
StarRocks内部实时更新技术的实现方案_starrocks 如何做更新同一条数据?
赞
踩
StarRocks内部实时更新技术的实现方案
导读:本次分享是对StarRocks内部实时更新技术方面的介绍。首先介绍为什么OLAP系统里面越来越需要实时更新,后面会介绍当前市面上一些OLAP数据库是如何去做实时更新的。
分享大纲如下:
实时更新需求
StarRocks 实时更新实现
当前和未来工作
- 1
01 实时更新需求
1. AP系统里面为什么需要实时更新
传统的OLAP系统:
最常使用的就是 T+1 批量ETL方式导入数据,同时通过Overwrite方式实现更新数据的导入。这种方式延迟会比较高,不太适合实时更新的需求。
增量不停地导入数据,数据只能追加(append only),不能更新(update),只能插入(insert)。这在实时日志分析、广告等场景都会用到。
追加更新数据,底层使用MOR(merge-on-read)方式来支持更新(类似LSM结构【日志结构合并树】)。这种方式能完美解决实时更新的需求,但是merge-on-read对查询的性能影响比较高,不太适合实时查询场景。
- 1
对实时分析的新需求:
摄入的数据基本是实时数据,也就是热数据,通常也会是可变的数据(volatile data),经常会被更新到。
很多HTAP的系统都支持实时数据的更新,把TP的数据实时的同步到AP系统里面(一般通过CDC的方式)。
- 1
另外,目前ELT的方式越来越流行,就是原始数据抽取(extract)出来直接导入(load)到数仓里面,然后在数仓内部进行一些高级的转换(transform),同时可以在数仓内部进行查询。大大简化了整个数据的pipeline,并且能够很方便的、对用户非常友好转化数据,使之能够更高效地被查询。涉及到复杂的DML的更新,比如update、delete或者是merge into等批量修改数据的语句,在AP系统越来越流行。
2. 实时更新的场景
(1)场景: full row upsert / delete 对数据库里的一行(整行)进行upsert或者delete:  在mysql下,插入一条数据,如果key(unique key)重复就覆盖数据行。
在mysql下,插入一条数据,如果key(unique key)重复就覆盖数据行。  在StarRocks下,有Unique key 表支持 upsert语义,另外 StartRocks 新加了一个 Primary key 的表模型,它支持upsert和delete语义。
在StarRocks下,有Unique key 表支持 upsert语义,另外 StartRocks 新加了一个 Primary key 的表模型,它支持upsert和delete语义。
有了这两个语义之后就能完美支持 从OLTP系统到OLAP系统CDC数据的同步。
(2)场景实现方式
① Merge-on-Read
当获取CDC数据,排序后直接写入新的文件,不做重复键检查。读取时通过Key值比较进行Merge,合并多个版本的数据,仅保留最新版本的数据返回。
Merge-on-Read方式写入数据非常快,但是读数据比较慢,对查询的影响比较大。它参考的是存储引擎比较典型的、应用广泛的LSM树的数据结构。 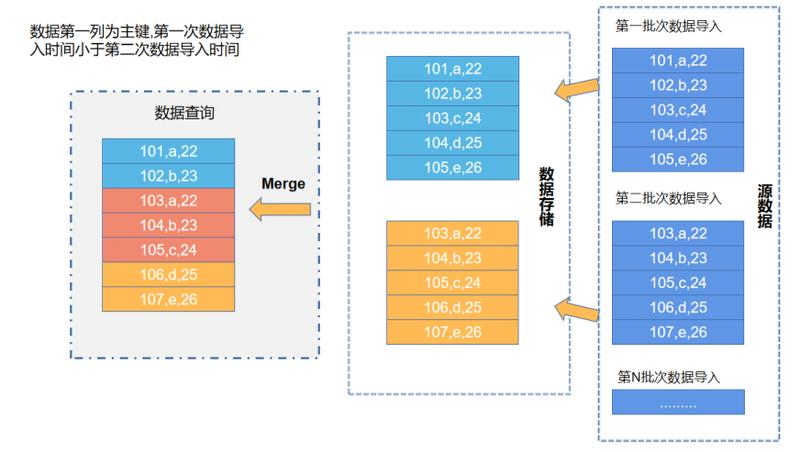 Hudi的MOR表以及StarRocks 的Unique key 表都是使用这种方式是实现的。
