
- 1高并发抢票时,防止机器人刷票的令牌大闸,减轻服务器的压力(防刷+限流)
- 2IDEA提交代码到GitHub_idea git commit and push
- 3图文讲解:iOS App提交流程_ios developer 创建app sku 是什么
- 4干货 | 关于SwiftUI,看这一篇就够了
- 5【计算机网络】[第三章:数据链路层][自用](需要重新排版)
- 6STM32编写ADC功能,实现单路测量电压值(OLED显示)_stm32战舰v3 adc显示到oled
- 7深度学习1:神经网络原理与算法详解_深度神经网络算法原理
- 8signature=37447d22ba390eb81bb1cd3414a3fcfb,generator-nodex
- 9kali linux 安装教程(最新)_kali虚拟机安装步骤
- 10sharding-jdbc分片策略
内存分配_内存的连续分配与回收
赞
踩
连续分配指为用户进程分配的必须是一个连续的内存空间。
内部碎片:已经分配给进程,但进程没有利用的存储空间。
外部碎片:内存空间太小无法被进程利用。
一、单一连续分配(无外部碎片,有内部碎片)——采用绝对装入
在单一连续分配方式中,内存被分为系统区和用户区。系统区通常位于内存的低地址部分,用于存放OS相关数据。用户区用于存放用户进程相关数据。
内存中只能有一道用户程序,且该用户程序独占整个用户区空间。
优点:实现简单;无外部碎片;可采用覆盖技术扩充内存,不一定需要采取内存保护。
缺点:只能用于单用户、单任务OS,有内部碎片,存储器利用率极低。
二、固定分区分配(无外部碎片,有内部碎片)——采用静态重定位装入
支持多道程序OS的出现,为了能在内存中装入多道程序,且这些程序之间又不会互相干扰,于是将整个用户空间划分为若干固定大小的分区,在每个分区中只装入一道作业,这样就形成了最早的,最简单的一种可以运行多道程序的内存管理方式。
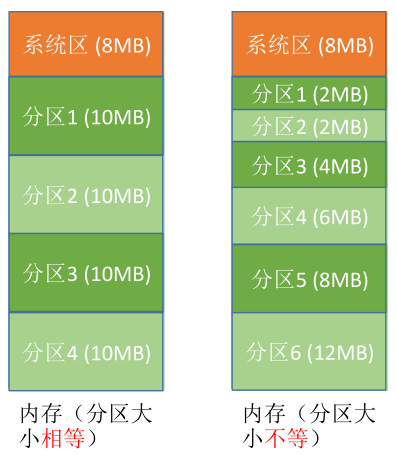
①分区大小相等:缺乏灵活性,但很适合用于一台计算机控制多个相同对象的场合。
②分区大小不等:增加了灵活性,可满足不同大小的进程需求,根据常在系统中运行的作业大小情况进行划分。
优点:实现简单,无外部碎片。
缺点:
当用户程序太大时,可能所有的分区都不能满足需求,此时不得不采用覆盖技术来解决,但这又会降低性能。
会产生内部碎片,内存利用率低。
两种常用的内存管理数据结构——空闲分区表和空闲分区链
为了方便管理各个分区,OS需要建立数据结构来记录内存的使用情况,来实现各个分区的分配与回收。
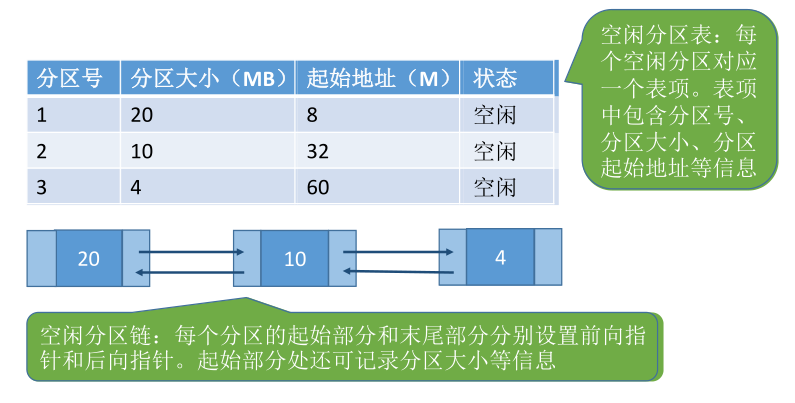
当某用户程序要装入内存时,由OS内核程序根据用户程序大小检索该表,从中找到一个能满足大小且未分配的分区,将之分配给该程序,然后修改状态为“已分配”。
三、动态分区分配(无内部碎片,有外部碎片)——动态重定位装入
动态分区分配又称可变分区分配(分区大小和位置都可变)。这种分配方式不会预先划分内存分区,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。因此系统分区的大小和数目是可变的。
动态分区和固定分区分配方式相比,内存空间的利用率要高一些。但是,总会存在一些分散的较小的空闲分区,即外部碎片,它们存在与已分配的分区之间,不能充分利用。可以采用拼接技术加以解决。
当多个空闲分区都能满足需求时,应该选择哪个分区分配呢?
