
热门标签
热门文章
- 1FPGA综合系统设计(三):贪吃蛇游戏(键盘+VGA)_基于vga的游戏设计的系统框图,画出各功能模块之间的连线
- 2干货|使用git中钩子文件做代码提交前的检查
- 3Neo4j-简单使用_neo4j使用
- 4Spring Boot 3.0:未来企业应用开发的基石_springboot 3.0
- 5海量数据处理-大数据离线批处理技术篇_大数据离线数据处理批量数据处理
- 6Linux与Windows下追踪网络路由:traceroute、tracepath与tracert命令详解_traceroute windows
- 7JMeter入门9---Tcp sampler AES加密_java tcp sampler
- 8解决MySql事务引起CannotAcquireLockException的问题
- 9京准电钟|基于纳秒级的GPS北斗卫星授时服务器
- 10SpringBoot 集成RabbitMQ集群及简单操作_springboot rabbitmq集群
当前位置: article > 正文
Meta Llama3简单速览_llama3 数据配比
作者:我家小花儿 | 2024-06-17 14:31:25
赞
踩
llama3 数据配比
前言
北京时间4月19号凌晨,Meta 发布了Llama3。下面,让我们根据官方报告,深入了解这一AI领域的重要更新。
发布内容
Meta Llama 3的发布标志着大型语言模型(LLM)的新纪元。以下是其主要发布内容的概览:
- 模型规模:推出了8B和70B参数的模型,预示着更广泛的应用场景。
- 可用性:模型将很快在AWS、Databricks、Google Cloud等主要平台上可用。
- 后续公布内容:更长的上下文窗口、额外的模型尺寸和增强的性能、Llama 3的研究论文
报告里面也提到,meta希望尽早尽频繁地发布,所以优先发布了目前两个版本的模型。
效果对比
直接上图:
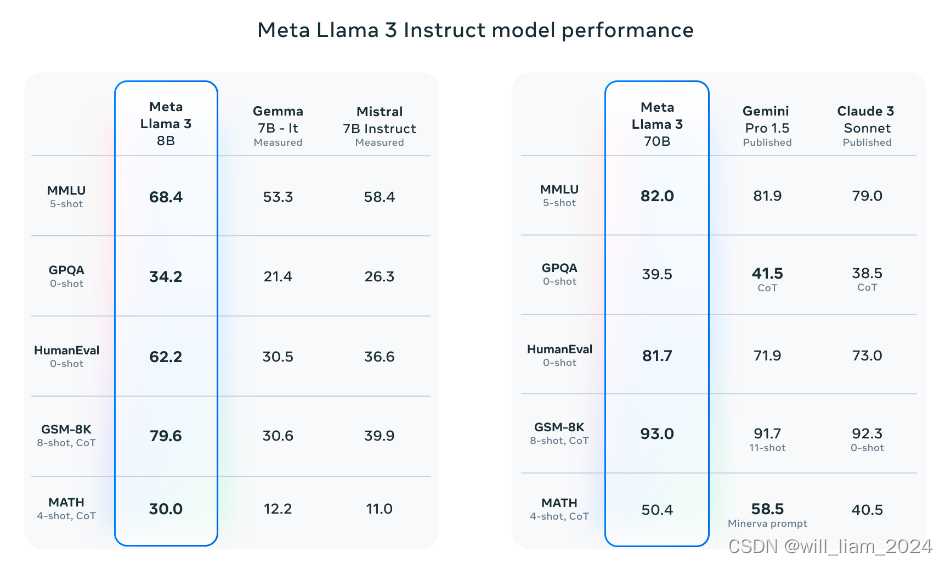
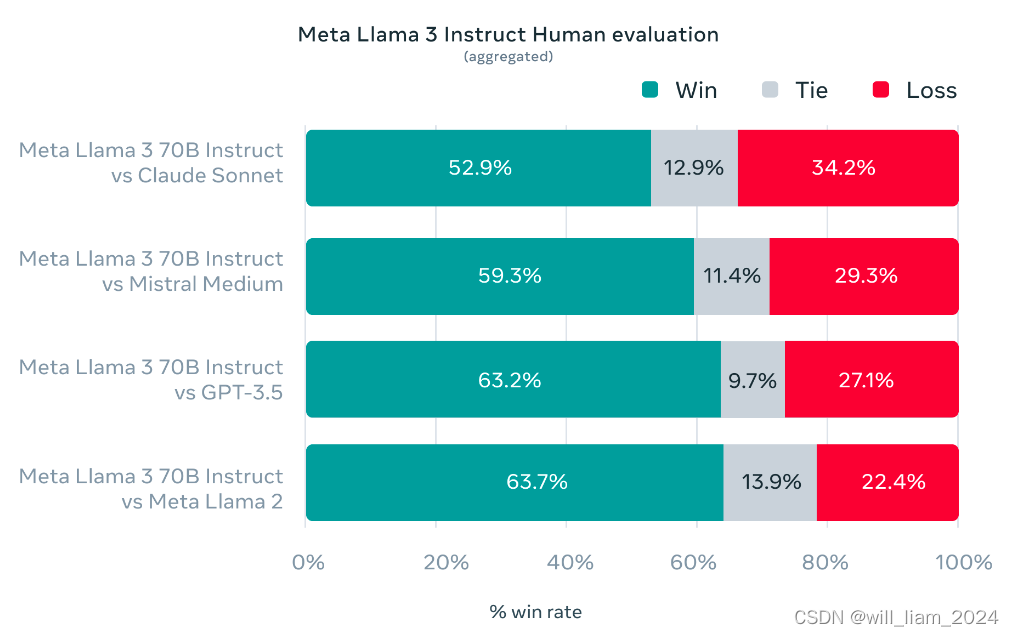
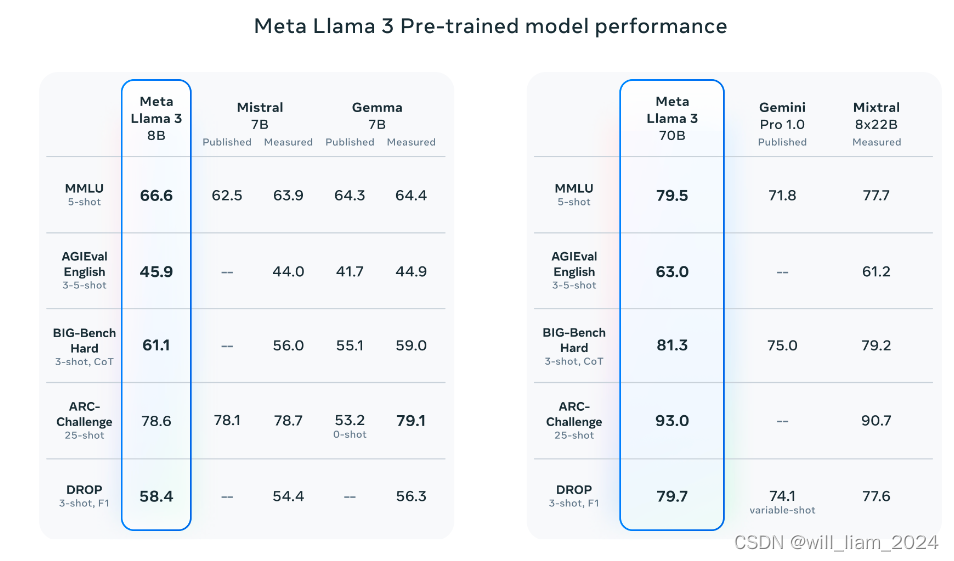
可以看到,intruct模型在推理、代码生成方面有大幅的提高,原文还提到错误拒绝率大幅降低。
模型结构 Model architecture
Llama 3采用了以下模型架构设计:
- 架构类型:标准解码器变换器(decoder-only transformer)架构。
- 词表:128K个token。
