构与算法/编程学习基础、ML算法简介、DL算法简介)来理解技术交互流程_ai算法工程师要学什么
- 4python -tkinter基础学习3_python tkinter colspawn
- 5浅谈以数据结构的视角去解决算法问题的步骤_数据结构解决问题的步骤
- 6操作系统学习笔记(八):连续内存分配——碎片整理_操作系统对内存碎片的合并
- 7基于Python语言的Web框架flask实现的校园二手物品发布平台_flask校园二手交易网站
- 8mysql数据库 set类型_MySQL数据库数据类型之集合类型SET测试总结
- 9记最近一次Nodejs全栈开发经历_nodejs 开发思维
- 102023年第三届纳米材料与纳米技术国际会议(NanoMT 2023)_2023中美纳米医学与纳米生物技术年会
文档基础模型引领文档智能走向多模态大一统_文档智能多模态模型
赞
踩
编者按:自2019年以来,微软亚洲研究院在文档智能领域进行了诸多探索,开发出一系列多模态任务的文档基础模型 (Document Foundation Model),包括 LayoutLM (v1、v2、v3) 、LayoutXLM、MarkupLM 等。这些模型在诸如表单、收据、发票、报告等视觉富文本文档数据集上都取得了优异的表现,获得了学术界和产业界的广泛认可,并已应用在包括 Azure Form Recognizer、AI Builder、Microsoft Syntex 等在内的微软产品中,赋能企业和机构的数字化转型。
你是否曾经在核销发票信息时,被涵盖抬头、开票日期、商品内容数量、单价、金额等多种信息且形式不一的发票搞得无从下手?处理重要的商业合同,小心翼翼,生怕弄错一位小数点,造成不可估量的经济损失?面对海量的简历,劳心劳力一一过目,不想错过每一位人才?除此之外,保险保单、业务报表、商务邮件、发货订单…… 商业活动中还有各种各样的文档需要处理。
随着企业数字化转型,各种文档、图表、图像内容的数字化已经成为企业一项重要的工作。但是面对大量质量参差不齐的扫描文件,版式各异的网页、电子文档,人工操作不仅费时费力、效率低,还容易出错,如何才能高效地提取、整理和分析文档中的信息?幸运的是,文档智能 (Document AI) 技术的出现将员工和企业从重复繁锁的文档数字化工作中解放了出来。

常见的商业文档示例(从左至右):表单、收据、发票、报告
文档智能是通过计算机进行自动阅读、理解以及分析商业文档的过程,是自然语言处理 (NLP) 和计算机视觉 (CV) 交叉领域的重要研究方向。深度学习技术的普及极大地推动了文档智能的发展,以文档版面分析、文档信息抽取、文档视觉问答以及文档图像分类等为代表的文档智能任务均有显著的性能提升,该技术也已经在帮助企业节约运营成本、提高员工效率、降低人为错误等方面发挥了重要作用。
从文本到多模态,文档智能模型逐步进化解锁新技能
微软亚洲研究院对文档智能的系列研究始于2019年。在对深度学习进行深入研究时,研究员们希望可以从公开的文档中抽取有用的信息,建立知识库,以支持深度学习模型的预训练任务。然而来自真实世界的文档并不是结构化的数据,如何从杂乱的文档中提取出结构化的文本信息就成了研究员们要解决的第一个问题。
