
- 1jdbc连接常用url格式_jdbc url格式
- 2验证性因子分析_result (default model) the model is probably unide
- 3OpenLayers 3地图添加图标_openlayers添加图标
- 4【读点论文】生成对抗网络 GAN_对抗生成网络 判别器的准确率
- 5Android Studio各种Gradle常见报错问题及解决方案_检查项目的build.gradle文件中的dependencies版本号,并确保它们与android
- 6google 隐私权政策_如何阻止不断出现的Google隐私权提醒消息?
- 7火车头采集软件如何批量伪原创(火影智能AI文章伪原创)_火车头+ai打造属于你的原创内容
- 8CoreText高级应用——富文本、按钮、输入框的混编_ios好用的富文本编辑器支持@#
- 9【文末附gpt升级秘笈】Suno全新功能在音乐创作领域的应用与影响
- 10Python爬虫:浏览器模拟登录_通过浏览器模拟登录,使得爬虫程序具有爬取权限
利用Lora调整和部署 LLM_llm lora
赞
踩
使用 NVIDIA TensorRT-LLM 调整和部署 LoRA LLM

大型语言模型 (LLM) 能够从大量文本中学习并为各种任务和领域生成流畅且连贯的文本,从而彻底改变了自然语言处理 (NLP)。 然而,定制LLM是一项具有挑战性的任务,通常需要完整的培训过程,该过程非常耗时且计算成本高昂。 此外,训练LLM需要多样化且具有代表性的数据集,而这些数据集可能很难获取和管理。
企业如何在不支付全面培训费用的情况下利用LLM的力量? 一个有前途的解决方案是低秩适应(LoRA),这是一种微调方法,可以显着减少可训练参数的数量、内存需求和训练时间,同时实现与各种 NLP 微调相当甚至更好的性能 任务和领域。
这篇文章解释了 LoRA 的直觉和实现,并展示了它的一些应用和优点。 它还将 LoRA 与监督微调和即时工程进行了比较,并讨论了它们的优点和局限性。 它概述了 LoRA 调整模型的训练和推理的实用指南。 最后,它演示了如何使用 NVIDIA TensorRT-LLM 优化 LoRA 模型在 NVIDIA GPU 上的部署。
教程先决条件
为了充分利用本教程,您将需要 LLM 训练和推理流程的基本知识,以及:
- 线性代数基础知识
- Hugging Face 注册用户访问权限以及对 Transformers 库的总体熟悉程度
- NVIDIA/TensorRT-LLM优化库
- 具有 TensorRT-LLM 后端的 NVIDIA Triton 推理服务器
什么是LoRA?
LoRA是一种微调方法,它将低秩矩阵引入到LLM架构的每一层中,并且仅训练这些矩阵,同时保持原始LLM权重冻结。 它是 NVIDIA NeMo 支持的 LLM 定制工具之一。
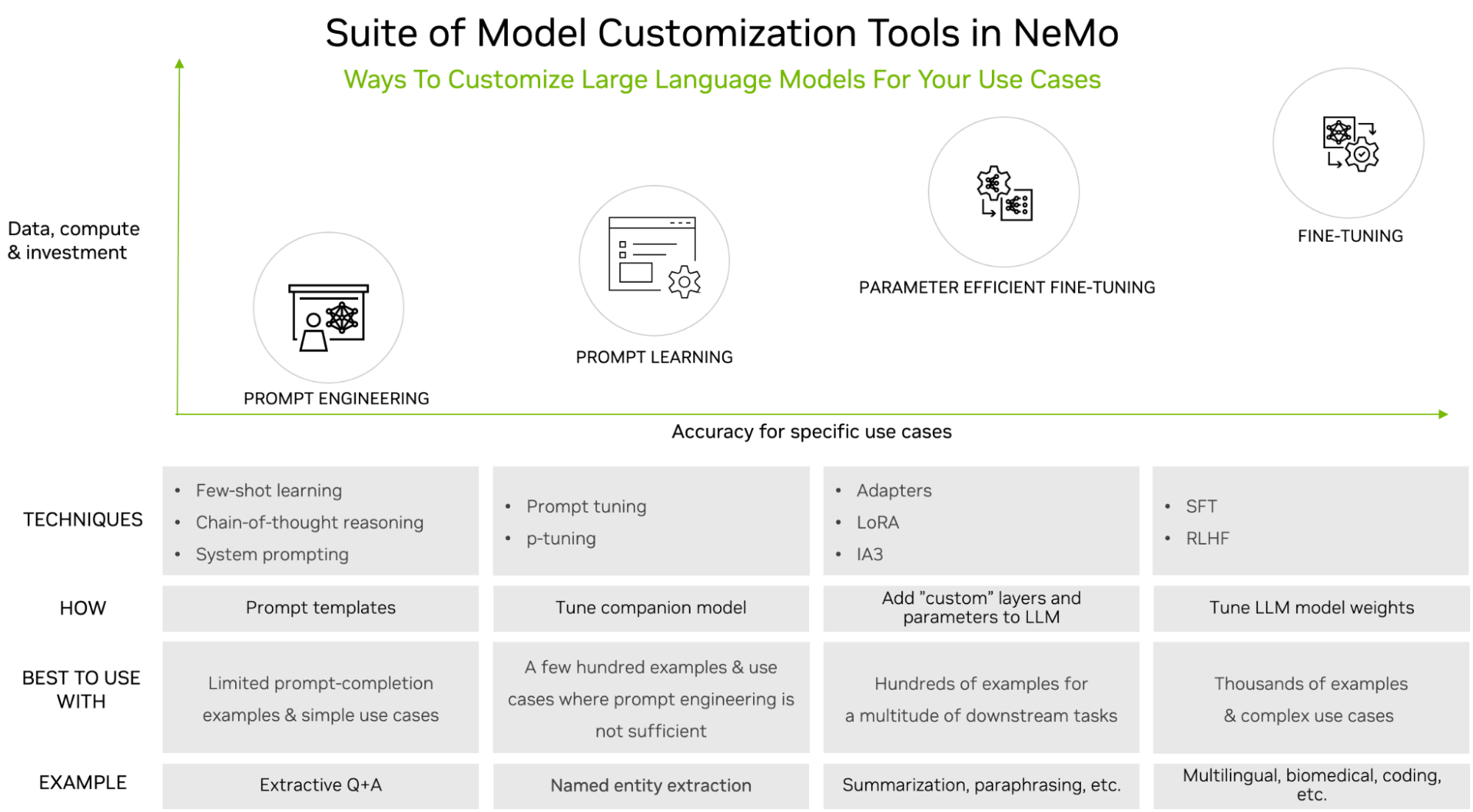
LLM 功能强大,但通常需要定制,尤其是在用于企业或特定领域的用例时。 有许多调整选项,从简单的提示工程到监督微调 (SFT)。 调整选项的选择通常基于所需数据集的大小(即时工程的最小值,SFT 的最大值)和计算可用性。
LoRA 调优是一种称为参数高效微调 (PEFT) 的调优系列。 这些技术是一种中间方法。 与即时工程相比,它们需要更多的训练数据和计算,但也能产生更高的准确性。 共同的主题是他们引入少量参数或层,同时保持原始 LLM 不变。
PEFT 已被证明可以在使用更少的数据和计算资源的情况下实现与 SFT 相当的精度。 与其他调优技术相比,LoRA 有几个优点。 它减少了计算和内存成本,因为它只添加了一些新参数,但不添加任何层。 它支持多任务学习,通过按需部署相关的微调 LoRA 变体,允许将单基 LLM 用于不同的任务,仅在需要时加载其低秩矩阵。