- 注意力机制:引入分组查询注意力(GQA)以提升推理效率,保持了与Llama 2相当的推理效率。
- 训练数据长度:on sequences of 8,192 tokens,序列长度为8192.
训练的数据 Training data
Llama 3的训练数据集特点:
- 数据规模:超过15T的令牌,是Llama 2的七倍,其中code的数据量是之前的四倍,数据都是公开来源。
- 多语言支持:包含超过30种语言的高质量非英语数据。
- 数据质量:通过数据过滤流程,确保了训练数据的最高质量。数据质量的pipeline包括启发式过滤器(业务规则相关)、NSFW过滤器、语义去重,还有用文本分类来预测数据质量。文中提到,用llama2驱动llama3做文本质量分类器(可能为了数据安全,不用gpt4)。
- 数据配比:meta进行了广泛的实验,以评估在最终预训练数据集中混合不同来源数据的最佳方式。在模型结构大差不差的背景下,数据收集和配比应该是每家大模型公司的核心技能了。
扩大预训练 Scaling up pretraining
- 一些发现:发现即使在模型训练了两个数量级更多的数据之后,模型性能仍在继续提高。80亿和700亿参数模型在训练了多达1.5万亿个令牌之后,继续以对数线性的方式提高。更大的模型可以在较少的训练计算下达到这些较小模型的性能,但通常更倾向于使用较小的模型,因为它们在推理过程中效率更高。
- 并行化训练:结合数据、模型和流水线并行化技术,提高了训练效率。在16000个GPU训练的时候,计算利用率达到400TFLOPS。训练在2个24000个GPU集群上进行,通过一些自动化运维工具使得有效训练时间超过95%,训练效率比llama2提升了3倍。
指令微调 Instruction fine-tuning
Llama 3在指令微调方面的创新:
- 微调方法:结合了监督式微调(SFT)、拒绝采样(Rejection Sampling)、近端策略优化(PPO)和直接策略优化(DPO)。提到PPO和DPO可以利用偏好数据,提升推理能力。
To be continued(4千亿参数量模型)
Meta Llama 3的旅程才刚刚开始,未来将推出超过400B参数的模型,这些模型将带来:
- 新功能:包括多模态交互、多语言对话能力等。
- 性能提升:更长的上下文窗口和更强的整体能力。
- 研究论文:完成训练后,将发布详细的研究论文。

内容引用
https://ai.meta.com/blog/meta-llama-3/
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

