
- 1Linux高危命令,运维人手一份_高危指令 操作系统
- 201uni-app 基础教程 环境配置【uniapp 专题 1】_uni-app测试正式配置
- 3博科br310交换机级联
- 4git -- 清除本地分支以及删除远程分支_分支中清除功能是什么意思
- 5「一本通 1.1 例 4」加工生产调度(典型例题,值得一看)_某工厂收到 n 个订单(ai,bi),
- 6智能优化算法:社交网络搜索算法-附代码_社交网络算法
- 74 招搞定 Java List 排序_javalist排序sort降序
- 8Moonshot AI API使用(2)-环境变量配置和简单对话demo_moonshot ai 配置环境变量
- 9MS-SQL Server 基础类 - SQL语句
- 10使用MapReduce进行编程来对数据进行处理和计算_能用平台编写mapreduce 程序并分析该程序的数据处理、map阶段、reduce阶段、迭代
AIGC教程:Stable Diffusion精进,如何训练特定画风LoRA模型?_stable diffusion + lora 训练一个动漫风格模型
赞
踩
(全套教程文末领取哈)
文生图只是AI生成能力的起步,如今,随着同行们的探索增加,很多人已经开始通过Stable Diffusion训练风格化的模型,即将AI变成一个特定画风的画师。
最近,就有一位开发者分享了自己训练风格化LoRA模型的经验和技巧,并且通过本地训练和Google Colab Notebook两种方式展示了方法与结果,让无论是否有强大GPU配置的同行都可以上手。
以下是Gamelook听译的完整内容:

今天要分享的是我在Stable Diffusion和LoRA风格领域的探索,LoRA,即Low-Rank Adaptation,大型语言模型的低阶自适应,它是一种可以将扩散模型带向全新层次的技巧。LoRA最初设计是为了教模型学习新概念,目前为止大多数用来训练角色。
然而,如果你仔细思考,主题和角色都是一种概念,艺术风格也是概念。无论如何,LoRA训练模型的主要优势之一,就是它比Dreambooth模型更小,而且更加模块化。

很多人都用Stable Diffusion训练风格化艺术,我对于LoRA的探索,主要是聚焦在复制或者融合特定的美术风格,如果你对于LoRA背后的理论和数学感兴趣,可以参考这篇论文进行深入研究:https://arxiv.org/abs/2106.09685
对我来说,在深入研究之前,我更喜欢先上手体验,这就是我们今天要做的事情。进入流程之前,首先要确保我们得到了所有需要的东西:你首先需要安装Stable Diffusion的AUTOMATIC1111 webui,加上你计划要训练的具体模型,我想要训练的是Vanilla模型(Stable Diffusion 1.5 ema 以及anything 4.5 pruned模型)。

接下来,你要准备带有说明文字的文本文件(.txt文件),这是训练LoRA模型的一个关键组成部分,所以我会在稍后进一步详细讲解。
最后,你需要一个可以训练LoRA的设备或笔记本,如果没有强大GPU的电脑配置也不用担心,你仍然可以跟上进度。实际上,我会将今天的分享拆解为两部分:对于第一部分,我会使用对用户非常友好的Kohya sd脚本,这里是它的详细介绍(https://github.com/kohya-ss/sd-scripts),你还可以通过创作者的视频了解更多内容。我将在Stable Diffusion 1.5版本训练这个模型。
对于第二部分,我将使用谷歌Colab Notebook作为LoRA训练者,这里,我将使用自己探索的经验训练anything v4.5 pruned模型。
第一部分:Kohya本地GUI训练
如我们之前所说,首先我们会使用对用户比较友好的Kohya的GUI,不要担心,安装过程非常直接,将其复制到你的电脑之后,在命令提示符程序输入“.\gui.ps1”,它就会告诉你本地主机链接(如图)
进入下一步之前,我尽量对自己的硬件和装备做到透明,我的显卡是RTX 3090,显存为24GB,这意味着我不用担心显存开销,可以轻松训练我的LoRA模型。