对此,微软亚洲研究院提出了统一预训练语言模型 UniLM,它既能阅读文档又能自动生成内容。UniLM 模型在抽象摘要、生成式问答和语言生成数据集的抽样领域均取得了优异的成绩。同时,研究员们还将模型从英文扩展到了更多语言,推出了 InfoXLM 模型。这些只针对文本信息处理的模型方法,满足了当时研究工作的需求,然而在现实场景中,文档内容并不是只有文字,还包含各种各样的字体、颜色、下划线等布局和风格信息。
2019年底,微软亚洲研究院结合 NLP 和 CV 技术,推出了通用文档理解预训练模型 LayoutLM,并第一次在文档级预训练中将文本与布局信息联合训练,其在 IIT-CDIP Test Collection 1.0 数据集约一千一百万张的扫描文档图像上进行了预训练,该数据集包含信件、备忘录、电子邮件、表格、票据等各式各样的文档类型。LayoutLM 在表格理解、票据理解、文档图像分类等任务的实验上获得了优于其它模型的结果,并有效改善了以往模型在具体场景中没有利用大规模无标注数据,且模型难以泛化的问题。随后在 LayoutLMv2 版本中,研究员们将视觉特征信息融入到预训练过程中,提升了模型的图像理解能力,从而将文本、布局和图像信息统一在一个框架中共同建模训练,使用一个模型就能更好地学习到不同模态之间的关联。
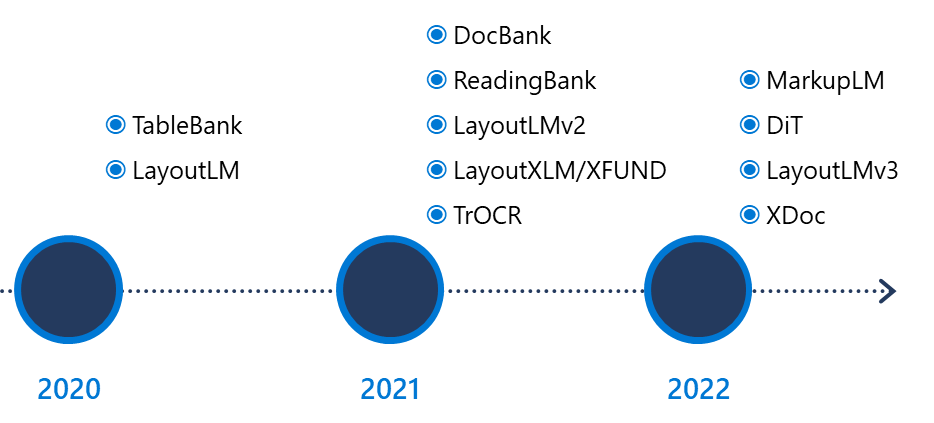
微软亚洲研究院文档智能系列研究发展历程
而为了满足不同用户对多语言的需求,研究员们在 LayoutLMv2 的基础上进一步提出了多语言文档理解任务的多模态预训练模型 LayoutXLM。LayoutXLM 模型不仅从各种不同语言的文档模板、布局、格式中获得了文本和视觉信号,同时还从文本、视觉和语言学的角度利用了局部不变的特性。除了在将近200种语言上进行了预训练外,为了更精准地评估多语言文档理解预训练模型的性能,研究员们还创建了多语言文档理解数据集 XFUND,其涵盖7种语言:中文、日文、西班牙文、法文、意大利文、德文、葡萄牙文。
另外,在众多视觉效果固定不变的文档之外,现实场景中还存在大量实时渲染的动态视觉富文本文档,如基于 HTML 的网页,或基于 XML 的 Office 文件等。为此,研究员们又开发了 MarkupLM 模型,可直接对动态文档的标记语言源代码进行处理,不需要任何额外的计算资源即可渲染生成动态文档的实际视觉效果。实验结果表明 MarkupLM 显著优于过去基于网页布局的方法,具有很高的实用性。
从最初的文本信息到布局信息,再到图像信息,微软亚洲研究院持续迭代文档智能技术和模型,并于今年发布了最新成果 LayoutLMv3,以统一的文本和图像掩码建模目标来预训练多模态模型。LayoutLMv3 的创新之处在于提出了一个词块对齐预训练目标,通过预测一个文本词的对应图像块是否被遮盖,并把图像细粒度对齐关系看作一种语言,来学习跨模态的对齐关系。与此同时,LayoutLMv3 首次将文本和图像同时进行掩码预测,进一步增强了跨模态学习的有效性。而在模型架构上,LayoutLMv3 不依赖复杂的 CNN 或 Faster R-CNN 网络来表征图像,直接利用文档图像的图像块,大大节省了参数并避免了复杂的文档预处理,进而让 LayoutLMv3 可适用于以文本为中心和以图像为中心的文档智能任务。
