
- 1Navicat实现 MYSQL数据库备份图文教程_navicat备份数据库
- 2【FPGA】用Verilog语言实现呼吸灯实验_fpga呼吸灯verilog
- 3Spring Boot打jar包趟过的坑_awd 修复jar
- 4Python爬虫实战(四):利用代理IP爬取某瓣电影排行榜并写入Excel(附上完整源码)_ip代理
- 5Stable Diffusion_为啥尺寸会影响生图是否畸形?
- 6分布式锁全面总结_分布式锁机制
- 7CSS中的动画效果
- 82024抖音矩阵云混剪系统源码 短视频矩阵营销系统_2024抖音矩阵云混剪系统 源码短视频矩阵营销系统
- 9测试用例编写_用例编号怎么写
- 10根本上解决mysql启动失败问题Job for mysqld.service failed because the control process exited with error code_job for dmservicedmserver.service failed because t
豆瓣评分预测(如何用自己的数据集进行文本分类)——基于pytorch的 BERT中文文本分类,超详细教程必会(1)_中文文本分类数据
赞
踩
1.加载数据
由于豆瓣数据为DMSC.csv格式,所以我们通过pd.read_csv函数读取数据,该函数是用来读取csv格式的文件,将表格数据转化成dataframe格式。
#读取数据
data = pd.read_csv('DMSC.csv')
#观察数据格式
data.head()
#输出数据的一些相关信息
data.info()
#只保留数据中我们需要的两列:Comment列和Star列
data = data[['Comment','Star']]
#观察新的数据的格式
data.head()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
输出结果:
| Comment | Star | |
|---|---|---|
| 0 | 连奥创都知道整容要去韩国。 | 3 |
| 1 | “一个没有黑暗面的人不值得信任。” 第二部剥去冗长的铺垫,开场即高潮、一直到结束,会有人觉… | 4 |
| 2 | 奥创弱爆了弱爆了弱爆了啊!!!!!! | 2 |
| 3 | 与第一集不同,承上启下,阴郁严肃,但也不会不好看啊,除非本来就不喜欢漫威电影。场面更加宏大… | 4 |
| 4 | 看毕,我激动地对友人说,等等奥创要来毁灭台北怎么办厚,她拍了拍我肩膀,没事,反正你买了两份… | 5 |
2. 文本预处理
由于一开始送训练数据进入BERT时,提示出现空白字符无法转换以及label标签范围不符合的问题,所以再一次将数据进行预处理,将空白去除以及标签为评分减一。
def clear_character(sentence):
new_sentence=''.join(sentence.split()) #去除空白
return new_sentence
data["comment_processed"]=data['Comment'].apply(clear_character)
data['label']=data['Star']-1
data.head()
- 1
- 2
- 3
- 4
- 5
- 6
输出结果:
| Comment | Star | comment_processed | label | |
|---|---|---|---|---|
| 0 | 连奥创都知道整容要去韩国。 | 3 | 连奥创都知道整容要去韩国。 | 2 |
| 1 | “一个没有黑暗面的人不值得信任。” 第二部剥去冗长的铺垫,开场即高潮、一直到结束,会有人觉… | 4 | “一个没有黑暗面的人不值得信任。”第二部剥去冗长的铺垫,开场即高潮、一直到结束,会有人觉得只… | 3 |
| 2 | 奥创弱爆了弱爆了弱爆了啊!!!!!! | 2 | 奥创弱爆了弱爆了弱爆了啊!!!!!! | 1 |
| 3 | 与第一集不同,承上启下,阴郁严肃,但也不会不好看啊,除非本来就不喜欢漫威电影。场面更加宏大… | 4 | 与第一集不同,承上启下,阴郁严肃,但也不会不好看啊,除非本来就不喜欢漫威电影。场面更加宏大,… | 3 |
| 4 | 看毕,我激动地对友人说,等等奥创要来毁灭台北怎么办厚,她拍了拍我肩膀,没事,反正你买了两份… | 5 | 看毕,我激动地对友人说,等等奥创要来毁灭台北怎么办厚,她拍了拍我肩膀,没事,反正你买了两份旅… | 4 |
3.划分训练集和测试集
通过train_test_split()函数进行数据集的划分。
from sklearn.model_selection import train_test_split
X = data[['comment_processed','label']]
test_ratio = 0.2
comments_train, comments_test = train_test_split(X,test_size=test_ratio, random_state=0)
print(comments_train.head(),comments_test.head)
- 1
- 2
- 3
- 4
- 5
4.保存txt格式
由于BERT里面的存储格式为txt以及文本加标签,所以通过dataframe.to_csv函数存储。
comments_train.to_csv('train.txt', sep='\t', index=False,header=False)
comments_test.to_csv('test.txt', sep='\t', index=False,header=False)
- 1
- 2
输出结果:

三、BERT模型
1. 特征转换
在run.py中先将保存好的训练数据、测试数据、验证数据转化为BERT向量。
print("Loading data...")
