
- 1128、仿真-基于51单片机空气质量粉尘pm2.5检测仿真设计(Proteus仿真+程序+参考论文+流程框架图+配套资料等)_mfz06粉尘传感器程序
- 2[开题报告]springboot个性化图书推荐系统31y94计算机毕业设计_图书推荐系统 开题报告
- 3Android SensorService源码分析(一)_android sensor注册源码
- 4【数据中台】开源项目(2)-Davinci可视应用平台_数据中台 开源
- 5毕业设计 基于51单片机的智能门禁系统的设计_门禁报警电路怎么连接单片机
- 6js实现搜索框的节流与防抖_js 搜索框适用节流还是防抖
- 7Spark MLlib 特征工程_spark ml 特征工程
- 8为什么 Microsoft Office 365 那么贵,还有那么多人用Microsoft 365?_office365有必要买吗
- 9推荐一款高效便捷的Android APK签名工具:Uber Apk Signer
- 10四种优秀的数据库设计工具
kafka性能测试_kafka单机入库速度
赞
踩
一.硬件配置
3台服务器配置如下:
CPU: 2物理CPU,12核/CPU , 48 processor Intel(R) Xeon(R) Silver 4116 CPU @ 2.10GHz
内存: 128GB
硬盘: 480GB*1 SSD盘(OS)+6TB*7 SAS盘
Broker节点数: 3个
网络:10GE
二.测试方案
2.1 测试套件
使用kafka官方提供的性能测试工具 kafka-perf-test
1)producer命令
| ./kafka-producer-perf-test.sh --producer-props bootstrap.servers="vm14:6667,vm15:6667,vm16:6667" --topic test-perf-1-1 --num-records 1000000 --record-size 512 --throughput 1000000 --topic TOPIC produce messages to this topic --num-records NUM-RECORDS nuMBer of messages to produce --payload-delimiter PAYLOAD-DELIMITER provides delimiter to be used when --payload-file is provided. Defaults to new line. Note that this parameter will be ignored if --payload-file is not provided. (default: \n) --throughput THROUGHPUT throttle maximum message throughput to *approximately* THROUGHPUT messages/sec --producer-props PROP-NAME=PROP-VALUE [PROP-NAME=PROP-VALUE ...] kafka producer related configuration properties like bootstrap.servers,client.id etc. These configs take precedence over those passed via --producer.config. --producer.config CONFIG-FILE producer config properties file. --print-metrics print out metrics at the end of the test. (default: false) --transactional-id TRANSACTIONAL-ID The transactionalId to use if transaction-duration-ms is > 0. Useful when testing the performance of concurrent transactions. (default: performance-producer- default-transactional-id) --transaction-duration-ms TRANSACTION-DURATION The max age of each transaction. The commitTransaction will be called after this time has elapsed. Transactions are only enabled if this value is positive. (default: 0) either --record-size or --payload-file must be specified but not both. --record-size RECORD-SIZE message size in bytes. Note that you must provide exactly one of --record-size or --payload-file. --payload-file PAYLOAD-FILE file to read the message payloads from. This works only for UTF-8 encoded text files. Payloads will be read from this file and a payload will be randomly selected when sending messages. Note that you must provide exactly one of --record-size or --payload-file. |
2)consumer命令
| ./kafka-consumer-perf-test.sh --broker-list "vm14:6667,vm15:6667,vm16:6667" --topic test-perf-1-1 --fetch-size 1000000 --messages 1000000 --threads 1 --broker-list <String: host> REQUIRED: The server(s) to connect to. --consumer.config <String: config file> Consumer config properties file. --date-format <String: date format> The date format to use for formatting the time field. See java.text. SimpleDateFormat for options. (default: yyyy-MM-dd HH:mm:ss:SSS) --fetch-size <Integer: size> The amount of data to fetch in a single request. (default: 1048576) --from-latest If the consumer does not already have an established offset to consume from, start with the latest message present in the log rather than the earliest message. --group <String: gid> The group id to consume on. (default: perf-consumer-61359) --help Print usage. --hide-header If set, skips printing the header for the stats --messages <Long: count> REQUIRED: The nuMBer of messages to send or consume --num-fetch-threads <Integer: count> NuMBer of fetcher threads. (default: 1) --print-metrics Print out the metrics. --reporting-interval <Integer: Interval in milliseconds at which to interval_ms> print progress info. (default: 5000) --show-detailed-stats If set, stats are reported for each reporting interval as configured by reporting-interval --socket-buffer-size <Integer: size> The size of the tcp RECV size. (default: 2097152) --threads <Integer: count> NuMBer of processing threads. (default: 10) --timeout [Long: milliseconds] The maximum allowed time in milliseconds between returned records. (default: 10000) --topic <String: topic> REQUIRED: The topic to consume from. |
2.2 Producer测试方案
第一组:测试单磁盘情况下topic的paritition数量变化对写入速度的影响
思路:partition数量对应的是producer的并行写入kafka的数量,通过本用例可以观察单磁盘情况下partition的增加是否对写入速度产生影响。
1 broker, 1 disks, 1 replication, record-size 512, records 10000000, throughput 1000000
| partition | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 1 | 115107.9137 | 56.21 | 546.61 | 744 |
| 3 | 152898.1851 | 74.66 | 410.3 | 647 |
| 5 | 172286.0638 | 84.12 | 363.76 | 647 |
| 7 | 196900.7817 | 96.14 | 316.89 | 587 |
| 9 | 191398.5492 | 93.46 | 325.96 | 582 |
结论:通过测试在单个节点单个磁盘不同数量partition下的写入速度,可以看出当在一定范围内(本例中为1-7)随着partition数量增加,写入速度会增加,超过极值点(本例中为7)后有下降趋势
第二组:测试磁盘增加对写入速度的影响
思路:磁盘数量对应kafka的服务端接收到producer的消息后,处理写入的并行数,一般会配置kafka的io.threads数量和磁盘的数量相等。通过本用例可以观察磁盘增加是否对写入速度产生影响。
1 broker, 5 partition, 1 replication, record-size 512, records 10000000, throughput 1000000
| disks | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 2 | 147303.6075 | 71.93 | 425.62 | 869 |
| 4 | 147331.8207 | 71.94 | 425.91 | 861 |
| 7 | 173391.3616 | 84.66 | 361.04 | 716 |
1 broker, 10 partition, 1 replication, record-size 512, records 10000000, throughput 1000000
| disks | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 2 | 174012.9118 | 84.97 | 359.21 | 610 |
| 4 | 188253.012 | 91.92 | 331.02 | 755 |
| 7 | 212075.5837 | 103.55 | 293.08 | 532 |
1 broker, 15 partition, 1 replication, record-size 512, records 10000000, throughput 1000000
| disks | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 2 | 177154.195 | 86.5 | 352.47 | 606 |
| 4 | 192126.6499 | 93.81 | 324.63 | 671 |
| 7 | 209784.3417 | 102.43 | 297.05 | 605 |
1 broker, 20 partition, 1 replication, record-size 512, records 10000000, throughput 1000000
| disks | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 2 | 172532.7812 | 84.24 | 361.79 | 621 |
| 4 | 192481.6661 | 93.99 | 323.99 | 613 |
| 7 | 214174.0378 | 104.58 | 289.85 | 755 |
结论:通过测试在单节点下挂载2块,4块,7块硬盘时的写入速度,分别在partition数量为5,10,15,20的情况下进行测试,可以看出不同partition数量时当硬盘数量增多时,写入速度都会增加,但是增量都不是特别显著,猜测是由于单个进程producer造成的写入速度瓶颈。
第三组:测试磁盘和parition数量关系对写入速度的影响