最后,它避免了灾难性遗忘,即LLM在学习新数据时突然忘记以前学到的信息的自然倾向。 从数量上讲,LoRA 的性能优于使用其他调优技术(例如提示调优和适配器)的模型,如《LoRA:大型语言模型的低阶适应》中所示。
LoRA 背后的数学原理
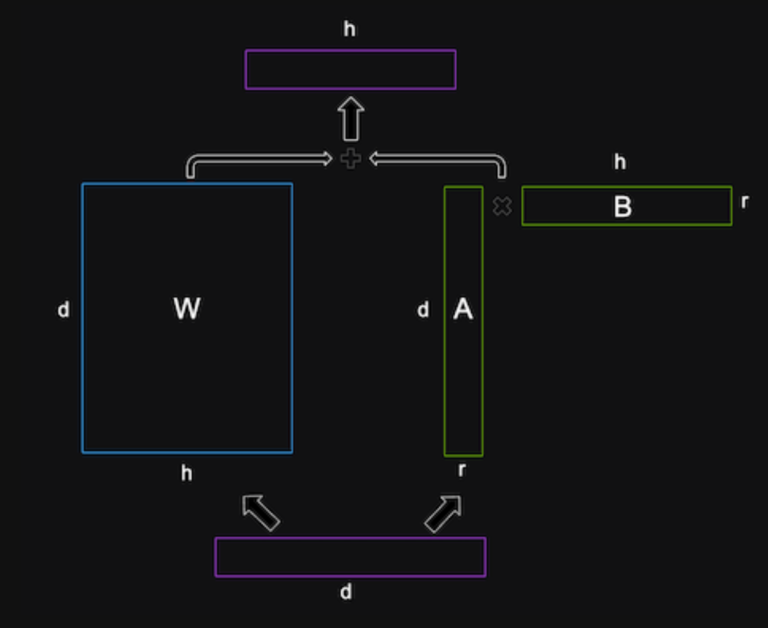
LoRA 背后的数学基于低秩分解的思想,这是一种通过两个较低秩的较小矩阵的乘积来近似矩阵的方法。 矩阵的秩是矩阵中线性独立的行或列的数量。 低秩矩阵具有较少的自由度,并且可以比满秩矩阵更紧凑地表示。
LoRA 对 LLM 的权重矩阵应用低秩分解,这些矩阵通常非常大且密集。 例如,如果 LLM 的隐藏大小为 1,024,词汇大小为 50,000,则输出权重矩阵 W 将具有 1024 x 50,000 = 51,200,000 个参数。
LoRA 将此矩阵 W 分解为两个较小的矩阵,即形状为 1024 x r 的矩阵 A 和形状为 r x 50,000 的矩阵 B,其中 r 是控制分解秩的超参数。 这两个矩阵的乘积将具有与原始矩阵相同的形状,但只有 1024 x r + r x 50,000 = 51,200,000 – 50,000 x (1024 – r) 参数。
超参数 r 对于正确设置至关重要。 选择较小的r可以节省大量参数和内存,实现更快的训练。 然而,较小的 r 可能会减少低秩矩阵中捕获的特定于任务的信息。 较大的 r 可能会导致过度拟合。 因此,为了实现特定任务和数据的理想精度与性能权衡,进行实验非常重要。
LoRA将这些低秩矩阵插入到LLM的每一层中,并将它们添加到原始权重矩阵中。 原始权重矩阵使用预训练的 LLM 权重进行初始化,并且在训练期间不会更新。 低秩矩阵是随机初始化的,并且是训练期间唯一更新的参数。 LoRA 还将层归一化应用于原始矩阵和低秩矩阵的总和以稳定训练。
多LoRA部署
部署LLM的一大挑战是如何有效地服务数百或数千个调优模型。 例如,单一基础 LLM(例如 Llama 2)可能针对每种语言或区域设置有许多经过 LoRA 调整的变体。 标准系统需要独立加载所有模型,占用大量内存容量。 利用 LoRA 的设计,通过加载单个基本模型以及每个相应 LoRA 调整变体的低秩矩阵 A 和 B,捕获每个模型较小的低秩矩阵中的所有信息。 通过这种方式,可以存储数千个 LLM 并在最小的 GPU 内存占用范围内动态、高效地运行它们。
LoRA调优
LoRA 调优需要准备特定格式的训练数据集,通常使用提示模板。 在形成提示时,您应该确定并遵循一种模式,该模式自然会因不同的用例而异。 下面显示了问题和答案的示例。
{
"taskname": "squad",
"prompt_template": "<|VIRTUAL_PROMPT_0|> Context: {context}\n\nQuestion: {question}\n\nAnswer:{answer}",
"total_virtual_tokens": 10,
"virtual_token_splits": [10],
"truncate_field": "context",
"answer_only_loss": True,
"answer_field": "answer",
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
提示包含开头的所有 10 个虚拟标记,然后是上下文、问题,最后是答案。 训练数据JSON对象中的相应字段将映射到该提示模板,形成完整的训练示例。
有几个可用的平台可用于定制LLM。 您可以使用 NVIDIA NeMo 或 Hugging Face PEFT 等工具。 有关如何使用 NeMo 在 PubMed 数据集上调整 LoRA 的示例,请参阅 NeMo Framework PEFT with Llama 2。
