
- 1大数据处理与分析:Spark与Hadoop的实战应用
- 2“金三银四” “阿里” 我去定了,谁也拦不住我,中高级Android面试中你不得不会的知识点_rxdialogfragment ontouchevent
- 32024年鸿蒙最全鸿蒙面试题 :请说下你是如何发布鸿蒙三方库的?(2),2024年最新面试基础知识_ohpm面试题
- 4飞桨论文复现课笔记(论文复现步骤)
- 5政安晨的机器学习笔记——快速理解AI中的ML与DL概念_ai dl
- 6Github 配置 SSH key_github ssh设置
- 7聚类+分类器python代码_聚类分类python代码
- 8IPsec IKEv2(HCIP)
- 9git核心功能文件恢复(git reset/git checkout/git restore/git revert/git stash/git commit --amend)
- 10【长度测量】机器视觉单幅图像长度测量【含Matlab源码 4055期】_基于图像长度估测算法
EMNLP 2023 | LLM工业界快速落地之PromptMix: 一种有效的混合数据增强策略将LLM能力迁移到小模型_emnlp 2023prompt文章
赞
踩
今天分享一篇接受到EMNLP 2023的文章,Title: PromptMix: A Class Boundary Augmentation Method for Large Language Model Distillation。这篇论文致力解决文本分类中训练数据有限的问题。这篇文章提出了一种名为PromptMix的数据增强方法来解决文本分类在训练数据有限的情况下的问题。
该方法分为两步:1)生成靠近类别边界的挑战性文本增强数据;2)运用基于提示的LLM分类器对增强数据重新标记,提升生成数据标签的准确性。
本文在四个文本分类数据集上进行测试:Banking77、TREC6、Subjectivity(SUBJ)和Twitter Complaints,实验表明,PromptMix方法在所有数据集上都取得了很高的准确率,尤其是在B77和SUBJ数据集上,其性能与NN+GPT3.5相当,甚至在某些情况下超过了NN+GPT3.5。
一、概述