Hudi的MOR表以及StarRocks 的Unique key 表都是使用这种方式是实现的。
② Copy-on-Write
当获取CDC数据后,新的数据和原来的记录进行full join,检查新的数据中每条记录跟原数据中的记录是否有冲突(检查Key 值相同的记录)。对有冲突的文件,重新写一份新的、包含了更新后数据的。
读取数据时直接读取最新数据文件即可,无需任何合并或者其他操作,查询性能最优,但是写入的代价很大,因此适合 T+1 的不会频繁更新的场景,不适合实时更新场景。 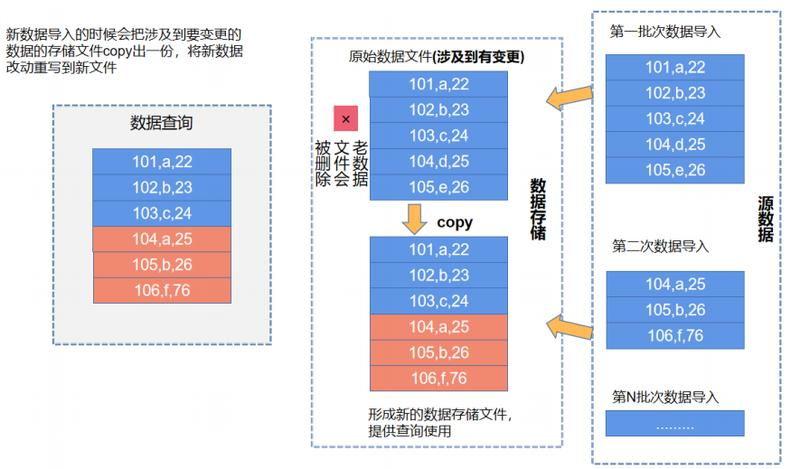 现在的数据湖方案里像 Delta Lake,Hudi 的 COW表,Iceberg 以及商用的 Snowflake都是使用这种方式达到数据更新目标。
现在的数据湖方案里像 Delta Lake,Hudi 的 COW表,Iceberg 以及商用的 Snowflake都是使用这种方式达到数据更新目标。
③ Delta Store
基本思想是牺牲写入性能,换取更高的读性能。当获取CDC数据后,通过主键索引,可以定位到这条记录原来所在的位置、文件(或者Block),然后在这个Block旁边放一个Delta Store,用来保存对于这个Block的增量修改。这个Delta Store 里保存的不是主键而是数据记录在Block里的行号(RowId)。
查询时读到原始Block,然后根据RowId与Delta 数据进行合并更新并返回最新数据给上层引擎。由于Delta数据是按行号组织的,与Merge-on-Read按照 Key进行合并比,查询性能好很多。不过这种方式会破坏二级索引,因为对Block做修改后,他的索引相当于失效了,想要在更新后再维护索引复杂度会很高。
这种方式写入性能差(要查询索引,定位原数据),但读取的性能好很多。另外因为引入了主键索引和Delta Store,复杂性也较高。 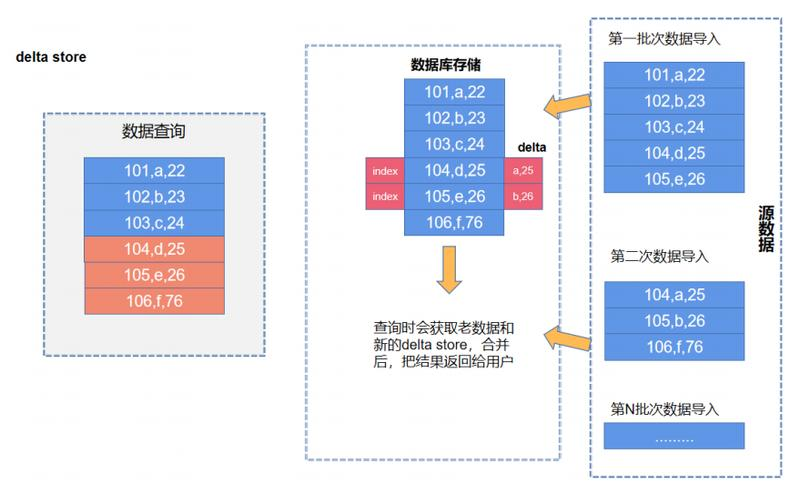 采用这种方案较典型的是Apache Kudu,许多TP系统甚至HTAP 数据库也会到 Delta Store 存储方式。
采用这种方案较典型的是Apache Kudu,许多TP系统甚至HTAP 数据库也会到 Delta Store 存储方式。
④ Delete-and-Insert
思路也是牺牲部分写性能,极大地优化读的性能。原理也是引入主键索引,通过主键索引定位原来这条记录所在位置,找到记录后只需要给这条记录打个删除标记(Delete Bitmap),表示这条记录是被删除的,然后所有其它update记录可以当成新增数据插入到新的Block里面。这样的好处是读取时直接把所有的Block都可以并行的加载,然后只需要根据Delete Bitmap标记过滤已经删除的记录。 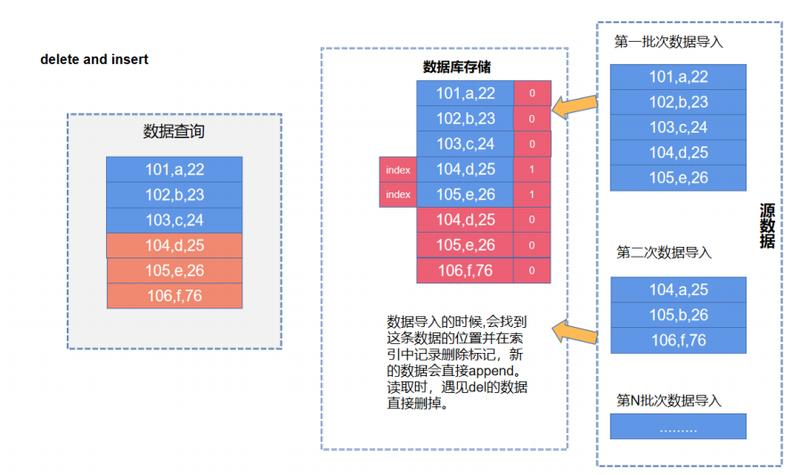 StarRocks 新的支持实时更新的 Primary Key 表就是用到这个 Delete+Insert 的方式实现的;另外还有阿里云的 ADB 和 Hologres 也用到在这种方式。
StarRocks 新的支持实时更新的 Primary Key 表就是用到这个 Delete+Insert 的方式实现的;另外还有阿里云的 ADB 和 Hologres 也用到在这种方式。