请注意,这篇文章使用来自 Hugging Face 的已调优的 LLM,因此无需进行调优。
LoRA推理
要使用 TensorRT-LLM 优化 LoRA 调整的 LLM,您必须了解其架构并确定它最接近的通用基础架构。 本教程使用 Llama 2 13B 和 Llama 2 7B 作为基本模型,以及 Hugging Face 上提供的几个经过 LoRA 调整的变体。
第一步是使用该目录中的转换器和构建脚本来编译所有模型并为硬件加速做好准备。 然后,我将展示使用命令行和 Triton 推理服务器进行部署的示例。
请注意,分词器不是由 TensorRT-LLM 直接处理的。 但有必要能够将其分类到定义的分词器系列中,以供运行时以及在 Triton 中设置预处理和后处理步骤。
设置和构建 TensorRT-LLM
首先克隆并构建 NVIDIA/TensorRT-LLM 库。 构建 TensorRT-LLM 并检索其所有依赖项的最简单方法是使用附带的 Dockerfile。 这些命令拉取基础容器并在容器内安装 TensorRT-LLM 所需的所有依赖项。 然后它会在容器中构建并安装 TensorRT-LLM 本身。
git lfs install
git clone https://github.com/NVIDIA/TensorRT-LLM.git
cd TensorRT-LLM
git submodule update --init --recursive
make -C docker release_build
- 1
- 2
- 3
- 4
- 5
检索模型权重
从 Hugging Face 下载基础模型和 LoRA 模型:
git-lfs clone https://huggingface.co/meta-llama/Llama-2-13b-hf
git-lfs clone https://huggingface.co/hfl/chinese-llama-2-lora-13b
- 1
- 2
编译模型
构建引擎,设置 --use_lora_plugin 和 --hf_lora_dir。 如果 LoRA 有单独的 lm_head 和嵌入,它们将替换基础模型的 lm_head 和嵌入。
python convert_checkpoint.py --model_dir /tmp/llama-v2-13b-hf \
--output_dir ./tllm_checkpoint_2gpu_lora \
--dtype float16 \
--tp_size 2 \
--hf_lora_dir /tmp/chinese-llama-2-lora-13b
trtllm-build --checkpoint_dir ./tllm_checkpoint_2gpu_lora \
--output_dir /tmp/new_lora_13b/trt_engines/fp16/2-gpu/ \
--gpt_attention_plugin float16 \
--gemm_plugin float16 \
--lora_plugin float16 \
--max_batch_size 1 \
--max_input_len 512 \
--max_output_len 50 \
--use_fused_mlp
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
运行模型
要在推理期间运行模型,请设置 lora_dir 命令行参数。 请记住使用 LoRA 分词器,因为经过 LoRA 调整的模型具有更大的词汇量。