train_data, dev_data, test_data = build_dataset(config)
train_iter = build_iterator(train_data, config)
dev_iter = build_iterator(dev_data, config)
test_iter = build_iterator(test_data, config)
time_dif = get_time_dif(start_time)
print("Time usage:", time_dif)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
def load_dataset(path, pad_size=32): contents = [] with open(path, 'r', encoding='UTF-8') as f: # 读取数据 for line in tqdm(f): lin = line.strip() if not lin: continue if len(lin.split('\t')) == 2: content, label = lin.split('\t') token = config.tokenizer.tokenize(content) # 分词 token = [CLS] + token # 句首加入CLS seq_len = len(token) mask = [] token_ids = config.tokenizer.convert_tokens_to_ids(token) if pad_size: if len(token) < pad_size: mask = [1] * len(token_ids) + [0] * (pad_size - len(token)) token_ids += ([0] * (pad_size - len(token))) else: mask = [1] * pad_size token_ids = token_ids[:pad_size] seq_len = pad_size contents.append((token_ids, int(label), seq_len, mask)) return contents

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
调用tokenizer,使用tokenizer分割输入,将数据转换为特征。
特征中包含4个数据:
- **tokens_ids:**分词后每个词语在vocabulary中的id,补全符号对应的id为0,[CLS]和[SEP]的id分别为101和102。应注意的是,在中文BERT模型中,中文分词是基于字而非词的分词。
- **mask:**真实字符/补全字符标识符,真实文本的每个字对应1,补全符号对应0,[CLS]和[SEP]也为1。
- seq_len:句子长度