思路:当kafka在新建一个partition时,会选择所有kafka服务器中partition数量最少的目录来新建。单个topic的所有partition是均匀分布在服务器中的各个目录的,最好的情况下,将topic的partition均匀分配在不同的磁盘中可以最大化提升并行写入和读取的速度。另外,当paritition数量是磁盘数量的整数倍的时候,可以保证partition在磁盘中的均匀分布,当不成整数倍的时候,不能保证partition的均匀分布。
通过本用例可以观察磁盘和paritition的数量变化对性能的影响,以及磁盘和partition的数量对应的倍数关系是否对写入性能有影响。
1 broker, 2 disks, 1 replication, record-size 512, records 10000000, throughput 1000000
| partition | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 2 | 109996.4801 | 53.71 | 572.67 | 2578 |
| 4 | 174926.0937 | 85.41 | 358.69 | 826 |
| 8 | 193569.6173 | 94.52 | 323.65 | 740 |
| 16 | 220891.9617 | 107.86 | 282.22 | 418 |
| 32 | 183046.2558 | 89.38 | 341.95 | 1839 |
| 补充组 | ||||
| 12 | 210194.4298 | 102.63 | 296.18 | 520 |
| 14 | 205090.3423 | 100.14 | 304.13 | 572 |
| 16 | 220891.9617 | 107.86 | 282.22 | 418 |
| 18 | 203417.4125 | 99.32 | 304.77 | 602 |
| 20 | 189530.3438 | 92.54 | 329.59 | 684 |
测试2块硬盘时partition数量成倍增加时写入速度的变化,先以大步长进行测试,找到大致的极值范围,再缩小步长进行测试,最佳点大致在partition=16左右
1 broker, 4 disks, 1 replication, record-size 512, records 10000000, throughput 1000000
| partition | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 4 | 145342.4996 | 70.97 | 431.95 | 647 |
| 8 | 171004.4803 | 83.5 | 367.04 | 923 |
| 16 | 182328.7022 | 89.03 | 343.28 | 769 |
| 32 | 186863.4962 | 91.24 | 333.92 | 753 |
| 64 | 183705.3366 | 89.7 | 339.13 | 847 |
| 补充组 | ||||
| 18 | 195809.673 | 95.61 | 317.23 | 736 |
| 20 | 195182.8864 | 95.3 | 319.75 | 978 |
| 22 | 189243.4049 | 92.4 | 329.94 | 817 |
| 24 | 187230.8556 | 91.42 | 332.49 | 857 |
| 28 | 182969.2246 | 89.34 | 341.24 | 1602 |
测试4块硬盘时partition数量成倍增加时写入速度的变化,先以大步长进行测试,找到大致的极值范围,再缩小步长进行测试,最佳点大致在partition=20左右
1 broker, 7 disks, 1 replication, record-size 512, records 10000000, throughput 1000000
| partition | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 7 | 164972.9444 | 80.55 | 379.46 | 580 |
| 14 | 187747.5921 | 91.67 | 333.13 | 841 |
| 28 | 186198.9349 | 90.92 | 334.86 | 765 |
| 56 | 171812.4495 | 83.89 | 358.76 | 1313 |
| 补充组 | ||||
| 16 | 199632.6759 | 97.48 | 313.02 | 830 |
| 18 | 188786.1053 | 92.18 | 329.63 | 994 |
| 20 | 191769.2632 | 93.64 | 324.96 | 776 |
测试7块硬盘时partition数量成倍增加时写入速度的变化,先以大步长进行测试,找到大致的极值范围,再缩小步长进行测试,最佳点大致在partition=16左右
结论:通过测试不同磁盘数量,不同partition数量的情况下写入速度的变化,可以看出磁盘和partition的数量对应的倍数关系对写入速度的影响不大。
第四组:测试单条消息大小的影响:
思路: 由于处理单条消息额外的性能消耗,单条消息的大小可能会对性能产生影响。可以推测:随着消息大小变大,吞吐量增加,每秒处理的消息条数逐渐变少。通过本用例可以观察单条消息大小对性能的影响。
3 broker, 7 disks, 1 replication, 48 partition, records 10000000, throughput 1000000
| record-size | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 128 | 897988.5057 | 109.62 | 11.64 | 253 |
| 256 | 798594.4737 | 194.97 | 63.54 | 324 |
| 512 | 425170.068 | 207.6 | 136.19 | 1123 |
| 1024 | 227019.9096 | 221.7 | 129.93 | 990 |
| 2048 | 107975.0362 | 210.89 | 128.92 | 873 |
结论:通过测试在3个节点挂载7块硬盘时单条消息大小分别为128,256,512,1024,2048的情况下测试写入速度,可以看出当单条消息由128增大到256时每秒消息条数略有下降,写入速度几乎成倍增加,再成倍增大时相应的每秒消息条数也几乎成倍减少,写入速度略有增大,增大到2048时不增反降,因此单条消息大小为256时即可以保持较高的写入速度,又可以保持每秒传输的消息数量较多,单条消息大小不应该超过1024。
第五组:测试副本数对写入性能的影响:
思路: 为了保证可靠性,一般会存多副本,但是副本的增加可能会降低kafka的写入性能,通过本用例可以观察副本数对kafka的写入性能的影响。
3 broker, 1 disks, 21 partition, record-size 512, records 10000000, throughput 1000000
| replication | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 1 | 422243.8036 | 206.17 | 143.41 | 541 |
| 2 | 409701.7371 | 200.05 | 148.78 | 523 |
| 3 | 406702.4565 | 198.59 | 148.98 | 927 |
结论:通过测试在3个节点挂载单块硬盘时,21partition,副本数量分别为1,2,3时的写入速度,可以看出当副本增加时写入速度略有下降,但不明显,差别很微小,这里猜测是由于cpu和网络并没有完全跑满,有富余的能力处理额外的副本。
* 补充:测试多进程producer下副本数对写入性能的影响
思路:为验证第五组测试的猜想,本例使用3*5个进程的producer产生数据,将cpu/网络资源跑满,再增加副本数量,来验证以上猜想以及副本数量在满cpu/网络的情况下对写入速度的影响。
3 broker, 1 disks, 21 partition, record-size 512, records 10000000, throughput 1000000,acks=-1
| replication | records/sec(sum) | MB/sec(sum) |
| 1 | 665.96 | 1363900 |
| 2 | 312.23 | 639443.6 |
| 3 | 196.38 | 402189.8 |
结论:可以看出当采用多进程的producer的时候,随着副本数量增加,由于kafka需要额外复制副本,写入速度下降了很多。
第六组:测试服务器个数对写入性能的影响:
思路: kafka是一个支持线性扩展的分布式消息中间件,写入性能会随着增加服务器而增加,通过本用例可以观察增加服务器数量对kafka的写入性能的影响。
1 broker, 1 disks, 1 replication, record-size 512, records 10000000, throughput 1000000
| partition | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 1 | 115107.9137 | 56.21 | 546.61 | 744 |
| 3 | 152898.1851 | 74.66 | 410.3 | 647 |
| 5 | 172286.0638 | 84.12 | 363.76 | 647 |
| 7 | 196900.7817 | 96.14 | 316.89 | 587 |
| 9 | 191398.5492 | 93.46 | 325.96 | 582 |
3 broker, 1 disks, 1 replication, record-size 512, records 10000000, throughput 1000000
| partition | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 1 | 77468.93496 | 37.83 | 814.41 | 1319 |
| 3 | 220448.8338 | 107.64 | 282.7 | 919 |
| 5 | 288383.8966 | 140.81 | 215.23 | 626 |
| 7 | 337336.3919 | 164.72 | 182.23 | 679 |
| 9 | 366609.2312 | 179.01 | 168.02 | 712 |
*这里可以看到broker的增加可以明显提高Kafka集群的写入性能,但没有达到理想的或近似线性的扩容。
结论:通过分别测试在1个节点和3个节点挂载单块硬盘时,不同partition数量的写入速度,可以看出当partition数量较少时(本例中为1partition),broker数量增多但由于只有1partition因此写数据时还是只往一个broker中写数据,因此没有提升写入速度,因为增加了寻找partition的开销导致写入速度下降,而当partition数量较多时,所有的partition会分散到不同的broker上,同时写数据,写入速度有明显提升。
第七组:测试开启异步写入对写入性能的影响:
思路: 在同步写入模式中,必须在落盘后才会写入成功,而在异步写入模式中,写入到kafka的内存中即可,开启异步写入应该会对写入性能产生明显提升。通过本用例可以观察异步写入对kafka写入性能的影响。
3 broker, 7 disks, 49 partition, 3 replication, record-size 512, records 10000000, throughput 1000000
| acks | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 0 | 451814.0333 | 220.61 | 130.81 | 534 |
| 1 | 411336.4321 | 200.85 | 143.81 | 573 |
| -1 | 144789.0424 | 70.7 | 421.57 | 1677 |
3 broker, 7 disks, 49 partition, 2 replication, record-size 512, records 10000000, throughput 1000000
| acks | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 0 | 457414.6922 | 223.35 | 130.35 | 531 |
| 1 | 432208.1514 | 211.04 | 137.79 | 714 |
| -1 | 235687.855 | 115.08 | 260.54 | 710 |
3 broker, 7 disks, 49 partition, 1 replication, record-size 512, records 10000000, throughput 1000000
| acks | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 0 | 456246.0078 | 222.78 | 130.44 | 429 |
| 1 | 425170.068 | 207.6 | 138.88 | 920 |
| -1 | 409819.2697 | 200.11 | 144.16 | 586 |
说明:
acks=0 the producer will not wait for any acknowledgment from the server at all.
acks=1 the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers.
acks=-1 the leader wait for the full set of in-sync replicas to acknowledge the record.