mpirun -n 2 python ../run.py --engine_dir "/tmp/new_lora_13b/trt_engines/fp16/2-gpu/" \
--max_output_len 50 \
--tokenizer_dir "chinese-llama-2-lora-13b/" \
--input_text "今天天气很好,我到公园的时后," \
--lora_dir "chinese-llama-2-lora-13b/" \
--lora_task_uids 0 \
--no_add_special_tokens \
--use_py_session
Input: "今天天气很好,我到公园的时后,"
Output: "发现公园里人很多,有的在打羽毛球,有的在打乒乓球,有的在跳绳,还有的在跑步。我和妈妈来到一个空地上,我和妈妈一起跳绳,我跳了1"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
您可以运行消融测试来直接查看 LoRA 调整模型的贡献。 要轻松比较使用和不使用 LoRa 的结果,只需使用 --lora_task_uids -1 将 UID 设置为 -1。 在这种情况下,模型将忽略 LoRA 模块,结果将仅基于基本模型。
mpirun -n 2 python ../run.py --engine_dir "/tmp/new_lora_13b/trt_engines/fp16/2-gpu/" \
--max_output_len 50 \
--tokenizer_dir "chinese-llama-2-lora-13b/" \
--input_text "今天天气很好,我到公园的时后," \
--lora_dir "chinese-llama-2-lora-13b/" \
--lora_task_uids -1 \
--no_add_special_tokens \
--use_py_session
Input: "今天天气很好,我到公园的时后,"
Output: "我看见一个人坐在那边边看书书,我看起来还挺像你,可是我走过过去问了一下他说你是你吗,他说没有,然后我就说你看我看看你像你,他说说你看我像你,我说你是你,他说你是你,"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
使用多个 LoRA 调整模型运行基本模型
TensorRT-LLM 还支持同时运行具有多个 LoRA 调整模块的单个基本模型。 这里,我们以两个 LoRA 检查点为例。 由于两个检查点的LoRA模块的rank r都是8,因此您可以将–max_lora_rank设置为8,以减少LoRA插件的内存需求。
此示例使用在中国数据集 luotuo-lora-7b-0.1 上微调的 LoRA 检查点和在日本数据集 Japanese-Alpaca-LoRA-7b-v0 上微调的 LoRA 检查点。 为了让 TensorRT-LLM 加载多个检查点,请通过 --lora_dir “luotuo-lora-7b-0.1/” " Japanese-Alpaca-LoRA-7b-v0/" 传入所有 LoRA 检查点的目录。 TensorRT-LLM 会将 lora_task_uids 分配给这些检查点。 lora_task_uids -1 是预定义值,对应于基础模型。 例如,传递 lora_task_uids 0 1 将在第一个句子上使用第一个 LoRA 检查点,在第二个句子上使用第二个 LoRA 检查点。
为了验证正确性,通过同样的中文输入 美国的首都在哪里? \n答案: 三次,还有同样的日文输入メリカ合众国の首都はどこですか? \n答え:三遍。 (在英语中,两个输入的意思是“美国的首都在哪里?\n答案”)。 然后分别在基础模型 luotuo-lora-7b-0.1 和 Japanese-Alpaca-LoRA-7b-v0 上运行:
git-lfs clone https://huggingface.co/qychen/luotuo-lora-7b-0.1
git-lfs clone https://huggingface.co/kunishou/Japanese-Alpaca-LoRA-7b-v0
BASE_LLAMA_MODEL=llama-7b-hf/
python convert_checkpoint.py --model_dir ${BASE_LLAMA_MODEL} \
--output_dir ./tllm_checkpoint_1gpu_lora_rank \
--dtype float16 \
--hf_lora_dir /tmp/Japanese-Alpaca-LoRA-7b-v0 \
--max_lora_rank 8 \
--lora_target_modules "attn_q" "attn_k" "attn_v"
trtllm-build --checkpoint_dir ./tllm_checkpoint_1gpu_lora_rank \
--output_dir /tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/ \
--gpt_attention_plugin float16 \
--gemm_plugin float16 \
--lora_plugin float16 \
--max_batch_size 1 \
--max_input_len 512 \
--max_output_len 50
python ../run.py --engine_dir "/tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/" \
--max_output_len 10 \
--tokenizer_dir ${BASE_LLAMA_MODEL} \
--input_text "美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:" \
--lora_dir "luotuo-lora-7b-0.1/" "Japanese-Alpaca-LoRA-7b-v0/" \
--lora_task_uids -1 0 1 -1 0 1 \
--use_py_session --top_p 0.5 --top_k 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
结果如下所示:
Input [Text 0]: "<s> 美国的首都在哪里? \n答案:"
Output [Text 0 Beam 0]: "Washington, D.C.
What is the"
Input [Text 1]: "<s> 美国的首都在哪里? \n答案:"
Output [Text 1 Beam 0]: "华盛顿。
"
Input [Text 2]: "<s> 美国的首都在哪里? \n答案:"
Output [Text 2 Beam 0]: "Washington D.C.'''''"
Input [Text 3]: "<s> アメリカ合衆国の首都はどこですか? \n答え:"
Output [Text 3 Beam 0]: "Washington, D.C.
Which of"
Input [Text 4]: "<s> アメリカ合衆国の首都はどこですか? \n答え:"
Output [Text 4 Beam 0]: "华盛顿。
"
Input [Text 5]: "<s> アメリカ合衆国の首都はどこですか? \n答え:"
Output [Text 5 Beam 0]: "ワシントン D.C."