- label:将label_list中的元素利用字典转换为index标识。
转换特征中一个元素的例子是:
**输入:**剧情有的承接欠缺,画面人设很棒。 3
tokens_ids:[101, 1196, 2658, 3300, 4638, 2824, 2970, 3612, 5375, 8024, 4514, 7481, 782, 6392, 2523, 3472, 511, 0,…,0]
mask:[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…,0]
**label:**3
**seq_len:**17
2.模型训练
完成读取数据、特征转换之后,将特征送入模型进行训练。
训练算法为BERT专用的Adam算法
训练集、测试集、验证集比例为6:2:2
每100轮会在验证集上进行验证,并给出相应的准确值,如果准确值大于此前最高分则保存模型参数,否则flags加1。如果flags大于1000,也即连续1000轮模型的性能都没有继续优化,停止训练过程。
for epoch in range(config.num_epochs): print('Epoch [{}/{}]'.format(epoch + 1, config.num_epochs)) for i, (trains, labels) in enumerate(train_iter): outputs = model(trains) model.zero_grad() loss = F.cross_entropy(outputs, labels) loss.backward() optimizer.step() if total_batch % 100 == 0: # 每多少轮输出在训练集和验证集上的效果 true = labels.data.cpu() predic = torch.max(outputs.data, 1)[1].cpu() train_acc = metrics.accuracy_score(true, predic) dev_acc, dev_loss = evaluate(config, model, dev_iter) if dev_loss < dev_best_loss: dev_best_loss = dev_loss torch.save(model.state_dict(), config.save_path) improve = '*' last_improve = total_batch else: improve = '' time_dif = get_time_dif(start_time) msg = 'Iter: {0:>6}, Train Loss: {1:>5.2}, Train Acc: {2:>6.2%}, Val Loss: {3:>5.2}, Val Acc: {4:>6.2%}, Time: {5} {6}' print(msg.format(total_batch, loss.item(), train_acc, dev_loss, dev_acc, time_dif, improve)) model.train() total_batch += 1 if total_batch - last_improve > config.require_improvement: # 验证集loss超过1000batch没下降,结束训练 print("No optimization for a long time, auto-stopping...") flag = True break if flag: break test(config, model, test_iter)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
训练结果:
1245it [00:00, 6290.83it/s]Loading data... 170004it [00:28, 6068.60it/s] 42502it [00:07, 6017.43it/s] 42502it [00:06, 6228.82it/s] Time usage: 0:00:42 Epoch [1/5] Iter: 0, Train Loss: 1.8, Train Acc: 3.12%, Val Loss: 1.7, Val Acc: 9.60%, Time: 0:02:14 * Iter: 100, Train Loss: 1.5, Train Acc: 25.00%, Val Loss: 1.4, Val Acc: 20.60%, Time: 0:05:10 * ... Iter: 5300, Train Loss: 0.75, Train Acc: 65.62%, Val Loss: 1.0, Val Acc: 50.07%, Time: 2:45:41 * Epoch [2/5] Iter: 5400, Train Loss: 1.0, Train Acc: 62.50%, Val Loss: 1.0, Val Acc: 51.02%, Time: 2:48:46 ... Iter: 7000, Train Loss: 0.77, Train Acc: 75.00%, Val Loss: 1.0, Val Acc: 52.84%, Time: 3:38:26 No optimization for a long time, auto-stopping... Test Loss: 1.0, Test Acc: 50.89% Precision, Recall and F1-Score... precision recall f1-score support 1 0.6157 0.5901 0.6026 3706 2 0.5594 0.1481 0.2342 3532 3 0.4937 0.5883 0.5369 9678 4 0.4903 0.5459 0.5166 12899 5 0.6693 0.6394 0.6540 12687 accuracy 0.5543 42502 macro avg 0.5657 0.5024 0.5089 42502 weighted avg 0.5612 0.5543 0.5463 42502 Time usage: 0:02:25