现在,如果你想要学习我的流程,但又缺乏强大的显卡,这也不会有问题,你可以调整自己的设置来降低模型训练对于显存的要求,不幸的是,我没有一个更低配的GPU来测试将设置降低到什么程度才能训练,不过,通过对于图片中的设定调整(可能需要全部关闭),你或许可以在低配电脑上训练。
1.1、数据集准备
接下来,我分享一些让数据集准备更流畅的事情,最初,我只打算训练图形绘制,比如美术师vofan的作品,这些是他的一些作品,他是动漫插画师领域比较著名的美术师。可以看到有些图片来自小说封面,这些都是她做的插画。
在进行文字说明之前,我们现需要对这些文件进行重命名,比较有用的一个技巧就是,确保你的所有文件都是同一种文件格式,比如JPG或PNG,以免在批处理的时候出现重复文件名。
这里是一个需要避免的做法,在Windows系统文件夹下,全选所有图片并点击这里的重命名icon,为所有图片选择一个名字(我选择的是graphic_illust),点击回车键,你所有的图片都被重新命名,唯一的区别就是它们的后缀数字变化。
 然而,可以看到这里有些古怪,比如名字是graphic_illust (1)的文件有两个,其实我们可以发现后续几乎所有的数字名都有重复,这是因为,我的图片格式既有JPG,又有PNG,所以批处理的时候自动将不同格式的文件进行了排序,于是就出现了重名文件,这是我们不希望的结果。
然而,可以看到这里有些古怪,比如名字是graphic_illust (1)的文件有两个,其实我们可以发现后续几乎所有的数字名都有重复,这是因为,我的图片格式既有JPG,又有PNG,所以批处理的时候自动将不同格式的文件进行了排序,于是就出现了重名文件,这是我们不希望的结果。
我们需要避免这样的现象,但怎么做到呢?这里介绍一个简单的解决方法:
我的方法是打开命令提示符程序(cmd),导航到图片文件夹,然后将所有的JPG转换成PNG格式,或者将所有PNG转换成JPG,只是为了让你文件夹内的所有文件保持为同一种格式。所以,你可以输入“ren *.jpg *.png”然后按回车键,这样文件夹内所有文件就会变成PNG格式。
然后,我们会到上一步,再次批处理重命名(参考此前步骤),这样我们就不会有重复的文件名了。
下一步,将这些图片放到图片处理工具中,我这里使用了birme,我发现自己的电脑配置可以支持768×768尺寸的图片训练,所以我将图片裁剪成这个分辨率尺寸。
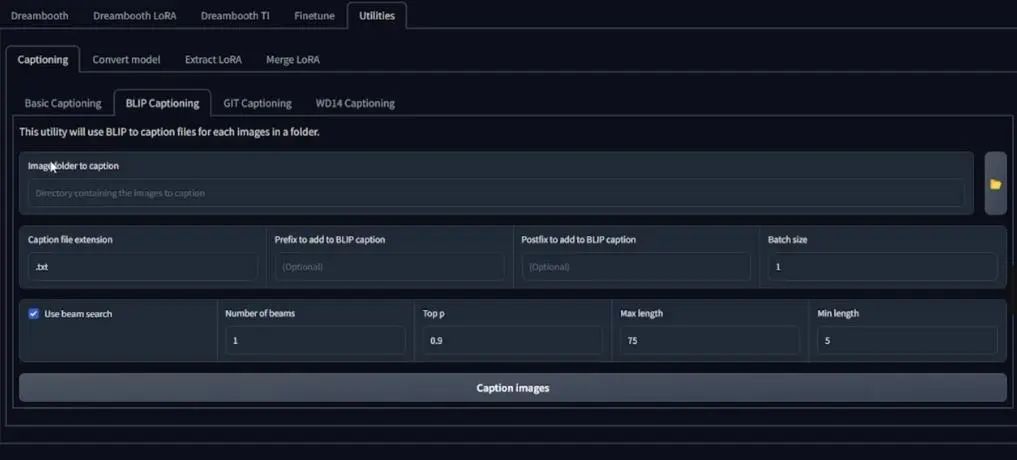
接下来是给你的图片增加说明文字,处理好所有的图片之后,进入gui界面,点击utilities标签,选择BLIP Captioning,将你的图片文件夹(文件路径)输入到指定位置。
如果想要训练特定风格,你可以在这里增加前缀,比我们这里输入“VOFANstyle”,但我并不只是用它来训练这一位美术师的风格,所以我选择留空,这里是我选择的配置:
说明文字处理完成之后,回到文件夹,就可以看到每张图片都有了一个txt说明文档:
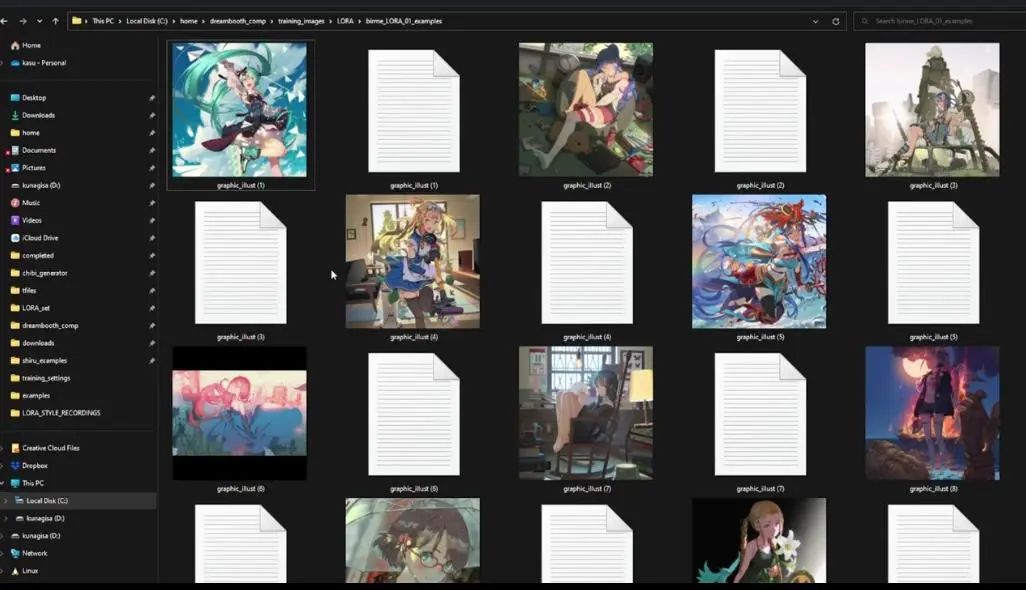
我用来编辑说明文字的工具是Visual Studio Code,可以看到这个界面,打开一个图片文件,然后点击右上角的icon,第二个窗口打开TXT文件。现在的问题是,我们是为什么增加说明文字?如果我们要训练一个角色,那么所有图片的说明都是同一个角色,这样它才能被识别。
所以我们这里可以把一个女孩(a girl)换成初音未来(Hatsune Miku),不过,我们并不是要训练一个角色,所以不用更换。
我们想要训练的是一种风格,所以会描述除了图片风格之外的一切,因此我们不会使用“插画(an illustration of)”或者“照片(a photo of)”之类的术语。基本而言,我们希望对想要改变的一切进行说明,这一点刚开始可能有点难以理解,但我会尽量解释的直观一些。
这个案例中,“一个绿色长发在空中飘扬的女孩(a girl wiht long green hair is flying through the air)”描述相当准确,但还不够精准。我要描述的是一个蓝绿色眼睛、绿色双马尾长发的少女(a teenage girl with teal eyes and long teal hair in twin tails),然后删掉其余所有描述,将在空中飞扬(flying through the air)留在最后。
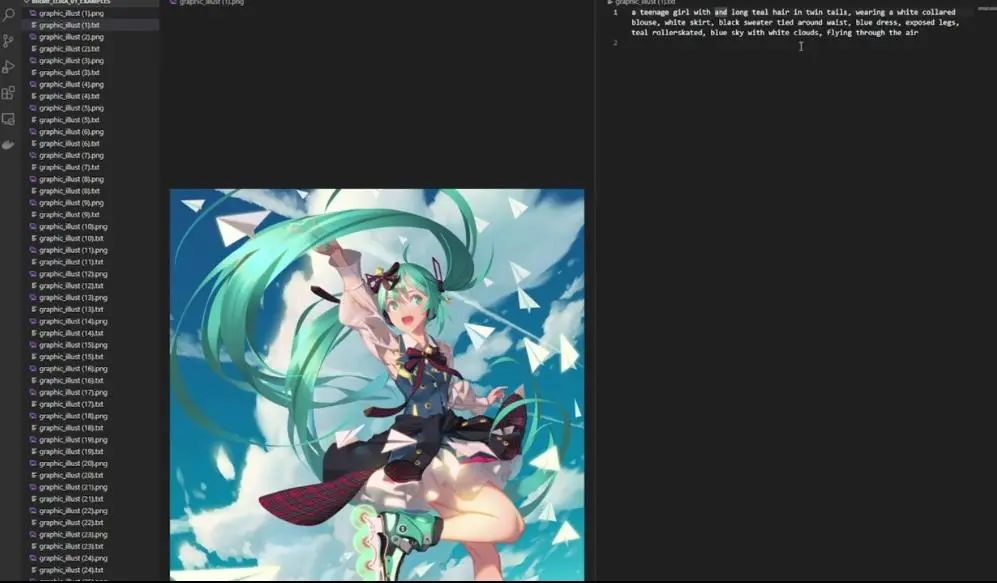
那么,除了上述特征之外,她还有什么特点?可以看到,她穿了一件白色衬衫,白色短裙,黑色毛衣围在腰间,还穿了一件蓝色连衣裙,腿部暴露在外,还有一双蓝绿色溜冰鞋。随后,还可以看到蓝天白云。
完整说明文字:a teenage girl with teal eyes and long teal hair in twin tails, wearing a white colored blouse, white skirt, black sweater tied around waist, blue dress, exposed legs, teal rollerskated, blue sky with white clouds, flying through the air
那么,我为何要在这里描述的这么具体呢?如果我不在这里描述,那就意味着我希望LoRA学习这些东西,如果我不描述蓝绿色眼睛,那么最终生成的所有角色都会有蓝绿色眼睛。所以,一定要将能够改变的所有东西描述出来。
这里是我要修改的第二个图片描述,可以看到这里的描述是错误的(a woman sitting at a table with a book and a cigarette),很明显这里缺失了一些东西,所以我们把它改为:
“a young woman with medium length hair, closed eyes, wearing a white collored blouse, green dress, school uniform, green hair ribbon, desaturated light brown ribbon, looking up to the right side, book in the foreground, blurry building in the background”
我觉得这些足以描述图片里的内容了,当然,这一步是非常耗时间的,因为你需要检查很多的文字,如果想要获得良好的数据集,就需要恰当处理这些说明文字。所以,我需要开始做这些事情,然后开始训练。
1.2、Kohya_ss设置
现在我到了GUI里的Kohya SD脚本部署界面,点击Dreambooth LoRA标签,也就是我们要使用的这个。
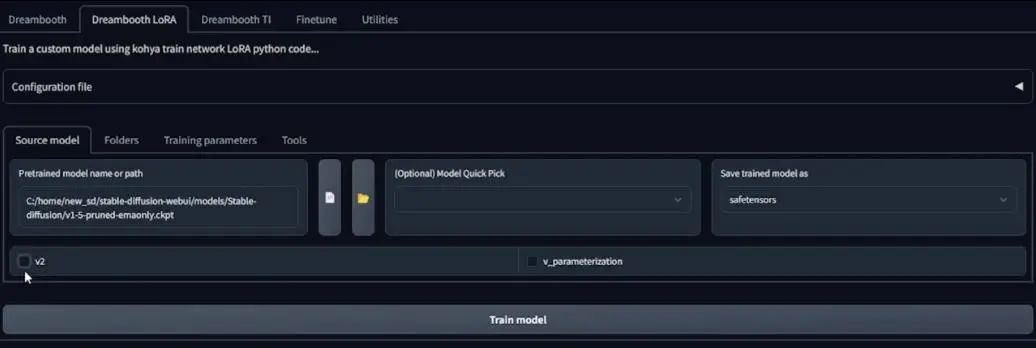
前面说到,我要使用Stable Diffusion的1.5版本模型,所以点击图片中的书页icon,等待它加载模型路径,而且要保持下边两个勾选框为空。
下一步是工具标签,Kohya的文件夹有些独特,而且必须遵循一定的传统,图片中的设定是我已经设置好的:
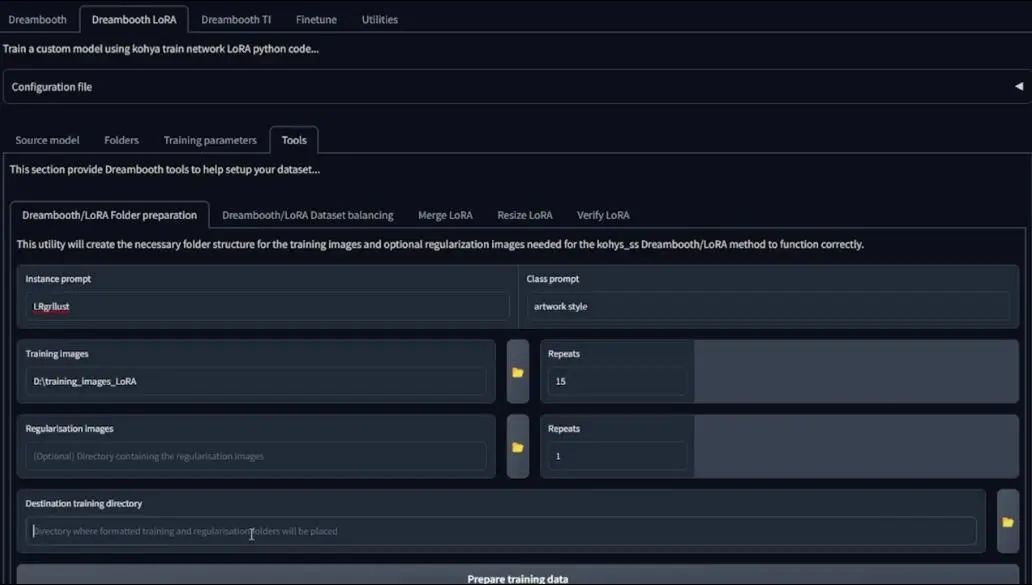
点击下方的准备数据集按钮即可。
随后,点击复制信息到文件夹标签(Copy info to Folders Tab),这很有用。
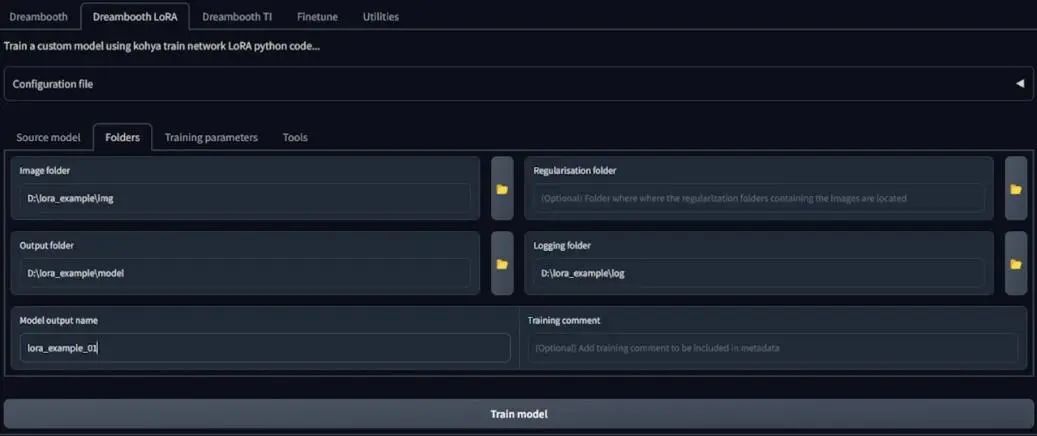
然后我们来到文件夹(Folders)标签,我们不用手动输入文件夹路径,它是上一步已经设置好的。对于模型输出名字,我这里设置为lora_example_01。
接下来是训练参数设置,打开Training Parameters之后看到的是默认设置,然而,由于我的数据集训练了157张图片,这些默认设置表现不会很好。经过了多次尝试之后,我发现使用修改后的设置配置文件好很多,所以我将它们加载到训练参数里。
在正常的LoRA模型训练中,你或许不会像我一样使用那么多的图片,所以可以将训练频率提高一些,因为我使用的数字非常低。然后我们具体来说其他设置。
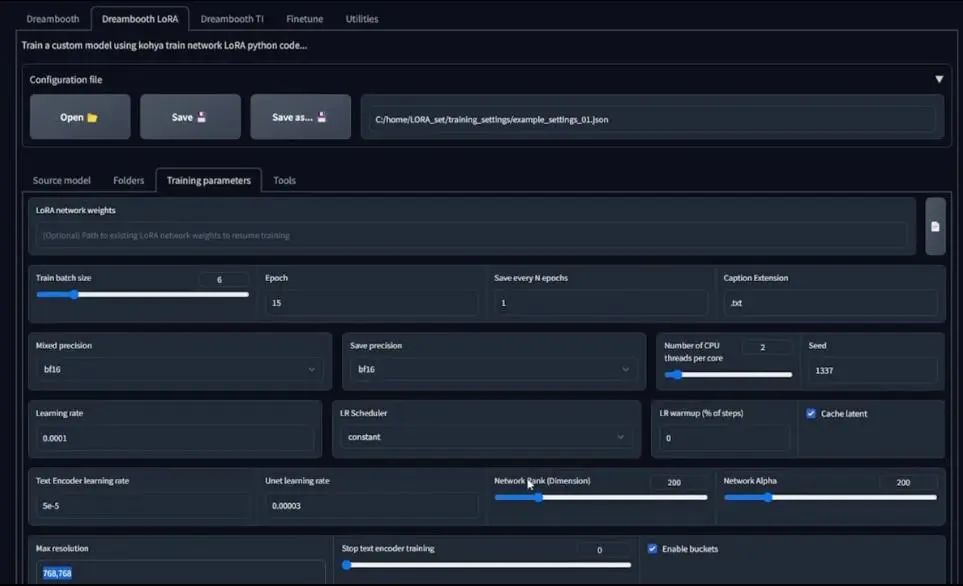
对于训练批处理大小(train batch size),如果你的GPU显存低于8GB,我建议将其设置为2甚至为1,它代表的是你可以同时运行的平行计算数量;随后是回合数(epoch),它代表的是你对一个数据集进行反复传播的次数,你可以调整这个数字,但我强烈建议至少大于1,因为这会成为你的快照文件(snapshot file)或者保存的LoRA文件。
最后我应该有15个LoRA文件,每个回合都有一个,你需要这些文件因为它们代表不同的时间点,你可以通过它来查看你的结果是否过度拟合。
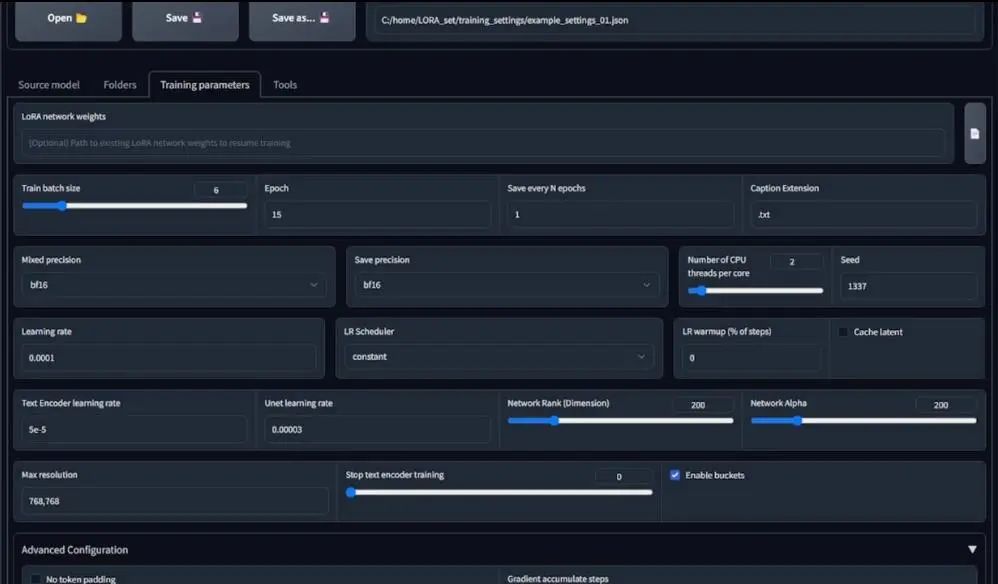
接下来是精确度,如果可以使用bf16精准度模型,一定要用它,如果训练的时候出错,使用fb16就行。对于LR Scheduler设置,选择constant就行,训练频率是默认的,如果你的文本编码器或unet学习频率为空白,它就会使用默认数值。
随后是network rank和network alpha设置,通常来说,你应该保持跟我一样或者相同的数值。对于768×768像素这样的高分辨率图片,使用更高的network rank是个好主意。对于非动漫模型的风格化训练,将其设置为200或者更好会更好一些。
根据我个人的经验,在数值256左右的时候会开始得到糟糕的结果,所以我建议不要设置那么高。或者,如果你想要这样高的设置,就需要进一步降低unet学习频率。
然后是高级设置,可以看到我的设置,你可以和我的设置一样,因为Stable Diffusion 1.5模型是在CLIP SKIP1基础上训练的,所以将其数值保持为1,对于动漫模型或其他V3版本,将clip skip设置为2。
我还启用了洗牌描述(shuffle caption),如果你发现LoRA训练有些颜色问题,你可以启用颜色增强(color augmentation)功能,但它随后会关闭这个页面中的cache latent,所以,如果颜色成为了大问题,你可以尝试启用这个功能。
总而言之,这就是我使用的设置,所以就可以开始训练模型了。但在此之前,我还需要提到一件小事,也就是步数计算,它会出现在控制台输出界面,如果你要训练的批处理大于1,总训练步数实际上会有比较大的差别,因为它是图片数量、重复次数与回合的乘积,我使用了157张图片,所以我的训练步数是35325步。
然而,我的训练批处理数量是6,所以我需要用总步数除以6,我之前说过,这是你同时运行的平行数量,因此得到的结果是5888步左右。当我真正训练的时候,它呈现的结果是5888步,而非总步数35325步训练结果。
如果一切就绪,你就可以按训练按钮开始训练。
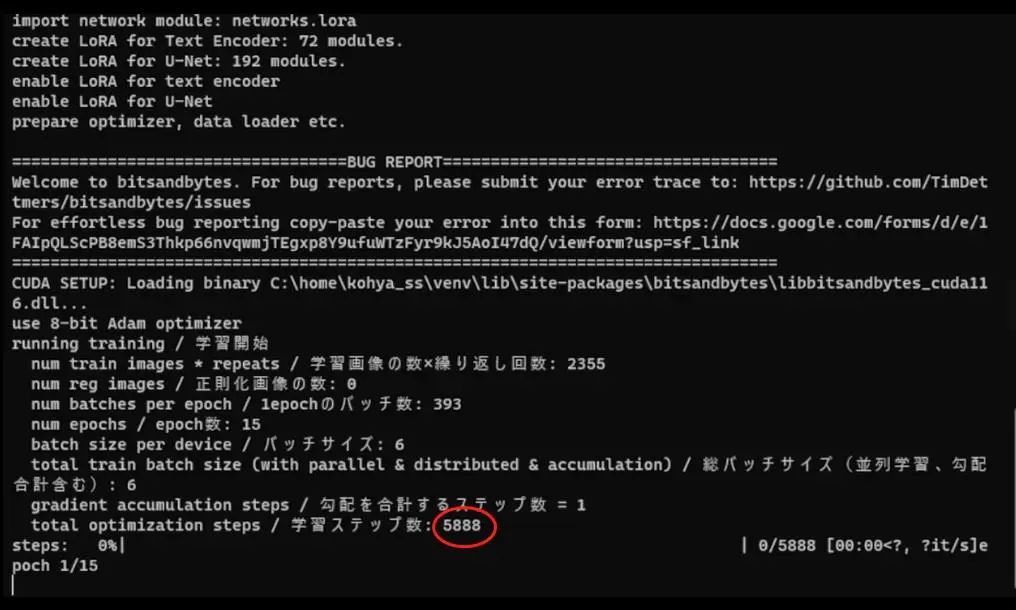
如果看power shell,可以看到最大训练步数是5888,随后是加载我的checkpoint,然后或许是cache latents。
现在它会计算步数,对我来说,总的训练时间在12个小时或15个小时左右,但这是对于15个回合、157张图片,而且分辨率较高、network rank也达到了200。所以,这并不是标准的训练时间,如果训练数量合理,LoRA的训练时间在30分钟到2小时之间。
1.4、分析结果
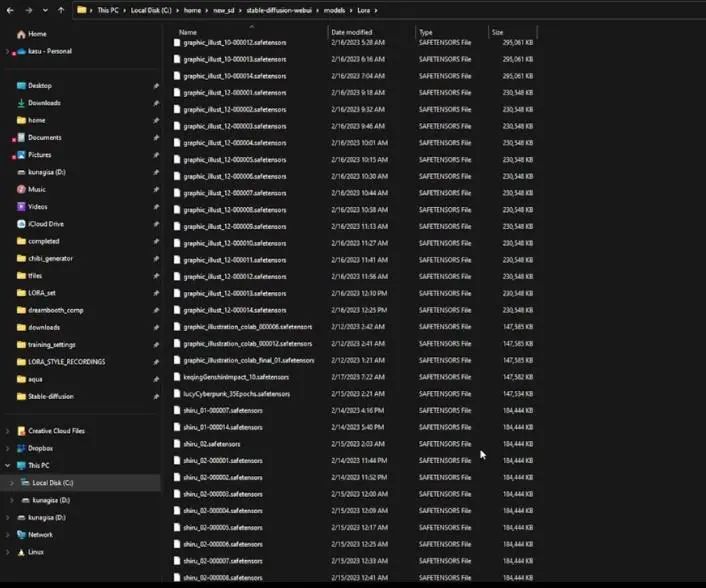
如果你的训练没有出错,那么恭喜。进入你建立的文件夹,然后打开模型文件夹,你应该可以看到与回合数一样多的文件,所以我这里有15个文件,全选复制粘贴到Stable Diffusion LoRA文件夹(stable-diffusion-webui/models/lora),确保所有的文件都在这里,否则就没办法进行下一步。
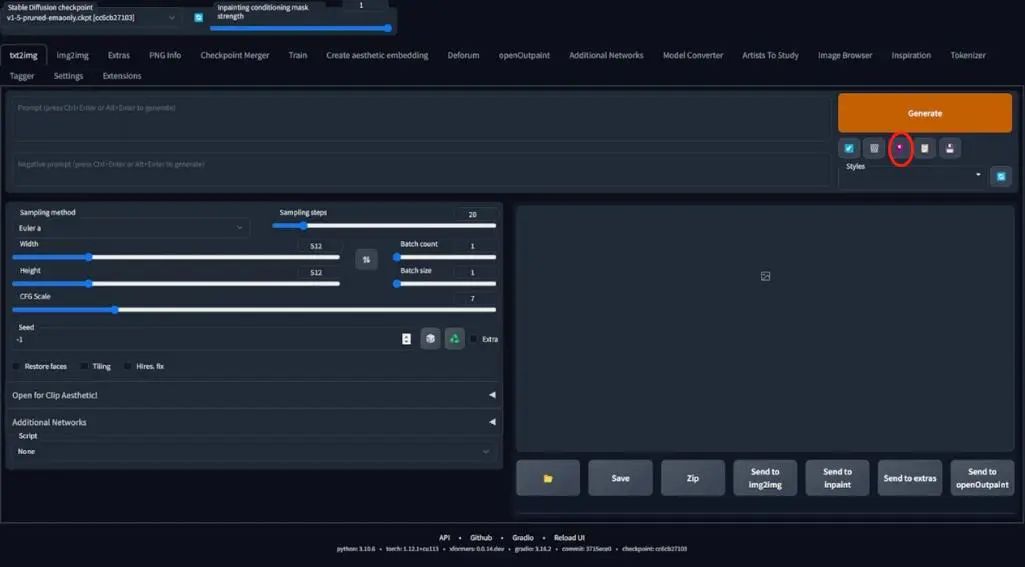
接下来是分析我们的LoRA模型,我的方式是选择一个非常标准和简单的指令以及负面指令,想要激活并使用你的LoRA模型,点击这里的红色按钮,进入lora标签,搜索你的lora名字,我的是graphic_illust_12。
选择一个,lora会以这种形式出现,随后,我使用lora写指令的方式是这样:
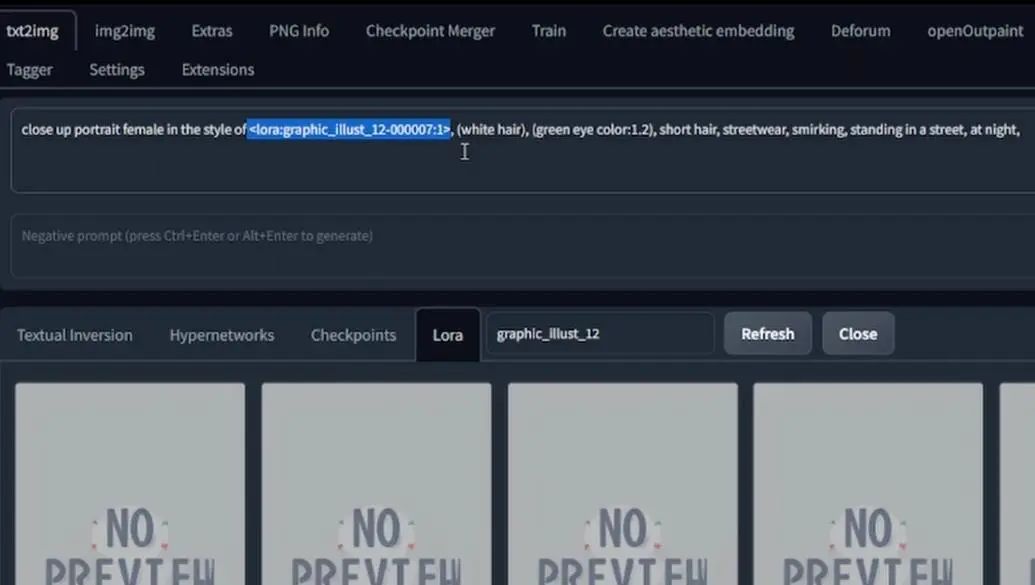
这就是我告诉Stable Diffusion加载LoRA风格学习信息的方式,然后粘贴负面指令,接着将采样方式设置为习惯使用的方式。
接下来,我在脚本选项下打开XYZ选择,还记得回合数是以LoRA名字格式保存的,所以这里使illust_12,随后是五个0,然后是一个整数,LoRA的权重或强度在冒号之后。我想要一个不仅能展示回合模型的变种,还能改变LoRA权重的网格。
为此,我首先要为X类型选择Prompt S/R,代表搜索和替换,这里我想要替换的是模型数字,所以我要将这里的000007改成变体num,接下来在X数值里,我写入NUM, 000001, 000002……0000014。
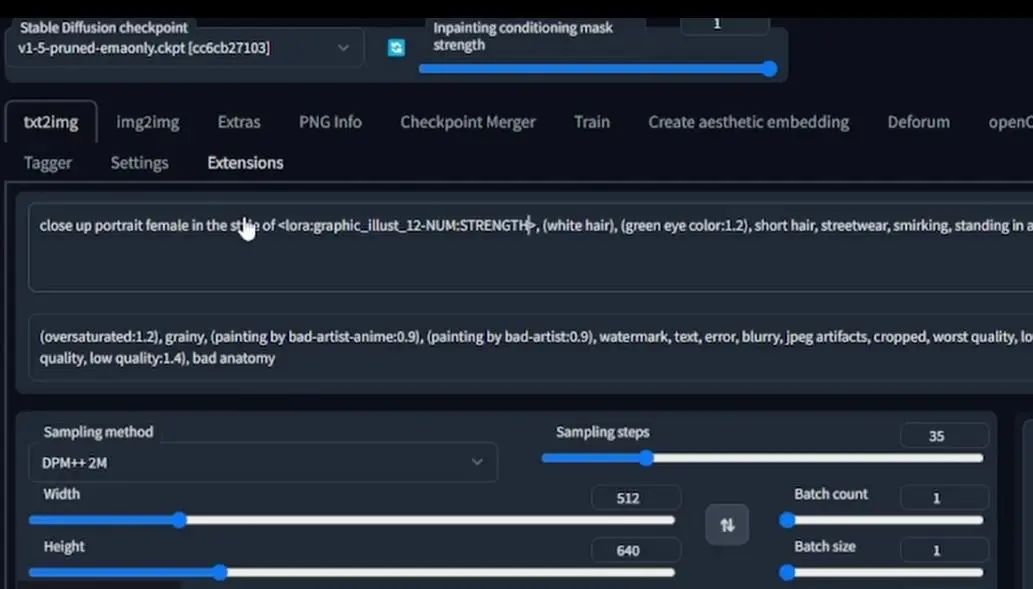
如果你理解了这个逻辑,那么后面就会比较直接了,比如Y类型选择Prompt S/R,然后在Y值输入STRENGTH, 0.1, 0.2……0.9, 1。并且将1改成strength,这样在输入指令之后,我至少会得到一个14×10或者10×14的展示变体的网格,别忘记将模型选择为你训练的模型,这里我已经选择了1.5 pruned-emaonly,所以,根据你的实际需要,选择不同的东西。
接下来我输入指令,它看起来网格已经生成好了,点击之后就是这样的效果:

我觉得最好是点进输出结果文件夹,把它放到Photoshop里,这样可以更好地观察一切,现在图片太小,很难知道是否有过度拟合。
这是Photoshop里的视图,横轴是X,竖轴是Y,这时候我们可以选择应该进一步测试哪个回合了。有人建议,LoRA强度为1的时候不应该有过度拟合。幸运或者不幸的是,由于尝试了很多次,我们并没有得到特别糟糕的结果。
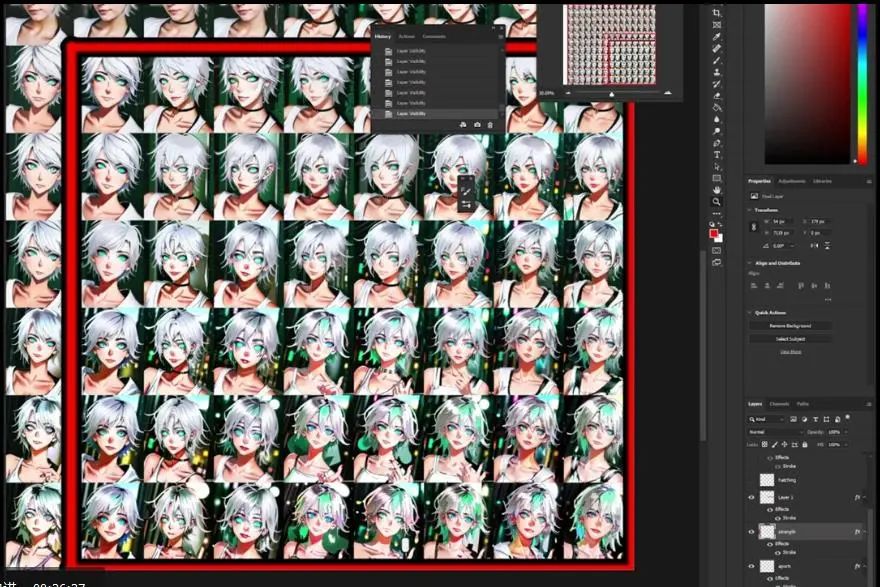
接着是聚焦于网格里的右下角,这里我们可以看到LoRA更高强度与回合的结果。更多回合意味着训练处理的时间更长,我个人想要开始分析的是回合7,这时候图片形状更清晰,强度为1。
如果你了解游戏,最终的世界让我想起这种风格:

哪怕数据里并没有这样的风格。
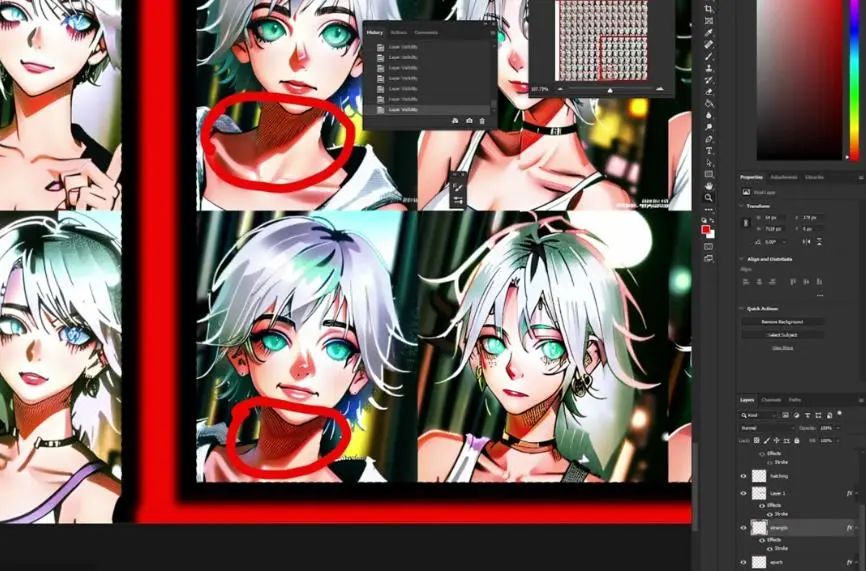
这里甚至还有影线标记(hatching mark),算是比较令人开心的意外。
随后,如果我们持续增加回合数,你会看到发生了一些令人困惑的事情,比如这里第八和第九回合的睫毛膏或者眼影,但到了第十回合的时候它们消失了。在强度为1的时候,从10回合到14回合,我们开始得到了非常好的插画效果,实际上做到了数据集想要它做的事情,或者说是我想要LoRA模型做到的效果。
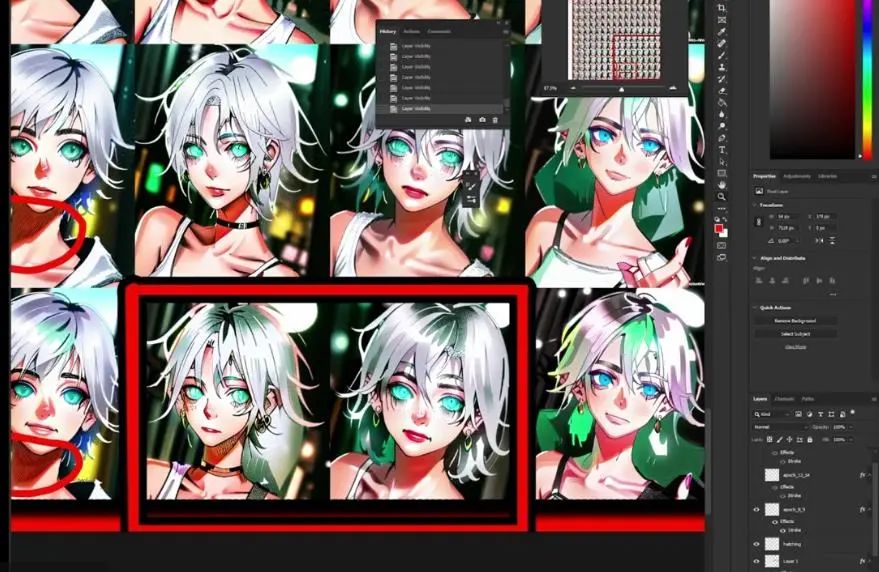
然而在倒数第二个回合,我们发现了一些人为现象(artifacting),所以13和14回合有些失控。如果我们用粗略的方式分析结果,可能就会因为过度拟合而放弃最后几个回合。
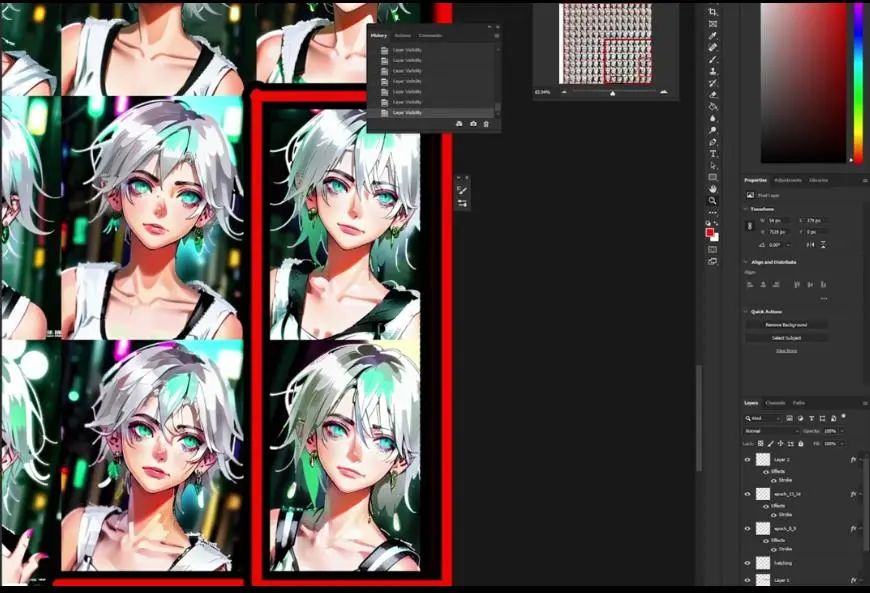
如果细看,我们会发现14回合强度0.8和0.9的表现非常不错,所以个人来说,基于实验结果,我会继续并且在webui用几个不同的指令测试最终的15回合,来看它到底是真的过度拟合,还是因为我生成时使用了比较糟糕的种子数字,所以我们开始尝试:
1.5、确定最终LoRA模型
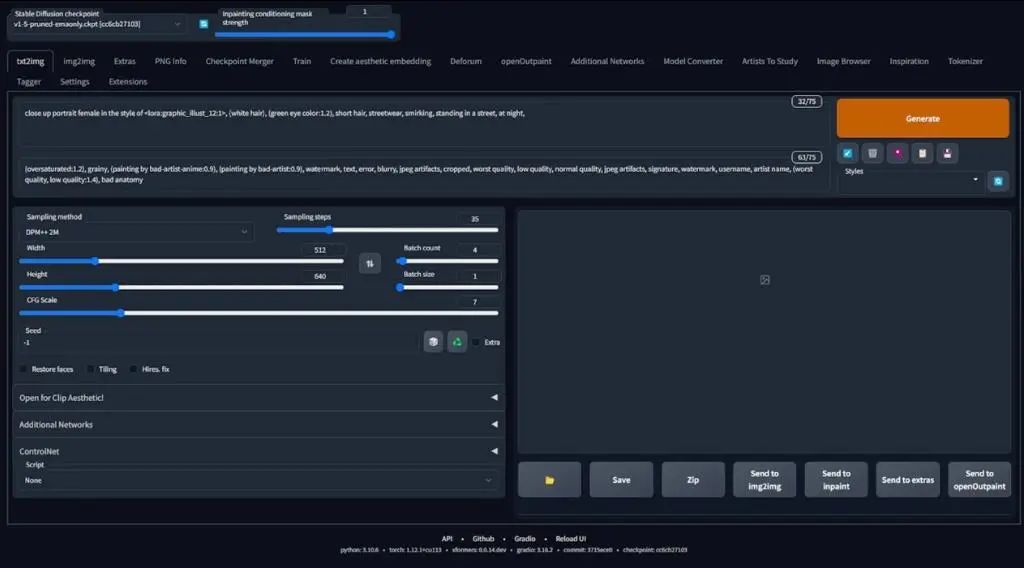
这里我们进入了stable diffusion webui界面,我希望测试最终回合,这里不会有任何数字附加,所以我们用随机种子测试强度1加入指令。

这些是我们的结果,个人而言我很喜欢。如果达不到你想要的清晰度,可以将lora强度降为0.9或者更低。
我们保留种子数字,将强度降低为0.9,可以看到人为痕迹消失了。当然,这些地方始终可以通过局部重绘(impainting)来提高,所以我并不太担心文生图部分。
那么,我们为何不尝试其他选择呢?比如将指令里的白色头发改为金色头发,这意味着我们的LoRA模型并没有被限制。如果我们不能通过指令的变化改变输出结果,那就意味着我们的LoRA模型出现了过度拟合,这是我们应该注意的另一件事。