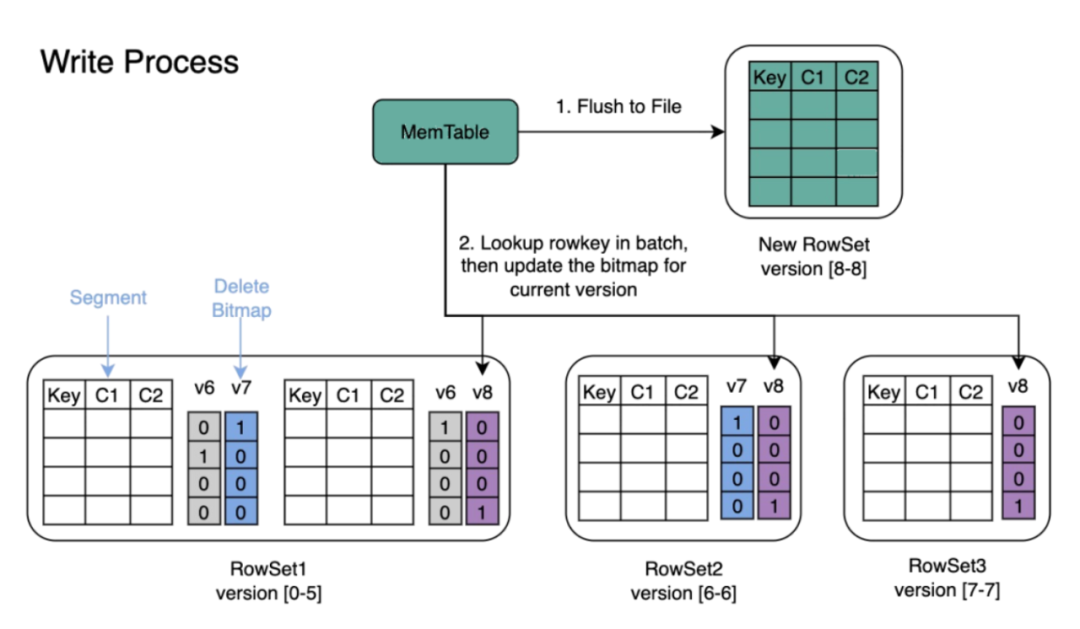
5:Merge On Write
Merge On Write 在写入的过程中,引入了 Delete Bitmap 数据结构,Doris/starrocks 使用 Delete Bitmap 标记 RowSet 中某一行是否被删除。这里使用了兼顾性能和存储空间的 Row Bitmap,将 Bitmap 中的 Mem Table 一起存储在 BE 中,每个 segment 会对应一个 Bitmap。
为了保持 Unique Key 原有的语义,Delete Bitmap 也支持多版本。每次导入会产生该版本增量的 Bitmap。在查询时需要合并此前所有版本的 Delete Bitmap。
DeltaWriter 会先将数据 flush 到磁盘
批量检查所有 Key。在点查过程中,会经过一个区间树,查找它在 Base 数据中的位置(rowsetid + segmentid + 行号)
如果 Key 存在,则将该行数据标记删除。标记删除的信息记录在 Delete Bitmap中,其中每个 Segment 都有一个对应的 Delete Bitmap
将更新的数据写入新的 Rowset 中,完成事务,让新数据可见(能够被查询到)
查询时,读取 Delete Bitmap,将被标记删除的行过滤掉,只返回有效的数据
- 1
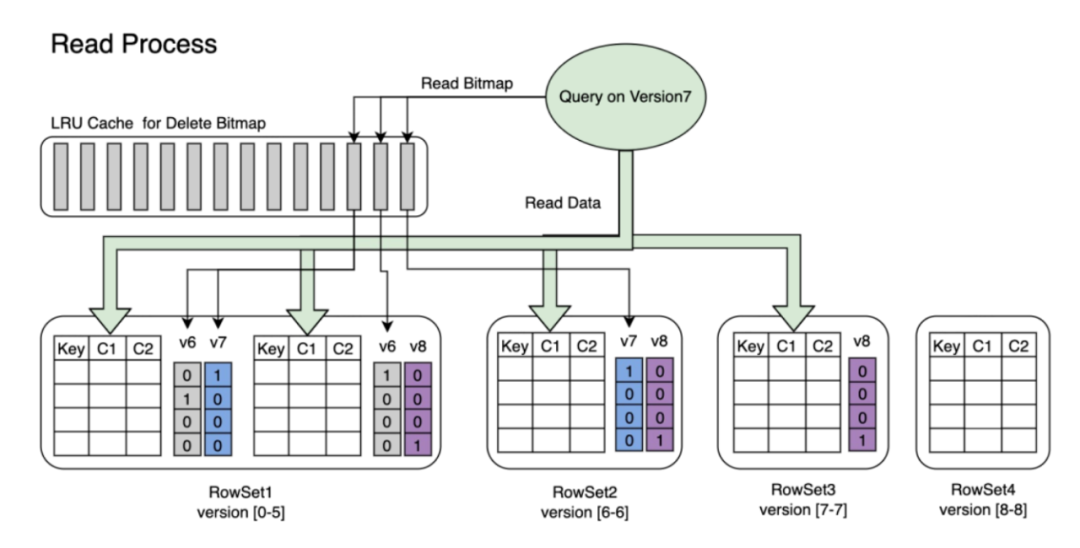
当我们查询某⼀版本数据时, Doris 会从 LRU Cache Delete Bitmap 中查找该版本对应的缓存。
如果缓存不存在,再去 RowSet 中读取对应的 Bitmap。
使⽤ Delete Bitmap 对 RowSet 中的数据进⾏过滤,将结果返回。
- 1
优缺点 数据导入时,会有和之前的数据比对的操作,会有一定的导入性能下降。
读时只需要根据标记位的索引跳过不需要读取的行,读取效率会比较高效。 
02 StarRocks 的实时更新
1. 基本系统架构
StarRocks 集群由FE和很多BE组成:
FE:FrontEnd,StarRocks 的前端节点,负责集群管理元数据,管理客户端连接,进行查询解析规划,生成查询执行计划,查询调度(把查询下发给BE执行)等工作。
BE:BackEnd,StarRocks 的后端节点,负责数据存储,查询执行计划的执行,compaction,副本管理等工作。表数据存储这块,每个表的数据根据分区或分桶机制被打散分成多个Tablet,为了容错 Tablet 会做多个副本,这些Tablet最终分布在不同的BE上。
如下图所示,一个导入事务可以分为两个阶段:Write , Commit. 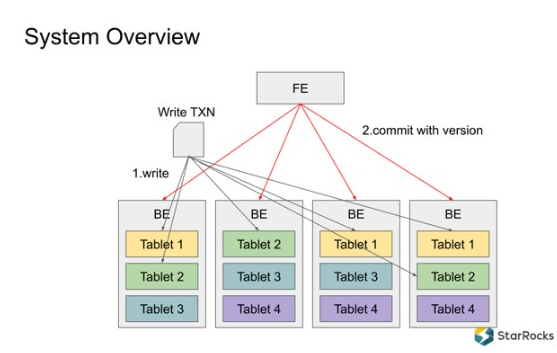
Write 阶段:在第一阶段,将写入事务的数据按照分区分桶规则分散地写入到很多的 Tablet里,每个 Tablet 收到数据后把数据写成内部的列存格式,形成一个 Rowset;
Commit 阶段:所有数据都写入成功后,FE 向所有参与的 Tablet 发起事务、提交 Commit,每个 Commit 会携带一个 Version 版本号,代表 Tablet 数据的最新版本。Commit 成功后,整个事务就完成了。