结论:通过测试在3个节点挂载7块硬盘时不同副本数下,测试不同的acks位下的写入速度,可以看出多副本时acks=0时速度最快,其次时acks=1时速度略小于acks=0的情况,而默认的acks=-1/all的情况最差,但单副本的情况下区别不明显。
第八组:测试ssd对写入性能的影响:
3 broker, 1 disks, 1 replication, records 10000000, throughput 1000000
| partition | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 1 | 77468.93496 | 37.83 | 814.41 | 1319 |
| 3 | 220448.8338 | 107.64 | 282.7 | 919 |
| 5 | 288383.8966 | 140.81 | 215.23 | 626 |
| 7 | 337336.3919 | 164.72 | 182.23 | 679 |
| 9 | 366609.2312 | 179.01 | 168.02 | 712 |
3 broker, 1 ssd, 1 replication, records 10000000, throughput 1000000
| partition | records/sec | MB/sec | avg latency(ms) | max latency(ms) |
| 1 | 79650.81085 | 38.89 | 792.23 | 995 |
| 3 | 197339.8587 | 96.36 | 315.64 | 1012 |
| 5 | 250356.7584 | 122.24 | 247.9 | 677 |
| 7 | 334784.0643 | 163.47 | 184.69 | 506 |
| 9 | 359027.7528 | 175.31 | 171.19 | 582 |
结论:通过测试在3个节点挂载1块硬盘/ssd时不同partition的写入速度,可以看出硬盘和ssd的写入速度相差不是很大,ssd盘写入速度甚至略小与sas盘,猜测可能和ssd盘为系统盘有关系。
第九组:测试producer线程数对写入性能的影响:
1 broker, 7 disks , 21 partition, 1 replication, records 1000000, throughput 1000000
| threads | records/sec | MB/sec |
| 1 | 67930.1678 | 33.1690 |
| 10 | 536480.6867 | 261.9535 |
| 20 | 563063.0631 | 274.9331 |
| 30 | 475285.1711 | 232.0728 |
结论:通过测试在1个节点挂载7块硬盘producer采用不同线程数时的写入速度,可以看出线程数在20左右的时候达到峰值,另有测更多partition和broker的情况下峰值时的线程数也在20左右,猜测瓶颈时在producer客户端。
* 在多线程模式下broker数量对写入性能的影响:
22 threads, 7 disks , 1 replication, records 1000000, throughput 1000000
| broker | partition | records/sec | MB/sec |
| 1 | 7 | 553703.2115 | 270.3629 |
| 3 | 7 | 406499.1870 | 198.4859 |
| 3 | 21 | 393541.1255 | 192.1588 |
结论:通过测试在22线程下1个broker和三个broker的写入速度,可以看到随着broker数量增加速度反而下降,与预期相反,也从侧面说明了可能时producer本身的性能达到了瓶颈。
第十组:测试磁盘大小对写入性能的影响:
另外3台服务器配置如下:
CPU: 2物理CPU,12核/CPU , 48 processor Intel(R) Xeon(R) Gold 5118 CPU @ 2.30GHz(这里cpu主频有变化)
内存: 128GB
硬盘: 480GB*1 SSD盘(OS)+4TB*7 SAS盘(这里硬盘大小有变化)
Broker节点数: 3个
对比第六组测试:
1 broker, 1 disks, 1 replication, records 10000000, throughput 1000000
| partition | records/sec (2.3GHZ cpu) | records/sec (2.1GHZ cpu) | MB/sec (2.3GHZ cpu) | MB/sec (2.1GHZ cpu) | avg latency(ms) (2.3GHZ cpu) | avg latency(ms) (2.1GHZ cpu) | max latency(ms) (2.3GHZ cpu) | max latency(ms) (2.1GHZ cpu) |
| 1 | 286196.7316 | 115107.9137 | 139.74 | 56.21 | 218.8 | 546.61 | 471 | 744 |
| 3 | 406421.4591 | 152898.1851 | 198.45 | 74.66 | 153.01 | 410.3 | 379 | 647 |
| 5 | 448350.0717 | 172286.0638 | 218.92 | 84.12 | 136.45 | 363.76 | 243 | 647 |
| 7 | 480145.9644 | 196900.7817 | 234.45 | 96.14 | 128.02 | 316.89 | 208 | 587 |
| 9 | 475036.8154 | 191398.5492 | 231.95 | 93.46 | 128.89 | 325.96 | 213 | 582 |
3 broker, 1 disks, 1 replication, records 10000000, throughput 1000000
| partition | records/sec (2.3GHZ cpu) | records/sec (2.1GHZ cpu) | MB/sec (2.3GHZ cpu) | MB/sec (2.1GHZ cpu) | avg latency(ms) (2.3GHZ cpu) | avg latency(ms) (2.1GHZ cpu) | max latency(ms) (2.3GHZ cpu) | max latency(ms) (2.1GHZ cpu) |
| 1 | 260613.4841 | 77468.93496 | 127.25 | 37.83 | 240.41 | 814.41 | 472 | 1319 |
| 3 | 320821.3025 | 220448.8338 | 156.65 | 107.64 | 193.25 | 282.7 | 632 | 919 |
| 5 | 520562.2072 | 288383.8966 | 254.18 | 140.81 | 117.29 | 215.23 | 595 | 626 |
| 7 | 374882.8491 | 337336.3919 | 183.05 | 164.72 | 163.95 | 182.23 | 968 | 679 |
| 9 | 482346.1316 | 366609.2312 | 235.52 | 179.01 | 125.88 | 168.02 | 414 | 712 |
结论:通过测试在两个不同的集群测试相同条件下的写入速度,来验证磁盘大小对写入速度的影响,这里结果相差较大,与预期的影响较小有较大差别,因为两个集群的cpu的主频有差别,所以这里的测试结果不能得到一个准确的评判,这里猜测由于cpu的性能提升而引起的写入速度增大的可能性更大。
2.3 Producer多并发情况下的性能评测
通过2.2节第九组测试用例《测试producer线程数对写入性能的影响》的结果可以看出,当同一个进程中的Producer线程数达到特定值(测试集群中为22),Producer的写入速度最快。
同时,在Producer的线程数为22时,当Broker从1增加到3,写入速度反而有小幅下降。这是比较反常的。
因此我们猜测,服务器的cpu处理性能是限制Producer写入速度的关键原因之一。
另外,由于每个Producer线程都在堆内存中有自己的buffer.memory缓冲区,同一个进程的所有线程又共用jvm的堆内存,因此可以考虑JVM的垃圾回收和内存分配机制也会影响Producer的写入性能。
基于上述的猜想,可得出如下推论:
1. 单机单线程producer的写入性能,受单个cpu核心的性能限制。
2. 单机多线程producer的写入性能,受服务器cpu总处理能力,以及线程所属客户端进程堆内存大小的限制。由于每个producer都会使用一个默认的32MB的buffer.memory内存缓冲区,当进程的堆内存分配不足时,会导致频繁GC,进而影响producer的写入性能。
3. 单机多进程producer的写入性能,受服务器cpu总处理能力的限制。
4. 多机多进程producer的写入性能,受kafka集群总处理能力的限制。
下面通过六组测试用例,对如上猜想和推论作验证。
测试条件:2Broker,14Partition,吞吐量 240000records/s,单条消息大小为512bytes
第一组 单机单线程producer的写入性能
| records/sec | MB/sec | avg latency | max latency |
| 261793 | 127.83 | 231.81 | 573 |
第二组 单机24线程producer的不同堆内存配置下的写入性能
| 堆内存配置 | records/sec | MB/sec |
| 512MB 仅设置Xmx | 423584 | 206.8 |
| 1024MB 仅设置Xmx | 551875 | 269.47 |
| 2048MB 仅设置Xmx | 900737 | 439.81 |
| 2048MB 设置Xms=Xmx | 927298 | 452.78 |
| 4096MB 仅设置Xmx | 900737 | 439.81 |
| 4096MB 设置Xms=Xmx | 1305480 | 637.44 |
增加堆内存对提升性能有明显帮助,当堆内存到4096MB时,设置Xms=Xmx能显著提升性能。
第三组 单机多进程producer的写入性能
多个独立进程和单个线程的多个进程相比,写入性能有所提升。24线程的Producer写入速度为637.44MB,而24进程的Producer写入速度为726.17MB/s。