Title: PromptMix: A Class Boundary Augmentation Method for Large Language Model Distillation
链接: https://arxiv.org/abs/2310.14192
代码: https://github.com/servicenow/promptmix-emnlp-2023
Authors: Gaurav Sahu, Olga Vechtomova, Dzmitry Bahdanau, Issam H. Laradji
1 Motivation
- 利用大型语言模型如GPT3生成新示例以解决文本分类训练数据不足的问题。
- LLM推理成本比较高、DistiBERTbase和BERTbase等模型受限于训练数据不足问题,如何将LLM的知识有效转移到SLM上是一个工业界值得尝试的问题。
2 Methods
省流版总结:
论文通过提出PromptMix方法来解决提出的问题,该方法包括两个步骤:
- 生成靠近类别边界的挑战性文本增强(但这样做增加了数据集中出现误标的风险);
- 使用基于提示的大型语言模型分类器对文本增强进行重新标注,增强生成数据的标签准确性。

详细方法和步骤:
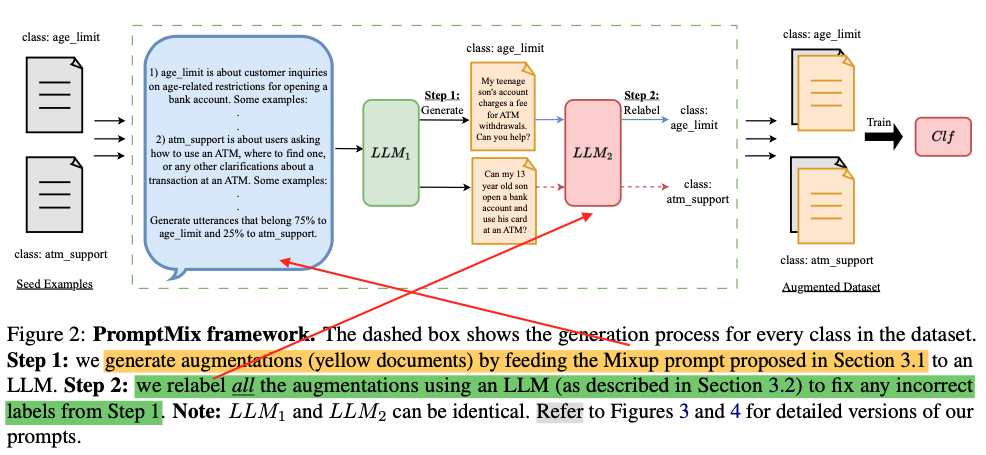
步骤一:挑战性文本增强生成: 根据已有的分类数据,在类别边界附近生成新的例子,从而提高模型面对边界情况的识别能力。

prompt分为三个部分,Instruct,Part1: 每个类别简要的概述。part2: 对于每一个类别 C i C_{i} Ci,随机选择一个 C j C_j Cj,按一定混合比例生成两者的难样本数据。
注意:生成结果中,有些分类是错的、有些结果是对的,需要进一步优化生成的Example。
步骤二:基于提示的LLM分类器重标记: 由于在类别边界附近生成的文本增强可能会增加假阳性的风险,所以使用基于提示的LLM分类器对这些数据进行重新标记,以保证生成数据的标签准确性。
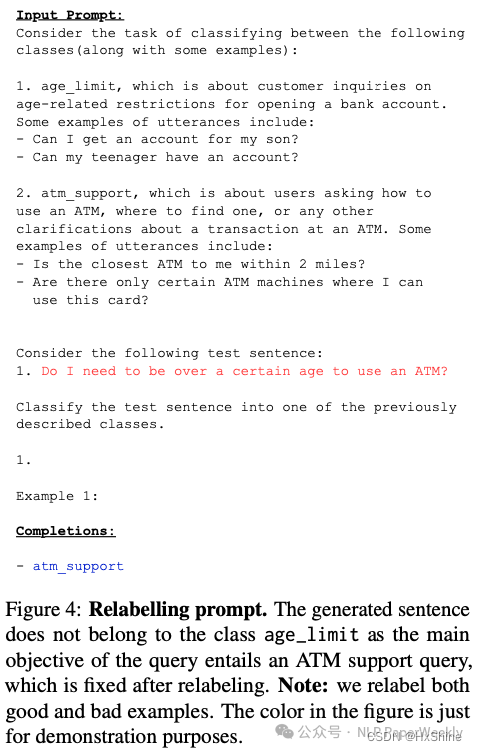
3 Conclusion
- PromptMix通过生成有挑战性样本和Relabeling策略,可以有效将如GPT3.5-turbo这样的大型LLM转移到更小、更便宜的分类器,如DistilBERT和BERT。