- 1
2. Tablet 内部结构
Tablet 是 StarRocks 底层存储引擎的基本单元,每个 Tablet 内部可以看作一个单机列存引擎,负责对数据的读写操作。
Tablet 内部分为以下四个部分: 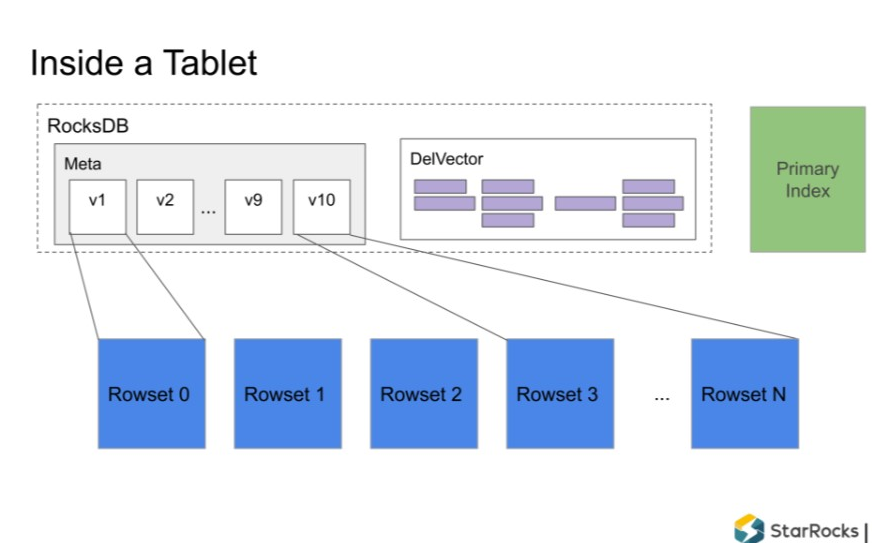
Rowset:一个 Tablet 的所有数据被切分成多个 Rowset,每个 Rowset 以列存文件的形式存储。
Meta(元数据):保存 Tablet 的版本历史以及每个版本的信息,比如包含哪些 Rowset 等。序列化后存储在 RocksDB 中,为了快速访问会缓存在内存中。
DelVector:记录每个 Rowset 中被标记为删除的行,同样保存在 RocksDB 中,也会缓存在内存中以便能够快速访问。
Primary Index(主键索引):保存主键与该记录所在位置的映射。目前主要维护在内存中,正在实现把主键索引持久化到磁盘的功能,以节约内存。
- 1
3. 元数据组织
和Delta lake或者其它数据湖保存元数据的方式类似,也是一个MVCC多版本方式。每次写事务或者每次Compaction 都会生成新的元数据版本。版本里面会记录这个版本包含哪些Rowset、相对上一个版本它的增量数据是什么(就是Delta)。  举个例子:
举个例子:
① 一开始创建一个tablet,版本是1.0,Rowset是空的,Delta也是空的
② 新来一个数据,写入数据后版本号变成 2.0,Rowsets 包含Rowset 0,Delta 相比上一个版本增加了Rowset 0
③ 又做一个新的commit,加进去一个Rowset 1,版本号变成 3.0
④ 假设两个Rowset 比较小,触发了一个compaction。输入Rowset 0 和1 ,目标是合并这两个Rowset。compaction 需要时间,但系统还会继续接收数据写入
⑤ 又commit一个新的版本 4.0,新加入Rowset 2,这时候Rowsets 里面包含 Rowset 0、1、2 三个Rowset
⑥ 这时compaction 完成,把Rowset 0 和 1合并为 Rowset 3,Rowsets 里就是 Rowset 2 和 3,版本变成 4.1
⑦ 最后再写入一次数据,版本变成 5.0,Rowsets 里有 Rowset 2、3、4,Delta 是 Rowset 4 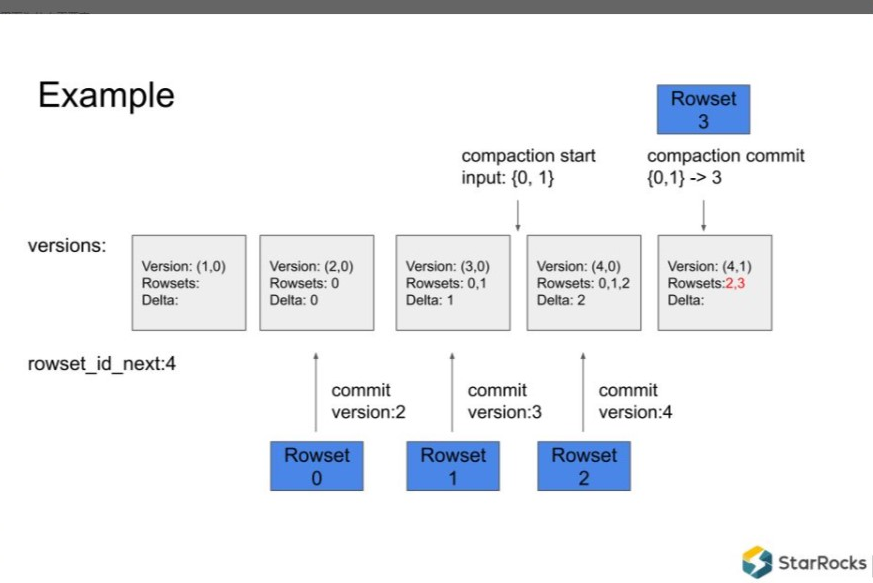 从上可以看出这是一个MVCC多版本的元数据组织,同时支持并行的Compaction 和写入操作。
从上可以看出这是一个MVCC多版本的元数据组织,同时支持并行的Compaction 和写入操作。
随着数据不断导入,元数据版本会逐渐积累,这个版本不能一直这样积累(每分钟可能产生好几个导入,半个小时可能上百个版本,一直下去元数据大小会很恐怖)。我们可以把一些老的版本,不太可能会被用到的版本元数据GC掉。其原理是:每个版本都有时间戳,当时间已经比较老了,就认为不太可能被查询到,就可以把它删除掉,删除后整个元数据大小就变小了,同时被compaction 过清理掉的Rowset也可以删除,回收存储空间。 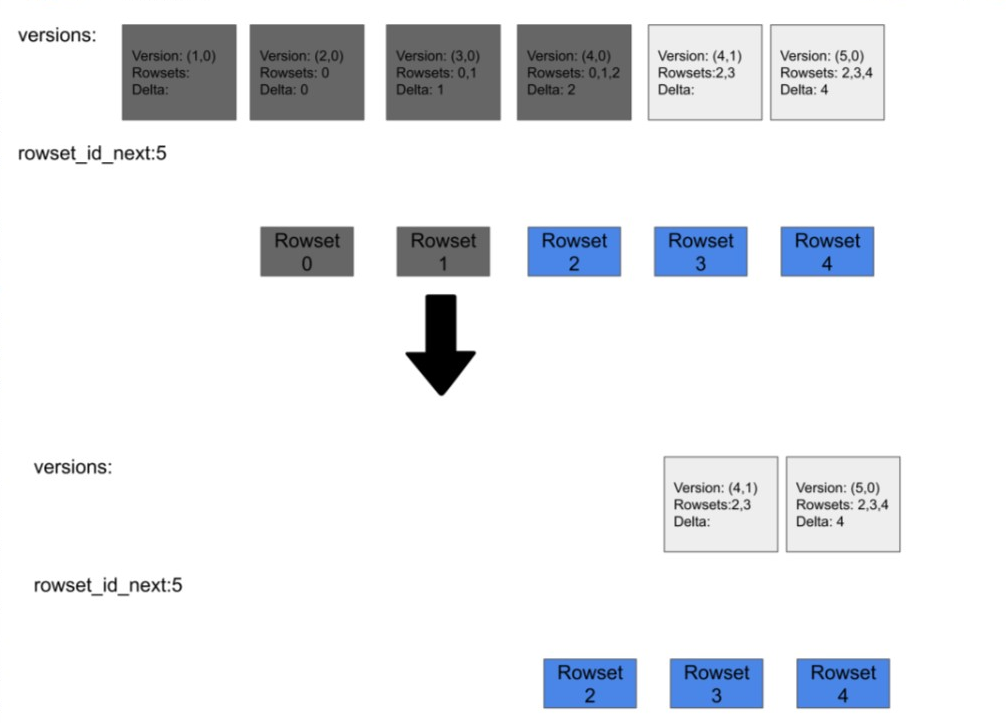
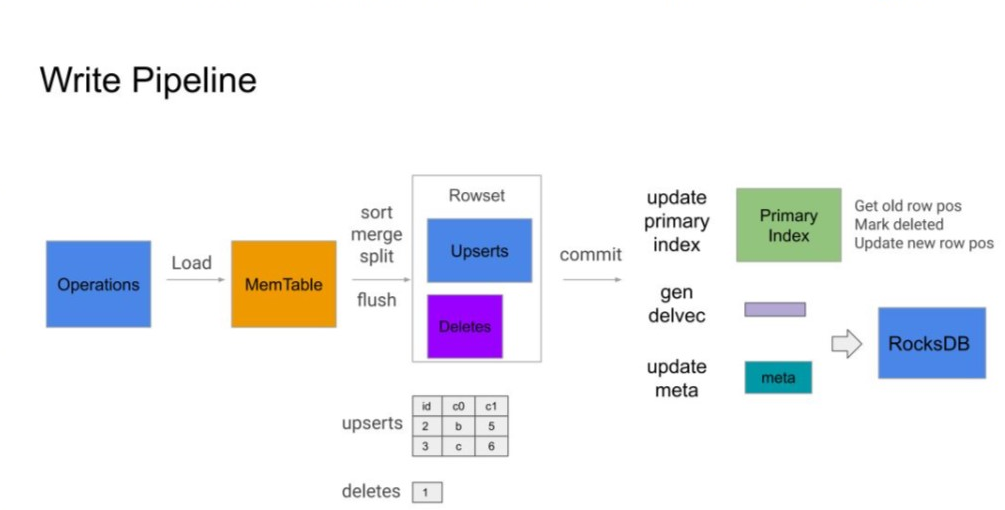