1)单机5进程
| 进程号 | records/sec | MB/sec | avg latency | max latency |
| 1 | 233934 | 114.23 | 252.16 | 751 |
| 2 | 232828 | 113.69 | 252.03 | 756 |
| 3 | 232460 | 113.51 | 252.88 | 754 |
| 4 | 232471 | 113.51 | 253.65 | 748 |
| 5 | 232401 | 113.48 | 253.06 | 740 |
| 合计 | 1164094 | 568.42 | 252.756 | 756 |
2)单机8进程
| 进程号 | records/sec | MB/sec | avg latency | max latency |
| 1 | 141310 | 69 | 424.15 | 1028 |
| 2 | 140773 | 68.74 | 426.79 | 1126 |
| 3 | 140552 | 68.63 | 430.17 | 950 |
| 4 | 140738 | 68.72 | 425.97 | 1107 |
| 5 | 140394 | 68.55 | 426.58 | 868 |
| 6 | 140044 | 68.38 | 430.2 | 1012 |
| 7 | 139155 | 67.95 | 434 | 873 |
| 8 | 138607 | 67.68 | 433.3 | 1104 |
| 合计 | 1121573 | 547.67 | 503.2 | 1126 |
3)单机24进程
| 进程号 | records/sec | MB/sec | avg latency | max latency |
| 1 | 62516 | 30.53 | 963.44 | 2560 |
| 2 | 62455 | 30.5 | 967.1 | 2562 |
| 3 | 62374 | 30.46 | 963.11 | 1965 |
| 4 | 62354 | 30.45 | 962.21 | 2116 |
| 5 | 62302 | 30.42 | 970.93 | 2361 |
| 6 | 62312 | 30.43 | 962.87 | 2333 |
| 7 | 62175 | 30.36 | 983.57 | 2145 |
| 8 | 62125 | 30.33 | 980.07 | 2188 |
| 9 | 62107 | 30.33 | 970.76 | 2234 |
| 10 | 62043 | 30.29 | 974.63 | 2584 |
| 11 | 62068 | 30.31 | 973.67 | 2128 |
| 12 | 61958 | 30.25 | 978.48 | 2512 |
| 13 | 61931 | 30.24 | 976.52 | 2280 |
| 14 | 61906 | 30.23 | 975.36 | 2211 |
| 15 | 61845 | 30.2 | 983.59 | 2411 |
| 16 | 61773 | 30.16 | 980.99 | 2438 |
| 17 | 61700 | 30.13 | 984.88 | 2366 |
| 18 | 61677 | 30.12 | 987.6 | 2073 |
| 19 | 61599 | 30.08 | 981.48 | 2083 |
| 20 | 61563 | 30.06 | 988.25 | 2426 |
| 21 | 61639 | 30.1 | 985.35 | 1918 |
| 22 | 61632 | 30.09 | 983.79 | 2350 |
| 23 | 61543 | 30.05 | 988.65 | 2423 |
| 24 | 61549 | 30.05 | 990.83 | 2061 |
| 合计 | 1487146 | 726.17 | 977.42 | 2584 |
第四组 多机多进程producer的写入性能
该用例证明,Producer写入的瓶颈经常发生在客户端服务器,受限于客户端服务器的cpu处理能力。
如下用例中,随着客户端从2台服务器增加到3台服务器,kafka集群的写入的总吞吐量从1066.53MB/s上升到了1694.22MB/s。
在达到kafka集群的处理能力瓶颈之前,随着客户端服务器的增加,kafka集群的吞吐量应该是线性提升的。
本测试用例中,kafka集群由2台broker组成,因此NIC的上限应为2*10Gb/s(实际用iperf测试的结果为7Gb/s-9Gb/s),这也是kafka集群吞吐量的理论上限值。
由于只有三台服务器可以用来作为Producer客户端进行测试,并且还存在本地写入数据获得的网络流量节约收益的影响,本测试用例中的1694.22MB/s还远没有达到集群吞吐量上限。
1)2节点客户端,5producer进程/节点
| 机器号-进程号 | records/sec | MB/sec | avg latency | max latency |
| vm16_1 | 199664 | 97.49 | 292.58 | 801 |
| vm16_2 | 198822 | 97.08 | 299.17 | 740 |
| vm16_3 | 198483 | 96.92 | 297.13 | 797 |
| vm16_4 | 196749 | 96.07 | 290.9 | 796 |
| vm16_5 | 195549 | 95.48 | 298.77 | 803 |
| vm15_1 | 239854 | 117.12 | 165.63 | 891 |
| vm15_2 | 239842 | 117.11 | 182.91 | 870 |
| vm15_3 | 238914 | 116.66 | 233.13 | 903 |
| vm15_4 | 238504 | 116.46 | 242.8 | 913 |
| vm15_5 | 237857 | 116.14 | 247.24 | 1005 |
| 合计 | 2184238 | 1066.53 | 255.026 | 1005 |
2)3节点客户端,5producer进程/节点
| 机器号-进程号 | records/sec | MB/sec | avg latency | max latency |
| vm16_1 | 232309 | 113.43 | 260 | 880 |
| vm16_2 | 232331 | 113.44 | 258.14 | 821 |
| vm16_3 | 230669 | 112.63 | 262.34 | 848 |
| vm16_4 | 229378 | 112 | 262.2 | 914 |
| vm16_5 | 225794 | 110.25 | 262.96 | 863 |
| vm15_1 | 236060 | 115.26 | 254.35 | 811 |
| vm15_2 | 236540 | 115.5 | 251.07 | 811 |
| vm15_3 | 232363 | 113.46 | 257.94 | 824 |
| vm15_4 | 231117 | 112.85 | 256.49 | 851 |
| vm15_5 | 230223 | 112.41 | 258.53 | 886 |
| vm14_1 | 231867 | 113.22 | 259 | 1077 |
| vm14_2 | 231042 | 112.81 | 259.87 | 1051 |
| vm14_3 | 230001 | 112.31 | 260.51 | 1028 |
| vm14_4 | 230043 | 112.33 | 260.11 | 1021 |
| vm14_5 | 230033 | 112.32 | 260.52 | 1037 |
| 合计 | 3469770 | 1694.22 | 258.9353333 | 1077 |
第五组 多机多进程producer在单机Broker下的写入性能
本用例将Broker数量减小至1台,7parititon,部署在vm14上,以测试多机多进程Producer写入单机Broker的吞吐量上限。
可以看到其中vm15,vm16写入vm14的网络流量之和达到800MB/s,接近vm14的网卡上限。
而vm14上的客户端由于不需要走网络流量,使得三台producer客户端写入Broker的速度达到1238.7MB/s,高于vm14的网卡速率。
因此可以假设:Kafka的写入速度瓶颈并不在磁盘上,而是在网卡上。该假设将在下一组实验中论证。
| 机器号-进程号 | records/sec | MB/sec | avg latency | max latency |
| vm16_1 | 169136 | 82.59 | 364.4 | 1132 |
| vm16_2 | 167914 | 81.99 | 366.66 | 1153 |
| vm16_3 | 167324 | 81.7 | 368.2 | 1180 |
| vm16_4 | 167622 | 81.85 | 367.47 | 1227 |
| vm16_5 | 165332 | 80.73 | 373.78 | 1187 |
| vm15_1 | 162723 | 79.45 | 377.7 | 789 |
| vm15_2 | 161274 | 78.75 | 380.7 | 867 |
| vm15_3 | 160632 | 78.43 | 382.7 | 871 |
| vm15_4 | 158836 | 77.56 | 387.53 | 863 |
| vm15_5 | 157898 | 77.1 | 389.6 | 881 |
| vm14_1 | 180564 | 88.17 | 339.76 | 756 |
| vm14_2 | 180108 | 87.94 | 340 | 749 |
| vm14_3 | 179700 | 87.74 | 341.87 | 846 |
| vm14_4 | 179166 | 87.48 | 343.58 | 840 |
| vm14_5 | 178635 | 87.22 | 344.29 | 799 |
| 合计 | 2536864 | 1238.7 | 364.5493333 | 1227 |
第六组 多机多进程producer在单机Broker下缩减磁盘后的写入性能
在上一组测试中证明单个服务器Broker挂满磁盘的情况下,从其他客户端写入数据的吞吐量可以接近网络流量上限,尝试缩减Broker的磁盘个数,观察是否仍然能够使写入速度达到网络上限?