- 在Banking77、TREC6、Subjectivity和Twitter Complaints四个文本分类数据集中,2-shot PromptMix在多个5-shot数据增强方法上表现更佳。

二、详细内容
1 Mixup的效果

**结论:**Mixup能有效的将两个类别的信息进行混合,从而提升最终难样本的分类效果。
2 测试精度&消融实验
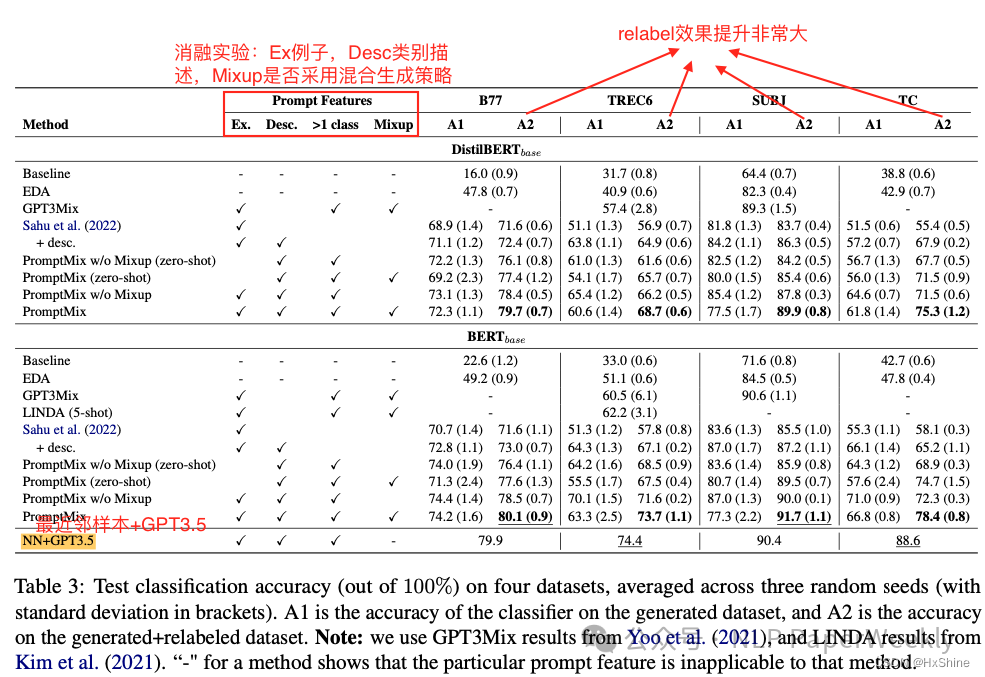
展示了在四个不同的文本分类数据集(Banking77、TREC6、SUBJ和Twitter Complaints)上,使用不同方法进行数据增强后的测试分类准确率。这些方法包括基线(Baseline)、NN+GPT3.5、Sahu等人的方法(Sahu et al. (2022))、PromptMix及其变体(包括有无Mixup的PromptMix)、Easy Data Augmentation (EDA)、GPT3Mix等。表格中还包含了使用GPT3.5-turbo生成的句子在重新标记(Relabeling)前后的变化,以及在不同方法下GPT3.5-turbo重新标记生成示例的百分比。
说明:
- Baseline:这是基线模型,它使用每个类别只有2个训练样本的原始数据集进行训练。这是为了展示在数据稀缺情况下,其他数据增强方法相对于基线的性能提升。
- NN+GPT3.5:这是一种使用最近邻(Nearest Neighbor)方法和GPT3.5模型的组合。在这种方法中,GPT3.5被用来对测试集的例子进行分类。
结论:
- 数据增强的有效性:在所有四个数据集上,使用数据增强方法(如EDA和PromptMix)的模型在测试分类准确率上显著优于基线(2-shot)模型。这表明在数据稀缺的情况下,数据增强是有帮助的。
- Relabel的重要性:通过比较A1(在第一步数据增强后)和A2(在第二步数据增强并重新标记后)的准确率,可以看出重新标记步骤显著提高了模型性能。这表明PromptMix方法中的重新标记步骤对于提高生成数据的质量至关重要。
- PromptMix方法的优势:PromptMix方法在所有数据集上都取得了很高的准确率,尤其是在B77和SUBJ数据集上,其性能与NN+GPT3.5相当,甚至在某些情况下超过了NN+GPT3.5。这表明PromptMix是一个有效的数据增强方法,尤其是在极端的少样本(2-shot)文本分类设置中。