微软亚洲研究院首席研究员韦福如表示:“Layout(X)LM 系列模型是大规模预训练基础研究,推进不同任务、语言和模态基础模型‘大一统’ (Big Convergence),以及构建通用基础模型等研究的重要组成部分。”
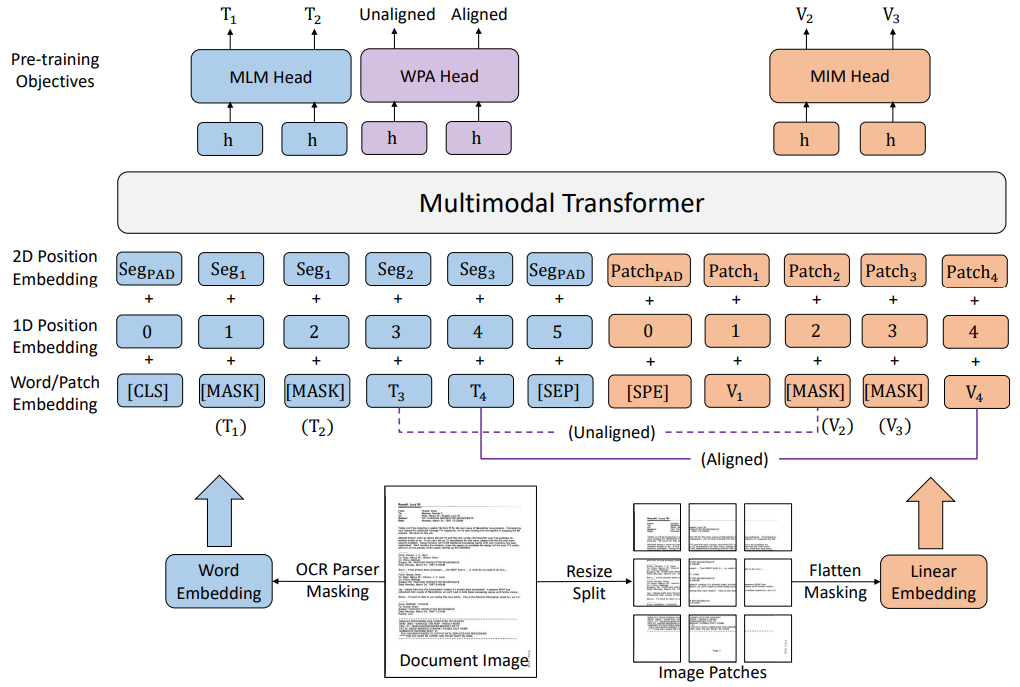
LayoutLMv3 的架构和预训练目标
“我们看到,在人工智能领域的研究中,包括 NLP、CV 等不同模态的研究都在呈现大一统 (Big Convergence) 的趋势,不同领域都在进行统一模型的研究。LayoutLM 的前两个版本着重解决的是语言处理问题,而 LayoutLMv3 最大的特点是可以同时应对 NLP 和 CV 两种模态的任务,在计算视觉领域取得了较大的突破,”微软亚洲研究院高级研究员崔磊表示。
微软亚洲研究院系列文档智能模型 GitHub 链接:GitHub - microsoft/unilm: Large-scale Self-supervised Pre-training Across Tasks, Languages, and Modalities
引领业界的基准模型
无论在大规模无标注数据的使用上,还是对文本、图片、多模态、多版式、多语言的富文本内容的理解上,LayoutLM 都极具领先性,尤其是 LayoutLMv3 更高的通用性和优越性,使之成为业界研究的基准模型,众多头部企业和机器人自动化 (RPA) 领域企业的文档智能产品中都有 LayoutLM 的身影。
“微软亚洲研究院不仅在基础模型和基准数据集的创新上取得了诸多成果,我们的模型还支撑了很多上层应用,让用户只用一个基础模型就能完成多项任务的训练。很多学术界和产业界的同仁都在用 LayoutLM 或 LayoutXLM 进行更多有意义的探索,促进文档智能领域向前发展。”崔磊说。
微软自身的产品更是一马当先,目前微软亚洲研究院在文档智能领域的一系列模型已应用到诸多微软的相关产品中,包括 Azure Form Recognizer、AI Builder、Microsoft Syntex 等。微软 Azure AI 合伙人研发经理张察表示,“我们很高兴能和微软亚洲研究院这些顶尖的研究员们合作。文档智能的基础模型极大地提高了我们在该领域应用、开发的效率,同时,也对文档智能的普及有着积极的推动作用。我们期待未来在这一领域有更多激动人心的进展。”
文档智能的下一步:大规模的统一框架
随着技术逐步走向成熟,文档智能已在金融、医疗、能源、政务、物流等不同行业实现了不同类型的应用。例如,在金融领域可实现财报分析和智能决策分析;在医疗领域推动病例数字化,分析医学文献和病例关联性,发现潜在治疗方案;在财务领域实现发票和订单的自动化信息提取,节省大量人工处理的时间成本。
但微软亚洲研究院并不会止步于此,崔磊表示,下一步研究员们将从提升模型规模、扩大训练数据规模和统一框架三个方面着手,进一步推进文档智能的基础研究。“NLP 领域的 GPT-3 证明了超大模型可以显著提升模型的性能,与此同时当前文档智能模型训练使用的数据还不及互联网数据的十分之一,还有很大的提升空间。我们希望不断扩展数据和模型规模,并实现一个统一的框架,把整个文档智能包含的要素都统一起来,这正是我们当前和未来研究工作的重点。”


