
- 1linux java 文件上传到服务器_java 上传文件到Linux服务器 工具类
- 2C/C++运行时库与 UCRT 通用运行时库:全面总结与问题实例剖析_msvcrt ucrt
- 3基于余弦相似度改进蝴蝶优化算法-附代码_余弦相似测度的改进
- 4【HIVE】HIVE— 索引、分区和分桶的区别_hive分区表 索引
- 5汽车芯片科普
- 6android 6.0 logcat机制(一)java层写log,logd接受log
- 7【数据结构】时间复杂度、空间复杂度(如何衡量一个算法的好坏 算法的复杂度 时间复杂度的概念 大O的渐进表示法 常见时间复杂度计算举例)_算法的时间复杂度有什么意义
- 8【SPIE出版-往届均已见刊检索 EI、SCOPUS双检索 | 高录用-稳定检索 | ISSN已确定(ISSN: 0277-786X)】第四届先进算法与信号图像处理国际学术会议(AASIP 2024)
- 9单片机STC89C52RC实现矩阵键盘(汇编语言版)_89c52接法
- 10SQLserver 2008r2 本地sa密码忘记_数据库2008r2忘记密码
【Python&语义分割】Segment Anything(SAM)模型介绍&安装教程_sam安装教程
赞
踩
1 Segment Anything介绍
1.1 概况
Meta AI 公司的 Segment Anything 模型是一项革命性的技术,该模型能够根据文本指令或图像识别,实现对任意物体的识别和分割。这一模型的推出,将极大地推动计算机视觉领域的发展,并使得图像分割技术进一步普及化。
论文地址:https://arxiv.org/abs/2304.02643
项目地址:Segment Anything
1.2 核心优势
Segment Anything 模型的核心优势在于其强大的泛化能力和广泛的适用性。该模型不仅可以接受来自其他系统的输入提示,例如根据 AR / VR 头显传来的用户视觉焦点信息来选择对应的物体,而且还能从科学图像分析、照片编辑等各类场景中识别出万物。同时,Meta AI 还发布了 Segment Anything 1-Billion(SA-1B)掩码数据集,这是计算机视觉领域有史以来体量最大的分割数据集。这个数据集的推出,使得 Segment Anything 模型能够支持更为广泛的应用场景,并助力计算机视觉基础模型的进一步研究。
1.3 使用方法
具体使用方法上,Segment Anything 提供了简单易用的接口,用户只需要通过提示,即可进行物体识别和分割操作。例如在图片处理中,用户可以通过 Hover & Click 或 Box 等方式来选取物体。值得一提的是,SAM 还支持通过上传自己的图片进行物体分割操作,提取物体用时仅需数秒。
总的来说,Meta AI 的 Segment Anything 模型为我们提供了一种全新的物体识别和分割方式,其强大的泛化能力和广泛的应用前景将极大地推动计算机视觉领域的发展。未来,我们期待看到更多基于 Segment Anything 的创新应用,以及在科学图像分析、照片编辑等领域的广泛应用。

2 安装教程
2.1 Web端使用
Segment Anything的官网提供了Demo可以在Web端直接对他的数据集或者自己上传的图片进行分割。我这里就不过多演示了,官网的英文很简单,应该都可以看懂,下面是效果图。
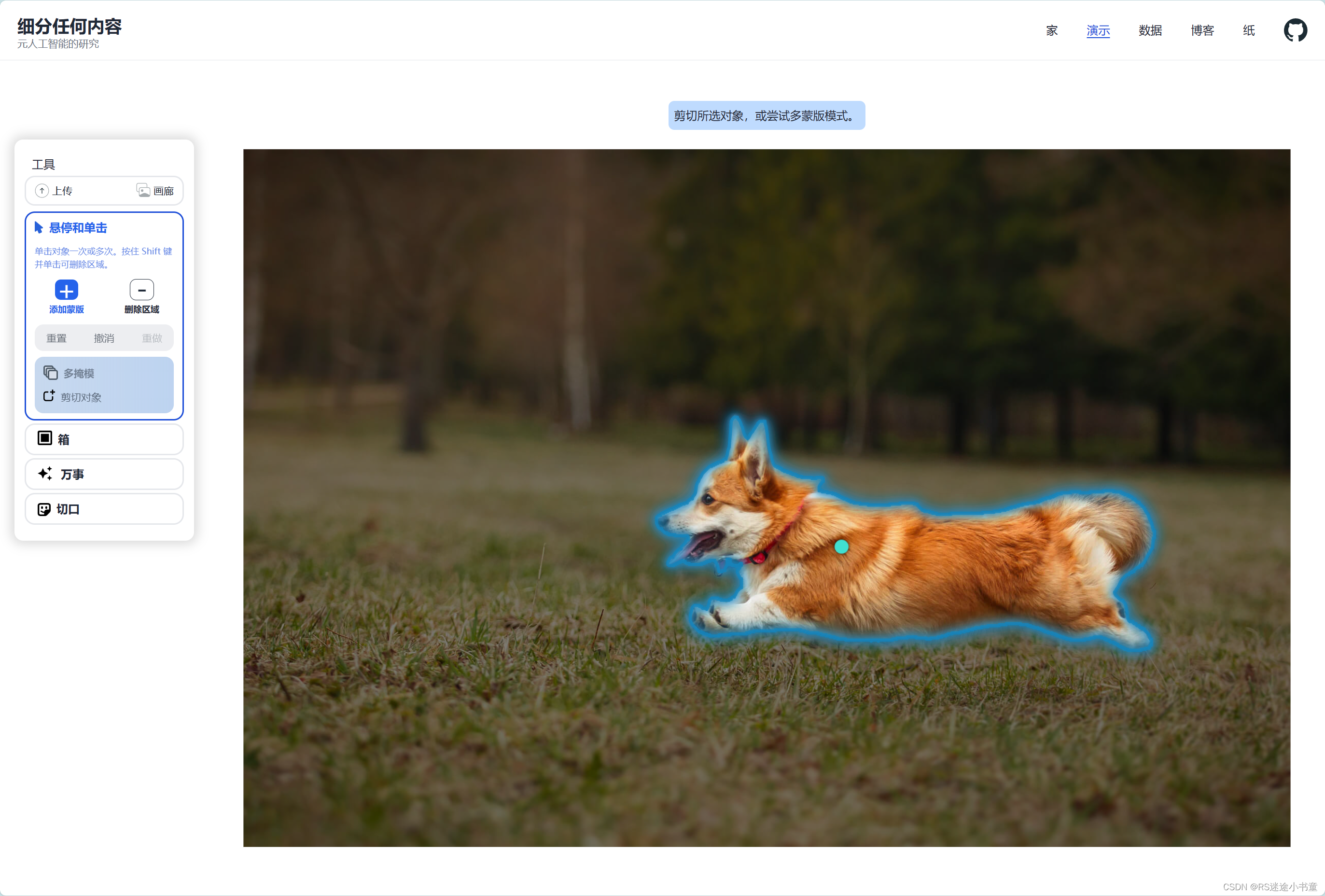
2.2 本地端使用(Python)
该代码要求使用 python>=3.8,并且需要安装 pytorch>=1.7 和torchvision>=0.8。按照以下说明安装 PyTorch 和 TorchVision 的依赖项。建议同时安装支持 CUDA 的 PyTorch 和 TorchVision。项目地址:Segment Anything