4. 写入流程
目前数据库里的写事务基本上是导入的方式来完成。导入就是把一批数据通过Broker Load 或者 StreamLoad 的方式整个写入到系统里面。从前面可以知道写入数据是由每个 Tablet 负责,每个 Tablet 接收到数据后,会执行一个写入流程。 写入流程如下:
① Tablet 收到批次数据后,先写到 MemTable 里面(在 MemBuffer 里保存),MemBuffer 满了之后再Flush到存储引擎上面。
② 在 Flush 之前会把这批导入中 Upsert 操作和 Delete 操作拆分开,同时还要按主键去重,最终效果是这批导入里的 Upsert 操作和 Delete 操作的 key 不再重复,相当于老版本被新的版本覆盖。Flush 包含 Sort、Merge、Split 三个操作,Sort 先按主键对数据排序,Merge 对主键相同的多条记录进行合并,只保留最新版本的数据。Split 把这批操作中的 Upsert 和 Delete 操作拆分开来,写入不同的文件。
③ Flush 完成后会生成一个包含多个文件的新 Rowset。
④ 这批数据发送完毕并 Flush 后,FE 发起 Commit 流程。BE 以一个单独的事务提交,同时查询 Primary Index 找到所有被更新的记录标记为删除,并生成 DelVector ,与新版本 Meta 一起提交到 RocksDB 中,达到事务的原子性。
- 1
 简单样例说明:
简单样例说明:
① 假设刚开始有一个Rowset 0 写入到系统,里面有1,2,3,4 四条记录
② 又一次写入,主键是1,3,5,发现1,3 已存在,它们就是 upsert 更新的操作。通过查询主键索引能够得到这两条记录原来在哪个位置,在原来的位置上生成delVector
③ 假设又新来一个事务,要对 6 进行插入,同时删除主键为 3 的记录。同样查询主键索引获取位置并生成delVector
④ Rowset 3 commit 后,也是查询主键索引,增量的生成delVector
整个过程完成之后,也生成了MVCC 的结构,查询引擎可以查询任何版本得到相应的数据。 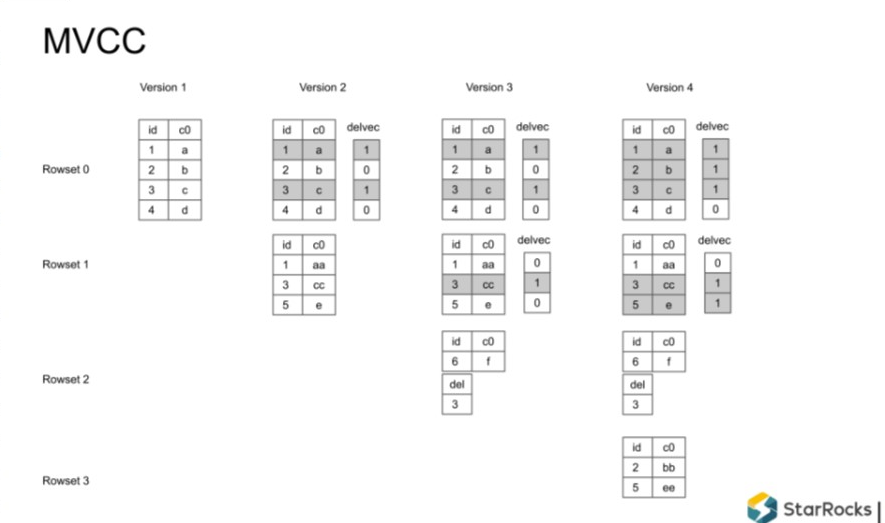
5. 写事务并发控制
StarRocks 支持并发写操作,系统中可能同时存在多个并发读事务和并发写事务执行。
对同一个表的写事务并发:
写入流程可以并发执行
但是 Commit 需要序列化(顺序)执行
- 1
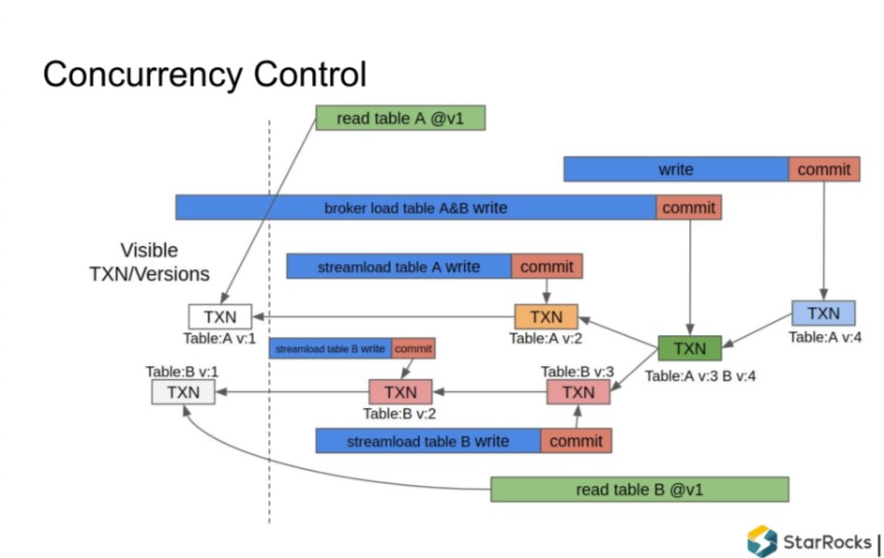 序列化执行过程中,Commit 需要做的事情是要更新Primary Index、同时生成 DelVector,然后把 DelVector 和 Meta 写入RocksDB。
序列化执行过程中,Commit 需要做的事情是要更新Primary Index、同时生成 DelVector,然后把 DelVector 和 Meta 写入RocksDB。 
6. 主键索引
Commit 阶段的最主要工作是查找和更新主键索引,约占整个 Commit 过程 90% 以上的时间。怎样让这个关键一步尽量的快?目前主键索引使用的是高性能内存 HashMap。
Key 是主键通过二进制编码后形成的 Binary String串