把一个新作业装入内存时,需按照一定的动态分区分配算法,从空闲分区表(或空闲分区链)中选出一个分区分配给作业。
动态分区分配的分配算法有4种:首次适应算法、最佳适应算法、最坏适应算法以及邻近适应算法。
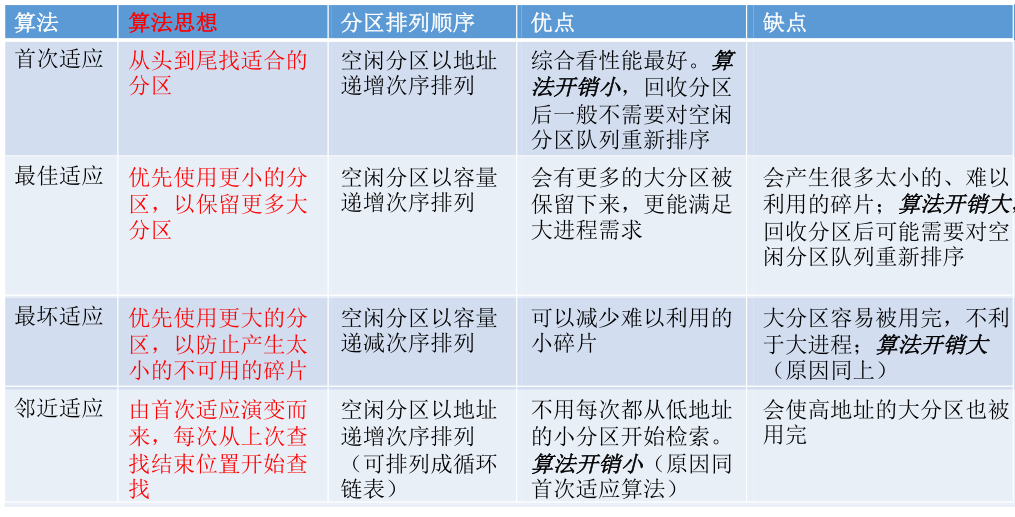
1、首次适应算法(First Fit)——顺序遍历符合就分配
每次都从低地址开始查找,找到第一个能满足大小的空闲分区。
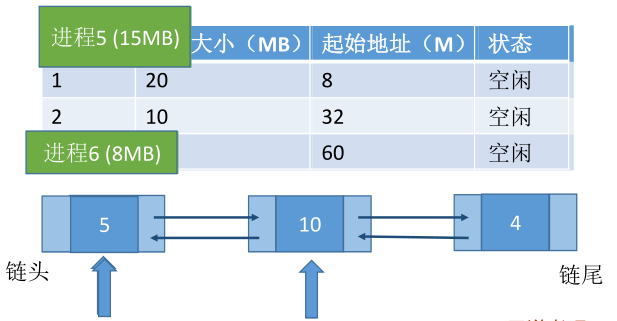
实现原理:空闲分区以地址递增的次序排列,每次分配内存时顺序查找空闲表(或空闲分区链),找到大小能满足要求的第一个空闲分区分配给进程。
2、最佳适应算法(Best Fit)——容量递增
最佳适应算法总是匹配与当前大小要求最接近的空闲分区,但是大多数情况下空闲分区的大小不能完全和当前要求的大小相等,几乎每次分配内存都会产生很小的难以利用的内存块,所以最佳适应算法最容易产生最多的内部碎片。
为保证当“大进程”到来时能有连续的大片空间,可以尽可能多地留下大片的空闲区,即优先使用更小的空闲区。
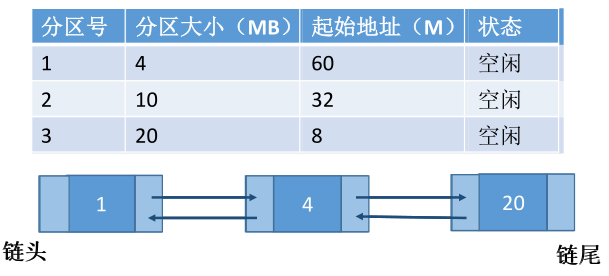
实现原理:空闲分区按容量递增的次序链接,每次分配内存时顺序查找空闲分区链(或表),找到满足要求的第一个空闲分区分配给进程。
注:每次分配完之后都要重新按容量递增的次序排列空闲分区链(或表)。
缺点:每次都选最小的分区进行分配,会留下越来越多小的难以利用的外部碎片。
3、最坏适应算法(Worst Fit)——容量递减
为了解决最佳适应算法外部碎片过多的问题,可以在每次分配时优先使用最大的连续空闲区,这样分配后的剩余空闲区就不会太小。
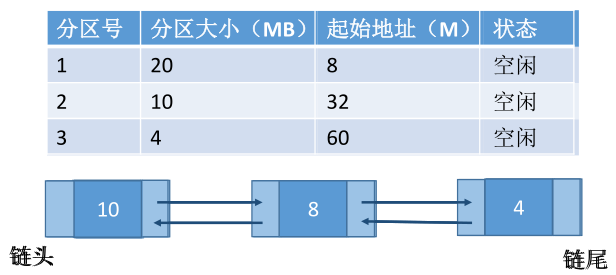
实现:空闲分区按容量递减的次序链接。(即链头的第一个空闲分区一定满足)
缺点:每次都选最大的分区进行分配,虽然可以让分配后留下的空闲区更大,但会导致较大的连续空闲区被迅速用完,如果之后有”大进程“到达,就没有符合的空闲分区分配了。
