
- 1【AI大模型开发者指南】llama3 web部署实战与原理解析(logits_warper、logits_processor)_logitswarper
- 2linux进程地址,Linux进程地址空间简介
- 3【微信小程序】纯前端获取用户手机号码(正式发布无效)_网页获取手机号
- 4spark的指令参数_spark 命令行
- 5【数据结构】堆
- 6京东面经_京东市场面经
- 7【python】求多变量/样本(矩阵)之间的相关性系数_计算各样本量之间的相关系数
- 8Guitar Pro8最新2024破解版注册激活码许可证_guitar pro 8注册机
- 9React18笔记【慕课网imooc】【尚硅谷】【Vue3+React18 + TS4考勤系统】_vue3+react18+ts4完整笔记
- 10数据结构->链表分类与oj(题),带你提升代码好感
关于yolov5继续训练后精度断崖式下降的问题_yolov5精度一直震荡
赞
踩
问题描述:
训练模型,设定epoches:300轮,在290-300轮时精度上升了一个点,仅10轮就上升了一个点,说明模型仍有上升空间,离收敛还有一段时间的,但是问题是我设定的就是300轮,再以300轮得到的last.pt进行继续训练的时候,精度呈现断崖式下降即0.48(300epoches)————》0.4(301epoches)————》0.47(302epoches)————》0.48(302–400epoches),不仅断崖式下降,且从0.47-0.48仅仅涨一个点竟然花费了100轮的时间,而且在400-450epoches的轮次内0.477-0.483大概就这个区间重复了好几次轮回!!!!!我都以为他废了,没想到462epoches的时候又涨到了0.485之后就一直再上升了。
分析原因:
因为我啥都没变,数据集没变,batchsize没变,模型没变,超参没变,我变的只有epoches,所以问题就出现在了epoches了,epoches改变直接改变的就是lr(学习率)。在yolov5-5.0中有两个学习率的动态调整策略,分别是线性下降的一种,一种是余弦退火策略。
- 1
if opt.linear_lr:
lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
else:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
- 1
- 2
- 3
- 4
- 5
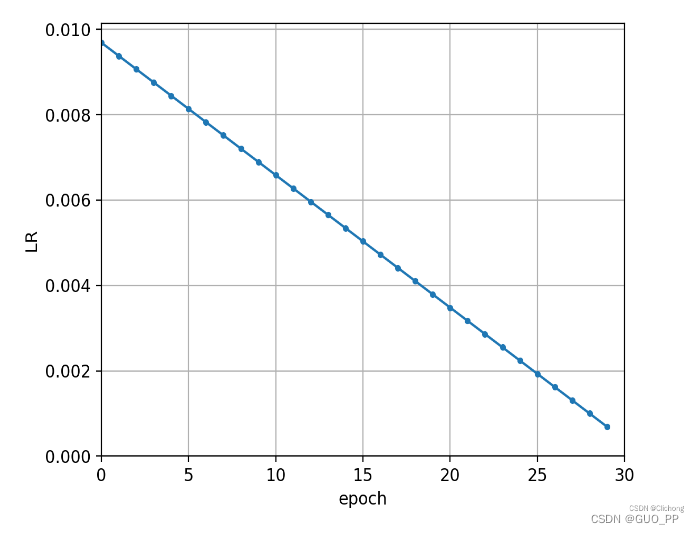
线性下降:
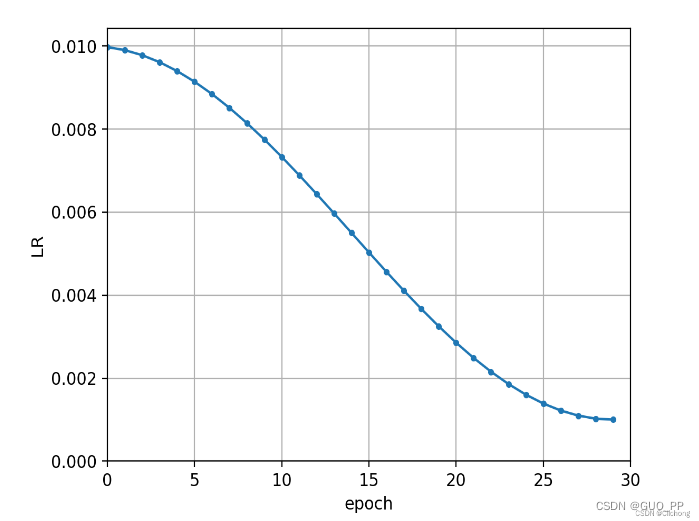
余弦退火:
二.