1)修改磁盘数:7=>6 partition7=>6
vm16,vm15流量之和为754.14MB/s
| 机器号-进程号 | records/sec | MB/sec | avg latency | max latency |
| vm16_1 | 158861 | 77.57 | 389.48 | 1114 |
| vm16_2 | 158548 | 77.42 | 391.12 | 1136 |
| vm16_3 | 158478 | 77.38 | 389.29 | 1118 |
| vm16_4 | 158323 | 77.31 | 390.9 | 1116 |
| vm16_5 | 158192 | 77.24 | 391.15 | 1121 |
| vm15_1 | 150838 | 73.65 | 409.12 | 1908 |
| vm15_2 | 150957 | 73.71 | 409.14 | 1915 |
| vm15_3 | 150747 | 73.61 | 412.26 | 1903 |
| vm15_4 | 150756 | 73.61 | 409.54 | 1908 |
| vm15_5 | 148774 | 72.64 | 413.31 | 1921 |
| vm14_1 | 156474 | 76.4 | 381.89 | 1899 |
| vm14_2 | 155705 | 76.03 | 391.09 | 1893 |
| vm14_3 | 154985 | 75.68 | 399.37 | 1910 |
| vm14_4 | 154971 | 75.67 | 398.95 | 1887 |
| vm14_5 | 155178 | 75.77 | 398.21 | 1900 |
| 合计 | 2321787 | 1133.69 | 398.3213333 | 1921 |
尝试降低本地客户端的影响:虽然磁盘数量从7降到6,但vm15,vm16写入vm14的流量仍达到915MB/s,接近或达到网卡速率上限。
若不考虑在kafka所在服务器上部署producer,可以稍微降低磁盘的配置,因为由于万兆网卡的速率限制,Broker上的磁盘写入能力并没有充分利用起来。
另一方面,将producer部署在kafka的Broker所在节点上,虽然提升了磁盘利用率,但可能会造成Broker中的内存和cpu资源被其他进程抢占,造成意外情况。
| 机器号-进程号 | records/sec | MB/sec | avg latency | max latency |
| vm16_1 | 195863 | 95.64 | 312.67 | 605 |
| vm16_2 | 194355 | 94.9 | 316.09 | 717 |
| vm16_3 | 194084 | 94.77 | 316.81 | 706 |
| vm16_4 | 193963 | 94.71 | 316.49 | 611 |
| vm16_5 | 192938 | 94.21 | 319.66 | 767 |
| vm15_1 | 186219 | 90.93 | 329.85 | 584 |
| vm15_2 | 183742 | 89.72 | 334.99 | 663 |
| vm15_3 | 178628 | 87.22 | 344.36 | 660 |
| vm15_4 | 177948 | 86.89 | 344.72 | 653 |
| vm15_5 | 176584 | 86.22 | 347.81 | 665 |
| 合计 | 1874324 | 915.21 | 328.345 | 767 |
2)修改磁盘数:7=>3 partition7=>6
vm16,vm15流量之和为540.8MB/s
| 机器号-进程号 | records/sec | MB/sec | avg latency | max latency |
| vm16_1 | 117913 | 57.57 | 525.2 | 9036 |
| vm16_2 | 117796 | 57.52 | 525.43 | 9050 |
| vm16_3 | 117553 | 57.4 | 528.17 | 9041 |
| vm16_4 | 117354 | 57.3 | 529.09 | 9043 |
| vm16_5 | 115561 | 56.43 | 537.25 | 9040 |
| vm15_1 | 105028 | 51.28 | 592.25 | 9090 |
| vm15_2 | 104716 | 51.13 | 593.88 | 9174 |
| vm15_3 | 104171 | 50.86 | 595.53 | 9173 |
| vm15_4 | 104112 | 50.84 | 595.75 | 9174 |
| vm15_5 | 103365 | 50.47 | 599.82 | 9156 |
| vm14_1 | 109101 | 53.27 | 571.93 | 9040 |
| vm14_2 | 109072 | 53.26 | 571.99 | 9037 |
| vm14_3 | 108882 | 53.17 | 573.01 | 9024 |
| vm14_4 | 108825 | 53.14 | 573.27 | 9037 |
| vm14_5 | 108672 | 53.06 | 574.35 | 9028 |
| 合计 | 1652121 | 806.7 | 565.7946667 | 9174 |
尝试降低本地客户端的影响,当磁盘数降到3时,可以看出Broker的吞吐量下降了。
| 机器号-进程号 | records/sec | MB/sec | avg latency | max latency |
| vm16_1 | 141087 | 68.89 | 438.53 | 7580 |
| vm16_2 | 139532 | 68.13 | 443.67 | 7567 |
| vm16_3 | 139349 | 68.04 | 443.77 | 7575 |
| vm16_4 | 139326 | 68.03 | 444.55 | 7564 |
| vm16_5 | 138220 | 67.49 | 448.9 | 7600 |
| vm15_1 | 140024 | 68.37 | 440.56 | 7655 |
| vm15_2 | 138669 | 67.71 | 444.13 | 7659 |
| vm15_3 | 138385 | 67.57 | 445.16 | 7663 |
| vm15_4 | 138163 | 67.46 | 445.63 | 7647 |
| vm15_5 | 138159 | 67.46 | 443.56 | 7659 |
| 合计 | 1390914 | 679.15 | 443.846 | 7663 |
2.4 Consumer测试方案
第一组:topic的paritition数量变化对Consumer读取速度的影响
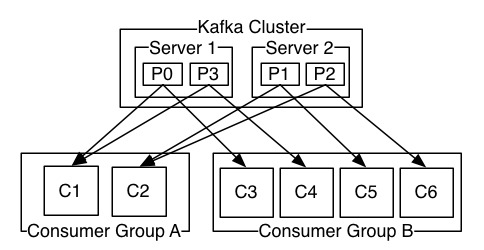
Partition是Consumer消费的基本单元,一个Partition最多只能被一个Consumer实例消费,而一个Consumer实例能够同时消费多个Partition。
当存在多个Partition时,通过多个Consumer实例可以使数据读取得到很好的扩展性。
1)单磁盘
| brokers | disks | partition | fetch.MB.sec | fetch.nMsg.sec |
| 1 | 1 | 1 | 202.5608 | 414844.603 |
| 1 | 1 | 3 | 251.7045 | 515490.7216 |
| 1 | 1 | 5 | 273.7764 | 560694.1018 |
| 1 | 1 | 7 | 284.5266 | 582710.4067 |
结论:单磁盘的情况下,增加partition的数量可以提高消费能力。
2)多磁盘
| brokers | disks | partition | fetch.MB.sec | fetch.nMsg.sec |
| 1 | 1 | 1 | 202.5608 | 414844.603 |
| 1 | 2 | 1 | 223.2095 | 457133.1139 |
| 1 | 2 | 2 | 247.9393 | 507779.6283 |
结论:增加磁盘数量可以提高消费能力。
3)多服务器
| brokers | disks | partition | fetch.MB.sec | fetch.nMsg.sec |
| 1 | 1 | 1 | 202.5608 | 414844.603 |
| 2 | 1 | 1 | 225.9357 | 462716.2687 |
| 2 | 1 | 2 | 330.2849 | 676423.4307 |
结论:增加broker数量可以提高消费能力
*本例只测试了单consumer单线程的本机消费能力,关于多个consumer和多线程的情况在后续用例中补充,该测试用例的结果均时在单consumer单线程的前提下进行的测试
第二组:测试ssd对Consumer读取性能的影响
ssd盘在数据读取时可能会对consumer的读取性能有提升
对照组sas盘:
| brokers | disks | partition | fetch.MB.sec | fetch.nMsg.sec |
| 1 | 1 | 1 | 202.5608 | 414844.603 |
| 1 | 1 | 3 | 251.7045 | 515490.7216 |
| 1 | 1 | 5 | 273.7764 | 560694.1018 |
实验组ssd盘:
| brokers | ssd | partition | fetch.MB.sec | fetch.nMsg.sec |
