
- 1SpringBoot中使用ElasticSearch聚合功能_elasticsearch多字段聚合+springboot
- 2Activity的启动和结束_activiti 结束流程
- 3并查集详解(原理+代码实现+应用+优化)_单向并查集代码
- 4如何从GitHub上下载来客源码并运行?_github下载下来的代码怎样运行
- 5百子作业 —— 中国邮递员问题_中国邮递员问题例题及答案
- 603 Python进阶:MySQL - mysql-connector_python mysql.connector
- 7深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-01-CNN基础知识点_cnn和dl
- 8python实现读取文件中的视频数据并实时展示_python读视频
- 9/etc/init.d/sshd配置SSHD路径忘记修改导致启动失败
- 10Java数组知识整理_for (string aa :bb)
NLP系列 9. Attention机制_nlp attention机制
赞
踩
Attention机制介绍
之前做项目时同组大佬用到过Attention机制,Attention机制对模型能够有一定的提升作用。
人在看一张图片一篇文章时,不会对所有部分都投入同样的注意力,而是有所侧重。所谓侧重就是赋予不同的权重。

Attention定义
Attention是一种用于提升基于RNN(LSTM或GRU)的Encoder + Decoder模型的效果的的机制。Attention机制目前非常流行,广泛应用于机器翻译、语音识别、图像标注等很多领域,之所以它这么受欢迎,是因为Attention给模型赋予了区分辨别的能力,例如,在机器翻译、语音识别应用中,为句子中的每个词赋予不同的权重,使神经网络模型的学习变得更加灵活,同时Attention本身可以做为一种对齐关系,解释翻译输入/输出句子之间的对齐关系,解释模型到底学到了什么知识,为我们打开深度学习的黑箱,提供了一个窗口。
Attention的原理
首先需要介绍Attention机制通常应用的场景:Encoder-Decoder:
Encoder-Decoder框架是深度学习的一种模型框架,是一个解决问题的通用框架,主要解决Seq2Seq类问题。Encoder-Decoder框架的流程可以理解为:先编码,存储,最后解码。用人脑流程来类比,先看到的是源Sequence,人脑根据自己的知识理解这个Sequence,并将理解的记忆下来,形成记忆(对应Context),这个过程叫Encoder。然后,再根据这个Context,针对不同的问题利于Context进行解答,形成答案并输出,这个过程叫Decoder。NLP的许多经典任务都可以抽象为Encode-Decoder,比如:机器翻译、文本摘要、阅读理解及语音识别等。模型的框架如下图所示:

在seq2seq模型中经常会遇到以下问题:
- 当输入序列非常长时,会损失一些信息,模型难以学到合理的向量表示;
- 序列输入时,随着序列的不断增长,原始根据时间步的方式表现越来越差。这是由于原始的这种时间步模型设计的结构有缺陷,即所有的上下文输入信息都被限制到固定的长度,整个模型的能力都同样受到限制;
- 编码器的结构无法解释,也就导致了其无法设计;
而Attention机制就是根据当前的某个状态,从已有的大量信息中选择性的关注部分信息的方法。Attention机制打破了传统Encoder-Decoder结构在解码时都依赖于内部一个固定长度向量的限制。基本思想是:通过保留编码器对输入序列编码的中间结果,然后训练一个模型来对这些输入进行选择性的学习并且在输出时将输出序列与之进行关联,不再是使用固定的向量c,而是在模型输出时会选择性地专注考虑输入中的对应相关的信息。所以可以引入Attention机制加以改进。
HAN的原理(Hierarchical Attention Networks)
HAN就是多层注意力模型,示意图如下:

利用了两次Attention机制,一层基于词,一层基于句。
首先是词层面:
输入采用word2vec形成基本语料向量后,采用双向GRU抽特征:
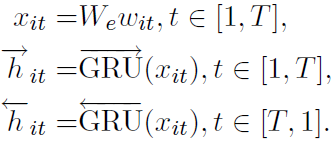
一句话中的词对于当前分类的重要性不同,采用attention机制实现如下:

利用Attention模型进行文本分类
参考:https://github.com/zhaowei555/multi_label_classify/blob/master/han/han.py