如果结果是金色头发,就像图片中的这样,那么我们就可以继续了,这就是测试LoRA角色的方法。
但是,如果是LoRA模型没被训练的东西,得到的结果是怎样呢?这也是我们风格训练的目的,所以我准备了一些指令来进行测试。
1.6、应用LoRA风格
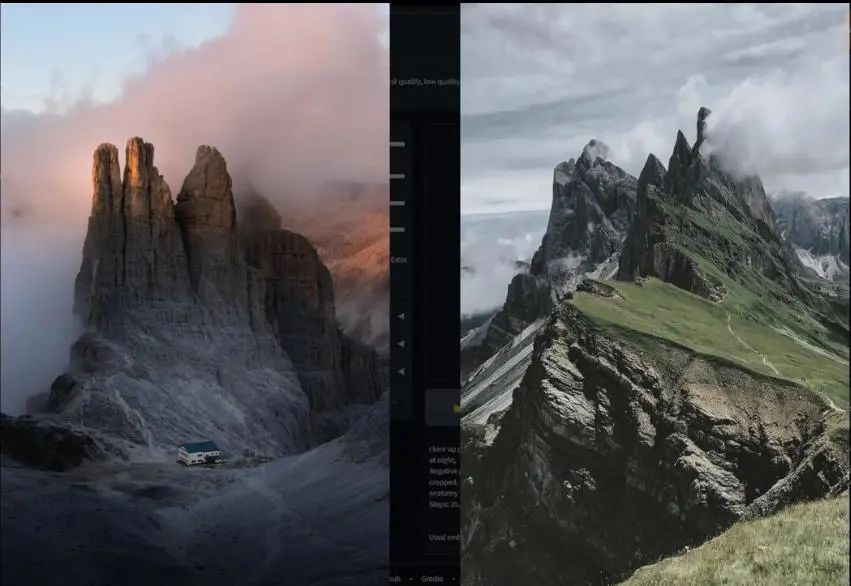
这里我们将指令中的角色相关内容去掉,将强度改回1,种子改为随机(-1),我们可以先测试一个户外环境的生成,比如意大利北部的名山多洛米蒂山(Dolomites),然后看它是否能够生成与其相关联的图形。

可以看到,结果很不错,它的结果是形状与多洛米蒂山一致,不过是不同的风格。

那么,换成室内场景是否可行呢?比如图书馆,我们就可以得到插画风格的图片。

然后我们来测试一些非常随机的东西,比如韩剧《非常律师英禑》,她喜欢一直飞来飞去的鲸鱼,所以我们可以将指令修改为flying whales来看得到什么结果:

这些结果很酷,我个人很喜欢。如果觉得太强烈,可以降低强度,但哪怕是强度为1也不会有人为痕迹。我们可以修改为0.8:

从我的分析来看,不管你输入什么指令,LoRA模型都不会出现过度拟合,当然,也或许是我没有找到对的测试方法来发现过度拟合。不过,我觉得这是一个不错的尝试。
所以,接下来我会开始动漫风格的LoRA训练,相信很多人都会感兴趣。
第二部分:用Google Colab训练Kohya LoRA模型
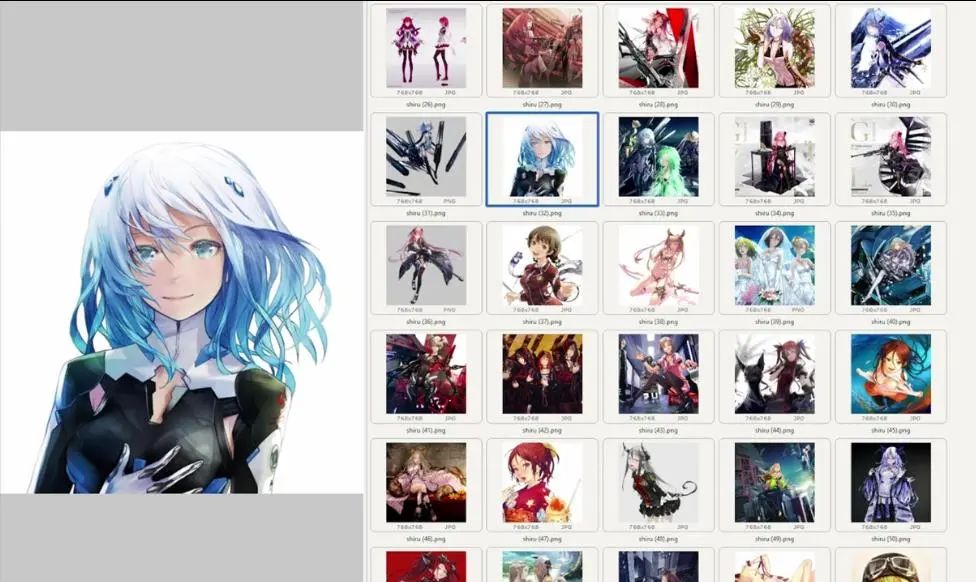
在开始训练LoRA之前,我们像以往一样要从数据集开始。这里我选择的是日本插画师redjuice的作品,他也以shiru这个名字被很多人熟知。Shiru的意思是汤,这里我选择的是768×768像素的图片,如果不熟悉我是如何准备数据集的,请参考第一部分。
这里可以看到,所有图片都有同样的名字,唯一的差别就是后缀数字,而且都是PNG格式。
2.1、数据集准备
由于这里假设你不会使用Kohya本地安装,而是使用Google Colab,所以我这里改变了添加说明文字的流程来使用AUTOMATIC1111里的网页扩展tagger。
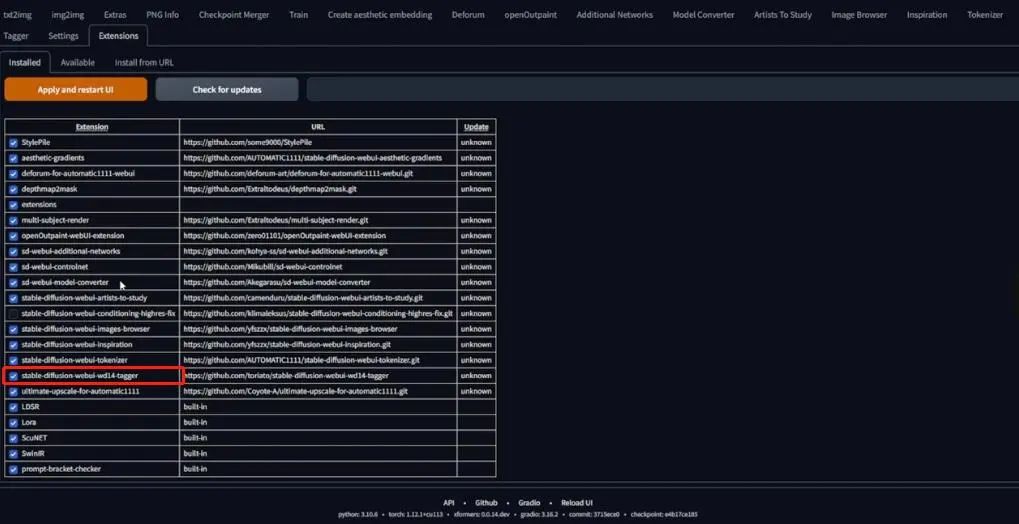
所以点击extensions,可以看到我已经安装了tagger,随后点击Tagger标签,就可以看到如下界面:
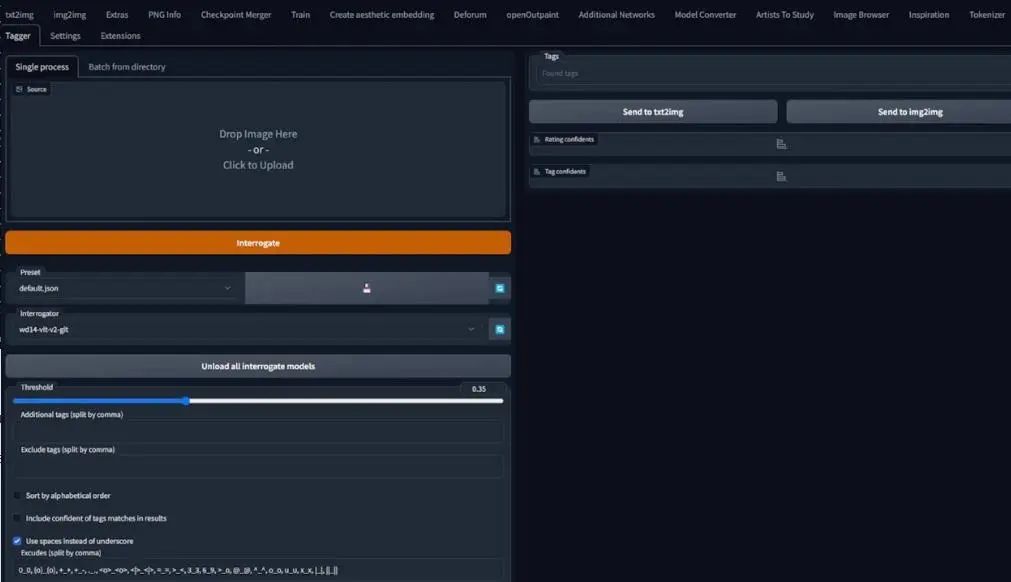
这里的文字说明流程与第一部分(blip captioning)不同,由于这次我们将使用clip skip 2模型训练,通常是动画风格,这里是v4.5 Pruned模型,一定要确保使用Danbooru风格的标签,你很快就会知道我说的是什么意思。
点击“从目录批处理(batch from directory)”标签,在输入目录里放入正确的路径。如果你想要在其他标签之前添加一个标签,比如redjuicestyle,对我而言,我通常不使用token带引用风格,所以这里我会留空。因此,我也不知道这里最好的方法是什么,如果了解过第一部分,就会知道这样的选择对于LoRA来说也非常好。
如果一切满足你的需求,可以点击interrogate按钮,然后检查控制台:
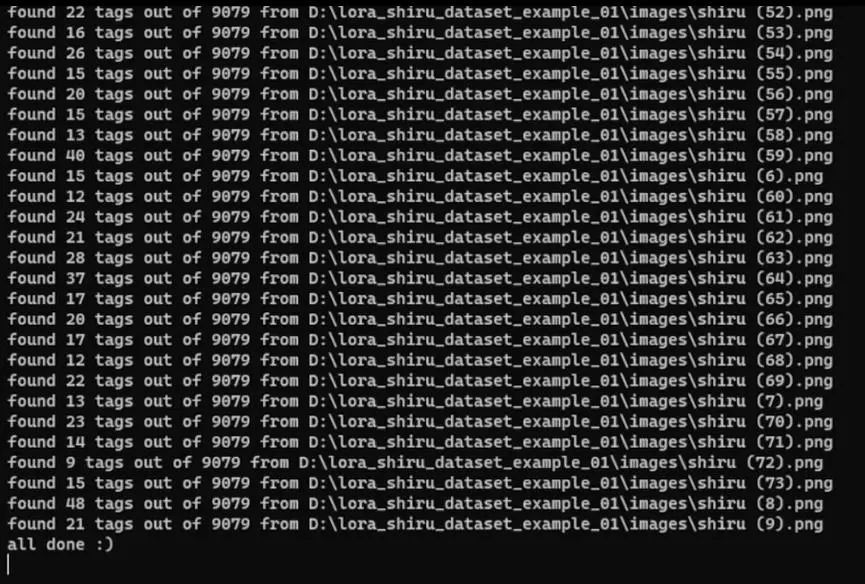
它在加载这些文件,完成之后我们跳转到数据集文件夹,看是否有说明文件。
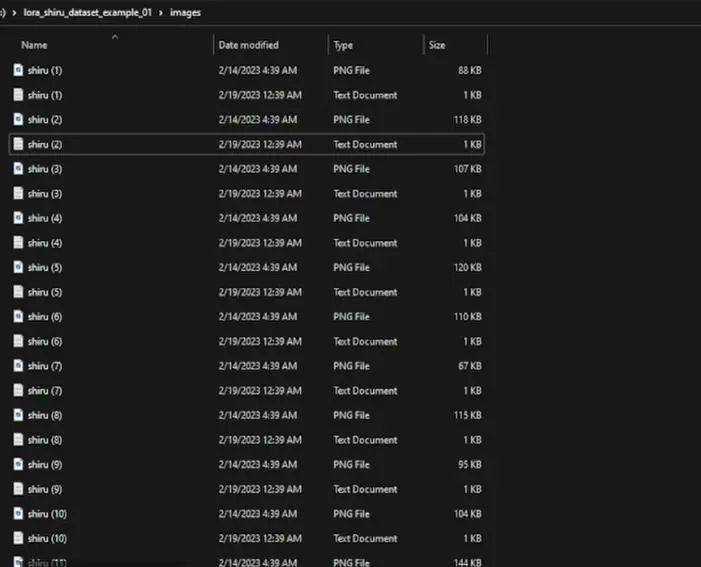
2.2、改良描述说明
可以看到每一个对应的图片都有了说明文件,然而我们还没有结束,还需要再次打开VS code软件进行编辑。
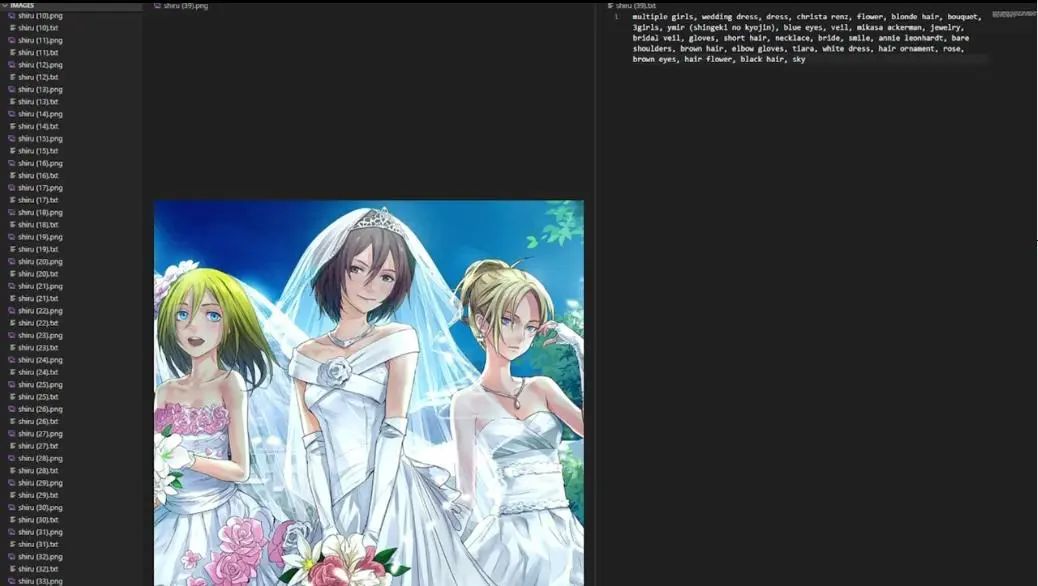
这是VS Code界面,左侧是我打开的数据集里的图片,右侧是它的描述文字,第一眼看去,我们可以发现其中的很多都是正确的。比如有婚纱、手套、肘部手套、冠状头饰、白色连衣裙等等,都是图中有的内容。
我不希望对每个细节都作出修改,但在这里有些东西是需要改变的,比如这里的角色描述是有名字参照的,如Mikasa Ackerman、Annie Leonhardt、Ymir(图片中并不存在),还有Christa Renz。这里的名字对我们来说是个问题,就像在第一部分说过的那样,我们希望描述的是所有我们希望改变的东西。如果将名字留下来,它就会作为一个记号,会影响LoRA最终的风格。
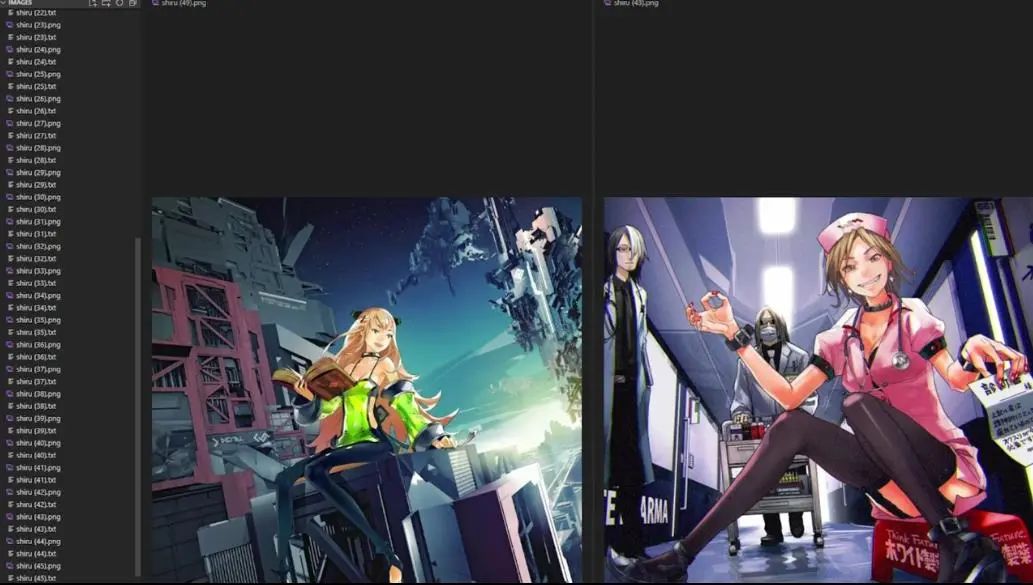
我们希望LoRA对于每张图片只在单一概念上做出妥协,所以,去掉所有的角色名即可,然后检查所有的描述文件,去掉其中的名字。
2.3、Kohya Colab Notebook
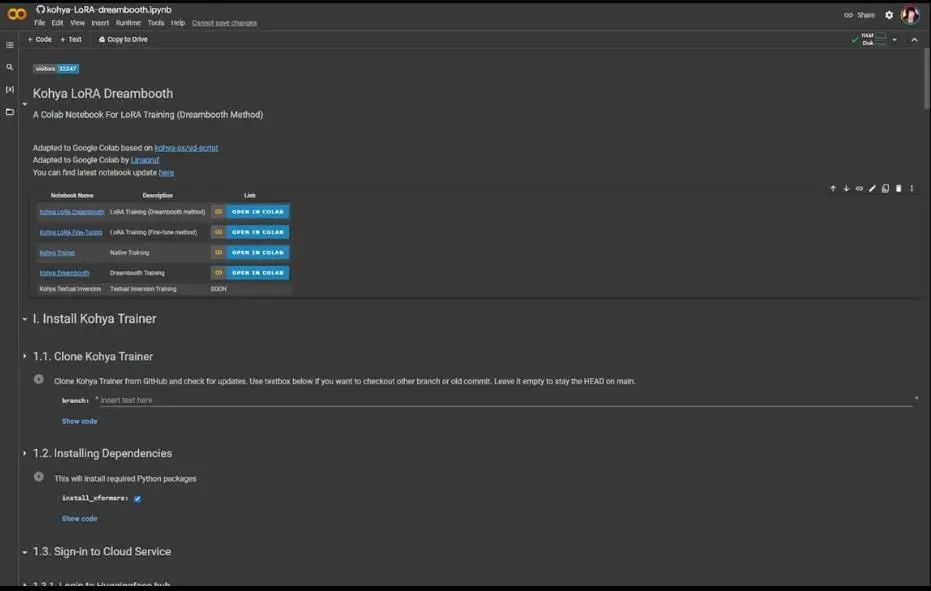
现在,我们的数据集已经恰当地被描述,接下来进入Google Colab Notebook,如图所示,它的用途非常直观,不过我会逐个介绍。
第一部分是Clone Kohya Trainer,只需要按播放按钮,它会提示你Kohya没有得到谷歌认证,只要选择运行即可,完成之后会有一个绿色对号。
接下来是安装dependencies,再次点击对应的播放按钮,它就会开始处理、安装Python包体,这需要一段时间,因此需要等待所有东西完成。
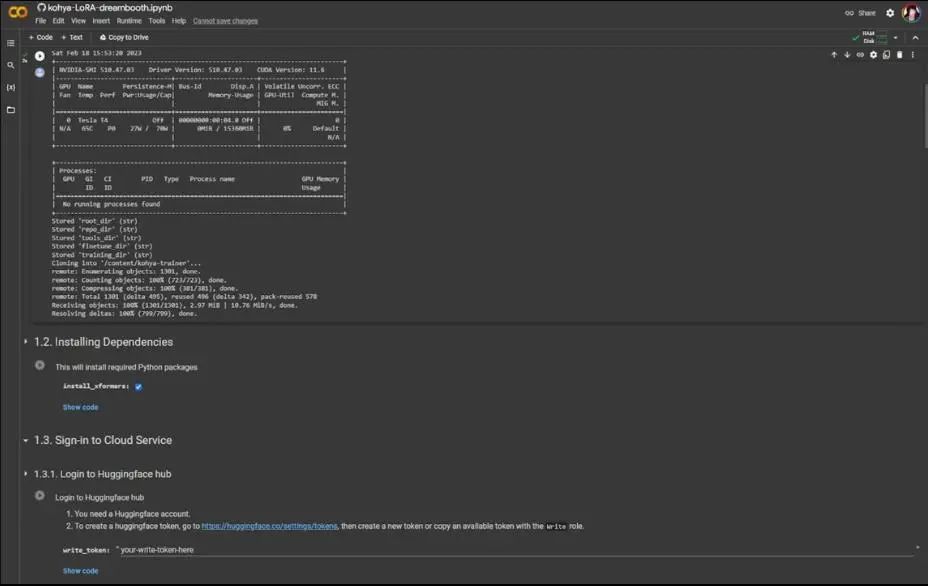