| 1 | 1 | 1 | 498.5514 | 1021033.2857 |
| 1 | 1 | 3 | 744.3312 | 3048780.4878 |
| 1 | 1 | 5 | 425.6287 | 1743375.1743 |
*多线程consumer对比实验组(数量等于partition数)
| brokers | ssd | partition | fetch.MB.sec | fetch.nMsg.sec |
| 1 | 1 | 3 | 254.1190 | 1040871.5564 |
| 1 | 1 | 5 | 213.6263 | 875013.1252 |
结论:使用ssd可用提升consumer的读取性能。
第三组:测试并发情况下consumer的性能
单个broker在vm15上,7块硬盘,7个partition
* 先后在三个节点上启动consumer(不同时启动,而是分别在不同节点进行测试)
单进程单线程
| host | fetch.MB.sec | fetch.nMsg.sec |
| vm14 | 252.7953 | 517724.7877 |
| vm15 | 442.6969 | 906643.3364 |
| vm16 | 293.3786 | 600839.4617 |
7进程单线程
| host | fetch.MB.sec | fetch.nMsg.sec |
| vm14 | 664.4753 | 1360845.456 |
| vm15 | 979.4621 | 2005938.397 |
| vm16 | 646.7693 | 1324583.567 |
第四组:测试有无group对consumer性能的影响
本组实验主要测试多个consumer同时消费时是否在同一组对总消费能力的影响
* 先后在三个节点上启动consumer(不同时启动,而是分别在不同节点进行测试)
单个broker在vm15上,7块硬盘,7个partition,7进程单线程
不带group_id
| host | fetch.MB.sec | fetch.nMsg.sec |
| vm14 | 925.1035 | 1894612.27 |
| vm15 | 1047.9904 | 2146284.597 |
| vm16 | 986.2786 | 2019898.688 |
带group_id
| host | fetch.MB.sec | fetch.nMsg.sec |
| vm14 | 670.608 | 1373405.073 |
| vm15 | 1075.5057 | 2202635.803 |
| vm16 | 654.3338 | 1340075.742 |
结论:vm15上是否有group id的影响不大,考虑到单broker在vm15上,所以忽略掉这组数据。在vm14和vm16上当带着相同的group id消费时,消费能力明显下降。多个消费者不属于一个组时,读取的是相同的一份数据,只有第一个取数据的消费之会经历从磁盘-内存-网络-客户端,之后的消费之会直接使用内存中的缓存数据,省略掉磁盘到内存的过程,相比之下,总消费能力高于同一组消费者消费的情况。
第五组:多broker对consumer性能的影响
* 先后在三个节点上启动consumer(不同时启动,而是分别在不同节点进行测试)
broker:vm15、vm16,7块硬盘,14个partition,consumer:14进程单线程
| host | fetch.MB.sec | fetch.nMsg.sec |
| vm14 | 959.2592 | 1964563 |
| vm15 | 1232.547 | 2524258 |
| vm16 | 1038.836 | 2127535 |
结论:与第三组的数据做对比发现在多进程的consumer消费时,broker增加一个,消费能力明显提升(vm14达到网络瓶颈,vm16上有ambari server)。
第六组:了解consumer运行时的资源消耗
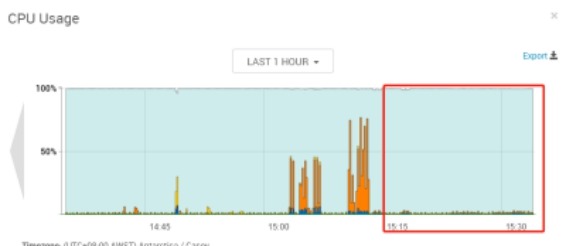
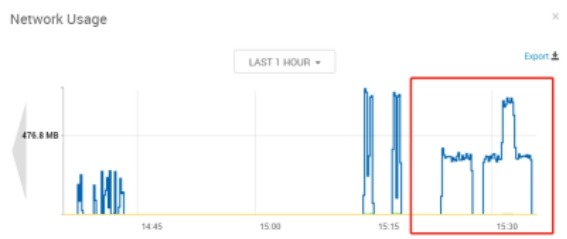
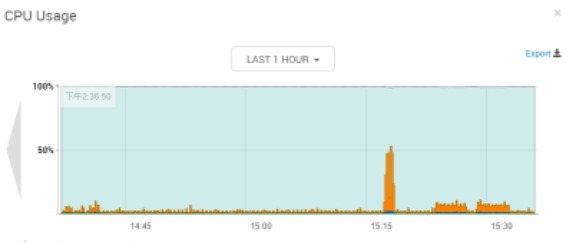
思路:通过观察consumer运行时broker上的资源使用以及consumer上的资源使用情况,了解Kafka读数据时对各个节点的哪些资源消耗较大。
broker:vm15,consumer:vm14、vm16, 两个consumer(单进程),topic:7partition,大致时间段:15:20-15:40
broker(vm15):
consumer(vm14):cpu使用率在7%左右,内存无变化
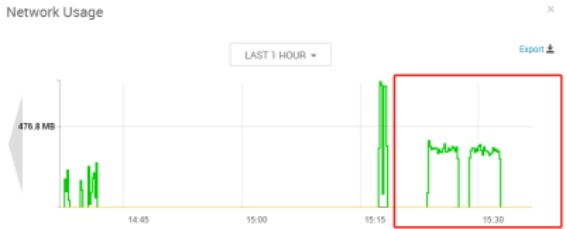
consumer(vm16):cpu使用率在7%左右,内存无变化
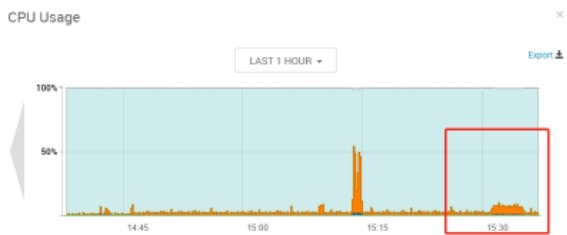
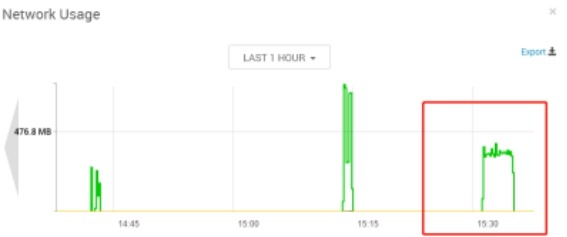
分析:从整体来看broker节点网络资源out量=consumer节点网络资源in总量,broker节点的cpu几乎无波动(使用率在1%以内),consumer节点的cpu使用率在7%左右。由此可见consumer读取数据时对broker的压力主要体现在网络上,对cpu的压力几乎可以忽略,这得益于Kafka的零拷贝技术。
2.5 同时读写情况下Kafka的性能表现
1)2.3节 第五组 多机多进程producer在单机Broker下的写入性能 的结果如下, 3client*5process,7 SAS disk 7parititon Topic,Broker 部署在node3上
| 机器号-进程号 | records/sec | MB/sec | avg latency | max latency |
| vm16_1 | 169136 | 82.59 | 364.4 | 1132 |
| vm16_2 | 167914 | 81.99 | 366.66 | 1153 |
| vm16_3 | 167324 | 81.7 | 368.2 | 1180 |
| vm16_4 | 167622 | 81.85 | 367.47 | 1227 |
| vm16_5 | 165332 | 80.73 | 373.78 | 1187 |
| vm15_1 | 162723 | 79.45 | 377.7 | 789 |
| vm15_2 | 161274 | 78.75 | 380.7 | 867 |
| vm15_3 | 160632 | 78.43 | 382.7 | 871 |
| vm15_4 | 158836 | 77.56 | 387.53 | 863 |
| vm15_5 | 157898 | 77.1 | 389.6 | 881 |
| vm14_1 | 180564 | 88.17 | 339.76 | 756 |
| vm14_2 | 180108 | 87.94 | 340 | 749 |
| vm14_3 | 179700 | 87.74 | 341.87 | 846 |
| vm14_4 | 179166 | 87.48 | 343.58 | 840 |
| vm14_5 | 178635 | 87.22 | 344.29 | 799 |
| 合计 | 2536864 | 1238.7 | 364.5493333 | 1227 |
由于上述节点的一些问题,改用第二组服务器(node1-node3)测试
| 服务器编号-进程编号 | record/s | MB/s | avg latency(ms) | max latency(ms) |
| node1-1 | 159994 | 78.12 | 387.58 | 916 |
| node1-2 | 157059 | 76.69 | 394.26 | 929 |
| node1-3 | 156040 | 76.19 | 395.68 | 823 |
| node1-4 | 155048 | 75.71 | 398.69 | 865 |
| node1-5 | 154263 | 75.32 | 400.97 | 900 |
| node2-1 | 157099 | 76.71 | 391.65 | 1085 |
| node2-2 | 155289 | 75.82 | 396.97 | 1155 |
| node2-3 | 152816 | 74.62 | 401.88 | 1057 |
| node2-4 | 152063 | 74.25 | 405.24 | 1127 |
| node2-5 | 150661 | 73.57 | 407.64 | 1015 |
| node3-1 | 159098 | 77.68 | 383.47 | 929 |
| node3-2 | 158277 | 77.28 | 386.23 | 955 |
| node3-3 | 154549 | 75.46 | 395.06 | 913 |
| node3-4 | 153884 | 75.14 | 398.12 | 970 |
| node3-5 | 151299 | 73.88 | 404.66 | 981 |
| 总计 | 2327439 | 1136.44 | 396.54 | 1155 |
2)多机多进程Consumer在单机Broker下的读取性能 的结果如下, 3client*1process,7 SAS disk 7parititon Topic,Broker 部署在node3上:
| 服务器编号-进程编号 | record/s | MB/s |
| node1-1 | 790954.2866 | 386.2081 |