2.2.1 git安装
pip install git+https://github.com/facebookresearch/segment-anything.git
该项目依赖opencv-python pycocotools matplotlib onnxruntime onnx torch等包。
pip install opencv-python pycocotools matplotlib onnxruntime onnx torch2.2.2 本地安装
个人认为本地安装是最简单的,我之前已经下载好了项目源码,大家直接在命令行里使用pip install 安装zip文件即可,链接中还包含了三个模型。由于我之前做目标识别时就已经安装了Pytorch所以这里就没有介绍Pytorch怎么安装,后续更新相关安装教程。
- C:\Users\JY03>cd /d G:\Neat Download Manager\Compressed
-
- G:\Neat Download Manager\Compressed>pip install segment-anything-main.zip
3 使用教程
3.1 官方demo教程
下载好官方的项目源码后,在notebooks文件夹中有三个demo文件,大家可以自己阅读观看,不过是.ipynb文件啊需要Jupyter打开,Pycharm打不开这种文件。
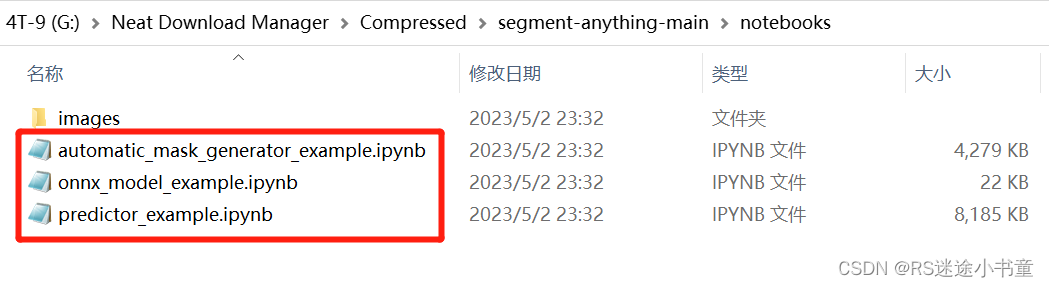
3.2 单点分割示例代码
我这里给大家提供一下最简单的单点分割代码,大家可以做做实验,后续会详细更新其使用教程的。代码中只需要修改图片路径和模型路径即可。模型大家可以在上面的2.2.2小节中下载。
- # -*- coding: utf-8 -*-
- """
- @Time : 2023/10/10 11:10
- @Auth : RS迷途小书童
- @File :SAM.py
- @IDE :PyCharm
- """
- import numpy as np
- import torch
- import matplotlib.pyplot as plt
- import cv2
- import sys
- from segment_anything import sam_model_registry, SamPredictor
-
-
- def show_mask(mask, ax, random_color=False):
- if random_color:
- color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
- else:
- color = np.array([30 / 255, 144 / 255, 255 / 255, 0.6])
- h, w = mask.shape[-2:]
- mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
- ax.imshow(mask_image)
-
-
- def show_points(coords, labels, ax, marker_size=375):
- pos_points = coords[labels == 1]
- neg_points = coords[labels == 0]
- ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white',
- linewidth=1.25)
- ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white',
- linewidth=1.25)
-
-
- def show_box(box, ax):