随后是1.3.1,登录Huggingface社区,确保你有一个Huggingface账号,并拥有一个具备写入职能的标记(token),我这里粘贴我的标记,然后点击播放按钮。
下一步是Mount Drive,点击播放,连接到Google Drive,完成之后,点击左侧的文件夹icon,就可以看到drive文件夹。
然后是为Colab打开特殊的文件浏览器,点击播放按钮,等待完成。
第二部分,我们开始下载想要使用的模型,我使用的是Anything v4.5 pruned,选择之后点击播放按钮,它就会开始下载,并且从Huggingface同步。
你可以跳过2.2,因为不会使用定制模型,所以我们直接说2.3,下载可用的VAE,我们使用的是动漫风格,所以看到选项是anime.vae.pt直接点击播放按钮即可。
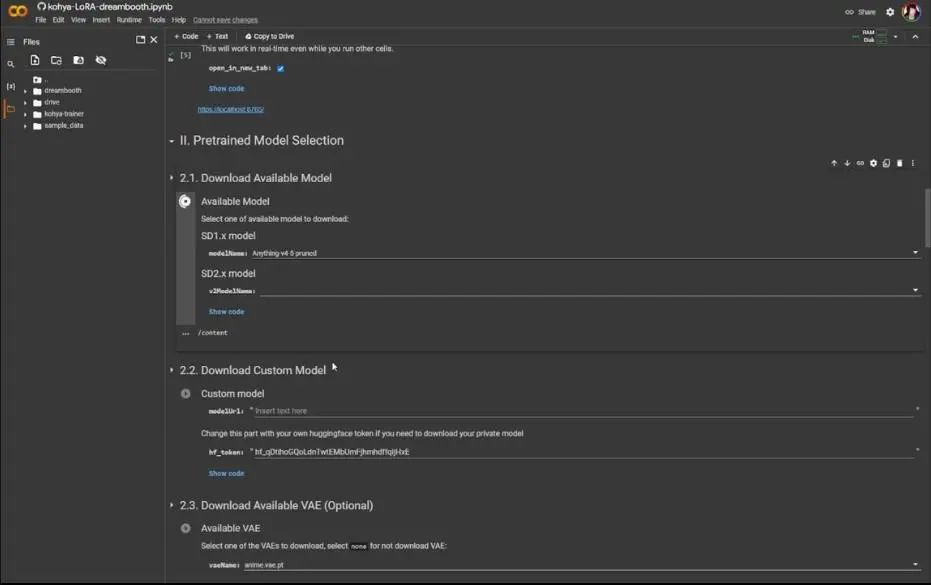
第三部分是数据获取,定义你的训练数据位置,将训练重复次数设置为10,其他随便改就行,因为它们的影响并不大,点击播放按钮之后,它会在左侧创建文件夹,位于Dreambooth文件夹之内。
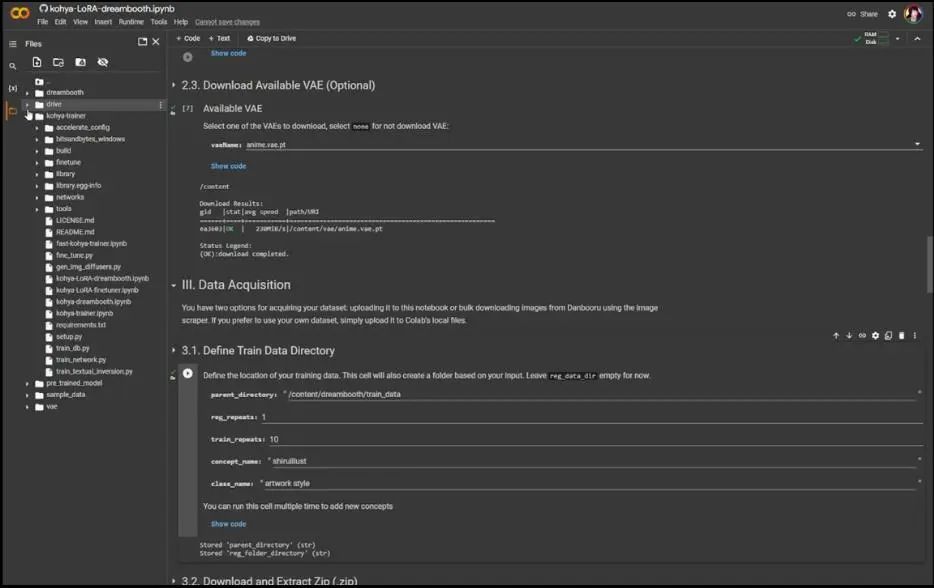
随后是上传数据集,其余第三部分和第四部分的东西都可以跳过,因为我们在本地准备了数据集。
接下来是定义重要文件夹,也就是第五部分,项目名写成“shiruillust”,将预训练模型路径改为Anything -v4-5,将后缀Safetensors改为ckpt(即checkpoint)。
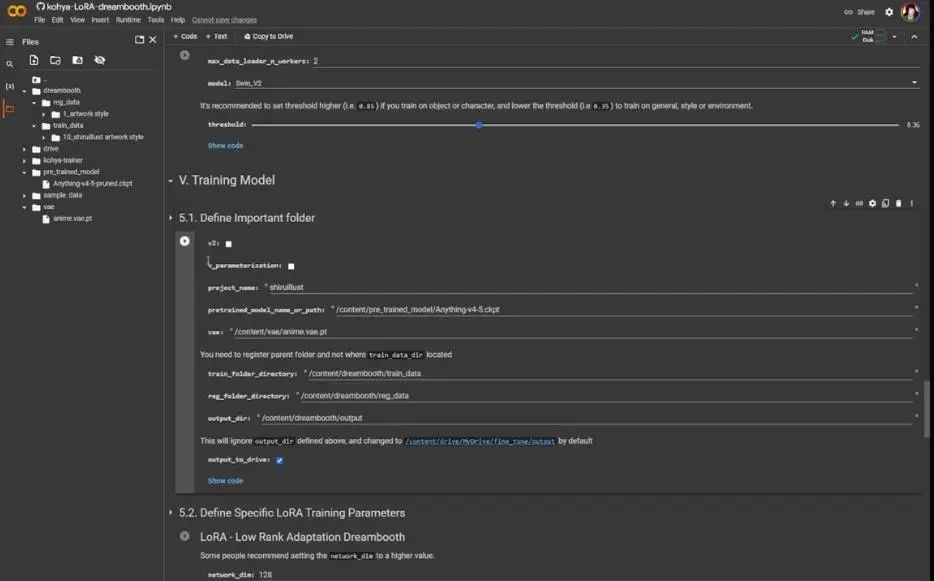
对于VAE,我们在左侧已经有了一个,点击复制路径,粘贴到对应位置就行。其他的设置看起来还好,不过,对于输出目录,我希望改为本地硬盘,因此勾选输出到硬盘驱动即可。随后点击播放按钮,开始定义我的文件夹。
由于我们跳过了数据上传,所以你要到本地数据集文件夹,全选,然后拖拽到左侧的训练数据文件夹。
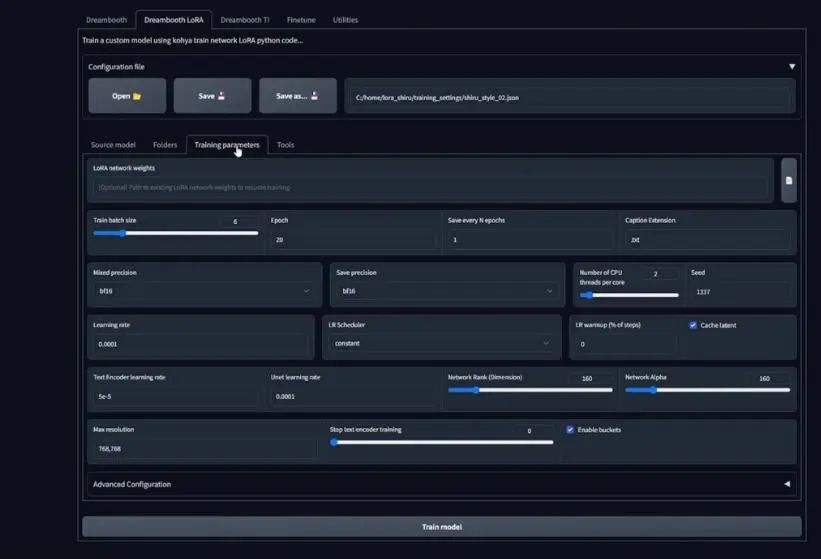
这是我的Kohya训练设置,我将回合设置为20,学习频率改为0.0001,network rank选了160,所以回到colab,将5.2部分的network dim设置为160,学习频率设置为1e-4,其余设置如图。
随后点击播放按钮。
然后是开始LoRA Dreambooth,我选择了fb16,但我不认为Colab GPU能够处理,所以保持fp16不变。你可以将分辨率调至我在本地训练时的768,但是这会导致程序崩溃,因为内存不足,因此分辨率尽可能调低,通常可以调至512,这里的设置是640。
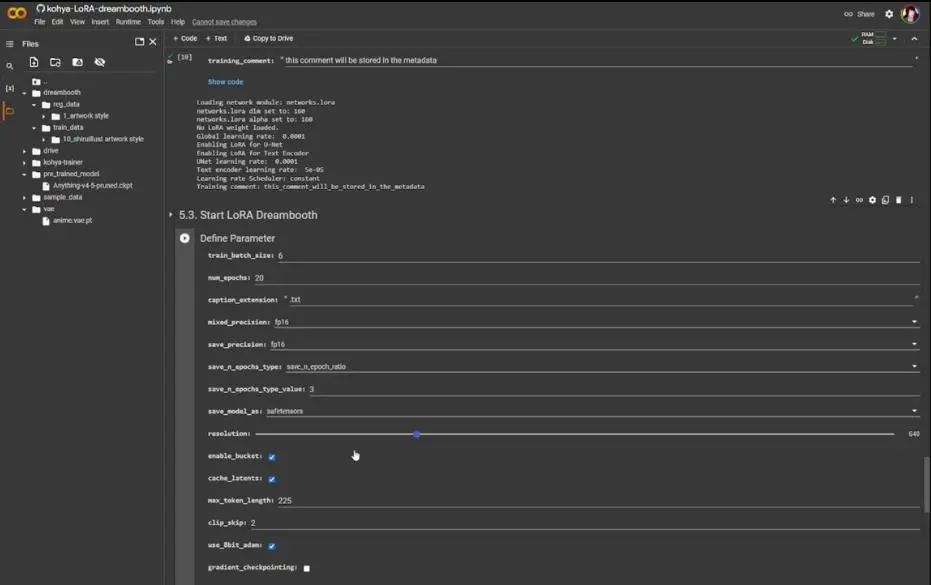
回合数设为20,将save_n_epochs_type设置为save_every_n_epochs,将保存回合类型值设为1,这样它就会像第一部分那样,从0.1、0.2一直到1。
其余设置看起来还可以,然后可以检查代码,看是否有数字出错,如果没问题,就可以点击播放按钮。
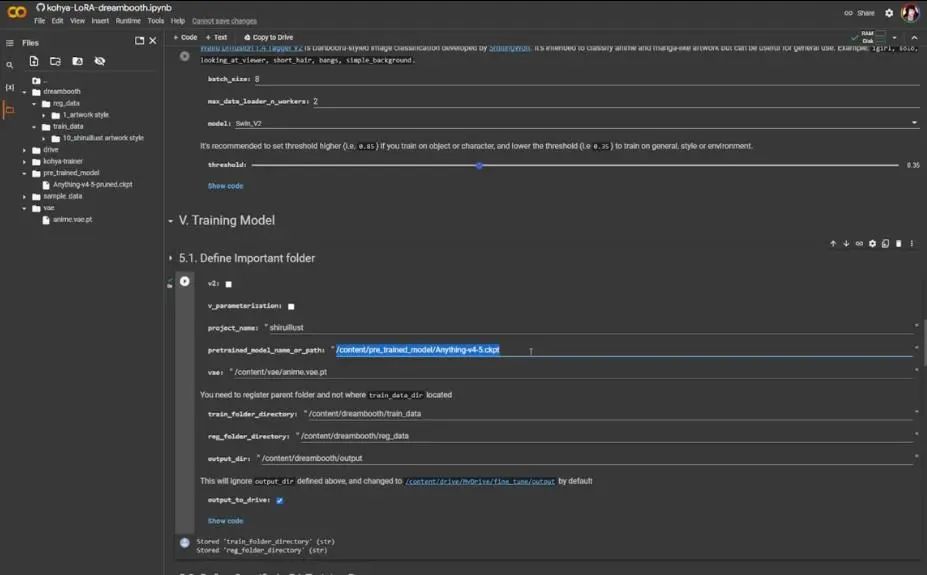
我们这里发现了一个错误,这是好事,因为我也犯错了,可以看到是我的本地路径写错了,所以回到预训练模型路径,我没有在路径里写上pruned,所以最好是直接复制路径粘贴,然后再次运行5.2,接下来是运行5.3。
这会持续一段时间,大约一个半小时,等待其完成就可以了。
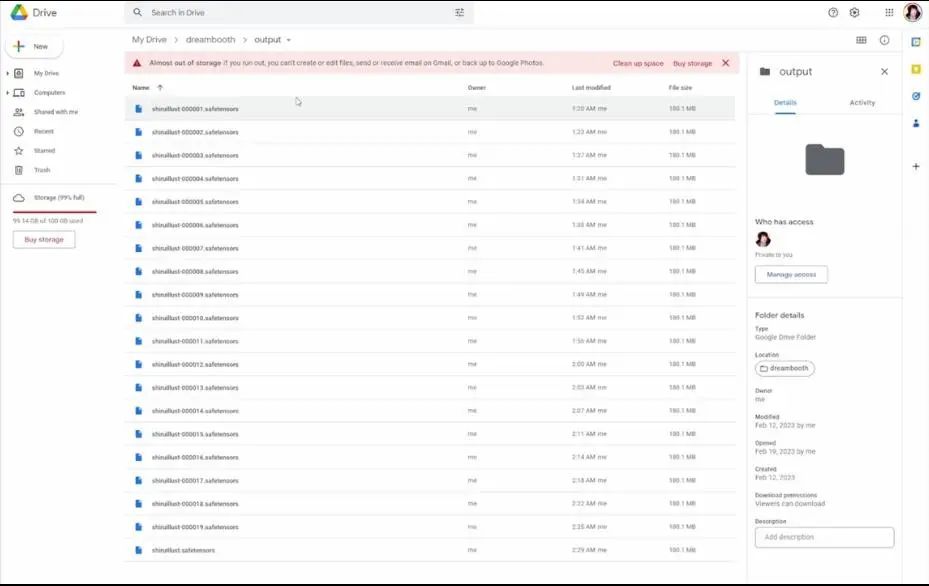
如果你想知道自己的文件在哪里,进入Google Drive,你会在My Drive文件夹下看到Dreambooth文件夹,所有一切都应该在这里的output文件夹里。点开之后可以看到所有的回合结果,最后结果是没有数字的文件。
你可以全选,右键,然后选择下载,它们会被打包为一个Zip文件,解压然后复制粘贴到Stable Diffusion下的LoRA模型文件夹,然后打开webui。
2.4、分析LoRA模型
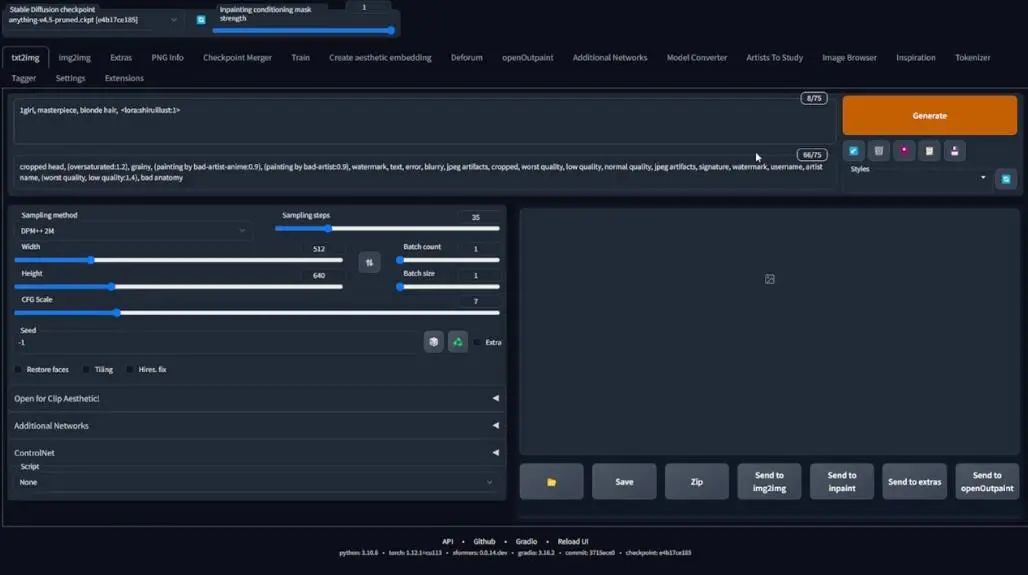
现在我们进入了webui,已经加载了LoRA,我的名字是shiruillust,我会选择最后一个没有数字的文件,运行,看它是否可行。