4、邻近适应算法(Next Fit)——地址递增
首次适应算法每次都从链头开始查找,这可能会导致低地址部分出现很多小的空闲分区,而每次分配查找时,都要经过这些分区,因此也增加了查找的开销。如果每次都从上次查找结束的位置开始检索,就能解决上述问题。
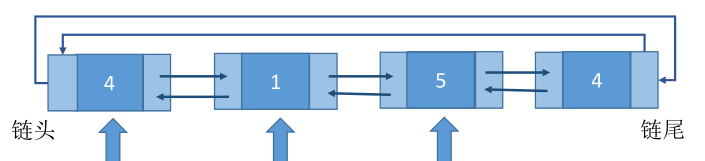
实现:空闲分区以地址递增的顺序排列(可排成一个循环链表),每次分配内存时从上次查找结束的位置开始查找空闲分区,找到第一个满足的分区。
缺点:导致高地址部分的大分区被使用(本来低地址有可用的分区)划分为小分区,最后导致无大分区可用。
首次适应算法每次都要从头查找,每次都需要检索低地址的小分区。但这种规则也决定了当低地址部分有更小的分区可以满足需求时,会更有可能用到低地址部分的小分区,也会更有可能把高地址部分的大分区保留下来(最佳适应算法的优点)。
邻近适应算法的规则可能会导致无论低地址、高地址部分的空闲分区都有相同的概率被使用,也就导致了高地址部分的大分区更可能被使用,划分为小分区,最后导致无大分区可用(最大适应算法的缺点)。
因此综合来看,反而首次适应最好,首次适应和邻近适应不需要重新排序。
空闲分区的分配与回收操作
以空闲分区表为例。
一、分配时如何改动空闲分区表
①空闲分区大小 > 申请大小
只用改变对应空闲分区的起始地址和大小项
②空闲分区大小 = 申请大小
删除对应空闲分区的表项
二、回收时,如何改动空闲分区表
①回收区的后面有一个相邻的空闲分区
改变后面相邻的空闲分区的起始地址和大小(即两个相邻的空闲分区合并为一个)
②回收区的前面有一个相邻的空闲分区
同样改变前面的空闲分区的起始地址和大小
③回收区的前后各有一个相邻的空闲分区
三个合并为一个(这时会导致空闲分区表长度减1)
④前后都没有空闲分区
新增一个表项
注:各表项的顺序不一定按地址递增顺序排列,具体的排列方式需要依据动态分区分配算法来确定。