3 Relabeling的效果
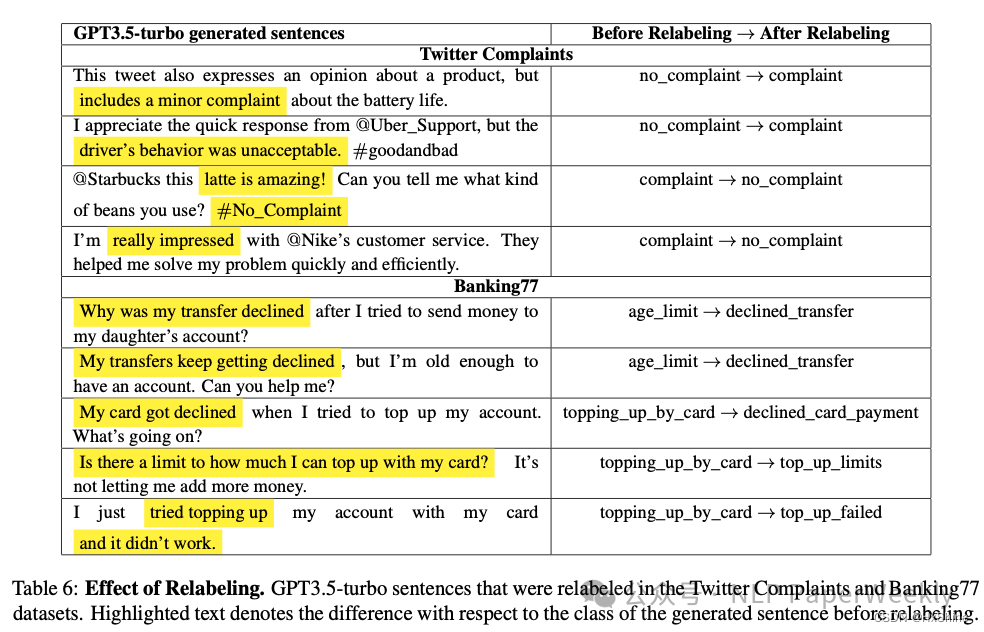
生成的数据由于使用Mixup混合策略,很容易产生badcase,利用Relabeling策略可以对这些标签进行修正,实验看出这一步带来效果的提升也非常大。
4 LLM基座对数据增强的影响
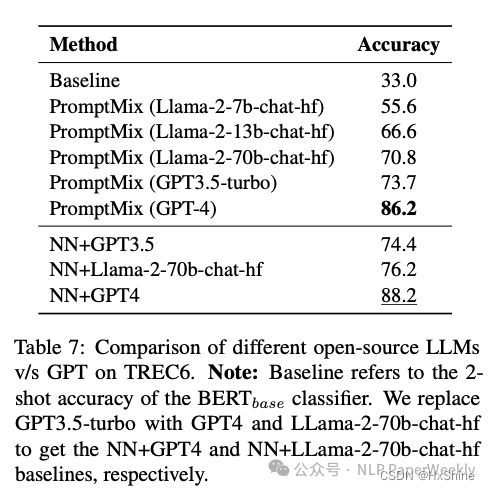
**结论:**基座模型能力越强,数据增强带来的效果越好,一方面是生成的质量越高带来的,另一方面Relabling阶段,LLM效果越好,也可能分的更准。
三、总结
这篇论文介绍了PromptMix,一种新颖的类边界数据增强方法,用于在训练数据有限的情况下提高大型语言模型的文本分类效果。该方法通过生成挑战性文本并结合Relabeling策略,生成类别精确的难样本,以便更好地迁移大型模型(如GPT3.5-turbo)的知识到更小、更经济高效的分类器(如DistilBERT和BERTbase)。论文的实验表明,PromptMix在2-shot场景中的效果优于多个5-shot数据增强方法。
结论1: PromptMix通过生成有挑战性样本和Relabeling策略可以有效将LLM知识迁移到小模型。 该方法通过生成接近类别边界的增强数据,然后使用LLM进行精准的Relabeling,有效提升了few-shot场景小模型的效果,可以大量降低人工的标注成本。
结论2: PromptMix为文本分类领域提供了一种新的数据增强策略。 本文所提出的方法在处理少量训练数据的情况下,为提升分类器的性能提供了新的思路和方案。这意味着我们用少量样本就可以训练处一个效果非常不错的分类模型,在工业界可能有着比较大的应用空间。
结论3: Relabeling策略可以带来非常大的效果提升。 说明直接用LLM生成样本效果不一定好,还需要进一步的处理策略,例如使用本文提到的Relabing策略,再利用LLM对增强的数据进行优化,从而整体上提升数据增强的质量。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家小花儿/article/detail/761201
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