先删掉LoRA,生成一张图片作为种子,然后黏贴LoRA模型,将图片种子代码粘贴到seed,然后点击生成,它应该会给我一个风格化的结果:

可以看到结果图片的确有redjuice风格。
我们将批处理量改为4,种子随机,然后再看结果:

四张图片看起来有些粗糙,但看起来还是可行的。所以,接下来我们重复第一部分的步骤,创造一个图片网格。
不过在此之前,我们先看看能否改变图片的部分内容,比如将金发改为红头发,如果结果图片没有改变,那就意味着我们的模型是有问题的:

可以看到,它可以改变角色头发的颜色,有些图片甚至将连衣裙颜色也变成了红色,想要精准控制,我们只需要随后将指令写的更具体即可。
回到脚本选项,将之前用过的XYZ值复制粘贴到对应位置,不过这里的回合是20,所以要将NUM增加到000019,其余保持不变。
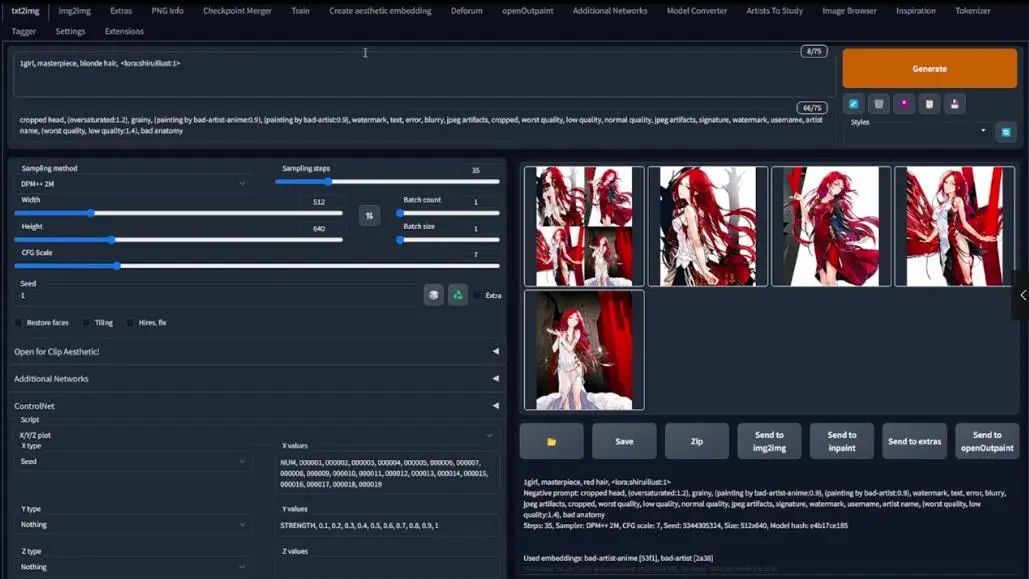
然后将批处理量改为1,将LoRA里的数字改为num和strength,确保使用Prompt S/R,然后点击生成。
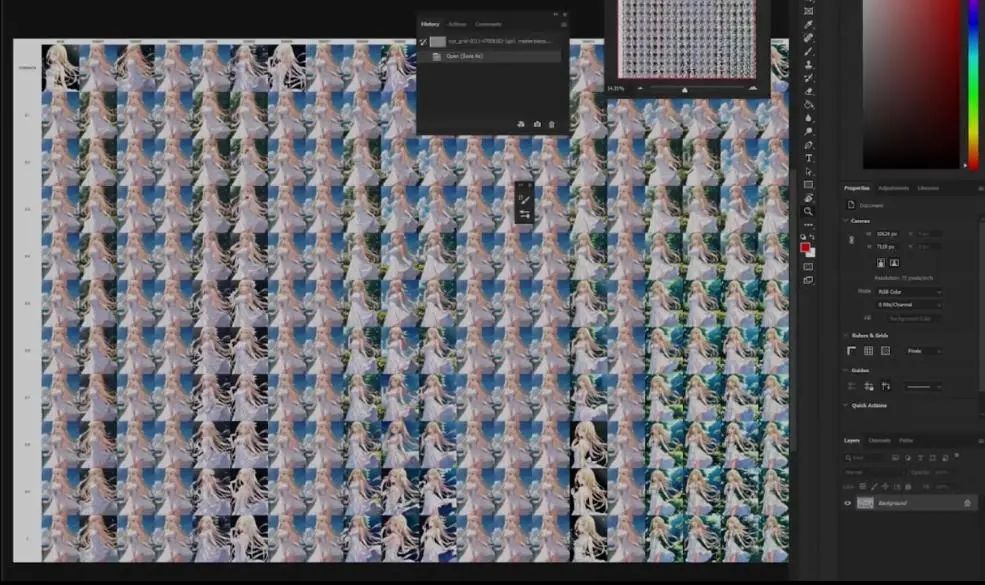
我们将结果图片在Photoshop里打开,然后只看最后几回合的结果,到了第9回合左右,才有一点redjuice风格的味道,到了14回合的时候可以看到比较大的变化。我这里只选择最后回合,它应该会给出最好的结果。
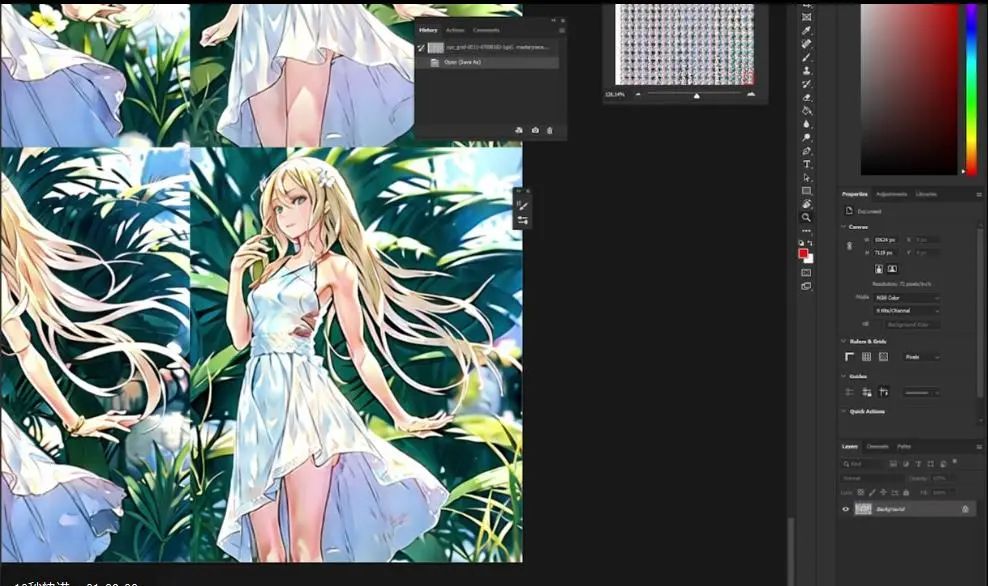
所以,我回到Stable Diffusion,然后用最终回合做一些生成测试。
2.5、验证最终LoRA模型

的确有redjuice风格。

如果记得开头,你们会发现有一个redjuice风格的赛博朋克角色Lucy,所以我们这里测试模型能否通过使用LoRA模型组合,来生成对应结果。
2.6、组合使用LoRA模型
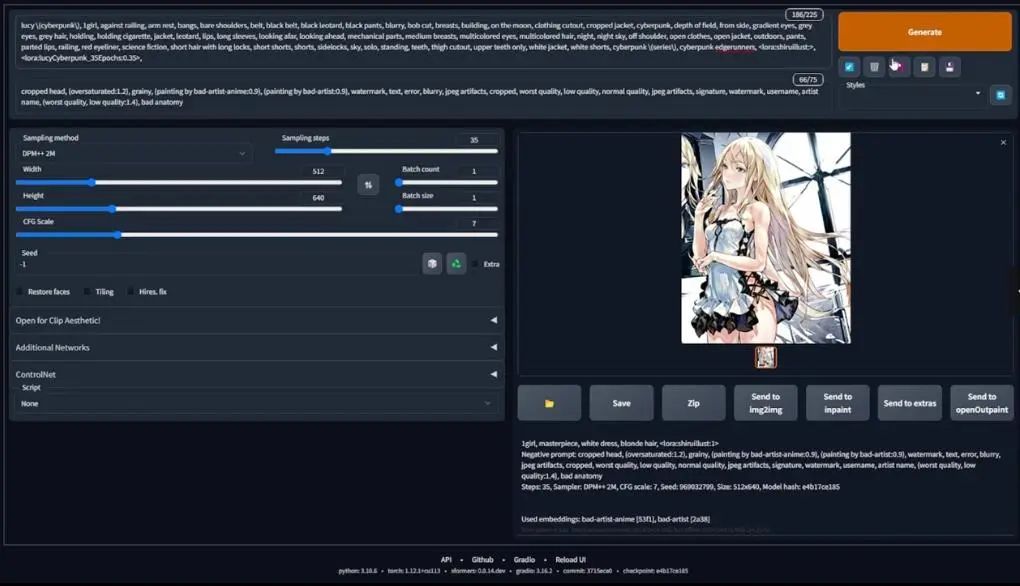
这里我们粘贴指令,最初的代码是本地训练版本,但我这里要改为Colab版本,看它是否可行。

Redjuice风格的Lucy。
增加批处理量,看它是否仍然有效:

生成结果是令人满意的。
然而,你可以在训练阶段做更多次重复或更多回合,因为步数太少会有些略显不足。
再用本地训练的LoRA模型生成,可以看到结果好一些:

但这也可能是因为我用了VAE。

看起来没有太大的区别。
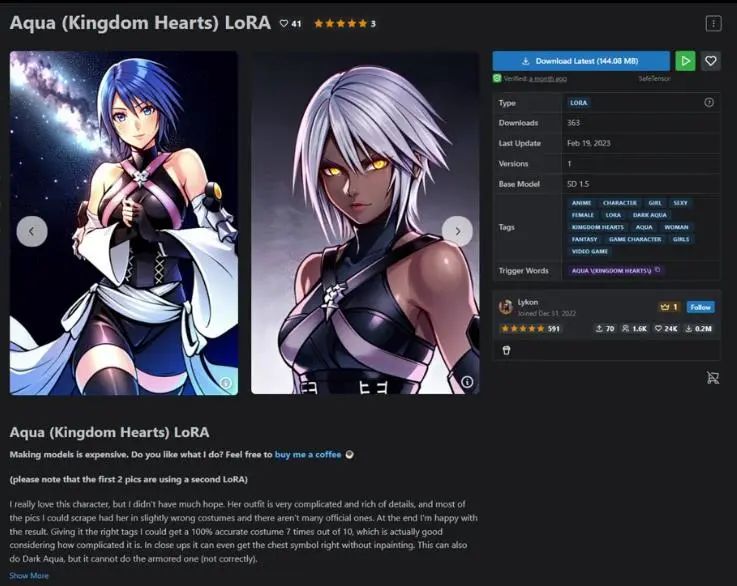
接下来我再用一个风格进行LoRA模型Colab训练,这是Lycon制作的LoRA,这次我们用来自《王国之心》的角色Aqua测试:

看起来像是Aqua

将批处理量改为4,可以看到风格也是持续的,看起来的确像是redjuice画的。如果想要保持不饱和色彩,你要卸掉VAE,我们可以试试:

有些图片没有出现粉色带子,这里我们需要调低角色LoRA风格或者角色强度,但整体结果已经完成了。
再来测试去掉VAE之后的Lucy:

可以看到这里的redjuice风格更明显了。
我所有训练的模型都可以在Civitai找到,希望能够有你需要的风格训练方法。不过,我也还在尝试之中,这些方法的确带给我比较满意的结果,希望也能帮到你们。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/喵喵爱编程/article/detail/776213
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