| node2-1 | 868217.3989 | 423.9343 |
| node3-1 | 1016968.68 | 496.5667 |
| 总计 | 2676140.366 | 1306.7091 |
3)多机单进程Consumer和多机多进程producer在单机Broker下同时读写性能 的结果如下,3client*1process consumer, 3client*5process producer,7 SAS disk 7parititon Topic,Broker 部署在node3上:
producer
| 服务器编号-进程编号 | record/s | MB/s | avg latency(ms) | max latency(ms) |
| node1-1 | 128985.6568 | 62.98 | 477.37 | 1298 |
| node1-2 | 128769.734 | 62.88 | 479.43 | 1314 |
| node1-3 | 128293.9471 | 62.64 | 481.55 | 1318 |
| node1-4 | 127828.1989 | 62.42 | 483.78 | 1349 |
| node1-5 | 127616.1307 | 62.31 | 482.98 | 1364 |
| node2-1 | 130712.1196 | 63.82 | 473.27 | 1330 |
| node2-2 | 129292.5114 | 63.13 | 479.4 | 1356 |
| node2-3 | 128945.7396 | 62.96 | 480.19 | 1359 |
| node2-4 | 127851.0791 | 62.43 | 484.19 | 1286 |
| node2-5 | 127775.9321 | 62.39 | 484.2 | 1360 |
| node3-1 | 128882.588 | 62.93 | 478.95 | 1001 |
| node3-2 | 127769.4018 | 62.39 | 481.74 | 855 |
| node3-3 | 127411.2581 | 62.21 | 484.46 | 1036 |
| node3-4 | 127171.4526 | 62.1 | 485.22 | 1034 |
| node3-5 | 126874.5718 | 61.95 | 486.4 | 980 |
| 总计 | 1924180.321 | 939.54 | 481.542 | 1364 |
consumer
| 服务器编号-进程编号 | record/s | MB/s |
| node1-1 | 587482.552 | 286.8567 |
| node2-1 | 537564.2873 | 262.4826 |
| node3-1 | 475098.2423 | 231.9816 |
| 总计 | 1600145.082 | 781.3209 |
通过对比同时读写和单独读写的情况下读取速度和写入速度,可以发现同时读写时,写入速度和读取速度都有所下降,其中写入总量由1136.44MB/s下降到939.54MB/s,读取总量从1306.7091MB/s下降到781.3209MB/s,考虑到同时读写时读和写都在三台机子上同时进行可能带来影响,还需要补充读写不在同一台机器上时的情况。
*1)单机进程producer在单机Broker下的写入性能 的结果如下, 1client*5process,7 SAS disk 7parititon Topic,Broker 部署在node3上,producer在node1上
| 服务器编号-进程编号 | record/s | MB/s | avg latency(ms) | max latency(ms) |
| node1-1 | 144529.5563 | 70.57 | 425.11 | 782 |
| node1-2 | 144146.2219 | 70.38 | 427.25 | 790 |
| node1-3 | 143653.3931 | 70.14 | 428.03 | 787 |
| node1-4 | 143620.3826 | 70.13 | 428.89 | 785 |
| node1-5 | 143266.4756 | 69.95 | 431.02 | 790 |
| 总计 | 719216.0296 | 351.17 | 428.06 | 790 |
*2)单机单进程Consumer在单机Broker下的读取性能 的结果如下, 1client*1process,7 SAS disk 7parititon Topic,Broker 部署在node3上,Consumer在node2上:
| 服务器编号-进程编号 | record/s | MB/s |
| node2-1 | 936691.6448 | 457.3690 |
*3)单机单进程Consumer和单机多进程producer在单机Broker下同时读写性能 的结果如下,1client*1process consumer, 1client*5process producer,7 SAS disk 7parititon Topic,Broker 部署在node3上,Producer在node1上,Consumer在node2上:
producer
| 服务器编号-进程编号 | record/s | MB/s | avg latency(ms) | max latency(ms) |
| node1-1 | 148628.1621 | 72.57 | 414.32 | 652 |
| node1-2 | 147719.2153 | 72.13 | 414.7 | 649 |
| node1-3 | 146877.3868 | 71.72 | 418.55 | 651 |
| node1-4 | 145747.0996 | 71.17 | 420.68 | 667 |
| node1-5 | 145158.949 | 70.88 | 421.91 | 650 |
| 总计 | 734130.8128 | 358.47 | 418.032 | 667 |
consumer
| 服务器编号-进程编号 | record/s | MB/s |
| node2-1 | 817825.9732 | 399.3291 |
Broker 部署在node3上,Producer在node1上,Consumer在node2上,通过对比同时读写和单独读写的情况下读取速度和写入速度,可以看出写入速度只有略微的下降,读取速度下降的较为明显
结论:在同时读写时,读写不同机时读取会受到一些影响,对于写入几乎没有影响,读写同机时读取影响较大,写入影响较小。
2.6 长时间写入的情况下kafka的性能表现
Kafka Broker为了提升写入效率,会将接收到的数据先缓存到os cache层,然后再批量写入到磁盘中。本用例用于观察Kafka在大批量长时间的数据写入时,写入性能是否稳定。
测试条件: 一台Broker,7*6T SAS盘, 7partition,7-14个 Producer进程同时写入。
1)磁盘io观测
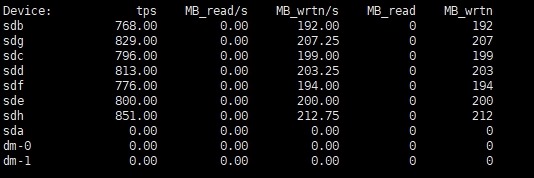
磁盘写入IO最大值可达到单磁盘200MB/s左右 ,服务器总写入磁盘io约为1400MB/s。
一般来说,小文件的读写速度会远小于大文件,而kafka由于是将数据批量flush到硬盘中,避免了小文件问题导致的性能影响,理论上能达到磁盘的写入上限,下面通过dd命令测试磁盘的最大写入速度。
sudo time dd if=/dev/zero of=/data/data1/test.dbf bs=8k count=300000 oflag=direct
of: 输出文件位置,对应挂载的磁盘。 oflag=direct: 关闭OS缓存。
| 文件总大小 | 文件个数 | 单个文件大小 | 是否开启OS缓存 | 磁盘 | CPU利用率 | 写入速度 | 命令 |
| 2.4GB | 300000 | 8kB | 否 | SAS | 0% | 974 kB/s | sudo time dd if=/dev/zero of=/data/data1/test.dbf bs=8k count=300000 oflag=direct |
| 2.4GB | 300000 | 8kB | 是 | SAS | 25% | 185 MB/s | sudo time dd if=/dev/zero of=/data/data1/test.dbf bs=8k count=300000 |
| 2.4GB | 300000 | 8kB | 否 | SSD | 10% | 200 MB/s | sudo time dd if=/dev/zero of=/home/work/test.dbf bs=8k count=300000 oflag=direct |
| 2.4GB | 300000 | 8kB | 是 | SSD | 41% | 314 MB/s | sudo time dd if=/dev/zero of=/home/work/test.dbf bs=8k count=300000 |
| 2.4GB | 30 | 80MB | 否 | SAS | 14% | 205 MB/s | sudo time dd if=/dev/zero of=/data/data1/test.dbf bs=80000k count=30 oflag=direct |
| 24GB | 30 | 80MB | 是 | SAS | 99% | 1.0 GB/s | sudo time dd if=/dev/zero of=/data/data1/test.dbf bs=80000k count=300 |