下面提出我猜测的原因,也不确定是这个原因,不过大概率是因为这个

在0-300轮之间,学习率线性下降,从初始值下降到几乎为0,最终精度也达到了0.48但是并没有收敛,看grident map大概就是这个样子,很多点ABCD马上就能找到最优值了但是截至了。
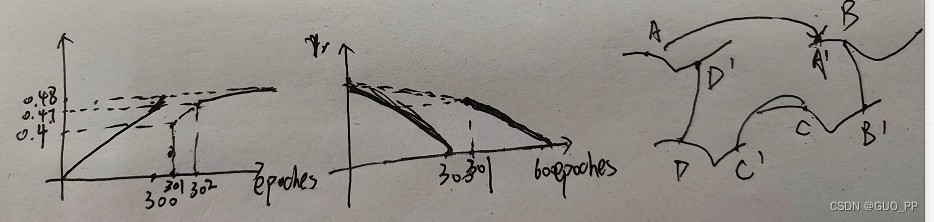
在300-460左右大概的轮,看学习率的图,在301处由于我们epoches设置为600,按照学习率的计算公式,学习率取的是初始学习率大概一半的值!!!!!而不是接近0的值。这就导致,本来模型此时此刻最需要的以小学习率,小步伐的动作去学习,反而代替为了以大学习率,大步伐下去学习,这就搞的A本来慢慢找能找到A最优,但是你跨步太大,啪!比如我跳到B点那个坑了,而且还回不去了,因为map是很复杂的么,你要回去还需要大量的训练!!!!!。这就导致模型精度忽然出现断崖式下降而且精度还很难找回去的原因了。
值得注意的是:我在做另外一组继续训练的实验的时候,虽然也出现了断崖式下降然后再涨回去的情况,但是涨的很快。这个可能就看模型本身了,或者看运气?这个也没有细究,有人感兴趣的话可以做实验讨论一下。
解决方法:
最后说一下解决方法哈,
反正,首先明确一点,你是不可能接上你300轮时候的精度了,除非你学习率按照方法三的来,但是得不偿失!
方法一:一个是我可以在继续训练后我改变一下lr的调整策略,比如300-600轮之间我以300轮时候的学习率为初始值,以300个epoches再线性下降。但是这样就有个问题,0-300轮的学习率下降的斜率和300-600轮学习率下降的斜率就不一样了,而且由于300轮时候的学习率本来就很小了,再用线性的方法去下降学习率去训练模型,很可能导致模型训练的很慢,会导致什么样的后果也就不知道了,可以尝试一下!!
方法二:或者还选择线性下降的方法,但是为了连贯性,301轮的学习率还选择300轮处的学习率,301轮-600轮的学习率选择一个斜率稍微大一点,但是也能连贯的下来的一种调整策略。
方法三:另一个就是,我就保持300轮时候的学习率继续学习下去,但是问题是,由于学习率没有再变小了,这样有可能找不到最优点
方法四:啥也不改,就按照上述分析原因的步骤来,但是这个我以这个yolov5模型下citypersons的数据集为例哈,效果不是很好。
其他的方法需要去尝试学习,看看别人咋做的,哎,这个都是经验之谈,也没有个明确的定论。