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
从训练结果可以看出准确率和F1分数最多只能达到60%,其实仔细分析评论也可以知道原因:
相近分数的差异性与评论相关性不大,比如两分的评论可能有时候与一分三分是一样的,这就导致很难根据评论准确的预测出分数,但是从测试结果可以明显的看出好评和差评能够明显区分出来,准确率能达到百分之九十。
3.模型测试
测试的时候与训练同样的原理,也是先将数据转化为特征,送入训练好的模型中,得到结果。
def final_predict(config, model, data_iter): map_location = lambda storage, loc: storage model.load_state_dict(torch.load(config.save_path, map_location=map_location)) model.eval() predict_all = np.array([]) with torch.no_grad(): for texts, _ in data_iter: outputs = model(texts) ### 一、网安学习成长路线图 网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。 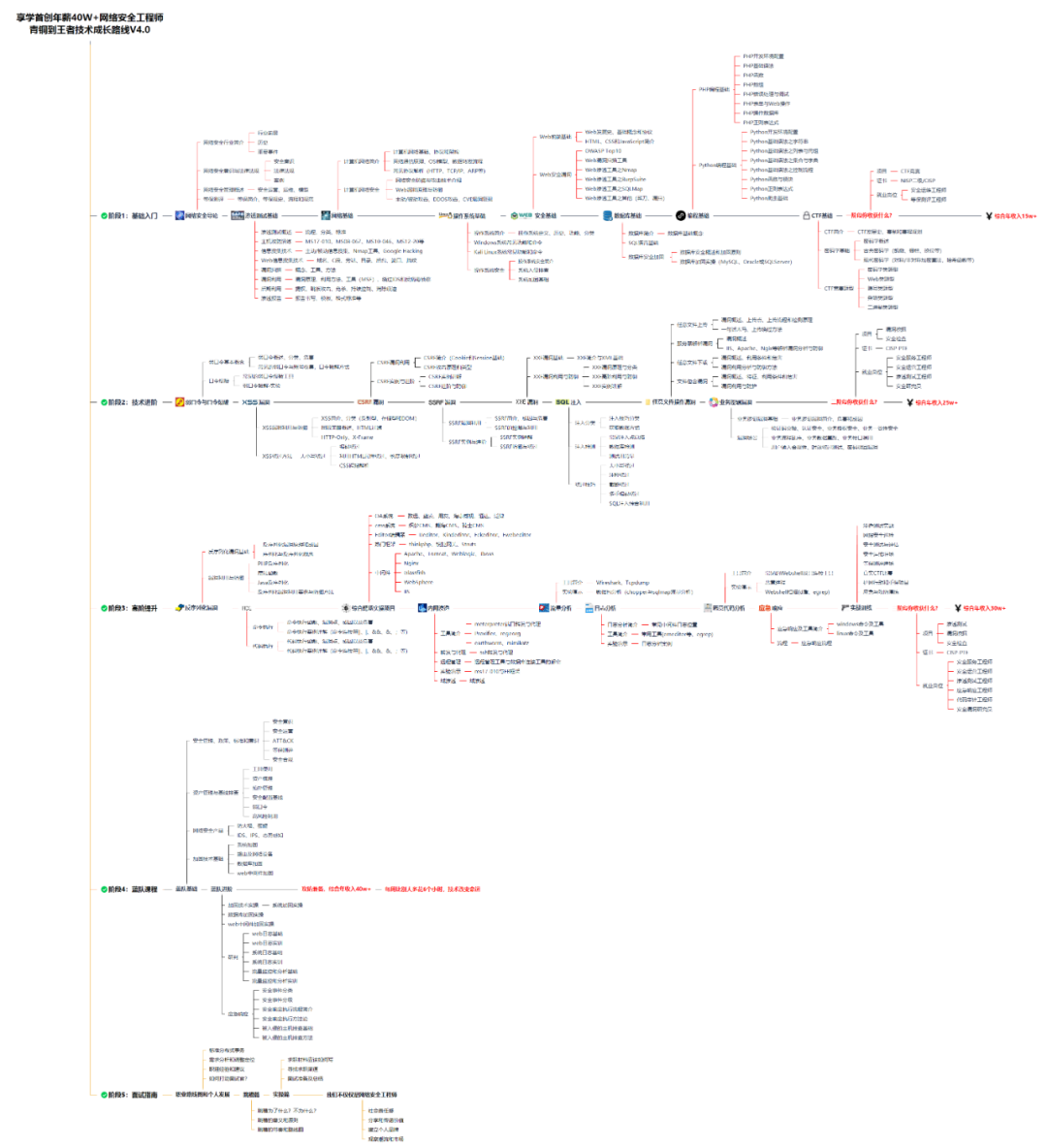 ### 二、网安视频合集 观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。 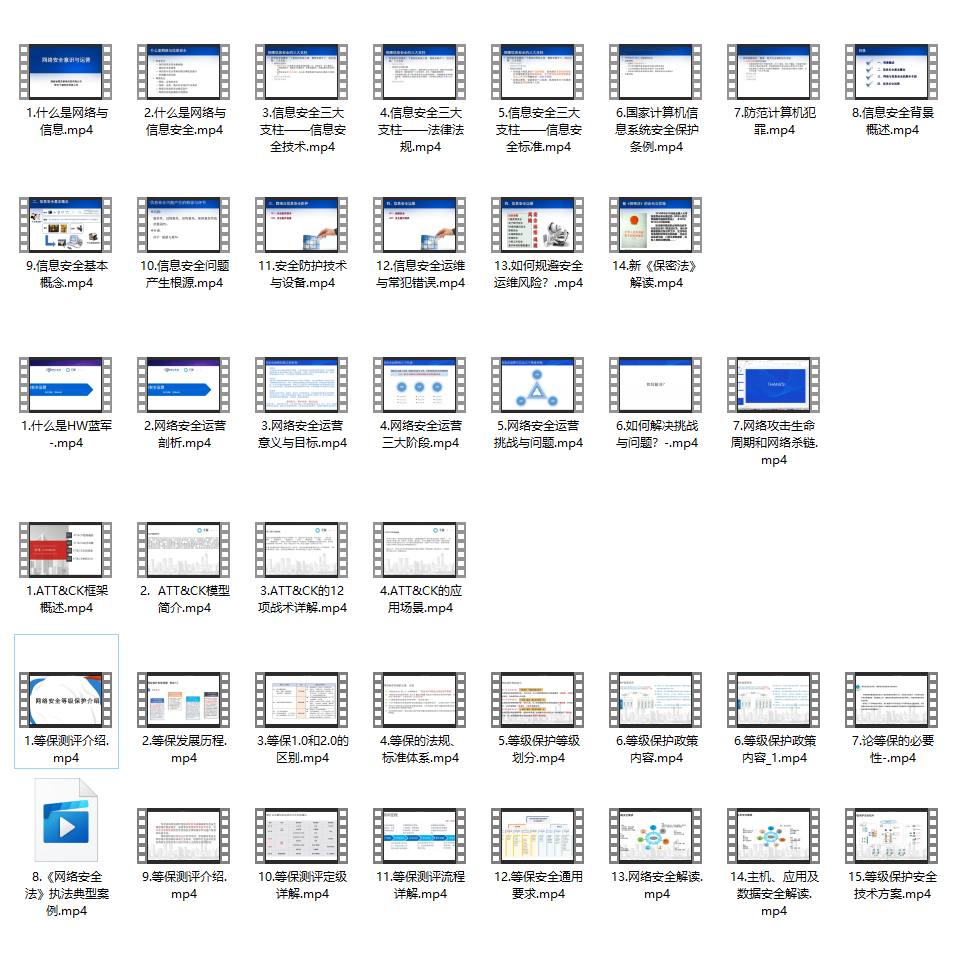 ### 三、精品网安学习书籍 当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。 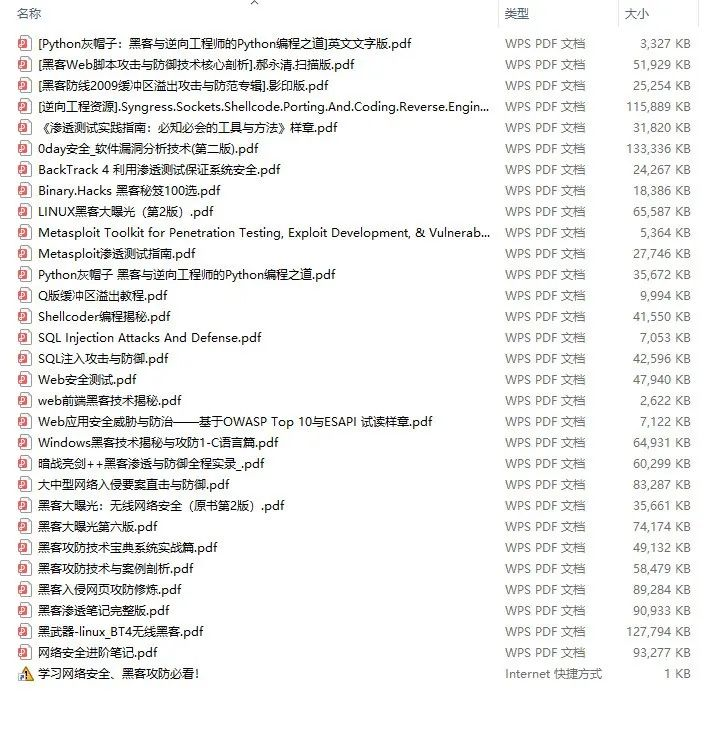 ### 四、网络安全源码合集+工具包 光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。  ### 五、网络安全面试题 最后就是大家最关心的网络安全面试题板块 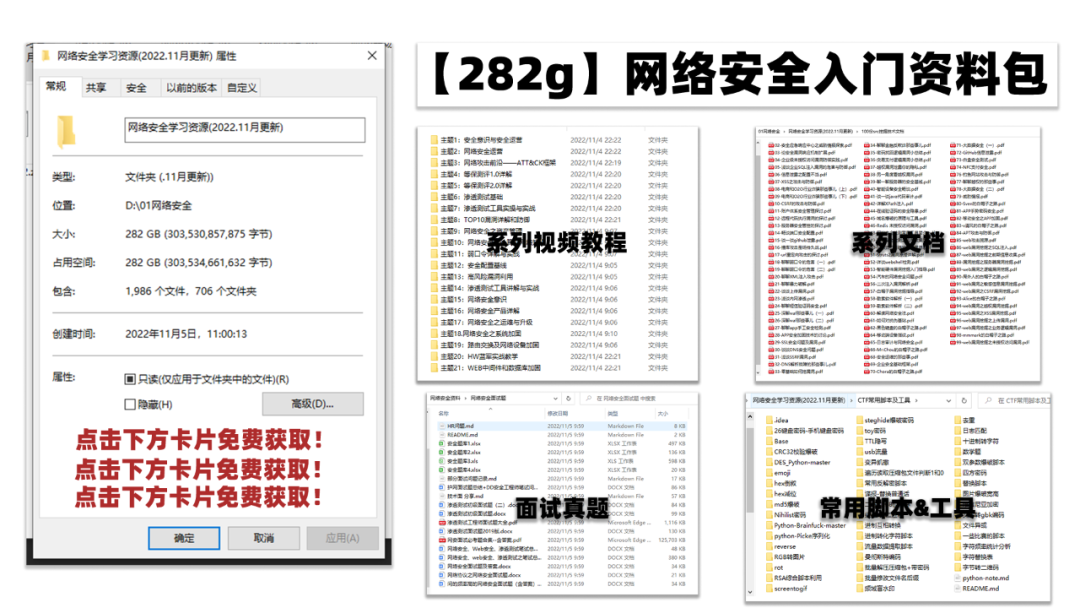 **网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。** **[需要这份系统化资料的朋友,可以点击这里获取](https://bbs.csdn.net/topics/618540462)** **一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53