| 2.4GB | 30 | 80MB | 否 | SSD | 19% | 389 MB/s | sudo time dd if=/dev/zero of=/home/work/test.dbf bs=80000k count=30 oflag=direct |
| 24GB | 30 | 80MB | 是 | SSD | 99% | 1.5 GB/s | sudo time dd if=/dev/zero of=/home/work/test.dbf bs=80000k count=300 |
在不开缓存的情况下,SAS盘写大文件的速度上限约为200MB/s。
2) 每秒写入记录数观测
随着Producer的进程数由7个增至14个,写入速度从80w条/秒上升至207w条/秒,并稳定运行。
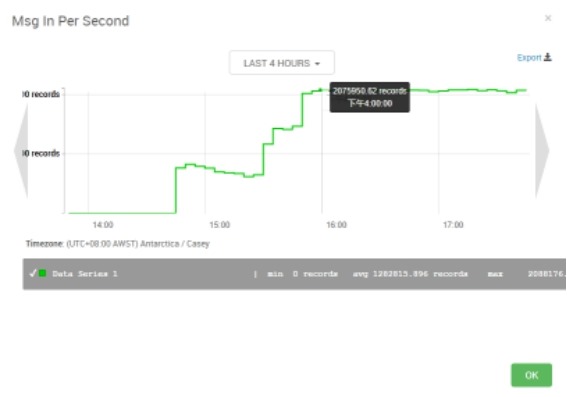
3) jvm状况观测
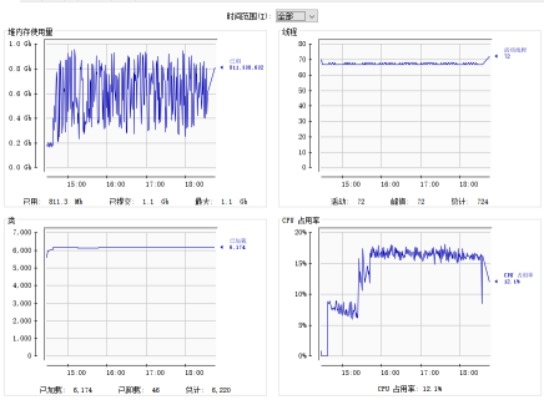

4) 内存状况观测
![]()
5) 总写入数据量
1.9TB*7=13.3TB
2.7 大数据量下压测kafka至磁盘空间不足时的表现
为了进一步观测kafka长时间运行的表现,可以考虑Kafka的单个Broker在最坏情况下的表现。极限的情况是,Broker所在服务器的磁盘被写满,观察这种情况对性能的影响。
本用例的运行条件与2.6相同,是在2.6的基础上继续执行同样的测试命令,14个其他服务器的客户都拿进程同时写入vm15中的kafka至磁盘达到饱和状态。
1)磁盘变化情况
磁盘空间一开始呈线性下降趋势,当服务器可用总空间仅剩98.9.9GB时,磁盘空间停止下降, 在8点40左右继续开始小幅下降。

2)写入速度的变化
消息写入速度从200w条/秒,经过4个小时的写入后组逐渐下降至100w条/秒左右,在23点20左右磁盘空间不足后短暂异常飙升,然后降至0,在第二天8点40后恢复5w条/秒的写入速度,之后又降为0。

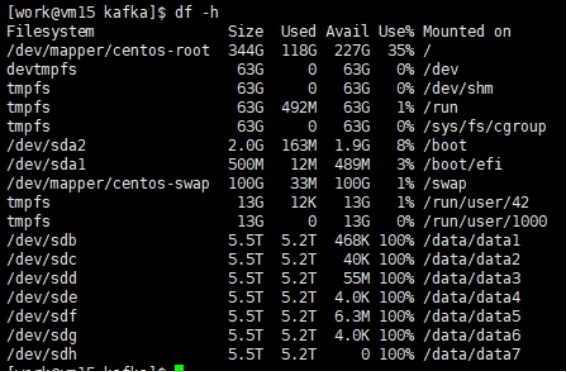
3)df -h查看已使用磁盘空间为100%
4)内存使用情况
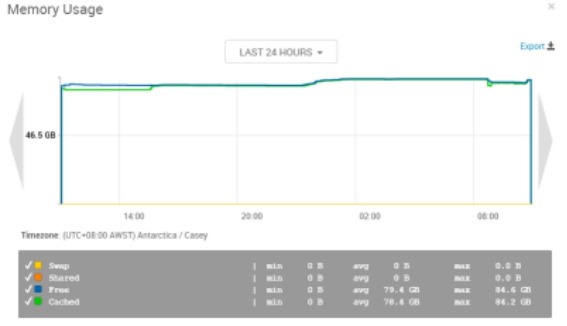
整个过程内存使用情况平稳。
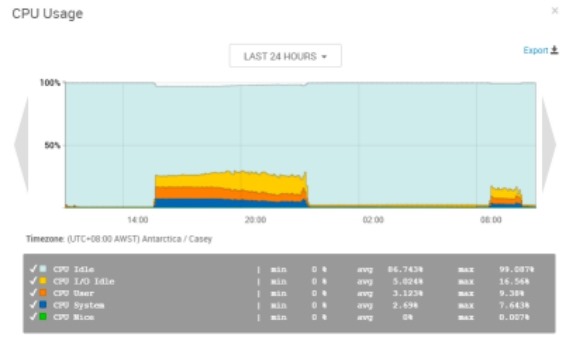
5)cpu和负载
整个过程CPU负载随着写入情况变化,负载较低。

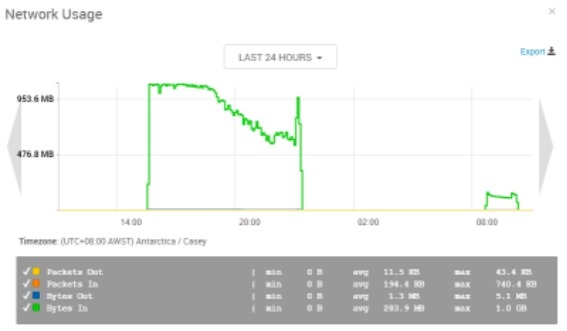
6)网络流量负载
整个过程中网络流量随写入速度变化明显。
7) 问题分析
问题1.vm.max_map_count=65535不太够用,需要调整为262144
| root@vm15 # sysctl -w vm.max_map_count=262144 root@vm15 # sysctl -a|grep vm.max_map_count vm.max_map_count = 262144 |
查看kafka 的vm.maps,
![]()
问题2. 硬盘空间不足导致Kafka Broker强制退出
| [2019-10-29 23:17:11,054] ERROR Error while appending records to test_long_time-0 in dir /data/data7/kafka-logs (kafka.server.LogDirFailureChannel) [2019-10-29 23:17:11,097] ERROR Error while appending records to test_long_time-3 in dir /data/data1/kafka-logs (kafka.server.LogDirFailureChannel) [2019-10-29 23:17:12,054] ERROR Error while appending records to test_long_time-5 in dir /data/data6/kafka-logs (kafka.server.LogDirFailureChannel) [2019-10-29 23:17:12,056] ERROR Error while appending records to test_long_time-4 in dir /data/data4/kafka-logs (kafka.server.LogDirFailureChannel) [2019-10-29 23:17:45,410] ERROR Error while appending records to test_long_time-1 in dir /data/data5/kafka-logs (kafka.server.LogDirFailureChannel) [2019-10-29 23:17:27,101] ERROR Error while appending records to test_long_time-2 in dir /data/data2/kafka-logs (kafka.server.LogDirFailureChannel) [2019-10-29 23:18:11,235] ERROR Shutdown broker because all log dirs in /data/data1/kafka-logs, /data/data2/kafka-logs, /data/data3/kafka-logs, /data/data4/kafka-logs, /data/data5/kafka-logs, /data/data6/kafka-logs, /data/data7/kafka-logs have failed (kafka.log.LogManager) |
系统优化
内存优化
这里主要针对三个参数进行调优测试:vm.swappiness、vm.dirty_background_ratio、vm.dirty_ratio。
vm.swappiness 表示 VM 系统中的多少百分比用来作为 swap 空间;
vm.dirty_background_ratio 指的是被内核进程刷新到磁盘之前缓存脏页数量占系统内存的百分比,异步flush,不影响正常I/O;
vm.dirty_ratio 指的是被内核进程刷新到磁盘之前的脏页数量,同步I/O,影响正常I/O。
对 照 组:vm.swappiness=60 vm.dirty_background_ratio=10 vm.dirty_ratio=20(系统默认值)
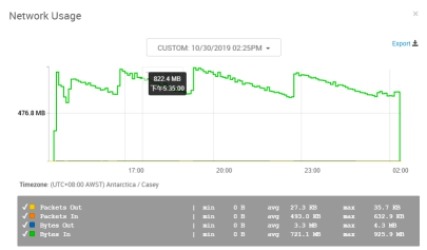
实验组一:vm.swappiness=1 vm.dirty_background_ratio=5 vm.dirty_ratio=60
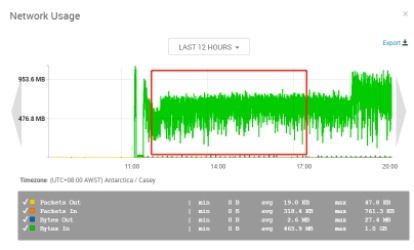
实验组二:vm.swappiness=1 vm.dirty_background_ratio=5 vm.dirty_ratio=20
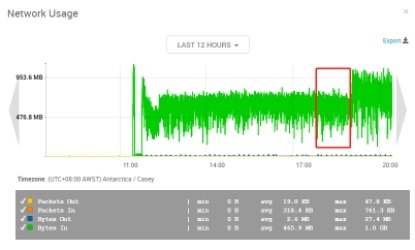
实验组三:vm.swappiness=1 vm.dirty_background_ratio=10 vm.dirty_ratio=20
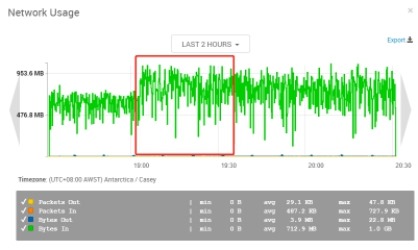
实验组四:vm.swappiness=1 vm.dirty_background_ratio=10 vm.dirty_ratio=60

相对与对照组的吞吐量和稳定性,四个实验组可以得出以下结论:
| vm.swappiness | vm.dirty_background_ratio | vm.dirty_ratio | 吞吐量 | 稳定性 |
| 1 | 5 | 60 | 降低 | 提高 |
| 1 | 5 | 20 | 降低 | 提高 |
| 1 | 10 | 20 | 不变 | 不变 |
| 1 | 10 | 60 | 不变 | 略好 |
根据实验组三可以看出 vm.swappiness 参数修改前后变化不大,考虑到系统内存很大,没用到 swap 的情况,可以暂时忽略该参数的影响,以下主要分析 vm.dirty_background_ratio 和 vm.dirty_ratio 的影响:
首先 vm.dirty_background_ratio 指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如5%)就会触发将一定缓存的脏页异步地刷入磁盘;vm.dirty_ratio 则指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不开始处理缓存脏页,在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
从实验现象中也可以看出 vm.dirty_background_ratio 的调整无论是对吞吐量还是稳定性都有很大的影响,10→5时,系统处理脏页(异步刷到磁盘)的频率会增加,由此造成了吞吐量的降低和吞吐量的更加稳定,而 vm.dirty_ratio 的调整要小一些,主要影响稳定性方面(不是很明显),20->60时,系统必须同步处理脏页的频率又有所下降,由此消除了一些吞吐量较低的点(由于阻塞式刷数据造成的吞吐量下降)。
最佳实践
一、存储
1.1 磁盘类型 大部分时候选择普通的sas盘即可
1.2 磁盘大小/数量 根据业务的数据量大小、副本数量、保存天数等策略的选择,计算出所需的总存储量来综合决定
二、主题
2.1 分区数量 24(3broker*7disk,均衡消费者的负载,同时尽量的将分区均摊到每块硬盘)
2.2 副本数量 一般情况下选择2,一致性要求较高时选择3
三、生产者/消费者 客户端
3.1 配置堆内存大小 -Xmx4096M -Xms4096M
3.2 线程/进程数 根据实际的业务需求决定