Value 是一个unit64位的行位置信息,前面32位是rowset_id,后面32位是rowset内部的rowid
HashMap 使用的是高性能的开源 phmap 库,每次操作耗时仅 20ns~200ns,单核可以达到 5M-50M op/s。如果一个导入事务有1千万行,要写入10个bucket,每个bucket 进行100万的hashmap的操作,这100万的操作在Primary index里面只需要0.1左右。这个commit过程是非常快的,也能保证整个系统多个写事务的并发操作。
- 1
主键索引优化:
① 由于支持的都是一些批量操作,可以通过预取的方式加速Hashmap操作,可以缓解 Cache miss 的开销
② 主键索引非常占内存,针对定长和变长类型的主键分别做了一些优化,以降低内存占用
定长主键使用定长的字符串类型(如:FixSlice) 保存到hashmap里面,就不需要保存字符串长度
变长主键设计一个shard by length的 hashmap,类似clickhouse里的hashmap,可以节约 1/2 ~ 1/3 的内存
cashe on-demand loading,如果一个表暂时没有更新操作(6分钟内没有load),就不加载到内存
③ 目前在做的工作
优化常量和基数低的主键列,减少内存占用
使用原始列128bit hash 做为主键,风险是有可能有冲突,但是冲突概率非常低,对特定应用可用
- 1
可持久化主键(Persistent Primary Index):
这项工作正在进行,大概思想还是用 hashmap 的方式实现。很多索引要么是用 LSM 的方式做,要么用 B tree 的方式做,都是有序索引,StarRocks 中没有有序的需求,所以使用 hashmap 的方式。 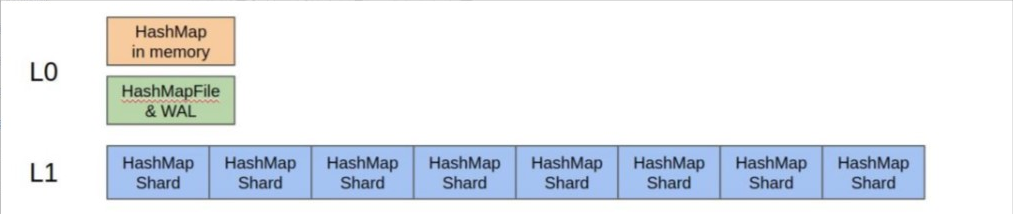 组织方式是 LSM Tree 的思想,分多层:
组织方式是 LSM Tree 的思想,分多层:
L0层 映射在内存里,有一个buffer,同时写 WAL(预写日志系统,一种高效的日志算法)或者 FlushSnapshot 。
L1层是 Shard HashMap,保存在磁盘上,每个shard 大概1M左右大小。如果有批量的读操作,可以根据 shard 把批量读操作也跟L1 shard 大小一样分成很多 bucket 。
- 1
比如一批读操作有100条,分8个shard,每个shard 大约 10几条的读操作,每次读操作批量的把 shard load 上来,操作完成后,shard 内存可以再释放掉,读取下一个 shard。
7. 场景:冷热数据
主键索引对内存要求比较高,比较适用两个场景,一个是数据按时间分区,数据按时间有冷热特征,比较老的数据基本上不会被更新,被更新的数据基本是最近几天的数据。因为我们的主键是 lazy 加载的方式,只有最近几天的表分区的加载到主键索引占用内存,整个表的内存就可空。 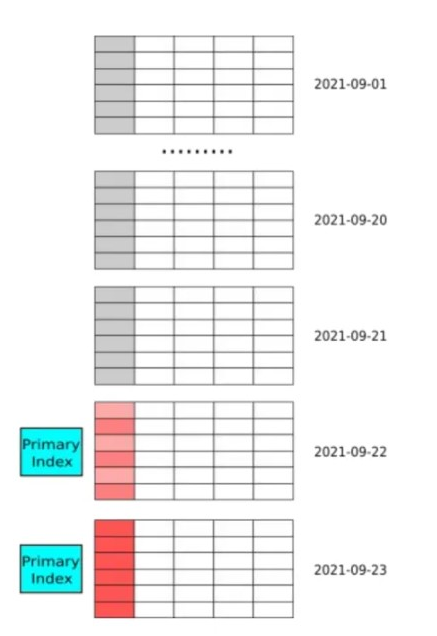 很多场景都是这个场景,比如:
很多场景都是这个场景,比如:
在线电商订单表
共享打车和共享单车的骑行订单数据
移动端 App 和 IOT 设备的 sessions
- 1
8. 场景:大宽表
Column 非常多(大于 100列),主键只占整个存储数据量的很小部分,可以允许整个主键索引放在内存里,对整个系统的消耗有限。  像 User profile ,用 user_id 做主键,占内存也不是特别大。