- x0, y0 = box[0], box[1]
- w, h = box[2] - box[0], box[3] - box[1]
- ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0, 0, 0, 0), lw=2))
-
-
- image = cv2.imread(r'G:\Neat Download Manager\Compressed\segment-anything-main\notebooks\images/truck.jpg')
- # 图片地址
- image = cv2.resize(image, None, fx=0.5, fy=0.5)
- image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
- plt.figure(figsize=(10, 10))
- plt.imshow(image)
- plt.axis('on')
- plt.show()
- sys.path.append("..")
- sam_checkpoint = "G:/Neat Download Manager/Misc/sam_vit_b_01ec64.pth"
- # 定义模型路径
- model_type = "vit_b"
- device = "cuda"
- sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
- sam.to(device=device)
- predictor = SamPredictor(sam)
- predictor.set_image(image)
- input_point = np.array([[250, 187]])
- # 输入兴趣点
- input_label = np.array([1])
- plt.figure(figsize=(10, 10))
- plt.imshow(image)
- show_points(input_point, input_label, plt.gca())
- plt.axis('on')
- plt.show()
- masks, scores, logits = predictor.predict(
- point_coords=input_point,
- point_labels=input_label,
- multimask_output=True,
- )
-
- print(masks.shape) # (number_of_masks) x H x W | output (3, 600, 900)
- for i, (mask, score) in enumerate(zip(masks, scores)):
- plt.figure(figsize=(10, 10))
- plt.imshow(image)
- show_mask(mask, plt.gca())
- show_points(input_point, input_label, plt.gca())
- plt.title(f"Mask {i+1}, Score: {score:.3f}", fontsize=18)
- plt.axis('off')
- plt.show()
4 总结
不得不说,国外程序员的创造力是真的牛,这些算法不仅功能强大最重要的是源码还是开源的,我们任重而道远啊。总的来说,Segment Anything这个模型还是很不错的,图片的分割效果非常好,真的可以做到分割万物。同时其前景也非常可观,我看现在已经有人使用SAM这个模型做了二开实现了样本的自动化标注,这对于我们在标记深度学习样本时有很大的帮助,还有很多领域都可以和SAM相契合,大家感兴趣可以自己去了解。