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
请注意,luotuo-lora-7b-0.1 对第一句和第五句(中文)产生了正确答案。 Japanese-Alpaca-LoRA-7b-v0 给出第六句的正确答案(日语)。
重要提示:如果其中一个 LoRA 模块包含微调嵌入表或 logit GEMM,则用户必须保证模型的所有实例都可以使用相同的微调嵌入表或 logit GEMM。
使用 Triton 和飞行批处理部署 LoRA 调整模型
本节介绍如何使用 Triton Inference 服务器进行动态批处理来部署经过 LoRA 调整的模型。 有关设置和启动 Triton 推理服务器的具体说明,请参阅使用 NVIDIA TensorRT-LLM 和 NVIDIA Triton 部署 AI 编码助手。
和以前一样,首先编译启用 LoRA 的模型,这次使用基本模型 Llama 2 7B。
BASE_MODEL=llama-7b-hf
python3 tensorrt_llm/examples/llama/build.py --model_dir ${BASE_MODEL} \
--dtype float16 \
--remove_input_padding \
--use_gpt_attention_plugin float16 \
--enable_context_fmha \
--use_gemm_plugin float16 \
--output_dir "/tmp/llama_7b_with_lora_qkv/trt_engines/fp16/1-gpu/" \
--max_batch_size 128 \
--max_input_len 512 \
--max_output_len 50 \
--use_lora_plugin float16 \
--lora_target_modules "attn_q" "attn_k" "attn_v" \
--use_inflight_batching \
--paged_kv_cache \
--max_lora_rank 8 \
--world_size 1 --tp_size 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
接下来,生成将随每个请求传递给 Triton 的 LoRA 张量。
git-lfs clone https://huggingface.co/qychen/luotuo-lora-7b-0.1
git-lfs clone https://huggingface.co/kunishou/Japanese-Alpaca-LoRA-7b-v0
python3 tensorrt_llm/examples/hf_lora_convert.py -i Japanese-Alpaca-LoRA-7b-v0 -o Japanese-Alpaca-LoRA-7b-v0-weights --storage-type float16
python3 tensorrt_llm/examples/hf_lora_convert.py -i luotuo-lora-7b-0.1 -o luotuo-lora-7b-0.1-weights --storage-type float16
- 1
- 2
- 3
- 4
- 5
然后创建一个 Triton 模型存储库并启动 Triton 服务器,如前所述。
最后,通过从客户端发出多个并发请求来运行多 LoRA 示例。 inflight batcher程序将在同一批处理中执行多个 LoRA 的混合批处理。
INPUT_TEXT=("美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "美国的首都在哪里? \n答案:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:" "アメリカ合衆国の首都はどこですか? \n答え:")
LORA_PATHS=("" "luotuo-lora-7b-0.1-weights" "Japanese-Alpaca-LoRA-7b-v0-weights" "" "luotuo-lora-7b-0.1-weights" "Japanese-Alpaca-LoRA-7b-v0-weights")
for index in ${!INPUT_TEXT[@]}; do
text=${INPUT_TEXT[$index]}
lora_path=${LORA_PATHS[$index]}
lora_arg=""
if [ "${lora_path}" != "" ]; then
lora_arg="--lora-path ${lora_path}"
fi
python3 inflight_batcher_llm/client/inflight_batcher_llm_client.py \
--top-k 0 \
--top-p 0.5 \
--request-output-len 10 \
--text "${text}" \
--tokenizer-dir /home/scratch.trt_llm_data/llm-models/llama-models/llama-7b-hf \
${lora_arg} &
done
wait
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
示例输出如下所示:
Input sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]
Input sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]
Input sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]
Input sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]
Input sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901]
Input sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901]
Got completed request
Input: アメリカ合衆国の首都はどこですか? \n答え:
Output beam 0: ワシントン D.C.
Output sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 29871, 31028, 30373, 30203, 30279, 30203, 360, 29889, 29907, 29889]
Got completed request
Input: 美国的首都在哪里? \n答案:
Output beam 0: Washington, D.C.
What is the
Output sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901, 7660, 29892, 360, 29889, 29907, 29889, 13, 5618, 338, 278]
Got completed request
Input: 美国的首都在哪里? \n答案:
Output beam 0: Washington D.C.
Washington D.
Output sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 139, 29901, 7660, 360, 29889, 29907, 29889, 13, 29956, 7321, 360, 29889]
Got completed request
Input: アメリカ合衆国の首都はどこですか? \n答え:
Output beam 0: Washington, D.C.
Which of
Output sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 7660, 29892, 360, 29889, 29907, 29889, 13, 8809, 436, 310]
Got completed request
Input: アメリカ合衆国の首都はどこですか? \n答え:
Output beam 0: Washington D.C.
1. ア
Output sequence: [1, 29871, 30310, 30604, 30303, 30439, 30733, 235, 164, 137, 30356, 30199, 31688, 30769, 30449, 31250, 30589, 30499, 30427, 30412, 29973, 320, 29876, 234, 176, 151, 30914, 29901, 7660, 360, 29889, 29907, 29889, 13, 29896, 29889, 29871, 30310]
Got completed request
Input: 美国的首都在哪里? \n答案:
Output beam 0: 华盛顿
W
Output sequence: [1, 29871, 30630, 30356, 30210, 31688, 30769, 30505, 232, 150, 173, 30755, 29973, 320, 29876, 234, 176, 151, 233, 164, 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36