像 User profile ,用 user_id 做主键,占内存也不是特别大。
9. Compaction
对数据的更新和删除会使得 Rowset 中的大量记录被标记为删除,另外数据持续实时导入会导致存在大量小的 Rowset 文件,这些会影响查询的读取性能,并且会浪费存储空间。StarRocks 的 Compaction 作用是删除已经标记删除的行、把实时导入产生的大量小文件合并成大文件。
LSM compaction 是merge 一些 sst 文件生成一个新的 sst 文件,在元数据里面原子的对 sst 文件进行替换。 StarRocks compaction 与 LSM 不同点在于:
没有重复记录,不需要考虑相同Key的merge。
没有 delete / range delete 的记录,rocksdb 曾经出行过 range delete bug。
由于引入了主键索引,Compaction 会使得记录的实际位置发生变化,这个变化需要同时反应到Primary Index里面, 这个数据就增加了复杂度。
- 1
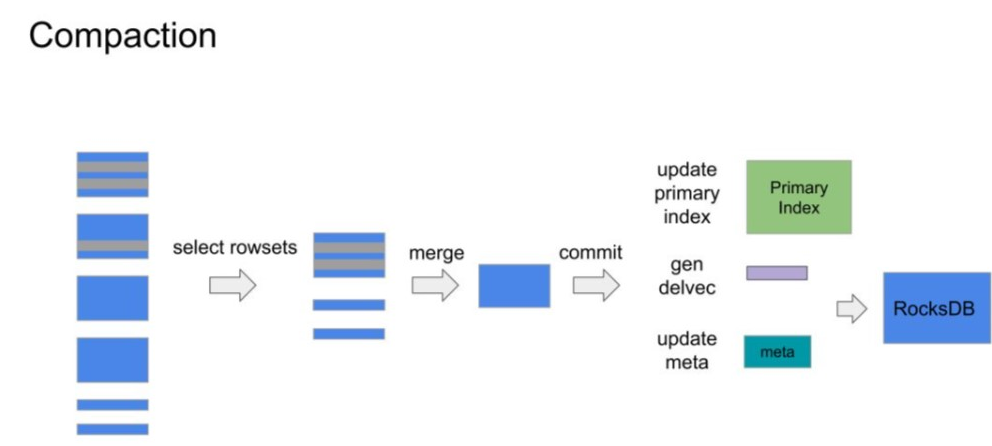
Compaction 可以理解为一个写入的事务,和外部写入事务类似:
根据策略,挑选一些 Rowsets。
merge Rowsets,生成新的 Rowset。
作为一个 Commit 把元数据写入到 rocksdb里面,同时生成 DelVector,在元数据中原子替换掉输入的 Rowsets 也写入到rocksdb里面。
- 1
10. Merge-on-Read vs Delete+Insert 模式
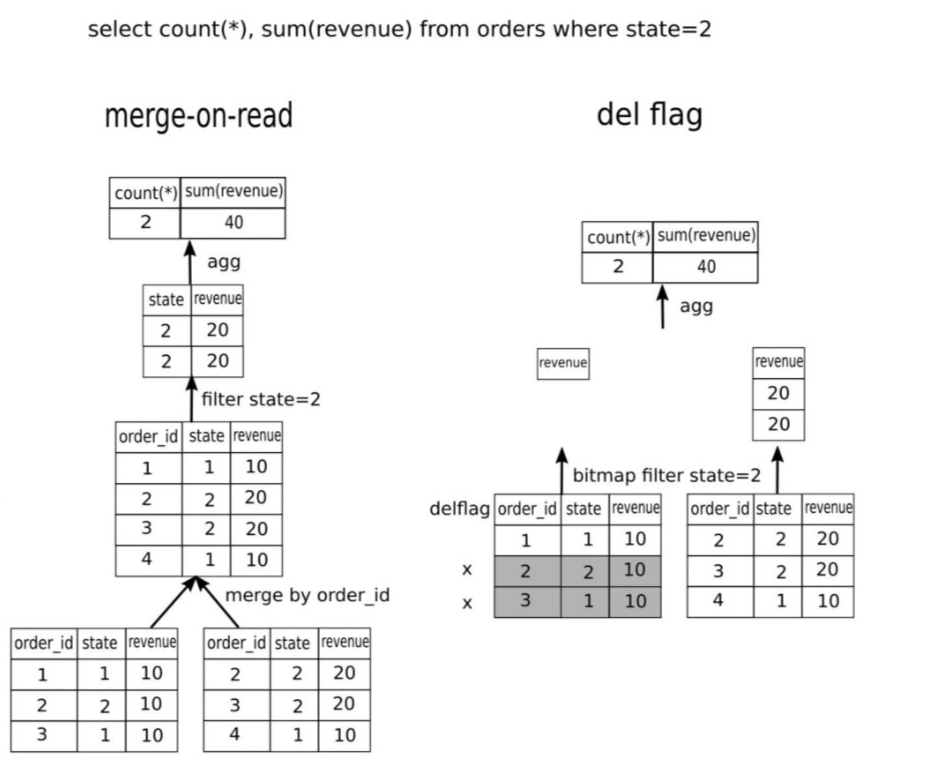
Delete+Insert 模式为什么对性能提升那么明显,这里与 Merge-on-Read 对比来看,对订单做统计查询:
使用 merge-on-read 方式,首先需要多个Rowset 需要做一次merge 操作,得到 merge 表后才应用 filter,过滤后再对剩下的数据进行汇总统计得到结果。
使用 delete + insert 方式,不需要 merge 操作,filter 可以下推到存储引擎最下面一层,这就可以利用 bitmap 索引加速查询。而 merge-on-read 方式下索引就失效了,另外merge-on-read 中需要把 order_id 和 state 列读取出来。在 delete + insert 这边 order_id 和 state 都不需要读,这极大的减少了 IO 量。
总结来看优势有以下几点:
不需要 merge 操作
不需要读 order_id,省 IO
过滤条件下推,利用 bitmap 索引加速查询
只扫描返回 revenue 列
- 1
11. Benchmark
(1)Simple Query on Single Table
这是内部一个测试,在实时导入的情况下,模拟订单表,数据量大概 2 亿行左右,5分钟一个batch。实际是2~3秒导入一次,很短的时间内把 2 亿条数据导入到系统里。一边导入一边查询,和原来 Merge-on-Read 方式对比,在简单查询的情况下有10到几十倍的性能提升。 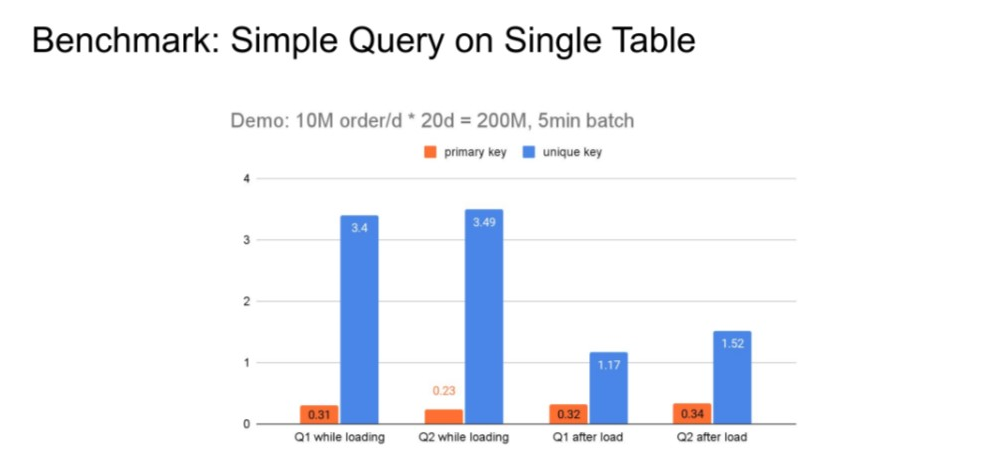 (2)TPC-H 1T
(2)TPC-H 1T
利用标准的TPC-H 1T 数据和市面上商用的MPP支持更新的数据库进行对比,基本上有2倍甚至2倍以上的性能提升。 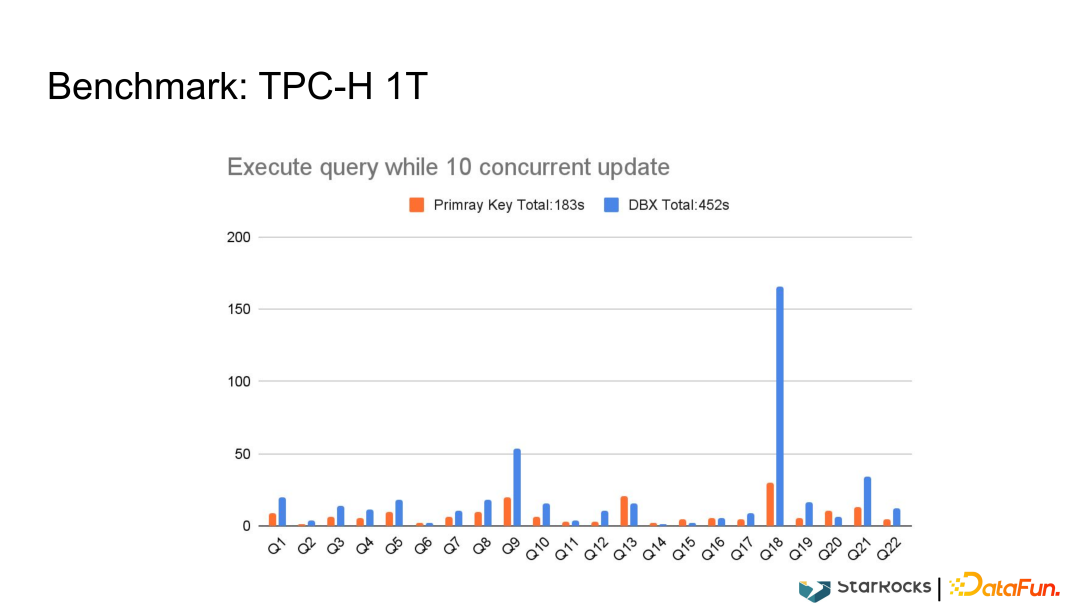
03 当前和未来工作
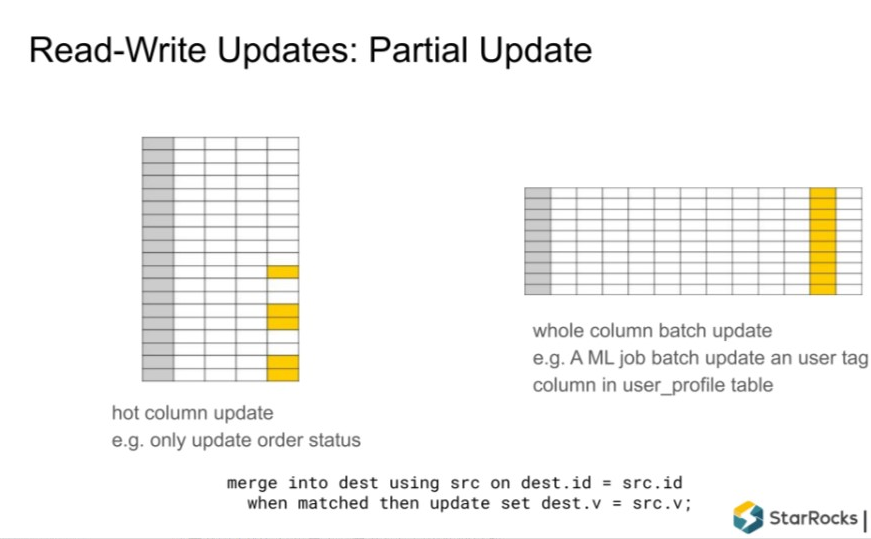
1. 支持 Partial Update(部分列更新)
StarRocks 现有支持的操作类型包括 Upsert 和 Delete,就是整行的更新和删除。Partial update 就是只更新其中的某一列或者某几列而不是所有的列。这个在 Merge-on-Read 里面很容易实现,但是在 Delete + Insert 的方式下有写挑战。最大的挑战是,比如一个表有100列,只更新其中一列,在做 Insert 过程中要把原来版本的数据先读上来拼成一整行之后才能写入。但是在列存情况下,99列可能需要做99次随机 IO 才能一行拼出来,对整个存储系统的 IO ps数压力特别大。 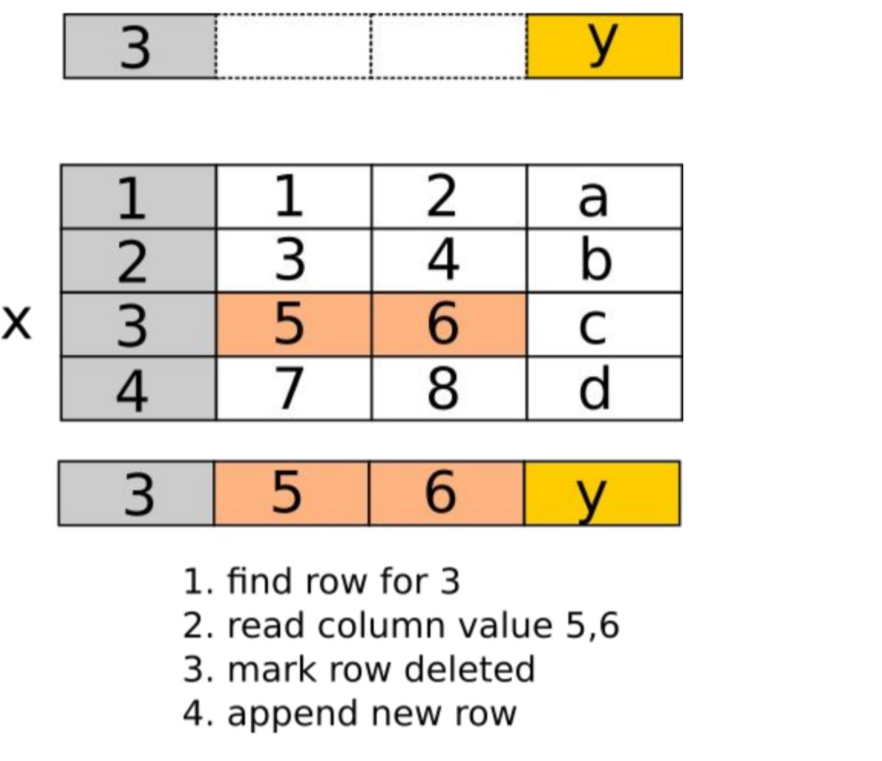 目前只实现了功能,如果是一个NVMe 或者 SSD 的磁盘基本能够杠住一定的流量 ,再高的流量还不太适合这个场景,后面也会持续优化。
目前只实现了功能,如果是一个NVMe 或者 SSD 的磁盘基本能够杠住一定的流量 ,再高的流量还不太适合这个场景,后面也会持续优化。
对一些隔离级别比较高的场景,在最后写入 commit 时需要检查冲突,如果写入事务发生冲突,还需要解决冲突操作,这里不做详述。
适用场景:
固定列的更新,比如订单表,第一次写入时大部分列已经固化,只会一些固定列比如订单状态。
某列的批量更新,比如 user_profile 表,上游有些像机器学习的任务批量更新用户标签。
大宽表,维护一个大宽表查询时不在需要 Join ,可以提高查询性能。对大宽表一般都是由两个或两个以上的Job 来导入,每个Job 只更新部分列。
- 1
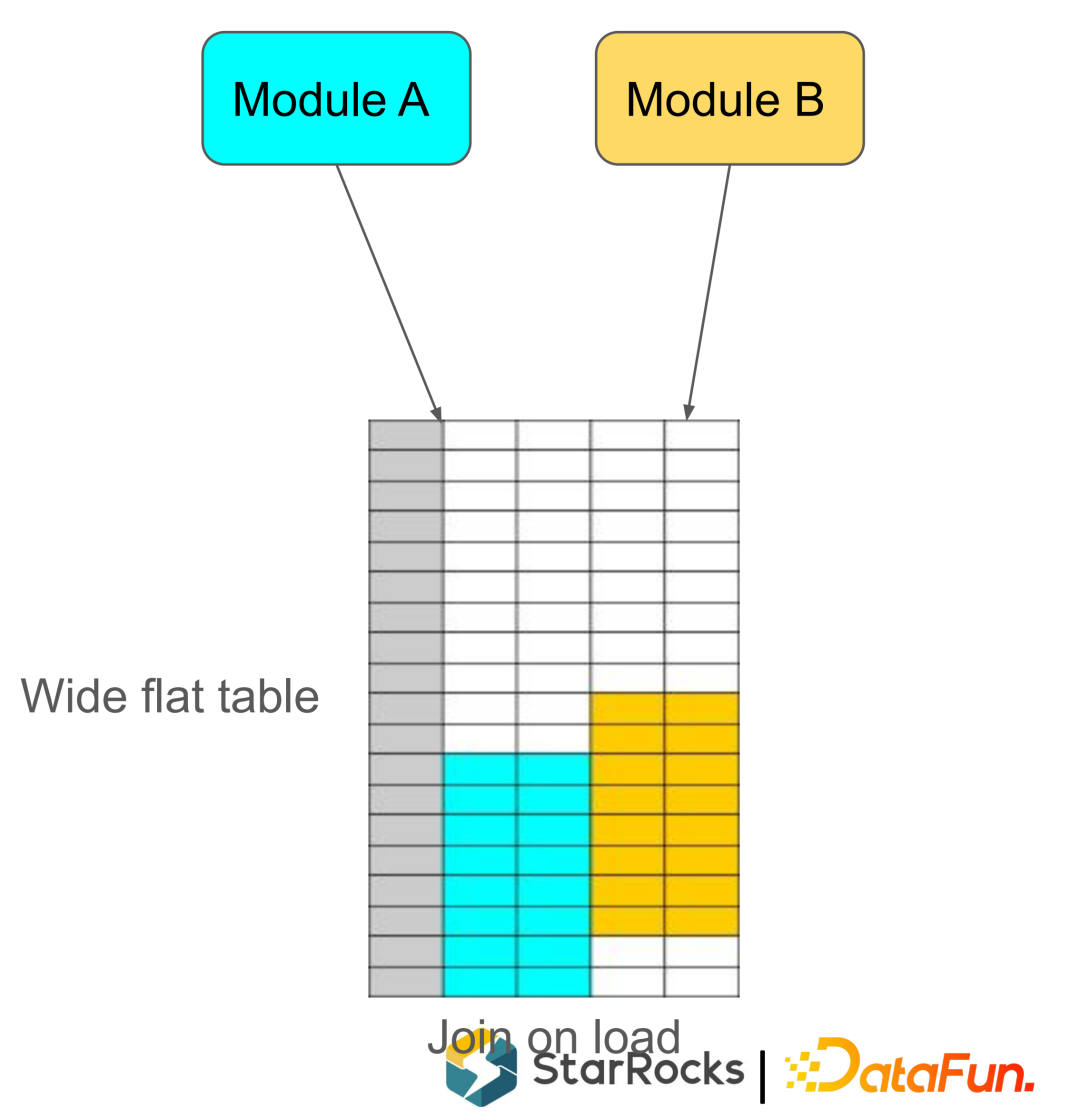
2.支持 Conditional Update(条件更新)
导入数据满足一定条件才更新,典型场景是:上游数据乱续到达,需要通过一个时间戳来判断是否需要更新。 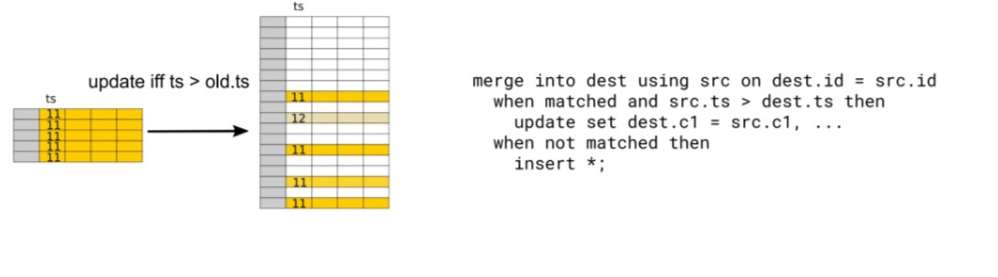
3.支持 Merge Update
对嵌套数据类型比如 Array 或者 Map/Set 新增加一笔记录。
array append
map/set add
- 1
4.通用 Read-Write 事务
做一些通用的修复工作,一般是多行的事务。比如要修补一个用户的订单数据,先需要把这个用户的数据删掉,再把新数据导入进来,而且要做到原子生效。 
5.Primary Key 表的物化视图
现在的Primary key 表不支持物化视图,因为如果 Primary key 表一些记录被修改了,无法增量的直接反馈到物化视图中。实现思路是 update Primary key 表之后,需要生成一个delta 数据,根据 delta 数据写到物化视图中去。 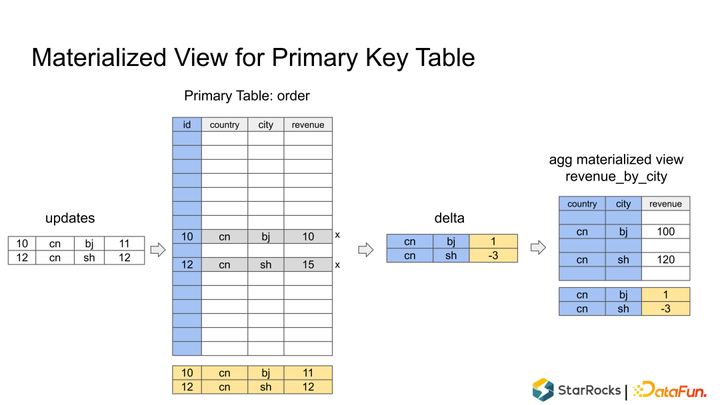

本文由 mdnice 多平台发布



